S-GBT: Smooth Growth Bound Tensor for Certified Robustness Against Word Substitution Attacks in NLP
Pith reviewed 2026-06-27 07:07 UTC · model grok-4.3
The pith
A tensor bounding the Hessian element-wise during training yields up to 23.4% higher certified robustness against word substitution attacks in NLP models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by defining the Smooth Growth Bound Tensor to provide element-wise upper bounds on the Hessian, and regularizing these bounds, one obtains provably tighter certified robustness guarantees against word substitution attacks. The bounds are derived specifically for LSTM and CNN, and the regularization is integrated into the training objective. Experimental results confirm improvements in certified accuracy while maintaining clean performance.
What carries the argument
The Smooth Growth Bound Tensor (S-GBT), an element-wise bound on the model's Hessian that controls the quadratic term in the robustness certificate.
If this is right
- Robustness certificates incorporate both first-order gradient bounds and second-order curvature bounds.
- The regularization can be applied directly during training without modifying the model architecture.
- Certified robust accuracy improves by up to 23.4% on multiple datasets compared to prior first-order methods.
- Clean accuracy stays competitive, showing the method does not trade off nominal performance.
Where Pith is reading between the lines
- This method might be adapted to other attack types if similar bounds can be computed for their perturbation models.
- Lower Hessian bounds could correlate with improved generalization beyond the specific attack considered.
- Future work could combine S-GBT with other defense techniques like adversarial training for compounded benefits.
Load-bearing premise
The theoretical element-wise Hessian bounds are valid and tight enough that minimizing them via regularization produces practically useful certified robustness against word substitutions.
What would settle it
Finding a word substitution where the actual change in model output exceeds the certified bound from the S-GBT, or training with the regularization and observing no gain in certified accuracy on the benchmarks.
Figures
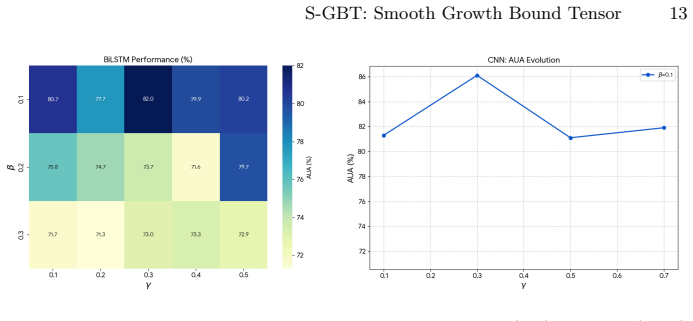
read the original abstract
Despite recent progress in Natural Language Processing (NLP), models remain vulnerable to word substitution attacks. Most existing defenses focus on first order sensitivity and measure how much the output changes when the input is slightly perturbed. However, they ignore how this sensitivity evolves, which is described by curvature. When gradients vary sharply, models can still fail. This paper introduces the Smooth Growth Bound Tensor (S-GBT), a second order method that bounds the Hessian element-wise, for which we provide formal theoretical proofs on the resulting robustness bounds. A regularization term is added during training to minimize these bounds. This yields tighter certified robustness against word substitution attacks. The change in the output under word substitution is bounded by both a linear term and a quadratic term. S-GBT is derived for two architectures: Long Short-Term Memory (LSTM) and Convolutional Neural Networks (CNN). The method is integrated directly into the training objective. Its effectiveness is evaluated on multiple benchmark datasets. The results show that combining first and second order regularization improves certified robust accuracy by up to 23.4% compared to prior methods, while clean accuracy remains competitive. These findings indicate that controlling both the gradient and its variation is a promising direction for building more robust models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Smooth Growth Bound Tensor (S-GBT), a second-order regularization technique that computes element-wise bounds on the Hessian of LSTM and CNN models. These bounds are incorporated into the training objective to produce certified robustness certificates against word-substitution attacks; the certificates combine a first-order linear term with a quadratic term derived from the Hessian bound. Formal proofs are claimed for the resulting robustness guarantees, and experiments on benchmark datasets report up to 23.4% improvement in certified robust accuracy over prior methods while preserving competitive clean accuracy.
Significance. If the claimed element-wise Hessian bounds can be shown to rigorously majorize the output change under discrete embedding-space substitutions, the approach would constitute a meaningful extension of certified robustness methods from first-order sensitivity to curvature control in NLP. The integration of the bound directly into training and the reported empirical gains would be of interest to the certified-defense community.
major comments (2)
- [Theoretical proofs section] Abstract and § on theoretical proofs: the central claim that element-wise bounds on the Hessian yield valid certificates for word-substitution attacks rests on controlling the quadratic remainder term (1/2)δᵀHδ for a discrete jump δ in embedding space. The manuscript must supply an explicit majorant (e.g., via an ∞-norm or Frobenius bound on δ together with the element-wise |H| matrix) rather than treating minimization of |H_ij| as automatically sufficient; without this step the certificate does not necessarily upper-bound |f(x+δ)−f(x)| on the actual attack set.
- [Derivation and regularization section] § on derivation for LSTM/CNN and regularization term: the transition from the element-wise Hessian bound to the final certified radius must be shown to remain valid after the regularization is added; if the regularization parameters appear inside the bound definition itself, the claimed “parameter-free” or independently verifiable nature of the certificate is compromised.
minor comments (2)
- [Abstract] The abstract states a 23.4% gain but does not specify the exact baseline methods, datasets, or attack model used; these details should be stated explicitly in the experimental section.
- [Method section] Notation for the Smooth Growth Bound Tensor should be introduced with a clear definition before its use in the regularization objective.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the detailed major comments. We address each point below. Where the comments identify opportunities for greater explicitness in the proofs and derivations, we agree that revisions will strengthen the manuscript and will incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Theoretical proofs section] Abstract and § on theoretical proofs: the central claim that element-wise bounds on the Hessian yield valid certificates for word-substitution attacks rests on controlling the quadratic remainder term (1/2)δᵀHδ for a discrete jump δ in embedding space. The manuscript must supply an explicit majorant (e.g., via an ∞-norm or Frobenius bound on δ together with the element-wise |H| matrix) rather than treating minimization of |H_ij| as automatically sufficient; without this step the certificate does not necessarily upper-bound |f(x+δ)−f(x)| on the actual attack set.
Authors: We thank the referee for highlighting this step. The theoretical proofs section bounds the quadratic remainder by combining the element-wise Hessian bound with the fact that word-substitution attacks induce discrete changes δ whose magnitude is controlled by the maximum embedding-space distance between substitutable tokens. This yields |½ δᵀ H δ| ≤ ½ ‖δ‖_∞² ⋅ Σ |H_ij|. To make the majorization fully explicit and directly tied to the attack set, we will insert a new lemma (and supporting corollary) that states the precise ∞-norm bound on admissible δ and shows how it produces a valid upper bound on |f(x+δ)−f(x)|. This addition does not change the claimed guarantees but renders the connection to the discrete attack set transparent. revision: yes
-
Referee: [Derivation and regularization section] § on derivation for LSTM/CNN and regularization term: the transition from the element-wise Hessian bound to the final certified radius must be shown to remain valid after the regularization is added; if the regularization parameters appear inside the bound definition itself, the claimed “parameter-free” or independently verifiable nature of the certificate is compromised.
Authors: The regularization term penalizes large element-wise Hessian entries during training but does not alter the definition of the bound used at certification time. After training, the certified radius is computed directly from the realized element-wise Hessian bounds of the final model; the regularization hyperparameters λ do not enter the certificate expression. Consequently, verification remains independent of training choices and can be performed by any party given only the trained weights. We will add a short clarifying paragraph (and a remark in the certification algorithm) that separates the training objective from the post-training bound evaluation to eliminate any potential ambiguity. revision: yes
Circularity Check
No significant circularity; bounds and certificates derived independently of fitted regularization values
full rationale
The paper states that formal theoretical proofs establish element-wise Hessian bounds that yield linear-plus-quadratic certificates for word-substitution deltas, with a separate regularization term added to training to minimize those bounds. Certified robust accuracy is then measured on external benchmark datasets after training. No equation or claim reduces the certificate itself to a quantity defined solely by the regularization parameters; the proofs are presented as self-contained derivations for LSTM and CNN architectures. No self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided text. The derivation chain therefore remains independent of its own fitted inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization coefficient
axioms (1)
- domain assumption The models (LSTM, CNN) are twice continuously differentiable so that the Hessian exists and can be bounded element-wise.
invented entities (1)
-
Smooth Growth Bound Tensor (S-GBT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (2018)
Alzantot, M., Sharma, Y., Elgohary, A., Ho, B.J., Srivastava, M., Chang, K.W.: Generating natural language adversarial examples. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (2018)
2018
-
[2]
In: Findings of the Association for Computational Linguistics: ACL 2025
Bouri, M., Saoud, A.: Bridging robustness and generalization against word substi- tution attacks in nlp via the growth bound matrix approach. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 12118–12137 (2025)
2025
-
[3]
In: 9th International Conference on Learning Representations (2021) 16 M
Dong, X., Luu, A.T., Ji, R., Liu, H.: Towards robustness against natural language word substitutions. In: 9th International Conference on Learning Representations (2021) 16 M. Bouri et al
2021
-
[4]
In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (2018)
Ebrahimi, J., Rao, A., Lowd, D., Dou, D.: HotFlip: White-box adversarial ex- amples for text classification. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (2018)
2018
-
[5]
Eger, S., Benz, Y.: From hero to zéroe: A benchmark of low-level adversarial at- tacks. In: Proceedings of the 1st conference of the Asia-Pacific chapter of the as- sociation for computational linguistics and the 10th international joint conference on natural language processing. pp. 786–803 (2020)
2020
-
[6]
In: Korhonen, A., Traum, D., Màrquez, L
Ge, T., Zhang, X., Wei, F., Zhou, M.: Automatic grammatical error correction for sequence-to-sequence text generation: An empirical study. In: Korhonen, A., Traum, D., Màrquez, L. (eds.) Proceedings of the 57th Annual Meeting of the As- sociation for Computational Linguistics. pp. 6059–6064. Association for Compu- tational Linguistics, Florence, Italy (Ju...
-
[7]
In: 3rd International Conference on Learning Representations (2015)
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. In: 3rd International Conference on Learning Representations (2015)
2015
-
[8]
Neural computation 9(8), 1735–1780 (1997)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation 9(8), 1735–1780 (1997)
1997
-
[9]
In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confer- ence on Natural Language Processing (2019)
Huang, P.S., Stanforth, R., Welbl, J., Dyer, C., Yogatama, D., Gowal, S., Dvi- jotham, K., Kohli, P.: Achieving verified robustness to symbol substitutions via interval bound propagation. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confer- ence on Natural Language Processing (2019)
2019
-
[10]
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Lan- guage Processing
Ivgi, M., Berant, J.: Achieving model robustness through discrete adversarial train- ing. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Lan- guage Processing. pp. 1529–1544 (2021)
2021
-
[11]
In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing
Jia, R., Raghunathan, A., Göksel, K., Liang, P.: Certified robustness to adversarial word substitutions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. pp. 4127–4140 (2019)
2019
-
[12]
CoRR abs/1408.5882(2014), http://arxiv.org/abs/1408.5882
Kim, Y.: Convolutional neural networks for sentence classification. CoRR abs/1408.5882(2014), http://arxiv.org/abs/1408.5882
Pith/arXiv arXiv 2014
-
[13]
The Journal of Supercomput- ing81(15), 1–45 (2025)
Kissami, I., Basmadjian, R., Chakir, O., Abid, M.R.: Toubkal: a high-performance supercomputer powering scientific research in africa. The Journal of Supercomput- ing81(15), 1–45 (2025)
2025
-
[14]
arXiv preprint arXiv:2004.14543 (2020)
Li, L., Qiu, X.: Tavat: Token-aware virtual adversarial training for language un- derstanding. arXiv preprint arXiv:2004.14543 (2020)
arXiv 2004
-
[15]
In: The 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (2011)
Maas, A.L., Daly, R.E., Pham, P.T., Huang, D., Ng, A.Y., Potts, C.: Learning word vectors for sentiment analysis. In: The 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (2011)
2011
-
[16]
In: 6th International Conference on Learning Representations (2018)
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learn- ing models resistant to adversarial attacks. In: 6th International Conference on Learning Representations (2018)
2018
-
[17]
In: Thirty-Fifth AAAI Conference on Artificial Intelligence (2021)
Maheshwary, R., Maheshwary, S., Pudi, V.: Generating natural language attacks in a hard label black box setting. In: Thirty-Fifth AAAI Conference on Artificial Intelligence (2021)
2021
-
[18]
In: Proceedings of the 2022 ACM on Asia Conference on Computer and Communications Security
Pei, W., Yue, C.: Generating content-preserving and semantics-flipping adversarial text. In: Proceedings of the 2022 ACM on Asia Conference on Computer and Communications Security. pp. 975–989 (2022)
2022
-
[19]
In: Proceedings of the 57th Conference of the Association for Computational Linguistics
Pruthi, D., Dhingra, B., Lipton, Z.C.: Combating adversarial misspellings with robust word recognition. In: Proceedings of the 57th Conference of the Association for Computational Linguistics. pp. 5582–5591 (2019) S-GBT: Smooth Growth Bound Tensor 17
2019
-
[20]
In: Korhonen, A., Traum, D., Màrquez, L
Pruthi, D., Dhingra, B., Lipton, Z.C.: Combating adversarial misspellings with robust word recognition. In: Korhonen, A., Traum, D., Màrquez, L. (eds.) Pro- ceedings of the 57th Annual Meeting of the Association for Computational Lin- guistics. pp. 5582–5591. Association for Computational Linguistics, Florence, Italy (Jul 2019). https://doi.org/10.18653/v...
-
[21]
arXiv preprint arXiv:2406.05532 (2024)
Qi, B., Luo, Y., Gao, J., Li, P., Tian, K., Ma, Z., Zhou, B.: Exploring adversarial robustness of deep state space models. arXiv preprint arXiv:2406.05532 (2024)
arXiv 2024
-
[22]
In: Proceedings of the 57th Conference of the Association for Computational Linguistics (2019)
Ren, S., Deng, Y., He, K., Che, W.: Generating natural language adversarial ex- amples through probability weighted word saliency. In: Proceedings of the 57th Conference of the Association for Computational Linguistics (2019)
2019
-
[23]
arXiv preprint arXiv:2310.10844 (2023)
Shayegani, E., Mamun, M.A.A., Fu, Y., Zaree, P., Dong, Y., Abu-Ghazaleh, N.: Survey of vulnerabilities in large language models revealed by adversarial attacks. arXiv preprint arXiv:2310.10844 (2023)
arXiv 2023
-
[24]
In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Song, L., Yu, X., Peng, H.T., Narasimhan, K.: Universal adversarial attacks with natural triggers for text classification. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 3724–3733 (2021)
2021
-
[25]
In: Conference on Em- pirical Methods in Natural Language Processing (2020)
Wang, B., Pei, H., Pan, B., Chen, Q., Wang, S., Li, B.: T3: Tree-autoencoder constrained adversarial text generation for targeted attack. In: Conference on Em- pirical Methods in Natural Language Processing (2020)
2020
-
[26]
9th International Conference on Learning Representations (ICLR) (2020)
Wang, B., Wang, S., Cheng, Y., Gan, Z., Jia, R., Li, B., Liu, J.: Infobert: Improv- ing robustness of language models from an information theoretic perspective. 9th International Conference on Learning Representations (ICLR) (2020)
2020
-
[27]
In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (2021)
Wang, W., Tang, P., Lou, J., Xiong, L.: Certified robustness to word substitution attack with differential privacy. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (2021)
2021
-
[28]
In: Proceedings of the 37th Conference on Uncertainty in Ar- tificial Intelligence (2021)
Wang, X., Jin, H., Yang, Y., He, K.: Natural language adversarial defense through synonym encoding. In: Proceedings of the 37th Conference on Uncertainty in Ar- tificial Intelligence (2021)
2021
-
[29]
In: AAAI Conference on Artificial Intelligence (2021)
Wang, X., Yang, Y., Deng, Y., He, K.: Adversarial training with fast gradient projection method against synonym substitution based text attacks. In: AAAI Conference on Artificial Intelligence (2021)
2021
-
[30]
In: 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD)
Wang, Z., Wang, W., Chen, Q., Wang, Q., Nguyen, A.: Generating valid and nat- ural adversarial examples with large language models. In: 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD). pp. 1716–1721. IEEE (2024)
2024
-
[31]
arXiv preprint arXiv:2405.02764 (2024)
Yang, Z., Meng, Z., Zheng, X., Wattenhofer, R.: Assessing adversarial robustness of large language models: An empirical study. arXiv preprint arXiv:2405.02764 (2024)
arXiv 2024
-
[32]
In: Proceed- ings of the 58th Annual Meeting of the Association for Computa- tional Linguistics
Ye, M., Gong, C., Liu, Q.: SAFER: A structure-free approach for certified robustness to adversarial word substitutions. In: Proceed- ings of the 58th Annual Meeting of the Association for Computa- tional Linguistics. pp. 3465–3475. Association for Computational Lin- guistics, Online (Jul 2020). https://doi.org/10.18653/v1/2020.acl-main.317, https://www.ac...
-
[33]
In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (2020) 18 M
Zang, Y., Qi, F., Yang, C., Liu, Z., Zhang, M., Liu, Q., Sun, M.: Word-level textual adversarial attacking as combinatorial optimization. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (2020) 18 M. Bouri et al
2020
-
[34]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Zeng, G., Qi, F., Zhou, Q., Zhang, T., Ma, Z., Hou, B., Zang, Y., Liu, Z., Sun, M.: OpenAttack: An open-source textual adversarial attack toolkit. In: Ji, H., Park, J.C., Xia, R. (eds.) Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System ...
-
[35]
In: Findings of Association for Computational Linguistics (2021)
Zeng, J., Zheng, X., Xu, J., Li, L., Yuan, L., Huang, X.: Certified robustness to text adversarial attacks by randomized [MASK]. In: Findings of Association for Computational Linguistics (2021)
2021
-
[36]
arXiv preprint arXiv:2105.03743 (2021)
Zeng, J., Zheng, X., Xu, J., Li, L., Yuan, L., Huang, X.: Certified robustness to text adversarial attacks by randomized [MASK]. arXiv preprint arXiv:2105.03743 (2021)
arXiv 2021
-
[37]
In: Advances in Neural Information Processing Systems (2015)
Zhang, X., Zhao, J.J., LeCun, Y.: Character-level convolutional networks for text classification. In: Advances in Neural Information Processing Systems (2015)
2015
-
[38]
In: 2024 IEEE Symposium on Security and Privacy (SP)
Zhang, X., Hong, H., Hong, Y., Huang, P., Wang, B., Ba, Z., Ren, K.: Text-crs: A generalized certified robustness framework against textual adversarial attacks. In: 2024 IEEE Symposium on Security and Privacy (SP). pp. 2920–2938. IEEE (2024)
2024
-
[39]
In: Moens, M.F., Huang, X., Spe- cia, L., Yih, S.W.t
Zhang, Y., Albarghouthi, A., D’Antoni, L.: Certified robustness to pro- grammable transformations in LSTMs. In: Moens, M.F., Huang, X., Spe- cia, L., Yih, S.W.t. (eds.) Proceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing. pp. 1068–1083. Asso- ciation for Computational Linguistics, Online and Punta Cana, Domini- can Rep...
-
[40]
arXiv preprint arXiv:2006.11627 (2020)
Zhou, Y., Zheng, X., Hsieh, C.J., Chang, K.w., Huang, X.: Defense against adversarial attacks in nlp via dirichlet neighborhood ensemble. arXiv preprint arXiv:2006.11627 (2020)
arXiv 2006
-
[41]
Zhu, C., Cheng, Y., Gan, Z., Sun, S., Goldstein, T., Liu, J.: Freelb: Enhanced ad- versarial training for natural language understanding. In: 8th International Con- ference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 (2020), https://openreview.net/forum?id=BygzbyHFvB S-GBT: Smooth Growth Bound Tensor 19 A Appendix A.1 ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.