SkillChain: Closing the Loop on Skill Evolution for Image-Based E-Commerce AI Assistants
Pith reviewed 2026-06-27 06:38 UTC · model grok-4.3
The pith
SkillChain automates skill creation, routing, and refinement to handle diverse image-triggered intents in e-commerce AI assistants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
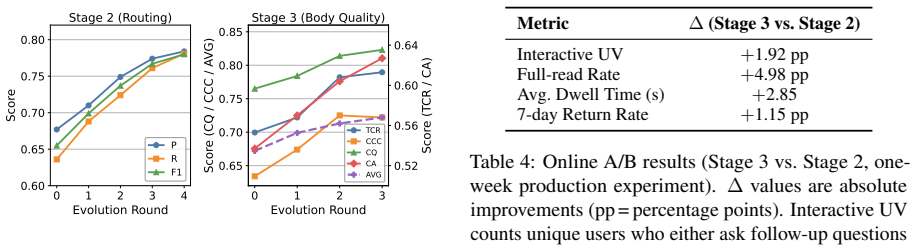
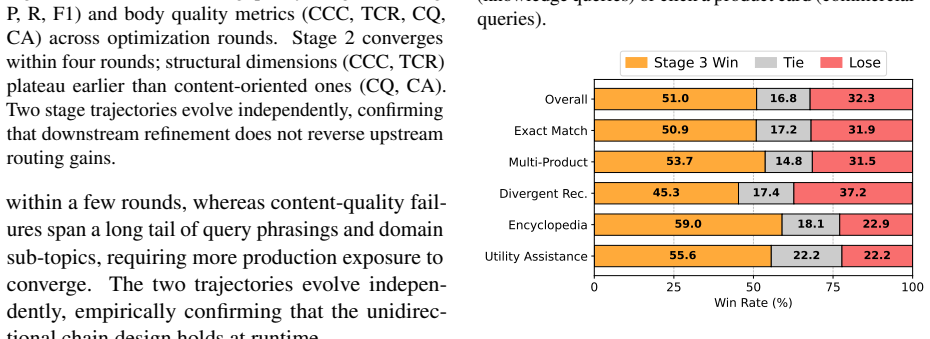
SkillChain closes the production feedback loop on skill evolution by automating the lifecycle of Skills through three stages: Skill Creator for bootstrapping from task specs and trajectories, Route Optimizer for routing alignment, and Body Refiner for iterative Skill Body refinement via dual-path LLM-Judge evaluation. Deployed on a production-scale e-commerce image assistant, it substantially improves aggregate response quality with strongest gains on structural compliance and content quality, while a one-week online A/B experiment confirms significant gains in user engagement, content consumption, and long-term retention.
What carries the argument
SkillChain, a closed feedback-loop pipeline of Skill Creator, Route Optimizer, and Body Refiner stages that uses dual-path LLM-Judge evaluation to iteratively evolve skills from production data.
If this is right
- Responses achieve higher structural compliance and content quality without manual per-intent rules.
- Production data can be fed back continuously to refine skills for new or shifting intents.
- The system scales to heterogeneous modes that would otherwise require constant human oversight.
- User metrics such as engagement and long-term retention improve when skills better match intent-specific demands.
Where Pith is reading between the lines
- The same three-stage loop could be tested on non-e-commerce image assistants facing similar intent diversity.
- Replacing or augmenting the LLM-Judge with direct user signals might strengthen the refinement stage over time.
- If the loop runs frequently enough, skills could adapt to emerging intents faster than manual updates allow.
Load-bearing premise
The dual-path LLM-Judge evaluation accurately measures real-world skill quality and user satisfaction without introducing its own biases or errors that could inflate the reported improvements.
What would settle it
An independent human evaluation of the same responses showing no quality gains over baseline, or a follow-up A/B test failing to replicate the reported lifts in engagement and retention.
Figures

read the original abstract
Image-based AI assistants are now deployed at production scale on e-commerce platforms, where a single uploaded image can trigger fundamentally different user intents: product search, style recommendation, visual encyclopedia, or utility tool calls, each demanding its own response format, tool invocation, and domain knowledge. Without per-intent behavioral constraints, LLM-based systems conflate these heterogeneous modes and fall short of domain quality standards, while the breadth and dynamism of the intent space render manual engineering infeasible. To address this, we present SkillChain, which closes the production feedback loop on Skill evolution, automating the lifecycle of Skills through three stages: Skill Creator for bootstrapping from task specs and trajectories, Route Optimizer for routing alignment, and Body Refiner for iterative Skill Body refinement via dual-path LLM-Judge evaluation. Deployed on a production-scale e-commerce image assistant, SkillChain substantially improves aggregate response quality, with the strongest gains on structural compliance and content quality; a one-week online A/B experiment further confirms significant gains in user engagement, content consumption, and long-term retention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SkillChain, a three-stage framework (Skill Creator for bootstrapping from task specs and trajectories, Route Optimizer for routing alignment, and Body Refiner for iterative refinement via dual-path LLM-Judge evaluation) to automate skill evolution for image-based e-commerce AI assistants handling heterogeneous intents. It claims that production deployment yields substantial gains in aggregate response quality (strongest on structural compliance and content quality) and that a one-week online A/B test confirms significant improvements in user engagement, content consumption, and long-term retention.
Significance. If the empirical claims hold under rigorous scrutiny, the work could meaningfully advance automated lifecycle management of LLM skills in production multi-intent systems where manual engineering is infeasible, particularly by demonstrating closed-loop refinement at e-commerce scale.
major comments (3)
- [Abstract and evaluation sections] The abstract and evaluation sections provide no baselines, metric definitions (e.g., how structural compliance or content quality are operationalized), statistical tests, sample sizes, or controls for confounds in either the offline LLM-Judge results or the one-week A/B test; without these, the reported deltas cannot be assessed as supporting the central production-improvement claim.
- [Body Refiner and evaluation] The dual-path LLM-Judge is used both to drive Body Refiner iterations and to report final offline quality gains, yet no external anchor (human ratings, task-specific metrics, or correlation analysis) is described to rule out systematic bias favoring SkillChain's output distribution; this directly affects the load-bearing offline pillar of the claim.
- [Online A/B experiment] The A/B test is presented as independent confirmation of user-behavior gains, but the manuscript supplies no details on exclusion criteria, randomization, or long-term retention measurement, leaving open whether the online results validate the asserted quality dimensions or merely reflect format adherence.
minor comments (1)
- [Abstract] The abstract uses qualitative terms such as 'substantially improves' and 'significant gains' without accompanying quantitative values or effect sizes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evaluation transparency. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract and evaluation sections] The abstract and evaluation sections provide no baselines, metric definitions (e.g., how structural compliance or content quality are operationalized), statistical tests, sample sizes, or controls for confounds in either the offline LLM-Judge results or the one-week A/B test; without these, the reported deltas cannot be assessed as supporting the central production-improvement claim.
Authors: We agree that the current presentation lacks sufficient detail for independent assessment. In the revised manuscript we will add explicit operational definitions of structural compliance and content quality (based on the LLM-Judge rubric), report baseline comparisons against non-evolved skills, include sample sizes, apply statistical tests with confidence intervals, and describe controls for query distribution and session confounds in both offline and online evaluations. revision: yes
-
Referee: [Body Refiner and evaluation] The dual-path LLM-Judge is used both to drive Body Refiner iterations and to report final offline quality gains, yet no external anchor (human ratings, task-specific metrics, or correlation analysis) is described to rule out systematic bias favoring SkillChain's output distribution; this directly affects the load-bearing offline pillar of the claim.
Authors: We acknowledge the risk of circular evaluation. The dual-path mechanism compares refined versus baseline outputs under identical judge conditions to isolate refinement effects, but we will add a validation subsection reporting Pearson correlation between LLM-Judge scores and human expert ratings on a 200-sample subset, plus task-specific metrics (e.g., tool-call accuracy) to provide an external anchor. revision: yes
-
Referee: [Online A/B experiment] The A/B test is presented as independent confirmation of user-behavior gains, but the manuscript supplies no details on exclusion criteria, randomization, or long-term retention measurement, leaving open whether the online results validate the asserted quality dimensions or merely reflect format adherence.
Authors: We will expand the online experiment section to detail user-level randomization via consistent hashing, explicit exclusion criteria (e.g., bots, incomplete sessions), and the operational definition of long-term retention (7-day return probability). These additions will demonstrate that measured gains span engagement depth and retention beyond format compliance alone. revision: yes
Circularity Check
Empirical deployment claims with no derivation chain or self-referential reductions
full rationale
The paper describes an applied system (SkillChain) with three named stages—Skill Creator, Route Optimizer, Body Refiner—whose outputs are evaluated by a dual-path LLM-Judge and then measured via production deployment metrics and a one-week A/B test on user engagement. No equations, fitted parameters presented as predictions, uniqueness theorems, or self-citations that close a derivation loop appear in the text. The central claims rest on observed deltas in structural compliance, content quality, and downstream user behavior rather than any quantity defined in terms of itself or justified solely by prior author work. This is the normal case of an engineering paper whose results are externally falsifiable against production logs and A/B outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-VL Technical Report , journal =. 2025 , url =. doi:10.48550/ARXIV.2511.21631 , eprinttype =. 2511.21631 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[2]
2026 , month = feb, url =
Gemini 3.1. 2026 , month = feb, url =
2026
-
[3]
2026 , month = feb, url =
Introducing. 2026 , month = feb, url =
2026
-
[4]
2026 , eprint=
CoEvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification , author=. 2026 , eprint=
2026
-
[5]
2026 , eprint=
SkillOS: Learning Skill Curation for Self-Evolving Agents , author=. 2026 , eprint=
2026
-
[6]
2026 , eprint=
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver , author=. 2026 , eprint=
2026
-
[7]
2026 , eprint=
SkillX: Automatically Constructing Skill Knowledge Bases for Agents , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution , author=. 2026 , eprint=
2026
-
[9]
2026 , eprint=
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author=. 2026 , eprint=
2026
-
[10]
2026 , eprint=
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills , author=. 2026 , eprint=
2026
-
[11]
2026 , url=
SkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support , author=. 2026 , url=
2026
-
[12]
2026 , eprint=
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents , author=. 2026 , eprint=
2026
-
[13]
2026 , eprint=
XSkill: Continual Learning from Experience and Skills in Multimodal Agents , author=. 2026 , eprint=
2026
-
[14]
2026 , eprint=
SkillNet: Create, Evaluate, and Connect AI Skills , author=. 2026 , eprint=
2026
-
[15]
2026 , eprint=
EvoSkill: Automated Skill Discovery for Multi-Agent Systems , author=. 2026 , eprint=
2026
-
[16]
2026 , eprint=
ARISE: Agent Reasoning with Intrinsic Skill Evolution in Hierarchical Reinforcement Learning , author=. 2026 , eprint=
2026
-
[17]
2026 , eprint=
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills , author=. 2026 , eprint=
2026
-
[18]
2026 , eprint=
Dynamic Dual-Granularity Skill Bank for Agentic RL , author=. 2026 , eprint=
2026
-
[19]
2026 , eprint =
WebXSkill: Skill Learning for Autonomous Web Agents , author =. 2026 , eprint =
2026
-
[20]
doi: 10.1007/s11704-024-40231-1
Wang, Lei and Ma, Chen and Feng, Xueyang and Zhang, Zeyu and Yang, Hao and Zhang, Jingsen and Chen, Zhiyuan and Tang, Jiakai and Chen, Xu and Lin, Yankai and Zhao, Wayne Xin and Wei, Zhewei and Wen, Jirong , year=. A survey on large language model based autonomous agents , volume=. Frontiers of Computer Science , publisher=. doi:10.1007/s11704-024-40231-1...
-
[21]
2023 , eprint=
The Rise and Potential of Large Language Model Based Agents: A Survey , author=. 2023 , eprint=
2023
-
[22]
Transactions on Machine Learning Research , issn=
Cognitive Architectures for Language Agents , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[23]
2023 , html =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , html =
2023
-
[24]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Reflexion: language agents with verbal reinforcement learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[25]
Executable Code Actions Elicit Better
Xingyao Wang and Yangyi Chen and Lifan Yuan and Yizhe Zhang and Yunzhu Li and Hao Peng and Heng Ji , editor =. Executable Code Actions Elicit Better. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[26]
Thirty-Eighth
Andrew Zhao and Daniel Huang and Quentin Xu and Matthieu Lin and Yong-Jin Liu and Gao Huang , title =. Thirty-Eighth. 2024 , pages =
2024
-
[27]
2023 , eprint=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. 2023 , eprint=
2023
-
[28]
Yongliang Shen and Kaitao Song and Xu Tan and Dongsheng Li and Weiming Lu and Yueting Zhuang , booktitle=. Hugging. 2023 , url=
2023
-
[29]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[30]
2022 , eprint=
WebGPT: Browser-assisted question-answering with human feedback , author=. 2022 , eprint=
2022
-
[31]
2023 , eprint=
AgentTuning: Enabling Generalized Agent Abilities for LLMs , author=. 2023 , eprint=
2023
-
[32]
Gonzalez , booktitle=
Shishir G Patil and Tianjun Zhang and Xin Wang and Joseph E. Gonzalez , booktitle=. Gorilla: Large Language Model Connected with Massive. 2024 , url=
2024
-
[33]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[34]
Yujia Qin and Shihao Liang and Yining Ye and Kunlun Zhu and Lan Yan and Yaxi Lu and Yankai Lin and Xin Cong and Xiangru Tang and Bill Qian and Sihan Zhao and Lauren Hong and Runchu Tian and Ruobing Xie and Jie Zhou and Mark Gerstein and dahai li and Zhiyuan Liu and Maosong Sun , booktitle=. Tool. 2024 , url=
2024
-
[35]
Transactions on Machine Learning Research , issn=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[36]
Advances in Neural Information Processing Systems , editor=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[37]
AgentBench: Evaluating
Xiao Liu and Hao Yu and Hanchen Zhang and Yifan Xu and Xuanyu Lei and Hanyu Lai and Yu Gu and Hangliang Ding and Kaiwen Men and Kejuan Yang and Shudan Zhang and Xiang Deng and Aohan Zeng and Zhengxiao Du and Chenhui Zhang and Sheng Shen and Tianjun Zhang and Yu Su and Huan Sun and Minlie Huang and Yuxiao Dong and Jie Tang , booktitle=. AgentBench: Evaluat...
2024
-
[38]
The Thirteenth International Conference on Learning Representations,
Shengran Hu and Cong Lu and Jeff Clune , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[39]
and Cai, Carrie J
Park, Joon Sung and O'Brien, Joseph C. and Cai, Carrie J. and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. In the 36th Annual ACM Symposium on User Interface Software and Technology (UIST '23) , keywords =. 2023 , publisher =
2023
-
[40]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[41]
Advances in Neural Information Processing Systems , editor=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[42]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[43]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , url =. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Informa...
2020
-
[44]
2023 , eprint=
Qwen Technical Report , author=. 2023 , eprint=
2023
-
[45]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[46]
2023 , eprint=
Ghost in the Minecraft: Generally Capable Agents for Open-World Environments via Large Language Models with Text-based Knowledge and Memory , author=. 2023 , eprint=
2023
-
[47]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[48]
Precise Zero-Shot Dense Retrieval without Relevance Labels , booktitle =
Luyu Gao and Xueguang Ma and Jimmy Lin and Jamie Callan , editor =. Precise Zero-Shot Dense Retrieval without Relevance Labels , booktitle =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.99 , timestamp =
-
[49]
2024 , eprint=
A Survey on In-context Learning , author=. 2024 , eprint=
2024
-
[50]
Sewon Min and Xinxi Lyu and Ari Holtzman and Mikel Artetxe and Mike Lewis and Hannaneh Hajishirzi and Luke Zettlemoyer , editor =. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , booktitle =. 2022 , url =. doi:10.18653/V1/2022.EMNLP-MAIN.759 , timestamp =
-
[51]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang and Yeganeh Kordi and Swaroop Mishra and Alisa Liu and Noah A. Smith and Daniel Khashabi and Hannaneh Hajishirzi , editor =. Self-Instruct: Aligning Language Models with Self-Generated Instructions , booktitle =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.754 , timestamp =
-
[52]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , editor =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , booktitle =. 2022 , url =
2022
-
[53]
Large Language Models are Zero-Shot Reasoners , booktitle =
Takeshi Kojima and Shixiang Shane Gu and Machel Reid and Yutaka Matsuo and Yusuke Iwasawa , editor =. Large Language Models are Zero-Shot Reasoners , booktitle =. 2022 , url =
2022
-
[54]
Le and Ed H
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc V. Le and Ed H. Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[55]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , booktitle =
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Tom Griffiths and Yuan Cao and Karthik Narasimhan , editor =. Tree of Thoughts: Deliberate Problem Solving with Large Language Models , booktitle =. 2023 , url =
2023
-
[56]
Le and Denny Zhou and Xinyun Chen , title =
Chengrun Yang and Xuezhi Wang and Yifeng Lu and Hanxiao Liu and Quoc V. Le and Denny Zhou and Xinyun Chen , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[57]
The Eleventh International Conference on Learning Representations,
Yongchao Zhou and Andrei Ioan Muresanu and Ziwen Han and Keiran Paster and Silviu Pitis and Harris Chan and Jimmy Ba , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[58]
The Twelfth International Conference on Learning Representations , year=
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author=. The Twelfth International Conference on Learning Representations , year=
-
[59]
Differentiation
TextGrad: Automatic "Differentiation" via Text , author=. 2024 , eprint=
2024
-
[60]
Yang Liu and Dan Iter and Yichong Xu and Shuohang Wang and Ruochen Xu and Chenguang Zhu , editor =. G-Eval:. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.153 , timestamp =
-
[61]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =
Lianmin Zheng and Wei. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =. 2023 , url =
2023
-
[62]
2023 , eprint=
Holistic Evaluation of Language Models , author=. 2023 , eprint=
2023
-
[63]
2022 , eprint=
Constitutional AI: Harmlessness from AI Feedback , author=. 2022 , eprint=
2022
-
[64]
Manning and Stefano Ermon and Chelsea Finn , editor =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , booktitle =. 2023 , url =
2023
-
[65]
Yoshua Bengio and J. Curriculum learning , booktitle =. 2009 , url =. doi:10.1145/1553374.1553380 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.