Generative Modeling of Bach-Style Symbolic Music: A Comparative Study of Autoregressive, Latent-Variable, and Adversarial Approaches
Pith reviewed 2026-06-27 05:27 UTC · model grok-4.3
The pith
Autoregressive LSTMs with attention generate the most musically coherent Bach-style piano music among the three model families tested on a shared MIDI corpus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
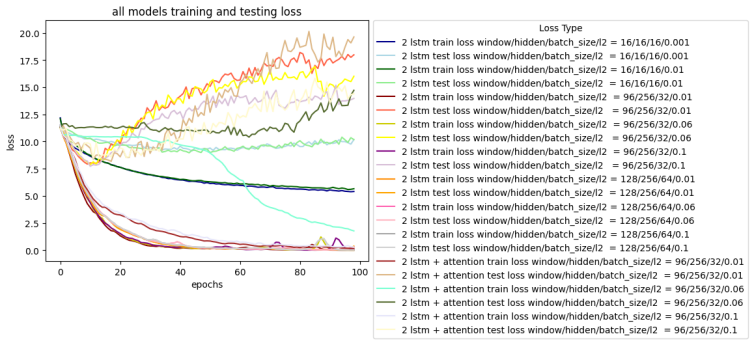
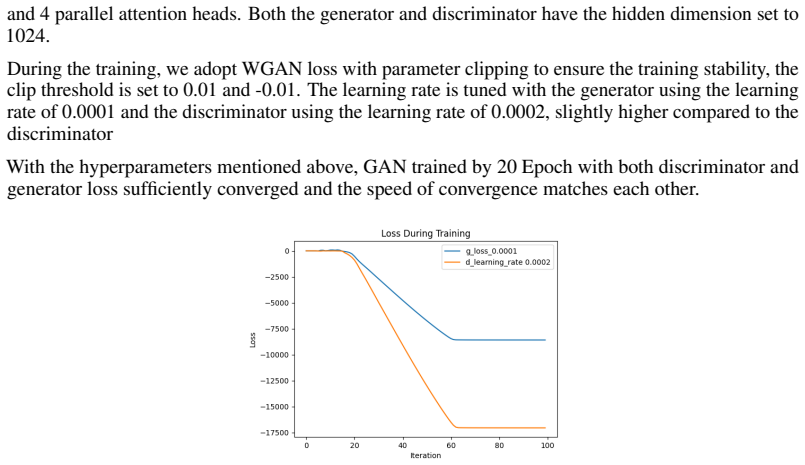
Experiments on the shared MIDI corpus demonstrate that the autoregressive LSTM with attention produces the most musically coherent samples. Vector quantization mitigates posterior collapse and yields more structured outputs than conventional recurrent VAEs. The adversarial approach captures local pitch patterns but remains difficult to train and generalizes less reliably to Bach's style.
What carries the argument
Three model families—autoregressive LSTMs with attention, latent-variable models (recurrent VAEs and VQ-VAEs), and GANs—applied to polyphonic note sequences from one MIDI corpus for direct comparison of coherence, structure, and stylistic fit.
If this is right
- Attention-based autoregressive models are preferable when coherence is the primary goal for symbolic music generation.
- Vector quantization offers a concrete way to improve structure and reduce collapse in recurrent latent-variable models for music.
- Adversarial methods need additional stabilization techniques to achieve reliable stylistic generalization on polyphonic sequences.
- Comparative evaluation on identical data reveals distinct failure modes: coherence gaps in latent models, training instability in GANs.
- The relative performance ordering can guide selection of base architectures before adding domain-specific refinements.
Where Pith is reading between the lines
- Future work could test whether combining attention mechanisms directly with vector quantization produces hybrids that exceed the best single-family results.
- The corpus-specific findings may not transfer to other composers or genres without repeating the comparison.
- Objective sequence-level metrics that align with human coherence judgments would strengthen future model rankings.
- The training difficulties observed with GANs suggest exploring conditional or progressive variants for sequential music tasks.
Load-bearing premise
That judgments of musical coherence and stylistic generalization on the shared MIDI corpus provide a sufficient and unbiased basis for ranking the three model families.
What would settle it
A blinded listening study with multiple expert musicians rating large sets of generated samples for coherence and Bach-style fidelity, or an automatic metric that correlates with such ratings and produces a different model ranking.
Figures







read the original abstract
We study generative modeling of Bach-style symbolic piano music using a shared MIDI corpus and three model families: autoregressive LSTMs with attention, latent-variable models including recurrent VAEs and vector-quantized VAEs, and generative adversarial networks. We compare their ability to model polyphonic note sequences, learn useful latent representations, and generate stylistically coherent compositions. Our experiments show that the autoregressive LSTM with attention produces the most musically coherent samples, while vector quantization helps mitigate posterior collapse and yields more structured outputs than conventional recurrent VAEs. The adversarial approach captures local pitch patterns but remains difficult to train and generalizes less reliably to Bach's style. These results highlight the relative strengths and failure modes of autoregressive, latent-variable, and adversarial approaches for symbolic music generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares three families of generative models—autoregressive LSTMs with attention, latent-variable models (recurrent VAEs and vector-quantized VAEs), and GANs—for producing Bach-style symbolic piano music on a shared MIDI corpus. It reports that the autoregressive LSTM with attention yields the most musically coherent samples, that vector quantization mitigates posterior collapse and produces more structured outputs than standard recurrent VAEs, and that the adversarial approach captures local pitch patterns but is difficult to train and generalizes less reliably.
Significance. A rigorously quantified comparison of these modeling paradigms on polyphonic symbolic music could clarify their relative strengths and typical failure modes, providing guidance for future work in music generation. The explicit discussion of posterior collapse and training stability issues is a positive feature if backed by reproducible evidence.
major comments (1)
- [Abstract] Abstract: the central comparative claims—that the autoregressive LSTM with attention 'produces the most musically coherent samples,' that VQ-VAEs 'yield more structured outputs,' and that GANs 'generalize less reliably'—are asserted without reference to any quantitative metrics (e.g., sequence perplexity, pitch-class histogram distances, or note-onset statistics), controlled listening-test protocols, inter-rater reliability statistics, or dataset statistics, rendering the model rankings unverifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central comparative claims—that the autoregressive LSTM with attention 'produces the most musically coherent samples,' that VQ-VAEs 'yield more structured outputs,' and that GANs 'generalize less reliably'—are asserted without reference to any quantitative metrics (e.g., sequence perplexity, pitch-class histogram distances, or note-onset statistics), controlled listening-test protocols, inter-rater reliability statistics, or dataset statistics, rendering the model rankings unverifiable.
Authors: We agree that the abstract would be strengthened by explicit references to the quantitative metrics and evaluation details that support the claims. The body of the manuscript reports sequence perplexity, pitch-class histogram distances, note-onset statistics, and dataset statistics, along with the evaluation protocol. We will revise the abstract to include brief citations to these supporting elements so that the model rankings are more directly verifiable from the abstract. revision: yes
Circularity Check
No circularity: empirical comparisons rest on direct experimental outputs
full rationale
The paper is an empirical comparative study of three model families on a shared MIDI corpus. Its central claims concern relative performance in musical coherence, structure, and generalization, derived from training and sampling experiments rather than any mathematical derivation chain. No equations, uniqueness theorems, ansatzes, or self-citations are invoked to force conclusions; the reported rankings follow from the experimental protocol itself. This is the standard case of a self-contained empirical paper whose results can be externally reproduced or falsified on the same corpus, yielding no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2021 , eprint=
Bach Style Music Authoring System based on Deep Learning , author=. 2021 , eprint=
2021
-
[2]
Bach2Bach: Generating Music Using A Deep Reinforcement Learning Approach
Nikhil Kotecha , title =. CoRR , volume =. 2018 , url =. 1812.01060 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Ondrej C. Self-Supervised. CoRR , volume =. 2021 , url =. 2102.05749 , timestamp =
-
[4]
2023 , eprint=
Simple and Controllable Music Generation , author=. 2023 , eprint=
2023
-
[5]
2012 , eprint=
Modeling Temporal Dependencies in High-Dimensional Sequences: Application to Polyphonic Music Generation and Transcription , author=. 2012 , eprint=
2012
-
[6]
Complete Bach Midi Index , howpublished =
-
[7]
Bach Chorale Harmony Data , howpublished =
-
[8]
Omar Peracha , title =. CoRR , volume =. 2021 , url =. 2107.10388 , timestamp =
-
[9]
2019 , eprint=
A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music , author=. 2019 , eprint=
2019
-
[10]
2022 , eprint=
Generating music with sentiment using Transformer-GANs , author=. 2022 , eprint=
2022
-
[11]
2016 , eprint=
WaveNet: A Generative Model for Raw Audio , author=. 2016 , eprint=
2016
-
[12]
Engel and Colin Raffel and Curtis Hawthorne and Douglas Eck , title =
Adam Roberts and Jesse H. Engel and Colin Raffel and Curtis Hawthorne and Douglas Eck , title =. CoRR , volume =. 2018 , url =. 1803.05428 , timestamp =
-
[13]
Colin Raffel and Daniel P. W. Ellis. Intuitive Analysis, Creation and Manipulation of MIDI Data with pretty\_midi. International Society for Music Information Retrieval Conference. 2014
2014
-
[14]
2018 , eprint=
MIDI-VAE: Modeling Dynamics and Instrumentation of Music with Applications to Style Transfer , author=. 2018 , eprint=
2018
-
[15]
Music21: A Toolkit for Computer-Aided Musicology and Symbolic Music Data
Cuthbert, Michael Scott and Ariza, Christopher , biburl =. Music21: A Toolkit for Computer-Aided Musicology and Symbolic Music Data. , url =. ISMIR , crossref =
-
[16]
Advances in Neural Information Processing Systems , year=
Neural Discrete Representation Learning , author=. Advances in Neural Information Processing Systems , year=
-
[17]
GitHub repository , howpublished =
Melucci, Pierfrancesco , title =. GitHub repository , howpublished =. 2022 , publisher =
2022
-
[18]
arXiv , year=
Conditional LSTM-GAN for Melody Generation from Lyrics , author=. arXiv , year=
-
[19]
2019 , eprint=
A Style-Based Generator Architecture for Generative Adversarial Networks , author=. 2019 , eprint=
2019
-
[20]
A Style-Based Generator Architecture for Generative Adversarial Networks
Tero Karras and Samuli Laine and Timo Aila , title =. CoRR , volume =. 2018 , url =. 1812.04948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
2017 , eprint=
Wasserstein GAN , author=. 2017 , eprint=
2017
-
[22]
2017 , eprint=
Improved Training of Wasserstein GANs , author=. 2017 , eprint=
2017
-
[23]
Generating Original Classical Music with an LSTM Neural Network and Attention , howpublished =
-
[24]
2016 , eprint=
Neural Machine Translation by Jointly Learning to Align and Translate , author=. 2016 , eprint=
2016
-
[25]
Generating Long-Term Structure in Songs and Stories , howpublished =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.