PolyAlign: Conditional Human-Distribution Alignment
Pith reviewed 2026-06-27 06:37 UTC · model grok-4.3
The pith
Language models should match context-specific human response distributions rather than a single global style.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
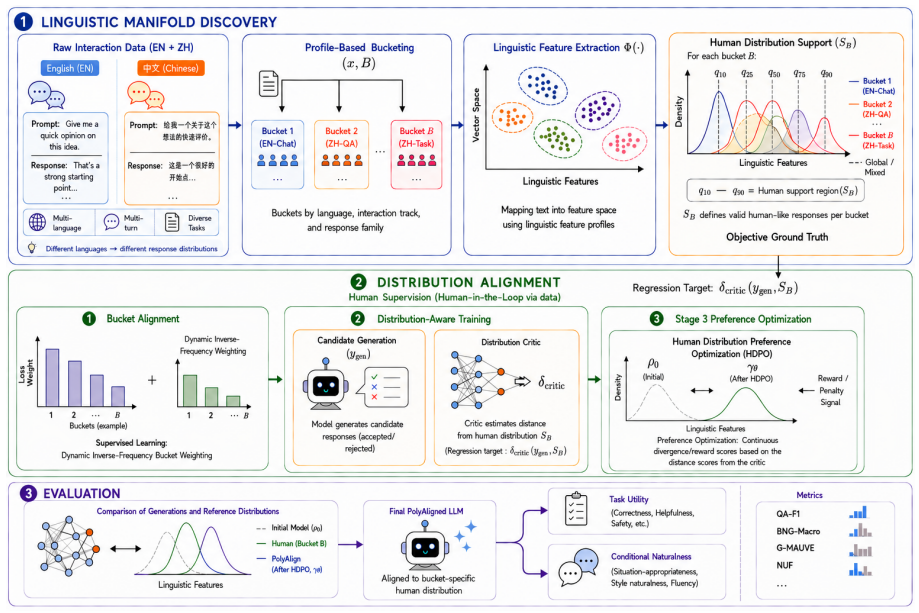
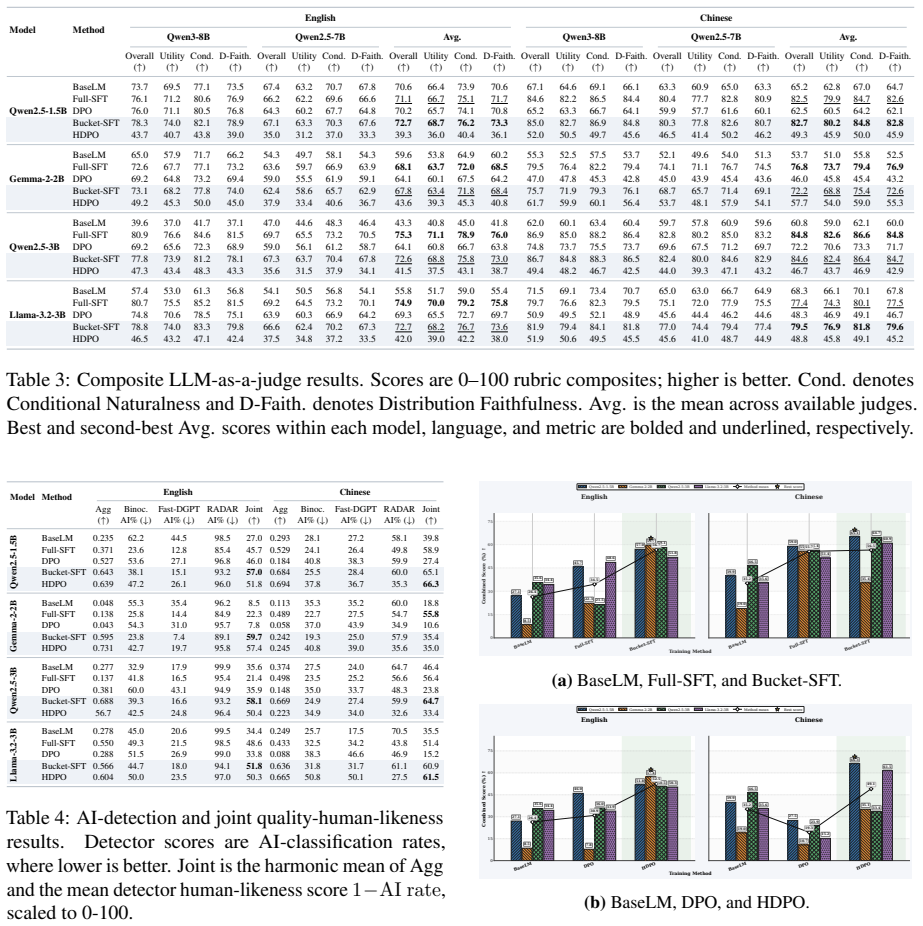
PolyAlign organizes bilingual interaction data into bucket-specific human reference distributions defined by language, interaction track, response family, and length. It combines Bucket-Aware SFT, which balances optimization across buckets, with Human-Distribution Preference Optimization that regularizes preference learning using critic-estimated distance to the bucket-specific human support. This produces models that improve conditional naturalness and distributional faithfulness across English and Chinese single- and multi-turn settings while preserving competitive task utility.
What carries the argument
Bucket-specific human reference distributions (defined by language, interaction track, response family, and length) together with Human-Distribution Preference Optimization (HDPO) that uses critic-estimated distance to those distributions as a regularization signal.
If this is right
- Models trained this way reproduce human response variation across languages and interaction types instead of converging to one style.
- Regularization toward bucket-specific human supports increases distributional faithfulness without harming average task performance.
- Post-training objectives can be made conditional on observable context attributes rather than global.
- Bilingual settings benefit when buckets explicitly separate English and Chinese distributions.
Where Pith is reading between the lines
- The same bucketing logic could be applied to additional languages or modalities if comparable human reference data exist.
- Explicit bucket definitions may reduce unwanted homogenization effects that appear in globally aligned models.
- Extending the bucket criteria to include domain or user intent could further sharpen the alignment signal.
Load-bearing premise
That bucket-specific human reference distributions can be reliably built from data and that critic-estimated distance to those distributions supplies a stable regularization signal during preference optimization.
What would settle it
An evaluation in which PolyAlign fails to raise conditional naturalness or distributional faithfulness scores relative to standard SFT plus preference optimization on the same bilingual single- and multi-turn test suite, or in which task utility drops by more than a small margin.
Figures


read the original abstract
Post-training methods such as supervised fine-tuning (SFT) and preference optimization typically align language models toward a single global assistant behavior. While effective for improving average helpfulness, this can suppress the natural variation of human responses across languages, tasks, and dialogue settings. We study this problem as conditional human-distribution alignment: models should match the human response distribution appropriate to the current interaction context, rather than a universal response style. We introduce PolyAlign, a distribution-aware alignment framework that organizes bilingual interaction data into bucket-specific human reference distributions defined by language, interaction track, response family, and length. PolyAlign combines Bucket-Aware SFT, which balances optimization across heterogeneous buckets, with Human-Distribution Preference Optimization (HDPO), which regularizes preference learning using critic-estimated distance to bucket-specific human support. Across a bilingual evaluation suite covering English and Chinese single- and multi-turn settings, PolyAlign improves conditional naturalness and distributional faithfulness while preserving competitive task utility. The results suggest that post-training should move beyond global alignment objectives toward interaction-aware alignment with human response distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PolyAlign as a distribution-aware post-training framework for conditional human-distribution alignment. It partitions bilingual (English/Chinese) interaction data into bucket-specific human reference distributions defined by language, interaction track, response family, and length; combines Bucket-Aware SFT (to balance optimization across buckets) with Human-Distribution Preference Optimization (HDPO) that regularizes preference learning via critic-estimated distance to the bucket-specific human support; and reports gains in conditional naturalness and distributional faithfulness across single- and multi-turn settings while preserving task utility.
Significance. If the empirical claims hold after proper validation of the bucket construction and critic signal, the work would be significant for shifting post-training objectives from global single-style alignment toward context- and language-aware matching of human response distributions, potentially yielding more natural multilingual dialogue models.
major comments (2)
- [HDPO and bucket construction sections] The load-bearing assumption is that bucket-specific human reference distributions (defined by language + track + response family + length) can be reliably estimated from data and that critic distance supplies a stable regularization signal in HDPO. The manuscript must demonstrate sufficient bucket occupancy, low label noise in response-family annotations, and independent validation of the critic against held-out human judgments; without these, reported gains in conditional naturalness could be artifacts of bucket construction rather than evidence of successful distributional alignment.
- [Abstract and Evaluation sections] The abstract asserts performance improvements in conditional naturalness and distributional faithfulness but supplies no experimental details, baselines, metrics, statistical tests, or ablation results. The full manuscript must include these (including quantitative tables and significance tests) so that the central claim can be verified against the data.
minor comments (1)
- [Introduction and Method] Notation for 'response family' and 'interaction track' should be defined explicitly on first use with an example to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. We address each major comment below with clarifications and commitments to strengthen the manuscript where needed.
read point-by-point responses
-
Referee: [HDPO and bucket construction sections] The load-bearing assumption is that bucket-specific human reference distributions (defined by language + track + response family + length) can be reliably estimated from data and that critic distance supplies a stable regularization signal in HDPO. The manuscript must demonstrate sufficient bucket occupancy, low label noise in response-family annotations, and independent validation of the critic against held-out human judgments; without these, reported gains in conditional naturalness could be artifacts of bucket construction rather than evidence of successful distributional alignment.
Authors: We agree these validations are necessary to substantiate the core assumptions. The manuscript provides initial bucket occupancy statistics and annotation procedures, but does not include the full set of requested analyses (e.g., inter-annotator agreement metrics or critic correlation with held-out judgments). In the revised version we will add a dedicated subsection with occupancy tables, label noise quantification, and independent critic validation results against human ratings to rule out construction artifacts. revision: yes
-
Referee: [Abstract and Evaluation sections] The abstract asserts performance improvements in conditional naturalness and distributional faithfulness but supplies no experimental details, baselines, metrics, statistical tests, or ablation results. The full manuscript must include these (including quantitative tables and significance tests) so that the central claim can be verified against the data.
Authors: The Evaluation section of the full manuscript already presents the requested elements: quantitative tables comparing against baselines (SFT, DPO), metrics for conditional naturalness and distributional faithfulness, ablation studies, and statistical significance testing. The abstract is intentionally concise and does not enumerate these details. We will add a brief reference to the evaluation protocol in the abstract and ensure all tables and tests are prominently cross-referenced. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces PolyAlign as a framework combining Bucket-Aware SFT and HDPO regularization based on bucket-specific human reference distributions. No equations, derivations, or self-citations appear in the abstract or described content that reduce any claimed prediction or result to its inputs by construction. The central claims rest on empirical improvements in naturalness and faithfulness across bilingual settings rather than self-definitional or fitted-input mechanisms. This aligns with the absence of load-bearing self-referential steps, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[3]
International Conference on Learning Representations , year=
Multitask Prompted Training Enables Zero-Shot Task Generalization , author=. International Conference on Learning Representations , year=
-
[4]
Journal of Machine Learning Research , volume=
Scaling Instruction-Finetuned Language Models , author=. Journal of Machine Learning Research , volume=
-
[5]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Constitutional
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and others , journal=. Constitutional
-
[9]
Advances in Neural Information Processing Systems , volume=
K. Advances in Neural Information Processing Systems , volume=
-
[10]
Zhou, Chunting and Liu, Pengfei and Xu, Puxin and Iyer, Srinivasan and Sun, Jiao and Mao, Yuning and Ma, Xuezhe and Efrat, Avia and Yu, Ping and Yu, Lili and others , journal=
-
[11]
Advances in Neural Information Processing Systems , volume=
Deep Reinforcement Learning from Human Preferences , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Learning to Summarize with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in Neural Information Processing Systems , volume=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Yuan, Zheng and Yuan, Hongyi and Tan, Chuanqi and Wang, Wei and Huang, Songfang and Huang, Fei , journal=
-
[15]
Hong, Jiwoo and Lee, Noah and Thorne, James , booktitle=
-
[16]
Meng, Yu and Xia, Mengzhou and Chen, Danqi , journal=
-
[17]
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , journal=
-
[18]
International Conference on Machine Learning , pages=
Pretraining Language Models with Human Preferences , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[19]
Dong, Yi and Wang, Zhilin and Sreedhar, Makesh and Wu, Xianchao and Kuchaiev, Oleksii , booktitle=
-
[20]
Wang, Zhilin and Dong, Yi and Zeng, Jiaqi and Adams, Virginia and Sreedhar, Makesh Narsimhan and Egert, Daniel and Delalleau, Olivier and Scowcroft, Jane and Kant, Neel and Swope, Aidan and others , booktitle=
-
[21]
and Sreedhar, Makesh Narsimhan and Kuchaiev, Oleksii , journal=
Wang, Zhilin and Dong, Yi and Delalleau, Olivier and Zeng, Jiaqi and Shen, Gerald and Egert, Daniel and Zhang, Jimmy J. and Sreedhar, Makesh Narsimhan and Kuchaiev, Oleksii , journal=
-
[22]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
On Diversified Preferences of Large Language Model Alignment , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[23]
and Xiong, Caiming and Socher, Richard , journal=
Keskar, Nitish Shirish and McCann, Bryan and Varshney, Lav R. and Xiong, Caiming and Socher, Richard , journal=
-
[24]
International Conference on Learning Representations , year=
Plug and Play Language Models: A Simple Approach to Controlled Text Generation , author=. International Conference on Learning Representations , year=
-
[25]
Krause, Ben and Gotmare, Akhilesh Deepak and McCann, Bryan and Keskar, Nitish Shirish and Joty, Shafiq and Socher, Richard and Rajani, Nazneen Fatema , booktitle=
-
[26]
Yang, Kevin and Klein, Dan , booktitle=
-
[27]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[28]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[29]
Entropic Distribution Matching in Supervised Fine-Tuning of
Li, Ziniu and Chen, Congliang and Xu, Tian and Qin, Zeyu and Xiao, Jiancong and Sun, Ruoyu and Luo, Zhi-Quan , booktitle=. Entropic Distribution Matching in Supervised Fine-Tuning of
-
[30]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and others , journal=
-
[32]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[33]
arXiv preprint arXiv:2502.02737 , year=
-
[34]
Spotting
Hans, Abhimanyu and Schwarzschild, Avi and Cherepanova, Valeriia and Kazemi, Hamid and Saha, Aniruddha and Goldblum, Micah and Geiping, Jonas and Goldstein, Tom , journal=. Spotting
-
[35]
Bao, Guangsheng and Zhao, Yanbin and Teng, Zhiyang and Yang, Linyi and Zhang, Yue , booktitle=. Fast-
-
[36]
and Finn, Chelsea , booktitle=
Mitchell, Eric and Lee, Yoonho and Khazatsky, Alexander and Manning, Christopher D. and Finn, Chelsea , booktitle=. 2023 , organization=
2023
-
[37]
Hu, Xiaomeng and Chen, Pin-Yu and Ho, Tsung-Yi , journal=
-
[38]
and others , journal=
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and others , journal=. Judging
-
[39]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, and 1 others. 2022 a . Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862
Pith/arXiv arXiv 2022
-
[40]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, and 1 others. 2022 b . Constitutional AI : Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073
Pith/arXiv arXiv 2022
-
[41]
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. 2024. Fast- DetectGPT : Efficient zero-shot detection of machine-generated text via conditional probability curvature. In International Conference on Learning Representations
2024
-
[42]
Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877--1901
2020
-
[43]
Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei
Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems, 30
2017
-
[44]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, and 1 others. 2024. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1--53
2024
-
[45]
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. 2020. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations
2020
-
[46]
Yi Dong, Zhilin Wang, Makesh Sreedhar, Xianchao Wu, and Oleksii Kuchaiev. 2023. SteerLM : Attribute conditioned SFT as an user-steerable alternative to RLHF . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 11275--11288
2023
-
[47]
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. 2024. KTO : Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306
Pith/arXiv arXiv 2024
-
[48]
Gemma Team , Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, L \'e onard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ram \'e , and 1 others. 2024. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118
Pith/arXiv arXiv 2024
-
[49]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[50]
Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2024. Spotting LLMs with binoculars: Zero-shot detection of machine-generated text. arXiv preprint arXiv:2401.12070
arXiv 2024
-
[51]
Jiwoo Hong, Noah Lee, and James Thorne. 2024. ORPO : Monolithic preference optimization without reference model. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11170--11189
2024
-
[52]
Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. 2023. RADAR : Robust AI -text detection via adversarial learning. Advances in Neural Information Processing Systems, 36:15077--15095
2023
-
[53]
Varshney, Caiming Xiong, and Richard Socher
Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, and Richard Socher. 2019. CTRL : A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858
Pith/arXiv arXiv 2019
-
[54]
o pf, Yannic Kilcher, Dimitri von R \
Andreas K \"o pf, Yannic Kilcher, Dimitri von R \"u tte , Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Rich \'a rd Nagyfi, and 1 others. 2023. OpenAssistant conversations: Democratizing large language model alignment. Advances in Neural Information Processing Systems, 36:47669--47681
2023
-
[55]
Bowman, and Ethan Perez
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Vinayak Bhalerao, Christopher Buckley, Jason Phang, Samuel R. Bowman, and Ethan Perez. 2023. Pretraining language models with human preferences. In International Conference on Machine Learning, pages 17506--17533. PMLR
2023
-
[56]
Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, and Nazneen Fatema Rajani. 2021. GeDi : Generative discriminator guided sequence generation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4929--4952
2021
-
[57]
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045--3059
2021
-
[58]
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582--4597
2021
-
[59]
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Ruoyu Sun, and Zhi-Quan Luo. 2024. Entropic distribution matching in supervised fine-tuning of LLMs : Less overfitting and better diversity. In NeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability
2024
-
[60]
Yu Meng, Mengzhou Xia, and Danqi Chen. 2024. SimPO : Simple preference optimization with a reference-free reward. Advances in Neural Information Processing Systems, 37:124198--124235
2024
-
[61]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730--27744
2022
-
[62]
Qwen Team , An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, and 24 others. 2024. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
Pith/arXiv arXiv 2024
-
[63]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36:53728--53741
2023
-
[64]
Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao , Arun Raja, and 1 others
Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao , Arun Raja, and 1 others. 2022. Multitask prompted training enables zero-shot task generalization. In International Conference on Learning Representations
2022
-
[65]
Christiano
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. 2020. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008--3021
2020
-
[66]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. Self-instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484--13508
2023
-
[67]
Zhang, Makesh Narsimhan Sreedhar, and Oleksii Kuchaiev
Zhilin Wang, Yi Dong, Olivier Delalleau, Jiaqi Zeng, Gerald Shen, Daniel Egert, Jimmy J. Zhang, Makesh Narsimhan Sreedhar, and Oleksii Kuchaiev. 2024 a . HelpSteer2 : Open-source dataset for training top-performing reward models. arXiv preprint arXiv:2406.08673
arXiv 2024
-
[68]
Zhilin Wang, Yi Dong, Jiaqi Zeng, Virginia Adams, Makesh Narsimhan Sreedhar, Daniel Egert, Olivier Delalleau, Jane Scowcroft, Neel Kant, Aidan Swope, and 1 others. 2024 b . HelpSteer : Multi-attribute helpfulness dataset for SteerLM . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Huma...
2024
-
[69]
Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M
Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. 2022. Finetuned language models are zero-shot learners. In International Conference on Learning Representations
2022
-
[70]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[71]
Kevin Yang and Dan Klein. 2021. FUDGE : Controlled text generation with future discriminators. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3511--3535
2021
-
[72]
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. 2023. RRHF : Rank responses to align language models with human feedback without tears. Advances in Neural Information Processing Systems, 36:10935--10950
2023
-
[73]
Dun Zeng, Yong Dai, Pengyu Cheng, Longyue Wang, Tianhao Hu, Wanshun Chen, Nan Du, and Zenglin Xu. 2024. On diversified preferences of large language model alignment. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 9194--9210
2024
-
[74]
Xing, and 1 others
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, and 1 others. 2023. Judging LLM -as-a-judge with MT-Bench and chatbot arena. Advances in Neural Information Processing Systems, 36:46595--46623
2023
-
[75]
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, and 1 others. 2023. LIMA : Less is more for alignment. Advances in Neural Information Processing Systems, 36:55006--55021
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.