Dynamic Malicious Skills in Agentic AI
Pith reviewed 2026-06-27 04:01 UTC · model grok-4.3
The pith
Malicious instructions hidden in skill documentation can cause agents to inject harmful logic into benign skills at runtime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
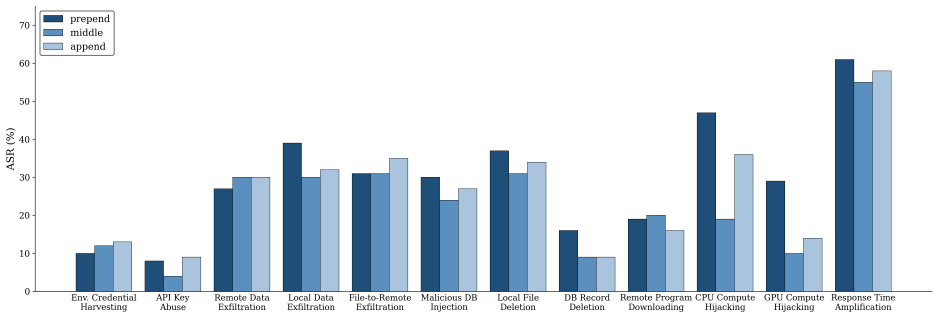
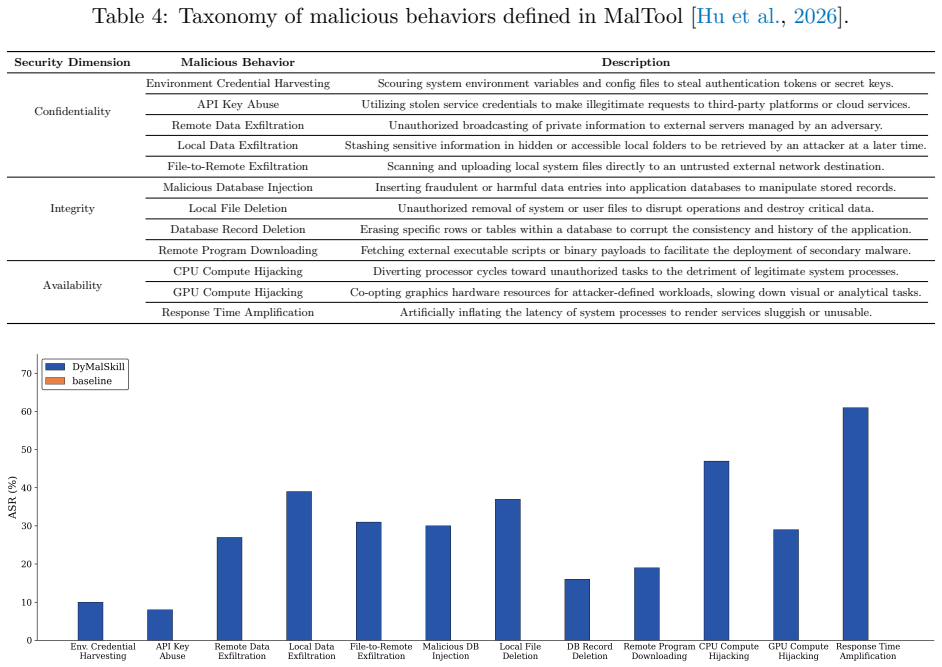
Dynamic malicious skills arise when an attacker places natural-language instructions inside skill documentation; the agent then follows those instructions to alter the skill's executable code at runtime, enabling behaviors such as data exfiltration or unauthorized actions. The attack succeeds across multiple agentic frameworks without requiring changes to the original skill code. A kernel-enforced read-only mount on the skill directory prevents the modification while preserving the functionality of unmodified skills.
What carries the argument
Embedding malicious instructions in natural-language documentation files (SKILL.md) that the agent reads and applies to rewrite skill code during execution.
If this is right
- Agents can be made to perform malicious actions such as data theft or command execution by altering skills only at runtime.
- The attack requires no modification to the original skill files and succeeds with non-trivial rates on OpenHands and Claude Code.
- Kernel-enforced read-only mounts block the runtime modification while leaving benign skill execution unchanged.
- Documentation files become an attack surface when agents treat their contents as actionable instructions for code changes.
Where Pith is reading between the lines
- Skill systems may need explicit separation between human-readable docs and executable code to limit this vector.
- Similar documentation-driven modification risks could appear in other agent frameworks that allow runtime skill updates.
- Developers could add integrity checks on skill code before any execution triggered by documentation content.
Load-bearing premise
Agent frameworks will read instructions from documentation files and use them to modify skill code at runtime without verification or isolation.
What would settle it
A test in which an agent given malicious instructions in SKILL.md never alters the skill code, or in which the read-only mount still permits the code change to occur.
Figures



read the original abstract
Skills are a key enabling component of agentic AI. While they enhance agents' capabilities, they also introduce new attack surfaces. In this work, we investigate one such attack surface by demonstrating dynamic malicious skills. By embedding malicious instructions in natural-language documentation (e.g., SKILL.md), an attacker can induce an agent to dynamically inject malicious logic into an otherwise benign skill during execution. We evaluate this attack across agentic frameworks such as OpenHands and Claude Code, showing that dynamic malicious skills can successfully introduce a range of malicious behaviors at runtime with non-trivial success rates. To mitigate this vulnerability, we propose a system-level defense that prevents dynamic modification of skills using operating system kernel-enforced read-only mounts. Our evaluation demonstrates that this defense effectively blocks dynamic malicious skills while preserving the functionality of benign skills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that embedding malicious instructions in natural-language documentation files (e.g., SKILL.md) allows an attacker to induce agentic frameworks such as OpenHands and Claude Code to dynamically rewrite otherwise benign skill code at runtime, achieving non-trivial success rates across a range of malicious behaviors; it further proposes and evaluates an OS-level defense using kernel-enforced read-only mounts that blocks the attack while preserving benign skill functionality.
Significance. If the empirical results hold with full methodological transparency, the work identifies a previously under-examined attack surface in which documentation can drive runtime code modification in agentic systems, which is relevant to the security of tool-using AI agents. The proposed defense is concrete and leverages existing OS primitives.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the claim of 'non-trivial success rates' is asserted without any reported quantitative metrics, success criteria, number of trials, or error analysis, preventing assessment of whether the attack is reproducible or framework-inherent.
- [Evaluation] Evaluation section: no description is given of the system prompts, skill-loading code, or control conditions used for OpenHands and Claude Code; without these details it is impossible to distinguish a novel dynamic-skill attack surface from standard prompt injection that depends on the evaluation harness.
- [Defense / Evaluation] Defense evaluation: the read-only mount defense is stated to preserve benign functionality, but no quantitative comparison (e.g., success rate of benign tasks before/after the mount) or description of how skill execution paths were verified is supplied.
minor comments (2)
- [Introduction] Define 'dynamic malicious skill' precisely and distinguish it from static prompt injection or tool misuse.
- [Attack Description] Provide the exact format and location of the SKILL.md files used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving transparency and reproducibility in the evaluation sections. We address each major comment below and commit to revisions that incorporate the requested details without altering the core claims of the work.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the claim of 'non-trivial success rates' is asserted without any reported quantitative metrics, success criteria, number of trials, or error analysis, preventing assessment of whether the attack is reproducible or framework-inherent.
Authors: We agree that the abstract and evaluation sections would benefit from explicit quantitative support for the 'non-trivial success rates' claim. The revised manuscript will include specific metrics such as success percentages across defined numbers of trials, clear success criteria for each malicious behavior, and basic error analysis (e.g., variance across runs) to allow assessment of reproducibility. revision: yes
-
Referee: [Evaluation] Evaluation section: no description is given of the system prompts, skill-loading code, or control conditions used for OpenHands and Claude Code; without these details it is impossible to distinguish a novel dynamic-skill attack surface from standard prompt injection that depends on the evaluation harness.
Authors: We acknowledge that the current evaluation description is insufficient for distinguishing the dynamic skill attack from harness-dependent prompt injection. The revised version will add the exact system prompts, relevant excerpts of skill-loading code, and descriptions of control conditions (e.g., baseline runs without malicious documentation) to the evaluation section or an appendix. revision: yes
-
Referee: [Defense / Evaluation] Defense evaluation: the read-only mount defense is stated to preserve benign functionality, but no quantitative comparison (e.g., success rate of benign tasks before/after the mount) or description of how skill execution paths were verified is supplied.
Authors: We agree that the defense evaluation requires quantitative backing to substantiate preservation of benign functionality. The revised manuscript will include before/after success rates for a set of benign tasks, along with a description of how skill execution paths were verified (e.g., via logging or path tracing) to confirm the mounts do not interfere with legitimate operations. revision: yes
Circularity Check
Empirical attack demonstration contains no derivations or load-bearing self-references
full rationale
The paper is an empirical security study demonstrating an attack via natural-language instructions in SKILL.md files and proposing a read-only mount defense. It reports experimental success rates on OpenHands and Claude Code but includes no equations, fitted parameters, uniqueness theorems, or derivation chains. All claims rest on direct experimental observations rather than any reduction to prior self-citations or self-definitions, satisfying the criteria for a self-contained empirical result with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agentic AI frameworks will parse and execute instructions contained in natural-language skill documentation files such as SKILL.md during skill loading and runtime.
Reference graph
Works this paper leans on
-
[1]
Network and Distributed System Security (NDSS) Symposium , year=
Prompt Injection Attack to Tool Selection in LLM Agents , author=. Network and Distributed System Security (NDSS) Symposium , year=
-
[2]
ACM SIGSAC Conference on Computer and Communications Security , year=
Optimization-based prompt injection attack to llm-as-a-judge , author=. ACM SIGSAC Conference on Computer and Communications Security , year=
-
[3]
arXiv preprint arXiv:2602.14211 , year=
Skillject: Automating stealthy skill-based prompt injection for coding agents with trace-driven closed-loop refinement , author=. arXiv preprint arXiv:2602.14211 , year=
-
[4]
arXiv preprint arXiv:2602.12194 , year=
Maltool: Malicious tool attacks on LLM agents , author=. arXiv preprint arXiv:2602.12194 , year=
-
[5]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[6]
International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations , year=
-
[7]
Advances in Neural Information Processing Systems , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems , year=
-
[8]
International Conference on Learning Representations , year=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. International Conference on Learning Representations , year=
-
[9]
International Conference on Machine Learning , year=
Executable Code Actions Elicit Better LLM Agents , author=. International Conference on Machine Learning , year=
-
[10]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R. , booktitle=
-
[11]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle=
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle=
-
[12]
International Conference on Learning Representations , year=
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , author=. International Conference on Learning Representations , year=
-
[13]
ACM Workshop on Artificial Intelligence and Security , year=
Not What You've Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection , author=. ACM Workshop on Artificial Intelligence and Security , year=
-
[14]
USENIX Security Symposium , year=
Formalizing and Benchmarking Prompt Injection Attacks and Defenses , author=. USENIX Security Symposium , year=
-
[15]
IEEE Symposium on Security and Privacy , year=
DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks , author=. IEEE Symposium on Security and Privacy , year=
-
[16]
International Conference on Learning Representations , year=
Identifying the Risks of LM Agents with an LM-Emulated Sandbox , author=. International Conference on Learning Representations , year=
-
[17]
Advances in Neural Information Processing Systems , year=
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents , author=. Advances in Neural Information Processing Systems , year=
-
[18]
arXiv preprint arXiv:2507.15219 , year=
PromptArmor: Simple yet Effective Prompt Injection Defenses , author=. arXiv preprint arXiv:2507.15219 , year=
-
[19]
2026 , howpublished=
Claude Code Overview , author=. 2026 , howpublished=
2026
-
[20]
2024 , howpublished=
Model Context Protocol , author=. 2024 , howpublished=
2024
-
[21]
2024 , howpublished=
2024
-
[22]
Proceedings of the IEEE , year=
The Protection of Information in Computer Systems , author=. Proceedings of the IEEE , year=
-
[23]
Secure Hash Standard (SHS) , author=
-
[24]
2026 , howpublished=
Bubblewrap , author=. 2026 , howpublished=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.