VISA: VLM-Guided Instance Semantic Auditing for 3D Occupancy World Models
Pith reviewed 2026-06-27 07:06 UTC · model grok-4.3
The pith
An offline VLM can audit physical object instances in 3D occupancy data and distill the results into model logits to raise closed-set mIoU without any change to inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
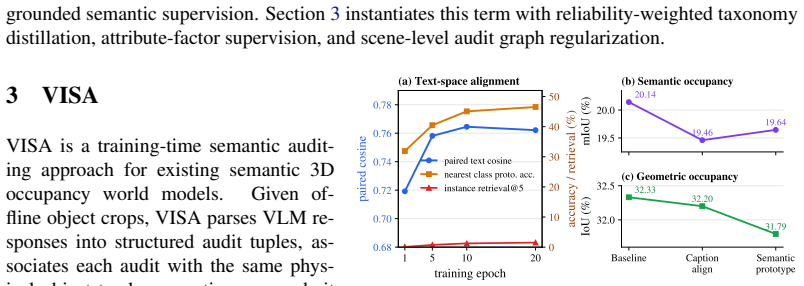
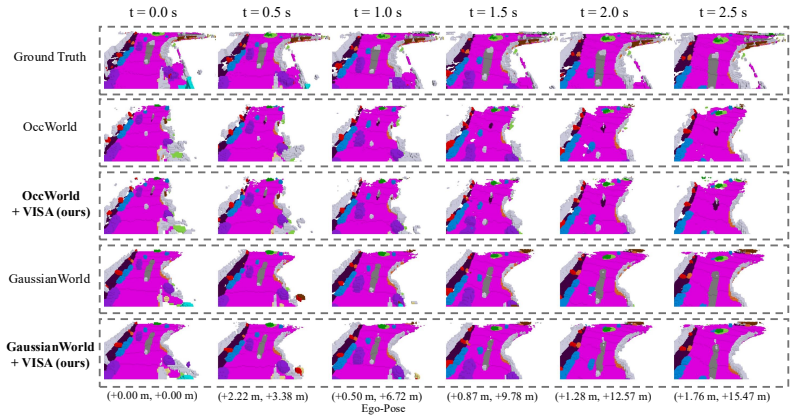
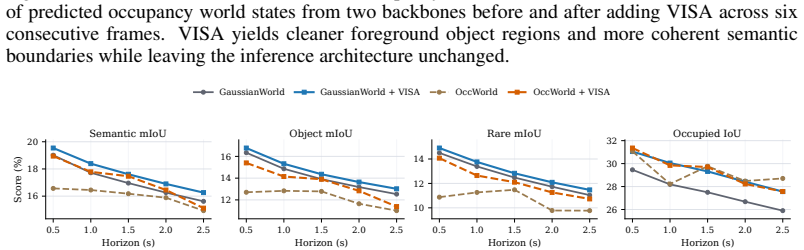
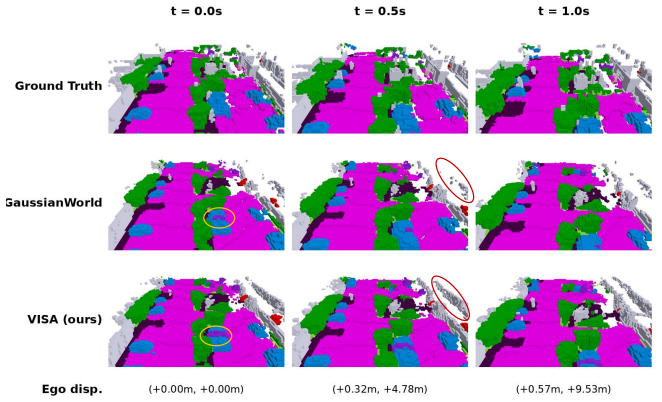
VISA shows that VLMs improve closed-set 3D occupancy when used as reliability-aware instance auditors rather than as generic embedding targets. For each physical object the offline VLM returns a structured audit that is propagated along the track, matched to 3D voxels, and distilled into semantic logits through three losses; the resulting models record higher mIoU on nuScenes while leaving the forward pass unchanged.
What carries the argument
VISA instance-audit pipeline: VLM query on object crops yields structured audit (class hypotheses, reliability, attributes, evidence) that is grounded to matched voxels and distilled via reliability-weighted taxonomy, attribute-factor, and scene-level graph losses.
If this is right
- OccWorld mIoU rises from 19.06 to 20.05 on nuScenes.
- GaussianWorld mIoU rises from 21.36 to 21.91, with object mIoU from 18.18 to 19.16 and rare-class mIoU from 15.60 to 16.79.
- Inference-time cost and architecture remain identical because the VLM is used only during training.
- The same audit distillation can be applied to any existing occupancy world model that already produces object tracks.
Where Pith is reading between the lines
- The same audit mechanism could be tested on other voxel-based perception tasks where rare-class accuracy limits downstream planning.
- If the reliability scores correlate with actual error rates across datasets, they could serve as per-voxel uncertainty estimates for planning modules.
- Extending the audit graph to include temporal consistency checks might further reduce drift in long tracks without extra labels.
Load-bearing premise
The offline VLM produces audits whose class hypotheses and reliability scores can be matched to 3D voxels and tracked without introducing new systematic errors that cancel the reported mIoU gains.
What would settle it
Running the identical VISA procedure on a held-out occupancy model and dataset split and observing zero or negative change in object and rare-class mIoU would falsify the claim that the audits reliably improve closed-set performance.
Figures



read the original abstract
Semantic 3D occupancy provides a voxelized world state for autonomous driving and robot decision making, but object and rare-class errors can affect free-space interpretation, collision checking, and temporal state propagation. We show that a common VLM strategy, aligning 3D voxel or object features with crop-caption embeddings, improves text-space similarity without reliably improving closed-set occupancy mIoU. Motivated by this mismatch, we propose VISA, a training-time semantic auditing approach for existing occupancy world models. VISA queries an offline VLM on a representative crop of each physical object instance, obtains a structured audit with class hypotheses, plausible confusions, reliability, attributes, and evidence, and propagates it along the object track. The audit is grounded to matched 3D object voxels and distilled into semantic logits through reliability-weighted taxonomy, attribute-factor, and scene-level audit graph losses, while inference remains unchanged and requires no VLM. On nuScenes, averaged across three runs, VISA improves OccWorld from 19.06 to 20.05 mIoU and GaussianWorld from 21.36 to 21.91 mIoU; on GaussianWorld, object mIoU improves from 18.18 to 19.16 and rare-class mIoU from 15.60 to 16.79. These results suggest that VLMs are better suited to closed-set occupancy as reliability-aware semantic auditors than as generic caption-embedding targets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VISA, a training-time semantic auditing method for 3D occupancy world models. An offline VLM is queried on 2D crops of tracked object instances to produce structured audits (class hypotheses, confusions, reliability scores, attributes, evidence). These are grounded to matched 3D voxels, propagated along tracks, and distilled via reliability-weighted taxonomy, attribute-factor, and scene-graph losses. Inference is unchanged and VLM-free. On nuScenes, averaged over three runs, VISA raises OccWorld mIoU from 19.06 to 20.05 and GaussianWorld from 21.36 to 21.91, with object mIoU rising from 18.18 to 19.16 and rare-class mIoU from 15.60 to 16.79 on GaussianWorld. The central claim is that VLMs are more effective as reliability-aware auditors than as direct caption-embedding targets for closed-set occupancy.
Significance. If the VLM audits prove reliable and the mIoU gains are not artifacts of variance or post-hoc choices, the work offers a practical way to inject semantic knowledge into occupancy models without runtime cost. It directly addresses the observed mismatch between text-space similarity and mIoU. The three-run averaging and separate reporting of object/rare-class metrics are positive; the method is modular and leaves inference unchanged.
major comments (3)
- [Experiments / Results] Experiments / Results (abstract and § on quantitative evaluation): the reported mIoU gains (+0.99 for OccWorld, +0.55 for GaussianWorld; object and rare-class lifts) rest on the unvalidated assumption that offline VLM audits are accurate enough to be grounded and propagated without net error. No audit-vs-nuScenes agreement rates, no per-class confusion matrices for the VLM hypotheses, and no ablation that removes reliability weighting or the scene-graph loss are supplied; without these the gains could be explained by base-model variance or data selection.
- [Method] Method (§ on grounding and propagation): the claim that audits can be accurately matched to 3D object voxels and propagated along tracks without introducing systematic errors (especially on occluded or rare-class instances) lacks a direct fidelity check. If grounding fails or track propagation drifts, the reliability-weighted losses could reinforce incorrect labels rather than correct them.
- [Evaluation protocol] Evaluation protocol: the abstract states numerical mIoU gains averaged across three runs but supplies no standard deviations, statistical tests, or explicit dataset splits / validation protocol. This makes it impossible to judge whether the improvements exceed within-run variance and undermines the cross-model claim.
minor comments (2)
- [Method] Notation for the three loss terms (taxonomy, attribute-factor, scene-graph) should be defined with explicit equations and weighting coefficients before the results are presented.
- [Figures] Figure captions for the audit examples should include the exact VLM prompt template and the reliability threshold used for filtering.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Experiments / Results] Experiments / Results (abstract and § on quantitative evaluation): the reported mIoU gains (+0.99 for OccWorld, +0.55 for GaussianWorld; object and rare-class lifts) rest on the unvalidated assumption that offline VLM audits are accurate enough to be grounded and propagated without net error. No audit-vs-nuScenes agreement rates, no per-class confusion matrices for the VLM hypotheses, and no ablation that removes reliability weighting or the scene-graph loss are supplied; without these the gains could be explained by base-model variance or data selection.
Authors: We agree that the current manuscript lacks direct validation of VLM audit accuracy and component ablations, which limits attribution of the observed gains. In the revised manuscript we will add (i) agreement rates between VLM class hypotheses and nuScenes ground-truth labels, (ii) per-class confusion matrices for the VLM outputs, and (iii) ablations that remove reliability weighting and the scene-graph loss. These additions will allow readers to assess whether the improvements exceed run-to-run variance. revision: yes
-
Referee: [Method] Method (§ on grounding and propagation): the claim that audits can be accurately matched to 3D object voxels and propagated along tracks without introducing systematic errors (especially on occluded or rare-class instances) lacks a direct fidelity check. If grounding fails or track propagation drifts, the reliability-weighted losses could reinforce incorrect labels rather than correct them.
Authors: Grounding uses the nuScenes-provided 3D instance masks and track IDs to associate 2D crops with voxels; propagation follows those same tracks. We acknowledge that the manuscript does not contain a dedicated fidelity analysis. We will add quantitative grounding-accuracy metrics (e.g., voxel overlap with available labels) stratified by occlusion level and rarity, together with qualitative examples of propagation on occluded and rare-class instances, to verify that systematic error reinforcement does not occur. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol: the abstract states numerical mIoU gains averaged across three runs but supplies no standard deviations, statistical tests, or explicit dataset splits / validation protocol. This makes it impossible to judge whether the improvements exceed within-run variance and undermines the cross-model claim.
Authors: The three runs were performed with independent random seeds on the official nuScenes train/validation split. We will revise the manuscript to report standard deviations, include statistical significance tests (paired t-tests on per-run mIoU), and explicitly restate the dataset splits and evaluation protocol in the experimental section. revision: yes
Circularity Check
No circularity in claimed derivation or results
full rationale
The paper describes an empirical training-time auditing method that queries an external offline VLM, grounds audits to 3D voxels, propagates along tracks, and applies reliability-weighted losses. Reported mIoU gains on nuScenes are presented as measured outcomes of this process rather than quantities defined by internal fits or self-referential equations. No load-bearing derivation reduces the central claim to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled via prior work. The method remains self-contained against external benchmarks (nuScenes labels) with no equations that equate outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. Funkhouser. Semantic scene com- pletion from a single depth image. InCVPR, 2017. URLhttps://arxiv.org/abs/1611. 08974
2017
-
[2]
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. InCVPR, 2020. URLhttps://arxiv.org/abs/1903.11027
Pith/arXiv arXiv 2020
-
[3]
Huang, W
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu. Tri-perspective view for vision-based 3d semantic occupancy prediction. InCVPR, 2023. URLhttps://arxiv.org/abs/2302. 07817
2023
-
[4]
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. InICCV, 2023. URLhttps://arxiv.org/ abs/2303.09551
arXiv 2023
-
[5]
X. Tian, T. Jiang, L. Yun, Y . Mao, H. Yang, Y . Wang, Y . Wang, and H. Zhao. Occ3d: A large- scale 3d occupancy prediction benchmark for autonomous driving. InNeurIPS Datasets and Benchmarks, 2023. URLhttps://arxiv.org/abs/2304.14365
arXiv 2023
- [6]
- [7]
-
[8]
Y . Li, Z. Yu, C. B. Choy, C. Xiao, J. M. Alvarez, S. Fidler, C. Feng, and A. Anandkumar. V oxformer: Sparse voxel transformer for camera-based 3d semantic scene completion. In CVPR, 2023. URLhttps://arxiv.org/abs/2302.12251
arXiv 2023
-
[9]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai. Bevformer: Learning bird’s- eye-view representation from multi-camera images via spatiotemporal transformers. InECCV,
-
[10]
URLhttps://arxiv.org/abs/2203.17270
-
[11]
D. Ha and J. Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018. URL https://arxiv.org/abs/1803.10122
Pith/arXiv arXiv 2018
-
[12]
C. Min, L. Xiao, Y . Nie, B. Dai, S. Zhang, et al. Driveworld: 4d pre-trained scene understand- ing via world models for autonomous driving.arXiv preprint arXiv:2405.04390, 2024. URL https://arxiv.org/abs/2405.04390
arXiv 2024
-
[13]
S. Zuo, W. Zheng, Y . Huang, J. Zhou, and J. Lu. Gaussianworld: Gaussian world model for streaming 3d occupancy prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. URLhttps://arxiv.org/abs/2412.10373
arXiv 2025
-
[14]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, 2021. URL https://arxiv.org/abs/2103.00020
Pith/arXiv arXiv 2021
-
[15]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023. URLhttps://arxiv.org/abs/2303.15343
Pith/arXiv arXiv 2023
-
[16]
J. Li, D. Li, S. Savarese, and S. Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational Conference on Machine Learning, pages 19730–19742, 2023. URLhttps://proceedings.mlr.press/ v202/li23q.html. 10
2023
-
[17]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning. InAdvances in Neural Informa- tion Processing Systems, 2023. URLhttps://arxiv.org/abs/2304.08485
Pith/arXiv arXiv 2023
-
[18]
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou. Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023. URLhttps://arxiv.org/abs/2308.12966
Pith/arXiv arXiv 2023
-
[19]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin. Qwen2-VL: En- hancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. URLhttps://arxiv.org/abs/2409.12191
Pith/arXiv arXiv 2024
-
[20]
R. Chen, Y . Liu, L. Kong, X. Zhu, Y . Ma, Y . Li, Y . Hou, Y . Qiao, and W. Wang. CLIP2Scene: Towards label-efficient 3d scene understanding by CLIP. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7020–7030, 2023. URL https://openaccess.thecvf.com/content/CVPR2023/html/Chen_CLIP2Scene_ Towards_Label-Efficient_3...
2023
-
[21]
S. Peng, K. Genova, C. M. Jiang, A. Tagliasacchi, M. Pollefeys, and T. Funkhouser. Openscene: 3d scene understanding with open vocabularies. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 815–824, 2023. URLhttps://openaccess.thecvf.com/content/CVPR2023/html/Peng_OpenScene_ 3D_Scene_Understanding_With_Open_Vocabu...
2023
-
[22]
R. Ding, J. Yang, C. Xue, W. Zhang, S. Bai, and X. Qi. PLA: Language-driven open-vocabulary 3d scene understanding.arXiv preprint arXiv:2211.16312, 2022. URLhttps://arxiv.org/ abs/2211.16312
arXiv 2022
-
[24]
URLhttps://arxiv.org/abs/2304.00962
-
[25]
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, Z. Muyan, Q. Zhang, X. Zhu, L. Lu, B. Li, P. Luo, T. Lu, Y . Qiao, and J. Dai. InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. URLhttps://arxiv.org/abs/2312.14238
Pith/arXiv arXiv 2024
-
[26]
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Li, Y . Liu, and C. Li. LLaV A- NeXT: Improved reasoning, ocr, and world knowledge.arXiv preprint arXiv:2401.13601, 2024
arXiv 2024
-
[27]
Z. Tan, Z. Dong, C.-J. Zhang, W. Zhang, H. Ji, and H. Li. Ovo: Open-vocabulary occupancy. arXiv preprint arXiv:2305.16133, 2023. URLhttps://arxiv.org/abs/2305.16133
arXiv 2023
-
[29]
URLhttps://arxiv.org/abs/2401.09413
-
[30]
Zhang, B
Z. Zhang, B. Gao, J. Ye, H. Jin, L. Jiang, and W. Yang. Clip prior-guided 3d open-vocabulary occupancy prediction.Pattern Recognition, 162:111347, 2025
2025
- [31]
-
[32]
Z. Yu, B. Pang, L. Liu, R. Zhang, Q. Peng, M. Luo, S. Yang, M. Chen, S. Cao, and H. Shen. Language driven occupancy prediction. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), 2024. URLhttps://arxiv.org/abs/2411.16072. 11
arXiv 2024
- [33]
-
[34]
Y . Feng, Y . Han, X. Zhang, T. Li, Y . Zhang, and R. Fan. Vipocc: Leveraging visual pri- ors from vision foundation models for single-view 3d occupancy prediction.arXiv preprint arXiv:2412.11210, 2024. URLhttps://arxiv.org/abs/2412.11210
arXiv 2024
-
[35]
A. E. Doruk and H. F. Ates. Vlmfusionocc3d: Vlm assisted multi-modal 3d semantic oc- cupancy prediction. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026. URLhttps://arxiv.org/abs/2603.02609
arXiv 2026
-
[36]
Huang, W
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu. Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction. InEuropean Conference on Computer Vision,
-
[37]
URLhttps://arxiv.org/abs/2405.17429
- [38]
- [39]
-
[40]
Y . Huang, A. Thammatadatrakoon, W. Zheng, Y . Zhang, D. Du, and J. Lu. Gaussianformer- 2: Probabilistic gaussian superposition for efficient 3d occupancy prediction. InProceedings of the computer vision and pattern recognition conference, pages 27477–27486, 2025. URL https://arxiv.org/abs/2412.04384
arXiv 2025
-
[41]
S. Zuo, W. Zheng, X. Han, L. Yang, J. Lu, et al. Quadricformer: Scene as superquadrics for 3d semantic occupancy prediction.Advances in Neural Information Processing Systems, 38: 47779–47801, 2026. URLhttps://arxiv.org/abs/2506.10977
arXiv 2026
-
[42]
X. Wang, Z. Zhu, W. Xu, Y . Zhang, Y . Wei, X. Chi, Y . Ye, D. Du, J. Lu, and X. Wang. Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17804–17813, 2023. URLhttps://arxiv.org/abs/2303.03991
arXiv 2023
-
[43]
Z. Li, Z. Yu, D. Austin, M. Fang, S. Lan, J. Kautz, and J. M. ´Alvarez. Fb-occ: 3d occupancy prediction based on forward-backward view transformation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. URLhttps:// arxiv.org/abs/2307.01492
arXiv 2023
-
[44]
Y .-Q. Wang, Y . Chen, X. Liao, L. Fan, and Z. Zhang. Panoocc: Unified occupancy rep- resentation for camera-based 3d panoptic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. URLhttps: //arxiv.org/abs/2306.10013
arXiv 2024
- [45]
-
[46]
M. Pan, J. Liu, R. Zhang, P. Huang, X. Li, L. Liu, and S. Zhang. Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. URLhttps:// arxiv.org/abs/2309.09502. 12
arXiv 2024
- [47]
-
[48]
L. Li, T. Zhou, W. Wang, J. Li, and Y . Yang. Deep hierarchical semantic segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1246–1257, 2022. URLhttps://arxiv.org/abs/2203.14335
arXiv 2022
-
[49]
Y . Cui, M. Jia, T.-Y . Lin, Y . Song, and S. Belongie. Class-balanced loss based on effective number of samples. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9268–9277, 2019. URLhttps://arxiv.org/abs/1901.05555
Pith/arXiv arXiv 2019
-
[50]
B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, and Y . Kalantidis. Decoupling rep- resentation and classifier for long-tailed recognition. InInternational Conference on Learning Representations, 2020. URLhttps://arxiv.org/abs/1910.09217
arXiv 2020
- [51]
-
[52]
X. Zhu, H. Zhang, F. He, R. Wu, Y . Shan, W. Yang, and H. Yu. Dr.Occ: Depth- and region- guided 3D occupancy from surround-view cameras for autonomous driving.arXiv preprint arXiv:2603.01007, 2026. URLhttps://arxiv.org/abs/2603.01007
arXiv 2026
- [53]
-
[54]
Z. Leng, J. Yang, W. Yi, and B. Zhou. Occupancy learning with spatiotemporal memory. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 26569–26578, 2025. URLhttps://arxiv.org/abs/2508.04705
arXiv 2025
-
[55]
Mattamala, J
M. Mattamala, J. Frey, P. Libera, N. Chebrolu, G. Martius, C. Cadena, M. Hutter, and M. F. Fallon. Wild visual navigation: fast traversability learning via pre-trained models and online self-supervision.Autonomous Robots, 49, 2024. URLhttps://arxiv.org/abs/2404. 07110. 13 A Additional Related Work 3D Semantic Occupancy and Occupancy World Models:Originati...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.