Redesigning Regularization for Effective Policy Smoothing
Pith reviewed 2026-06-27 06:57 UTC · model grok-4.3
The pith
Redesigning regularization by fixing three theory-implementation gaps enables effective global Lipschitz smoothing of reinforcement learning policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the original regularization's inadequate smoothing arises from three specific discrepancies between its theoretical formulation and its implementation, and that remedies addressing these discrepancies yield a modified regularization capable of achieving the intended global Lipschitz continuity; the result is smoother policies that also improve task performance and confer robustness against abrupt velocity command changes during sim-to-real deployment on a quadruped robot.
What carries the argument
The modified regularization term that enforces global Lipschitz continuity after correcting three identified theory-implementation discrepancies.
If this is right
- Policies achieve smoother motion while control performance improves or stays at least as high.
- Smoothness from the redesigned regularization confers robustness to abrupt changes in target velocity commands during sim-to-real transfer.
- The same redesign works across multiple reinforcement learning tasks and algorithms.
- Smoother policies can be obtained directly from training rather than through separate post-processing steps.
Where Pith is reading between the lines
- The same three-discrepancy diagnosis could be applied to other regularizers that aim for global properties but are implemented locally.
- Extending the approach to additional robot morphologies beyond quadrupeds would test whether the robustness benefit generalizes.
- If the remedies preserve expressiveness as claimed, the method might reduce reliance on action filtering or smoothing layers in deployed controllers.
Load-bearing premise
The original regularization's insufficient smoothing stems primarily from three identifiable implementation discrepancies with theory rather than an inherent tradeoff that cannot be resolved.
What would settle it
A controlled comparison in which the modified regularization is applied to the same tasks and algorithms yet produces no measurable increase in policy smoothness or no gain in robustness to sudden velocity changes relative to the original implementation.
Figures

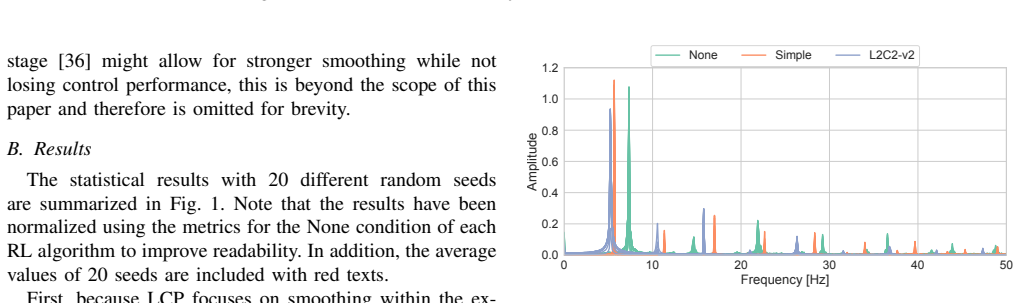
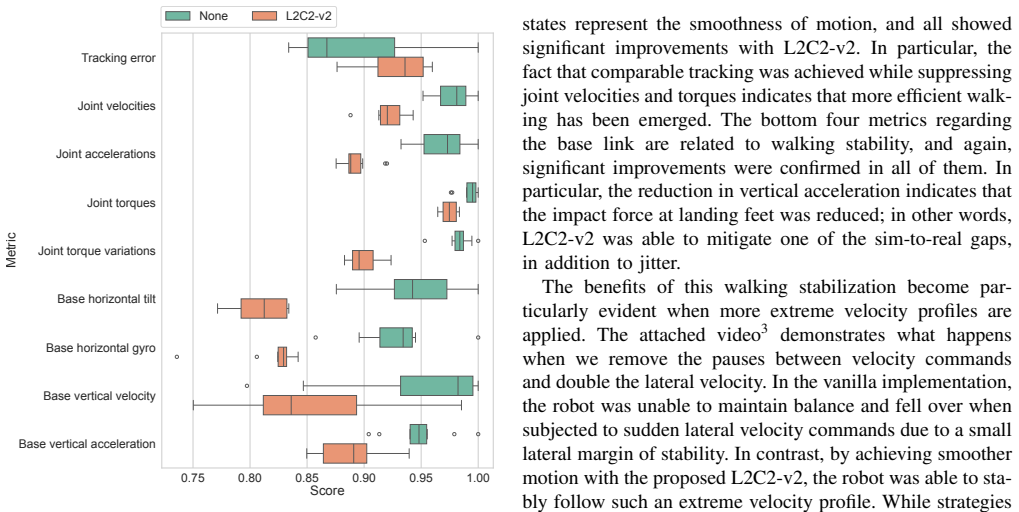
read the original abstract
This paper proposes a novel regularization design to effectively smooth policy functions in reinforcement learning. While regularization that enhances ``global'' Lipschitz continuity was initially considered, it has been limited to ``local'' Lipschitz continuity due to a tradeoff between smoothness and expressiveness. However, it has become apparent that the original implementation is cumbersome and does not provide sufficient smoothing, leading to a preference for simpler implementations. This stems from a discrepancy between theory and implementation, and a more appropriate implementation can expect to facilitate smoothing. Therefore, this paper identifies three reasons why the original implementation does not function adequately and provide remedies for them. This modified regularization performs well across multiple tasks and algorithms, successfully achieving smooth motion while improving control performance. Furthermore, by applying it to sim-to-real reinforcement learning for a quadruped robot, it is demonstrated that smooth motion provides robustness against sudden changes in target velocity commands.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the original regularization approach for enforcing global Lipschitz continuity in RL policies fails to deliver sufficient smoothing due to three specific implementation discrepancies with theory. It identifies these issues, proposes targeted remedies to restore the intended smoothness-expressiveness balance, and validates the modified regularization through experiments on multiple tasks and algorithms, plus a sim-to-real quadruped robot demonstration showing robustness to sudden velocity command changes.
Significance. If the empirical validation holds with proper metrics and controls, the work could provide a practical implementation fix for policy smoothing in RL, with potential benefits for stable real-world robotic control and sim-to-real transfer where smoothness aids robustness.
major comments (2)
- [Abstract] Abstract: The assertion that the modified regularization 'performs well across multiple tasks and algorithms' and 'improves control performance' is presented without any quantitative metrics, baselines, statistical analysis, or error bars; this leaves the central empirical claim unsupported in the visible description and requires explicit data in the results section to substantiate.
- [Section identifying the three reasons] Section identifying the three reasons: The attribution of insufficient smoothing specifically to the three implementation discrepancies lacks a formal derivation or counter-example showing how each discrepancy quantitatively violates the global Lipschitz property (as opposed to other possible causes such as hyperparameter choices); without this, the causal link to the proposed remedies remains unverified.
minor comments (2)
- [Experiments] Ensure all experimental claims include specific numerical results, comparison tables, and ablation studies isolating the effect of each remedy.
- [Throughout] Clarify notation for the regularization terms and any modified loss functions to avoid ambiguity between the original and redesigned versions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the modified regularization 'performs well across multiple tasks and algorithms' and 'improves control performance' is presented without any quantitative metrics, baselines, statistical analysis, or error bars; this leaves the central empirical claim unsupported in the visible description and requires explicit data in the results section to substantiate.
Authors: We agree that the abstract would be strengthened by explicit quantitative support. The results section already reports performance metrics, baselines, and error bars across tasks and algorithms. We will revise the abstract to include key quantitative findings (e.g., average reward improvements and smoothness metrics with statistical measures) drawn directly from those results. revision: yes
-
Referee: [Section identifying the three reasons] Section identifying the three reasons: The attribution of insufficient smoothing specifically to the three implementation discrepancies lacks a formal derivation or counter-example showing how each discrepancy quantitatively violates the global Lipschitz property (as opposed to other possible causes such as hyperparameter choices); without this, the causal link to the proposed remedies remains unverified.
Authors: The three discrepancies were identified by comparing the original implementation against the precise conditions required for global Lipschitz continuity in the theory. While the current text emphasizes empirical outcomes, we acknowledge that an explicit derivation or counter-example would clarify the causal role of each discrepancy versus hyperparameter effects. We will add a short formal illustration and controlled ablation in the revised section to make this link explicit. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper identifies three implementation discrepancies between theory and prior regularization methods, proposes targeted remedies, and validates them empirically across tasks, algorithms, and a sim-to-real quadruped experiment. No equations, derivations, or load-bearing steps are shown that reduce by construction to fitted inputs, self-definitions, or self-citation chains; the contribution rests on external empirical benchmarks and independent analysis of discrepancies rather than renaming or re-deriving its own premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction. MIT press, 2018
2018
-
[2]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on robot learning. PMLR, 2022, pp. 91–100
2022
-
[3]
How simulation helps autonomous driving: A survey of sim2real, digital twins, and parallel intelligence,
X. Hu, S. Li, T. Huang, B. Tang, R. Huai, and L. Chen, “How simulation helps autonomous driving: A survey of sim2real, digital twins, and parallel intelligence,”IEEE Transactions on Intelligent V ehicles, vol. 9, no. 1, pp. 593–612, 2023
2023
-
[4]
Real-world humanoid locomotion with reinforcement learning,
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath, “Real-world humanoid locomotion with reinforcement learning,”Science Robotics, vol. 9, no. 89, p. eadi9579, 2024
2024
-
[5]
Regularizing action policies for smooth control with reinforcement learning,
S. Mysore, B. Mabsout, R. Mancuso, and K. Saenko, “Regularizing action policies for smooth control with reinforcement learning,” in IEEE International Conference on Robotics and Automation. IEEE, 2021, pp. 1810–1816
2021
-
[6]
Regularisation of neural networks by enforcing lipschitz continuity,
H. Gouk, E. Frank, B. Pfahringer, and M. J. Cree, “Regularisation of neural networks by enforcing lipschitz continuity,”Machine Learning, vol. 110, no. 2, pp. 393–416, 2021
2021
-
[7]
How to train your quadrotor: A framework for consistently smooth and respon- sive flight control via reinforcement learning,
S. Mysore, B. Mabsout, K. Saenko, and R. Mancuso, “How to train your quadrotor: A framework for consistently smooth and respon- sive flight control via reinforcement learning,”ACM Transactions on Cyber-Physical Systems, vol. 5, no. 4, pp. 1–24, 2021
2021
-
[8]
Sim-to-real learning of all common bipedal gaits via periodic reward composition,
J. Siekmann, Y . Godse, A. Fern, and J. Hurst, “Sim-to-real learning of all common bipedal gaits via periodic reward composition,” inIEEE international conference on robotics and automation. IEEE, 2021, pp. 7309–7315
2021
-
[9]
Lipsnet: A smooth and robust neural network with adaptive lipschitz constant for high accuracy optimal control,
X. Song, J. Duan, W. Wang, S. E. Li, C. Chen, B. Cheng, B. Zhang, J. Wei, and X. S. Wang, “Lipsnet: A smooth and robust neural network with adaptive lipschitz constant for high accuracy optimal control,” in International Conference on Machine Learning. PMLR, 2023, pp. 32 253–32 272
2023
-
[10]
L2C2: Locally lipschitz continuous constraint towards stable and smooth reinforcement learning,
T. Kobayashi, “L2C2: Locally lipschitz continuous constraint towards stable and smooth reinforcement learning,” inIEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2022, pp. 4032– 4039
2022
-
[11]
Enhancing control policy smoothness by aligning actions with predictions from preceding states,
K. Kwak and H. Hwang, “Enhancing control policy smoothness by aligning actions with predictions from preceding states,”arXiv preprint arXiv:2601.18479, 2026
-
[12]
Learning humanoid standing-up control across diverse postures,
T. Huang, J. Ren, H. Wang, Z. Wang, Q. Ben, M. Wen, X. Chen, J. Li, and J. Pang, “Learning humanoid standing-up control across diverse postures,” inRobotics: Science and Systems, 2025
2025
-
[13]
Towards adaptable humanoid control via adaptive motion tracking,
T. Huang, H. Wang, J. Ren, K. Yin, Z. Wang, X. Chen, F. Jia, W. Zhang, J. Long, J. Wang, and J. Pang, “Towards adaptable humanoid control via adaptive motion tracking,” inIEEE International Conference on Robotics and Automation, 2026
2026
-
[14]
Agile: A comprehensive workflow for humanoid loco-manipulation learning, 2026
H. Zhao, R. Cathomen, L. Gulich, W. Liu, E. A. Ongan, M. Lin, S. Jain, S. Pouya, and Y . Chang, “Agile: A comprehensive work- flow for humanoid loco-manipulation learning,”arXiv preprint arXiv:2603.20147, 2026
-
[15]
Mastering diverse, unknown, and cluttered tracks for robust vision-based drone racing,
F. Yu, Y . Su, Y . Hu, Y . Deng, L. Zhang, and D. Zou, “Mastering diverse, unknown, and cluttered tracks for robust vision-based drone racing,”IEEE Robotics and Automation Letters, vol. 11, no. 2, pp. 2090–2097, 2026
2090
-
[16]
Gradient- based regularization for action smoothness in robotic control with reinforcement learning,
I. Lee, H.-G. Cao, C.-T. Dao, Y .-C. Chen, and I.-C. Wu, “Gradient- based regularization for action smoothness in robotic control with reinforcement learning,” inIEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2024, pp. 603–610
2024
-
[17]
H. A. David and H. N. Nagaraja,Order statistics. John Wiley & Sons, 2004
2004
-
[18]
Non-negative monte carlo estimation of f-divergences,
F. Nielsen, “Non-negative monte carlo estimation of f-divergences,” 2020
2020
-
[19]
On tilted losses in machine learning: Theory and applications,
T. Li, A. Beirami, M. Sanjabi, and V . Smith, “On tilted losses in machine learning: Theory and applications,”Journal of Machine Learning Research, vol. 24, no. 142, pp. 1–79, 2023
2023
-
[20]
Smooth tchebycheff scalarization for multi-objective optimization,
X. Lin, X. Zhang, Z. Yang, F. Liu, Z. Wang, and Q. Zhang, “Smooth tchebycheff scalarization for multi-objective optimization,” inInterna- tional Conference on Machine Learning. PMLR, 2024, pp. 30 479– 30 509
2024
-
[21]
Benchmark- ing smoothness and reducing high-frequency oscillations in continuous control policies,
G. Christmann, Y .-S. Luo, H. Mandala, and W.-C. Chen, “Benchmark- ing smoothness and reducing high-frequency oscillations in continuous control policies,” inIEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2024, pp. 627–634
2024
-
[22]
Learning smooth time-varying linear policies with an action jacobian penalty,
Z. Xie, K. Karol, and J. Hodgins, “Learning smooth time-varying linear policies with an action jacobian penalty,”arXiv preprint arXiv:2602.18312, 2026
-
[23]
On the continuity and smoothness of the value function in reinforcement learning and optimal control,
H. Harder and S. Peitz, “On the continuity and smoothness of the value function in reinforcement learning and optimal control,” inIEEE Conference on Decision and Control. IEEE, 2024, pp. 1935–1940
2024
-
[24]
Stabilizing the q- gradient field for policy smoothness in actor-critic,
J. W. Lee, K. Kwak, D. Kim, and H. Hwang, “Stabilizing the q- gradient field for policy smoothness in actor-critic,” inInternational Conference on Machine Learning. PMLR, 2026
2026
-
[25]
Robust locomotion policy with adaptive lipschitz constraint for legged robots,
Y . Zhang, B. Nie, and Y . Gao, “Robust locomotion policy with adaptive lipschitz constraint for legged robots,”IEEE Robotics and Automation Letters, vol. 10, no. 1, pp. 272–279, 2025
2025
-
[26]
Smooth filtering neural network for reinforcement learning,
W. Wang, J. Duan, X. Song, L. Xiao, L. Chen, Y . Wang, B. Cheng, and S. E. Li, “Smooth filtering neural network for reinforcement learning,” IEEE Transactions on Intelligent V ehicles, 2024
2024
-
[27]
Ode-based smoothing neural network for rein- forcement learning tasks,
Y . Wang, W. Wang, X. Song, T. Liu, Y . Yin, L. Chen, L. Wang, J. Duan, and S. Li, “Ode-based smoothing neural network for rein- forcement learning tasks,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 44 564–44 583
2025
-
[28]
Lipsnet++: Unifying filter and controller into a policy network,
X. Song, L. Chen, T. Liu, W. Wang, Y . Wang, S. Qin, Y . Ma, J. Duan, and S. E. Li, “Lipsnet++: Unifying filter and controller into a policy network,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 56 204–56 241
2025
-
[29]
Learning smooth humanoid locomotion through lipschitz-constrained policies,
Z. Chen, X. He, Y .-J. Wang, Q. Liao, Y . Ze, Z. Li, S. S. Sastry, J. Wu, K. Sreenath, S. Gupta,et al., “Learning smooth humanoid locomotion through lipschitz-constrained policies,” inIEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2025, pp. 4743– 4750
2025
-
[30]
Neural networks and the bias/variance dilemma,
S. Geman, E. Bienenstock, and R. Doursat, “Neural networks and the bias/variance dilemma,”Neural computation, vol. 4, no. 1, pp. 1–58, 1992
1992
-
[31]
Optimistic reinforcement learning by forward kullback–leibler divergence optimization,
T. Kobayashi, “Optimistic reinforcement learning by forward kullback–leibler divergence optimization,”Neural Networks, vol. 152, pp. 169–180, 2022
2022
-
[32]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in International Conference on Learning Representations, 2014
2014
-
[33]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goul ˜ao, A. Kallinteris, M. Krimmel, A. KG,et al., “Gymnasium: A standard interface for reinforcement learning environments,”arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Pseudo-quantized actor-critic algorithm for robustness to noisy temporal difference error,
T. Kobayashi, “Pseudo-quantized actor-critic algorithm for robustness to noisy temporal difference error,”arXiv preprint arXiv:2604.01613, 2026
-
[35]
Flexible Empowerment at Reasoning with Extended Best-of-N Sampling
——, “Flexible empowerment at reasoning with extended best-of-n sampling,”arXiv preprint arXiv:2604.15614, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Hyperparameters in rein- forcement learning and how to tune them,
T. Eimer, M. Lindauer, and R. Raileanu, “Hyperparameters in rein- forcement learning and how to tune them,” inInternational conference on machine learning. PMLR, 2023, pp. 9104–9149
2023
-
[37]
Rsl-rl: A learning library for robotics research,
C. Schwarke, M. Mittal, N. Rudin, D. Hoeller, and M. Hutter, “Rsl-rl: A learning library for robotics research,”arXiv preprint arXiv:2509.10771, 2025
-
[38]
Rough terrain navigation for a quadruped robot using deep rein- forcement learning-based blind locomotion control and a stuck-escape strategy,
K. Irie, T. Yoshida, T. Matsuzawa, T. Suzuki, Y . Hara, and M. Tomono, “Rough terrain navigation for a quadruped robot using deep rein- forcement learning-based blind locomotion control and a stuck-escape strategy,”Advanced Robotics, vol. 39, no. 18, pp. 1182–1198, 2025
2025
-
[39]
Amor: Adaptive character control through multi-objective reinforcement learning,
L. N. Alegre, A. Serifi, R. Grandia, D. M ¨uller, E. Knoop, and M. B¨acher, “Amor: Adaptive character control through multi-objective reinforcement learning,” inSpecial Interest Group on Computer Graphics and Interactive Techniques Conference, 2025, pp. 1–11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.