Budget-Constrained Step-Level Diffusion Caching
Pith reviewed 2026-06-27 07:01 UTC · model grok-4.3
The pith
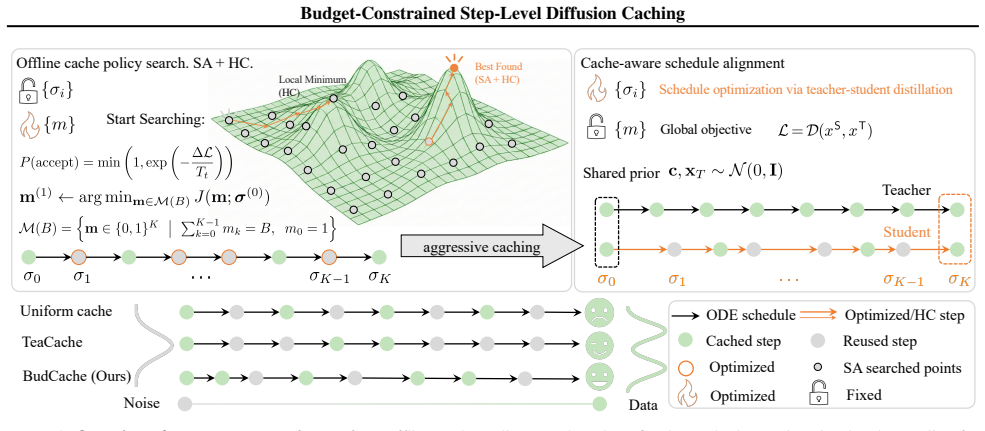
BudCache fixes the inference budget first and searches offline for the best cache policy instead of using error thresholds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By fixing the compute budget ahead of time and using simulated annealing plus hill climbing to select which denoising steps to cache, BudCache identifies policies that deliver better final output quality than threshold-based heuristics while making latency predictable and eliminating online search overhead; cache-aware schedule alignment further reduces trajectory mismatch under tight budgets.
What carries the argument
Offline search that combines Simulated Annealing with deterministic Hill Climbing to choose a fixed set of steps to cache under a preset budget constraint.
If this is right
- Inference latency becomes fixed and known before deployment rather than varying with input.
- No runtime overhead from per-step error calculations or online policy search is required.
- Quality at a given budget exceeds that of existing heuristic caching methods.
- Schedule alignment becomes available as an extra lever when the budget is extremely small.
Where Pith is reading between the lines
- The separation of policy search from inference could let the same method apply to other iterative sampling processes that exhibit temporal redundancy.
- Fixed policies might be combined with light domain-specific fine-tuning without changing the core offline-search approach.
- Making latency fully predictable could simplify scheduling on shared hardware or edge devices where compute must be reserved in advance.
Load-bearing premise
Cache policies found by offline search on a small set of examples generalize to new inputs without needing any per-input changes or online adjustment.
What would settle it
Measuring output quality on a held-out set of diverse prompts and finding that the fixed offline policy produces lower quality than a threshold heuristic at the exact same step budget.
Figures







read the original abstract
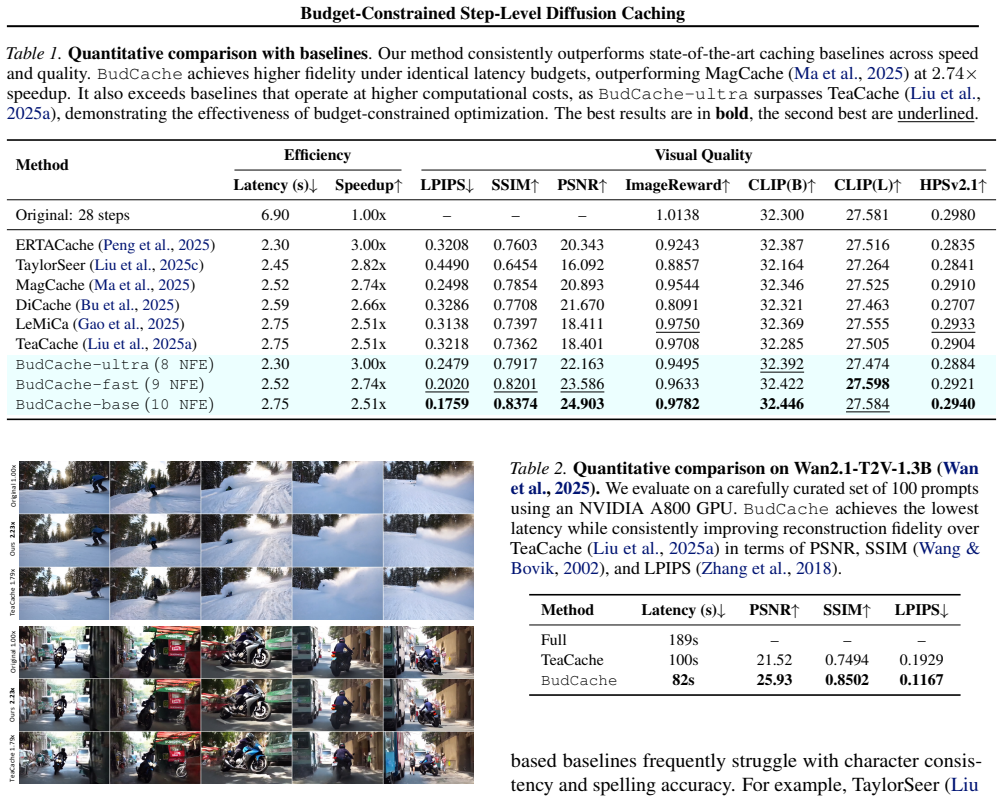
Step-level caching accelerates diffusion models by exploiting temporal redundancy across denoising steps. Existing methods make per-step cache decisions using threshold-based heuristics, without directly optimizing for final output quality. As a result, their inference latency varies across inputs and is difficult to control at deployment. In this work, we propose BudCache, which inverts this formulation: rather than letting per-step error thresholds dictate the runtime cost, we fix the compute budget in advance and search for the cache policy that best preserves the final output. To tackle the combinatorial complexity of step selection, we combine Simulated Annealing with deterministic Hill Climbing. This offline search identifies high-quality cache policies within minutes and introduces no online search or thresholding overhead during inference. When the compute budget is very tight, we further introduce cache-aware schedule alignment, which adapts the time discretization to the selected cache policy to reduce cache-induced trajectory mismatch. Experiments on FLUX.1-dev and Wan2.1 show that BudCache achieves better generation quality than heuristic caching baselines under the same inference budgets. Code is available at https://github.com/Westlake-AGI-Lab/BudCache
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BudCache, which inverts the standard caching formulation for diffusion models: instead of per-step threshold heuristics that produce variable latency, it fixes the inference budget upfront and uses an offline combination of simulated annealing and hill climbing to discover a cache policy that maximizes final output quality. For very tight budgets it adds cache-aware schedule alignment to mitigate trajectory mismatch. Experiments on FLUX.1-dev and Wan2.1 are reported to show higher generation quality than heuristic baselines under identical budgets, with the search performed once and incurring no online overhead.
Significance. If the central empirical claim holds, the work addresses a practical deployment need by making inference cost predictable while still improving quality over existing heuristics. The offline nature of the search and the release of code are positive features that would allow others to reproduce and extend the approach.
major comments (2)
- [Experiments] Experimental section: the manuscript provides no information on the size, diversity, or composition of the prompt set used for the offline SA+HC search, nor any indication that final quality metrics were measured on a held-out test distribution disjoint from the optimization prompts. This directly affects the load-bearing claim that a single discovered policy generalizes to unseen inputs without per-input adaptation or thresholding.
- [Method] Method section (cache policy representation): the precise encoding of the cache policy (binary mask per step? per-layer decisions?) and the exact objective function maximized by the search are not stated, making it impossible to assess whether the reported gains are robust or sensitive to the particular search formulation.
minor comments (2)
- [Abstract] Abstract: the phrase 'better generation quality' should be accompanied by the specific metric(s) used (FID, CLIP score, human preference, etc.) so readers can immediately gauge the magnitude of improvement.
- [Method] The description of 'cache-aware schedule alignment' would benefit from a short equation or pseudocode showing how the time discretization is adjusted given the selected cache steps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental details and method clarity. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Experiments] Experimental section: the manuscript provides no information on the size, diversity, or composition of the prompt set used for the offline SA+HC search, nor any indication that final quality metrics were measured on a held-out test distribution disjoint from the optimization prompts. This directly affects the load-bearing claim that a single discovered policy generalizes to unseen inputs without per-input adaptation or thresholding.
Authors: We agree these details are essential. The revised manuscript will specify that the offline search used a set of 200 prompts drawn from a diverse pool (covering photography, illustration, abstract concepts, and text-heavy scenes) sampled from public datasets. Quality metrics for the reported results were evaluated on a disjoint held-out set of 100 prompts never seen during policy search, confirming generalization of the single policy. We will add this information to the experimental section along with a brief description of prompt diversity. revision: yes
-
Referee: [Method] Method section (cache policy representation): the precise encoding of the cache policy (binary mask per step? per-layer decisions?) and the exact objective function maximized by the search are not stated, making it impossible to assess whether the reported gains are robust or sensitive to the particular search formulation.
Authors: We will expand the method section to state explicitly that the cache policy is encoded as a binary mask of length equal to the number of denoising steps (one bit per step, indicating cache or recompute). The objective maximized by simulated annealing plus hill climbing is the expected output quality under the fixed budget, measured as the average of a perceptual metric (LPIPS distance to a high-quality reference trajectory) over the prompt set. We will include the precise formulation and pseudocode in the revision. revision: yes
Circularity Check
Empirical offline optimization procedure with no circular reductions
full rationale
The paper presents BudCache as a direct computational search (simulated annealing + hill climbing) that selects a fixed cache policy for a pre-specified budget; the output policy is the literal result of that search rather than a derived quantity claimed to follow from first principles or equations. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the central result, and performance claims are framed as empirical comparisons to heuristic baselines. The derivation chain is therefore self-contained as an optimization procedure whose validity rests on external test-set measurements rather than any definitional or fitted-input equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated annealing combined with hill climbing can efficiently identify high-quality cache policies in the combinatorial space of denoising steps
Reference graph
Works this paper leans on
-
[1]
Dicache: Let diffusion model determine its own cache.arXiv preprint arXiv:2508.17356,
Bu, J., Ling, P., Zhou, Y ., Wang, Y ., Zang, Y ., Lin, D., and Wang, J. Dicache: Let diffusion model determine its own cache.arXiv preprint arXiv:2508.17356,
-
[2]
Cheng, Z., Sun, P., Li, J., and Lin, T. Twinflow: Realizing one-step generation on large models with self-adversarial flows.arXiv preprint arXiv:2512.05150,
-
[3]
Feng, X., Lei, M., Wang, Y ., Fu, D., and Zhang, C. Cleanstyle: Plug-and-play style conditioning purifi- cation for text-to-image stylization.arXiv preprint arXiv:2602.20721,
-
[4]
Lemica: Lexicographic minimax path caching for efficient diffusion-based video generation
Gao, H., Chen, P., Shi, F., Tan, C., Liu, Z., Zhao, F., Wang, K., and Lian, S. Lemica: Lexicographic minimax path caching for efficient diffusion-based video generation. arXiv preprint arXiv:2511.00090,
-
[5]
Ge, X., Zhang, X., Xu, T., Zhang, Y ., Zhang, X., Wang, Y ., and Zhang, J. Senseflow: Scaling distribution matching for flow-based text-to-image distillation.arXiv preprint arXiv:2506.00523,
-
[6]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al. Hunyuan- video: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
URLhttps://arxiv.org/abs/2506.15742. Lei, M., Song, X., Zhu, B., Wang, H., and Zhang, C. Stylestudio: Text-driven style transfer with selective con- trol of style elements. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 23443– 23452,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
Lin, S., Wang, A., and Yang, X. Sdxl-lightning: Progres- sive adversarial diffusion distillation.arXiv preprint arXiv:2402.13929,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Timestep embedding tells: It’s time to cache for video diffusion model
10 Budget-Constrained Step-Level Diffusion Caching Liu, F., Zhang, S., Wang, X., Wei, Y ., Qiu, H., Zhao, Y ., Zhang, Y ., Ye, Q., and Wan, F. Timestep embedding tells: It’s time to cache for video diffusion model. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pp. 7353–7363, 2025a. Liu, H., Zhang, W., Xie, J., Faccio, F., Xu, ...
-
[11]
Mag- cache: Fast video generation with magnitude-aware cache
Ma, Z., Wei, L., Wang, F., Zhang, S., and Tian, Q. Mag- cache: Fast video generation with magnitude-aware cache. arXiv preprint arXiv:2506.09045,
-
[12]
Peng, X., Liu, H., Yan, C., Ma, R., Chen, F., Wang, X., Wu, Z., Liu, S., and Lin, M. Ertacache: Error rectification and timesteps adjustment for efficient diffusion.arXiv preprint arXiv:2508.21091,
-
[13]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M ¨uller, J., Penna, J., and Rombach, R. Sdxl: Im- proving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Sabour, A., Fidler, S., and Kreis, K. Align your steps: Op- timizing sampling schedules in diffusion models.arXiv preprint arXiv:2404.14507,
-
[15]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[16]
arXiv preprint arXiv:2510.22200 (2025)
Team, M. L., Cai, X., Huang, Q., Kang, Z., Li, H., Liang, S., Ma, L., Ren, S., Wei, X., Xie, R., et al. Longcat-video technical report.arXiv preprint arXiv:2510.22200,
- [17]
-
[18]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Wang, R., Li, Z., Zhu, B., Yuan, L., Zhang, H., Yang, X., Chang, X., and Zhang, C. Parallel diffusion solver via residual dirichlet policy optimization (2025).URL https://arxiv.org/abs/2512.22796,
-
[20]
Wu, X., Hao, Y ., Sun, K., Chen, Y ., Zhu, F., Zhao, R., and Li, H. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., and Yang, W. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
11 Budget-Constrained Step-Level Diffusion Caching Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Du- rand, F., and Freeman, B. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024a. Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W. T., a...
-
[23]
Zhao, T., Lei, M., Yuan, L., Yang, Y ., Song, C., Wang, Y ., Zhu, B., and Zhang, C. Dyweight: Dynamic gradient weighting for few-step diffusion sampling.arXiv preprint arXiv:2603.11607,
-
[24]
Zou, C., Liu, X., Liu, T., Huang, S., and Zhang, L. Ac- celerating diffusion transformers with token-wise feature caching.arXiv preprint arXiv:2410.05317, 2024a. Zou, C., Zhang, E., Guo, R., Xu, H., He, C., Hu, X., and Zhang, L. Accelerating diffusion transformers with dual feature caching.arXiv preprint arXiv:2412.18911, 2024b. 12 Budget-Constrained Step...
-
[25]
We fix the caching policy m∗ obtained from the search phase and optimize the continuous time steps σ
Cache-aware schedule alignment details.The time schedule refine- ment is performed offline on a lightweight calibration set comprising only 100 prompts randomly sampled from the MS-COCO 2014 valida- tion dataset (Lin et al., 2014). We fix the caching policy m∗ obtained from the search phase and optimize the continuous time steps σ. The optimization uses t...
2014
-
[26]
Scaling the calibration set.Calibration scale is a natural axis to study for both image and video diffusion
with a limited calibration budget of 100 prompts and did not observe measurable gains; this may be related to insufficient calibration scale and the higher-dimensional trajectory space of video generation. Scaling the calibration set.Calibration scale is a natural axis to study for both image and video diffusion. On image models such as FLUX.1-dev (Labs, ...
2024
-
[27]
A red colored car
prompts, demonstrating consistent generalization of the searched configuration across inference settings. Setting Method Efficiency Visual Quality Latency (s)↓LPIPS↓SSIM↑PSNR↑ImageReward↑CLIP(L)↑HPSv2.1↑ iPNDM(2M) Original: 28 steps 6.90 – – – 0.9740 27.48 0.2984 TeaCache 2.75 0.4124 0.6569 15.35 0.9387 27.52 0.2908 BudCache-base2.750.1632 0.8337 23.80 0....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.