Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
Pith reviewed 2026-06-27 04:15 UTC · model grok-4.3
The pith
Natural language serves as the unified action interface for a video model that generates physically grounded future trajectories across robotic manipulation, driving, navigation, and human-to-robot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A single language-conditioned video generation model can function as an embodied world model by predicting physically grounded future visual trajectories from current observations, using natural language as the common action representation across robotic manipulation, autonomous driving, indoor navigation, and human-to-robot transfer.
What carries the argument
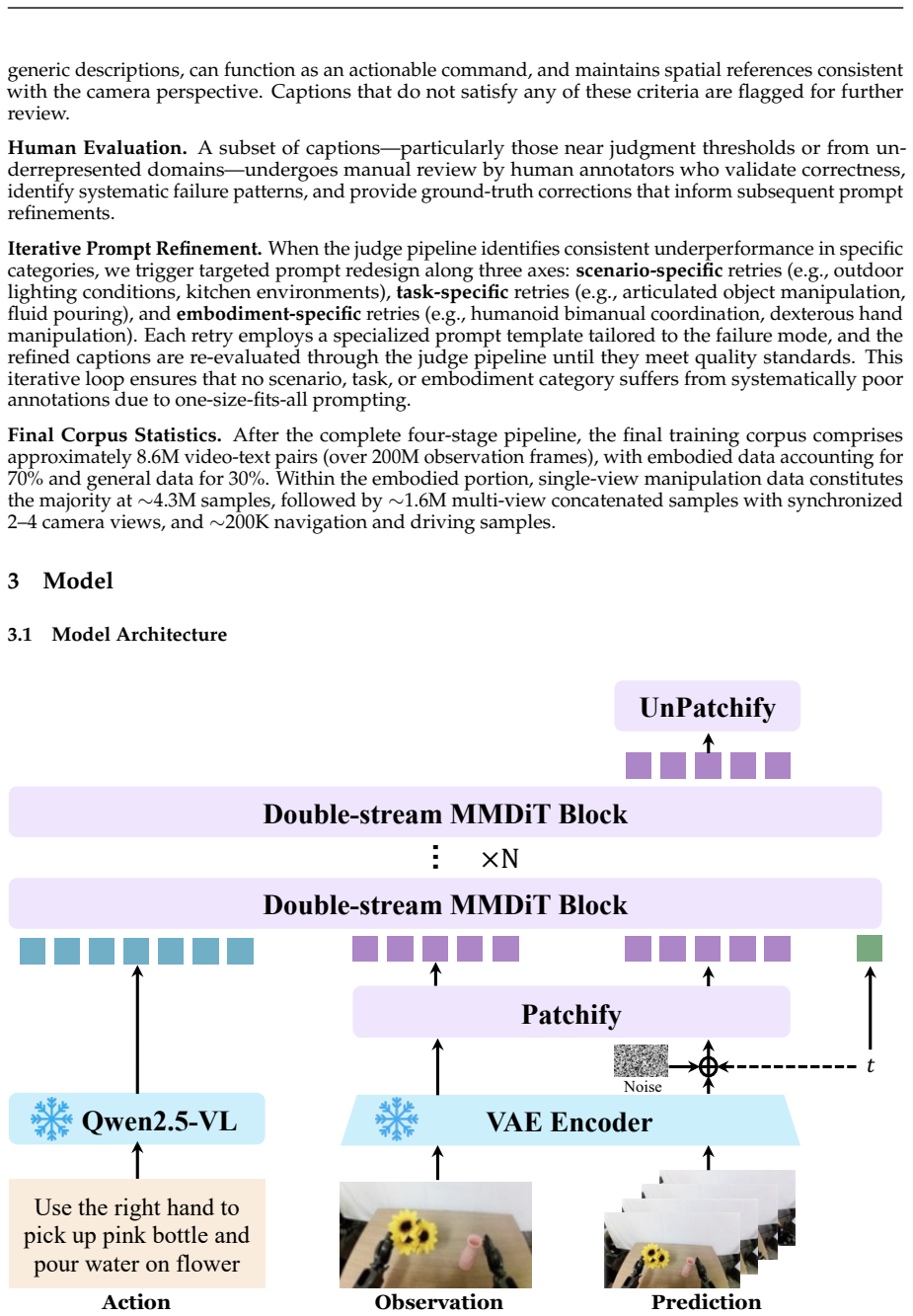
Double-Stream MMDiT with MLLM Action Encoding, which couples frozen Qwen2.5-VL semantics to video-VAE latents via layer-wise joint attention in a 60-layer diffusion transformer, together with the Embodied World Knowledge corpus of 8.6M video-text pairs and the General+Expert Progressive Curriculum.
If this is right
- The model can generate synthetic video data to augment policy training in multiple robot domains.
- It supplies scalable virtual environments for evaluating policies without real hardware.
- Language instructions can serve as planning signals that guide downstream robot control.
- Zero-shot generalization across embodiments is supported by the shared language interface and curriculum.
Where Pith is reading between the lines
- If the unification holds, language may replace specialized low-level action spaces when training policies for heterogeneous robot hardware.
- Closed-loop integration with real robot controllers would be a direct next test of whether the predicted trajectories remain useful under feedback.
- Extending the same architecture to longer time horizons or multi-agent interactions could be checked on existing benchmarks without new data collection.
Load-bearing premise
The combination of the 8.6M video-text corpus and the double-stream coupling of semantics with video latents produces accurate physical trajectories without any additional domain-specific mechanisms.
What would settle it
Demonstration that the generated trajectories systematically violate basic physical constraints, such as object penetration or incorrect motion under gravity, on a held-out multi-embodiment test set would falsify the claim of physically grounded prediction.
Figures







read the original abstract
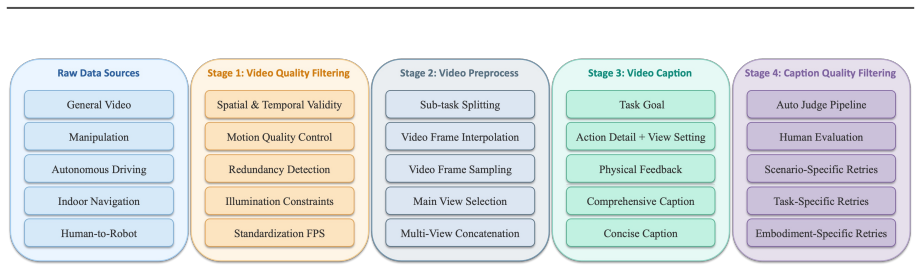
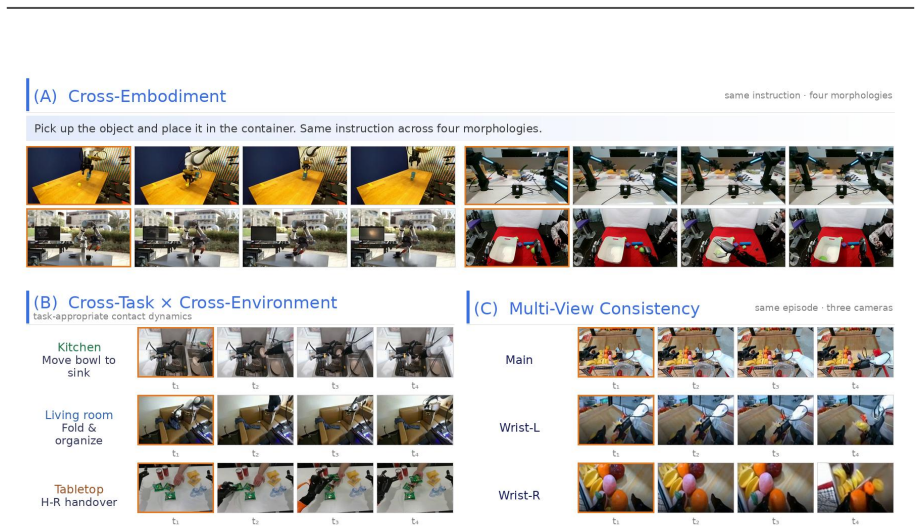
We introduce Qwen-RobotWorld, a language-conditioned video world model for embodied intelligence. With natural language as a unified action interface, it predicts physically grounded future visual trajectories from current observations across robotic manipulation, autonomous driving, indoor navigation, and human-to-robot transfer. This unified formulation provides three promising application directions: synthetic data generation for policy training augmentation, scalable virtual environments for policy evaluation, and language-guided planning signals for downstream robot control. This is achieved through a three-part design: a) Double-Stream MMDiT with MLLM Action Encoding, where a 60-layer double-stream diffusion transformer couples frozen Qwen2.5-VL semantics with video-VAE latents through layer-wise joint attention; b) Embodied World Knowledge (EWK), an 8.6M video-text corpus (200M+ frames) with action-language mapping over 20+ embodiments and 500+ action categories; and c) General+Expert Progressive Curriculum, a two-stage training strategy that first learns general visual priors and then injects embodied specialization under a shared language interface. Extensive results show strong competitiveness: ranks 1st overall on EWMBench and DreamGen Bench, outperforms all open-source models on WorldModelBench and PBench. Additional zero-shot analyses on RoboTwin-IF benchmark further support robust generalization and multi-view consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Qwen-RobotWorld, a language-conditioned video world model for embodied intelligence. With natural language as a unified action interface, it predicts physically grounded future visual trajectories from current observations across robotic manipulation, autonomous driving, indoor navigation, and human-to-robot transfer. This is achieved via a three-part design: (a) Double-Stream MMDiT with MLLM Action Encoding (60-layer diffusion transformer coupling frozen Qwen2.5-VL semantics with video-VAE latents via layer-wise joint attention), (b) Embodied World Knowledge (EWK) corpus of 8.6M video-text pairs (200M+ frames) with action-language mapping over 20+ embodiments and 500+ action categories, and (c) General+Expert Progressive Curriculum (two-stage training for general visual priors then embodied specialization). The model claims 1st overall on EWMBench and DreamGen Bench, outperforming all open-source models on WorldModelBench and PBench, plus zero-shot generalization on RoboTwin-IF, with applications in synthetic data generation, virtual environments, and language-guided planning.
Significance. If the benchmark rankings and generalization claims hold under rigorous verification, the work would be significant for providing a unified language-conditioned world model spanning multiple embodied domains and embodiments. The scale of the EWK corpus, the Double-Stream MMDiT architecture, and the progressive curriculum represent concrete engineering contributions that could support downstream uses in policy training and evaluation. The cross-embodiment coverage and zero-shot analyses are particular strengths worth highlighting if substantiated.
major comments (2)
- [Abstract] Abstract and results sections: the manuscript states top rankings on EWMBench, DreamGen Bench, WorldModelBench, and PBench but supplies no information on evaluation protocols, baseline implementations, statistical tests, number of runs, or failure modes. These details are load-bearing for the central performance claims and must be added for the results to be verifiable.
- [Abstract] The weakest assumption (physical grounding and cross-embodiment generalization from the 8.6M corpus and Double-Stream MMDiT) is not directly tested or falsified in the provided text; if the full manuscript contains only benchmark rankings without ablation on physical accuracy metrics or embodiment-specific controls, this remains an unaddressed risk to the unification claim.
minor comments (2)
- [Abstract] The abstract mentions "extensive results" and "additional zero-shot analyses" but does not reference specific tables, figures, or sections containing the quantitative data; adding explicit pointers would improve readability.
- [§3] Notation for the Double-Stream MMDiT (e.g., exact definition of layer-wise joint attention and how frozen Qwen2.5-VL outputs are injected) could be clarified with a diagram or equation if not already present in §3.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on verifiability and the strength of our unification claims. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract and results sections: the manuscript states top rankings on EWMBench, DreamGen Bench, WorldModelBench, and PBench but supplies no information on evaluation protocols, baseline implementations, statistical tests, number of runs, or failure modes. These details are load-bearing for the central performance claims and must be added for the results to be verifiable.
Authors: We agree that these details are essential for verifiability. The revised manuscript will include an expanded Experiments section with: (1) full evaluation protocols for each benchmark, (2) descriptions of baseline implementations and reproduction steps, (3) statistical tests and confidence intervals, (4) the number of runs per experiment, and (5) a dedicated failure-mode analysis. These additions will be placed before the main results tables. revision: yes
-
Referee: [Abstract] The weakest assumption (physical grounding and cross-embodiment generalization from the 8.6M corpus and Double-Stream MMDiT) is not directly tested or falsified in the provided text; if the full manuscript contains only benchmark rankings without ablation on physical accuracy metrics or embodiment-specific controls, this remains an unaddressed risk to the unification claim.
Authors: The benchmarks already embed physical-grounding metrics (e.g., trajectory consistency under dynamics, collision avoidance, and embodiment transfer success) and cross-embodiment splits. Nevertheless, we acknowledge the value of explicit controls. The revision will add a new subsection with (a) quantitative physical-accuracy ablations (physics-violation rates, dynamics consistency scores) and (b) embodiment-specific controls that isolate the contribution of the shared language interface versus domain-specific data. These will directly test the unification hypothesis. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an architecture (Double-Stream MMDiT), a data corpus (EWK 8.6M video-text pairs), and a training curriculum, then reports external benchmark rankings (EWMBench, DreamGen Bench, WorldModelBench, PBench). No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims rest on benchmark comparisons rather than any internal reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video-VAE latents preserve sufficient physical information for trajectory prediction when coupled with MLLM semantics
Reference graph
Works this paper leans on
-
[1]
Llama: Open and efficient foundation language models , author=. arXiv:2302.13971 , year=
-
[2]
arXiv preprint arXiv:2503.20314 , year=
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
-
[3]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[4]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[5]
arXiv preprint arXiv:2209.03003 , year=
Flow straight and fast: Learning to generate and transfer data with rectified flow , author=. arXiv preprint arXiv:2209.03003 , year=
-
[6]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[7]
Journal of artificial intelligence research , volume=
Reinforcement learning: A survey , author=. Journal of artificial intelligence research , volume=
-
[8]
Proceedings of Machine Learning and Systems , volume=
Reducing activation recomputation in large transformer models , author=. Proceedings of Machine Learning and Systems , volume=
-
[10]
arXiv preprint arXiv:2304.11277 , year=
Pytorch fsdp: experiences on scaling fully sharded data parallel , author=. arXiv preprint arXiv:2304.11277 , year=
-
[11]
Advances in neural information processing systems , volume=
Gpipe: Efficient training of giant neural networks using pipeline parallelism , author=. Advances in neural information processing systems , volume=
-
[12]
13th USENIX symposium on operating systems design and implementation (OSDI 18) , pages=
Ray: A distributed framework for emerging \ AI \ applications , author=. 13th USENIX symposium on operating systems design and implementation (OSDI 18) , pages=
-
[13]
ICML , year=
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author=. ICML , year=
-
[14]
Advances in neural information processing systems , volume=
Root mean square layer normalization , author=. Advances in neural information processing systems , volume=
-
[15]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. arXiv:2301.12597 , year=
-
[16]
GPT-4 technical report , author=. arXiv:2303.08774 , year=
-
[17]
NeurIPS , year=
Perception test: A diagnostic benchmark for multimodal video models , author=. NeurIPS , year=
-
[18]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis , author=. arXiv:2405.21075 , year=
-
[19]
NeurIPS , year=
Egoschema: A diagnostic benchmark for very long-form video language understanding , author=. NeurIPS , year=
-
[20]
CVPR , year=
Mvbench: A comprehensive multi-modal video understanding benchmark , author=. CVPR , year=
- [21]
-
[22]
2024 , journal=
MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI , author=. 2024 , journal=
2024
-
[23]
MMBench: Is Your Multi-modal Model an All-around Player? , year =
Yuan Liu and Haodong Duan and Yuanhan Zhang, Bo Li and Songyang Zhang and Wangbo Zhao and Yike Yuan and Jiaqi Wang and Conghui He and Ziwei Liu and Kai Chen and Dahua Lin , journal =. MMBench: Is Your Multi-modal Model an All-around Player? , year =
-
[24]
2023 , journal=
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination & Visual Illusion in Large Vision-Language Models , author=. 2023 , journal=
2023
-
[25]
Grok-1.5 vision preview , year =
-
[26]
Grok-2 Beta Release , year =
-
[27]
Are We on the Right Way for Evaluating Large Vision-Language Models? , author=. arXiv:2403.20330 , year=
-
[28]
ICML , year=
Mm-vet: Evaluating large multimodal models for integrated capabilities , author=. ICML , year=
-
[29]
NeurIPS , year=
Flamingo: a visual language model for few-shot learning , author=. NeurIPS , year=
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vila: On pre-training for visual language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[31]
arXiv preprint arXiv:2406.08418 , year=
OmniCorpus: An Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text , author=. arXiv preprint arXiv:2406.08418 , year=
-
[32]
and Stoica, Ion and Xing, Eric P
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P. , year =. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90\ url =
- [33]
-
[34]
LVLM-eHub: A Comprehensive Evaluation Benchmark for Large Vision-Language Models , author=. arXiv:2306.09265 , year=
-
[35]
NeurIPS , year=
Language models are few-shot learners , author=. NeurIPS , year=
-
[36]
Visual instruction tuning , author=. arXiv:2304.08485 , year=
-
[37]
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv:2304.10592 , year=
-
[38]
The dawn of lmms: Preliminary explorations with gpt-4v (ision) , author=. arXiv:2309.17421 , year=
-
[39]
Our World in Data , year =
Hannah Ritchie and Veronika Samborska and Max Roser , title =. Our World in Data , year =
-
[43]
arXiv preprint arXiv:2307.06281 , year=
Mmbench: Is your multi-modal model an all-around player? , author=. arXiv preprint arXiv:2307.06281 , year=
-
[44]
2024 , eprint=
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding , author=. 2024 , eprint=
2024
-
[45]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. arXiv:2311.16502 , year=
-
[46]
Llama-adapter: Efficient fine-tuning of language models with zero-init attention , author=. arXiv:2303.16199 , year=
-
[47]
Manning and Stefano Ermon and Chelsea Finn , editor =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , booktitle =. 2023 , url =
2023
-
[48]
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. arXiv:2305.06500 , year=
-
[49]
mplug-owl: Modularization empowers large language models with multimodality , author=. arXiv:2304.14178 , year=
-
[50]
Llama-adapter v2: Parameter-efficient visual instruction model , author=. arXiv:2304.15010 , year=
-
[51]
Otter: A multi-modal model with in-context instruction tuning , author=. arXiv:2305.03726 , year=
-
[52]
Pandagpt: One model to instruction-follow them all , author=. arXiv:2305.16355 , year=
-
[53]
What Makes for Good Visual Tokenizers for Large Language Models? , author=. arXiv:2305.12223 , year=
-
[54]
Evaluating object hallucination in large vision-language models , author=. arXiv:2305.10355 , year=
-
[55]
Microsoft coco captions: Data collection and evaluation server , author=. arXiv:1504.00325 , year=
-
[56]
International journal of computer vision , volume=
Visual genome: Connecting language and vision using crowdsourced dense image annotations , author=. International journal of computer vision , volume=. 2017 , publisher=
2017
-
[57]
Laion-5b: An open large-scale dataset for training next generation image-text models , author=. arXiv:2210.08402 , year=
-
[58]
, author=
Laion coco: 600m synthetic captions from laion2b-en. , author=. https://laion.ai/blog/laion-coco/ , year=
-
[59]
DataComp: In search of the next generation of multimodal datasets , author=. arXiv:2304.14108 , year=
-
[60]
2022 , url =
COYO-700M: Image-Text Pair Dataset , author =. 2022 , url =
2022
-
[61]
CVPR , year=
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts , author=. CVPR , year=
-
[62]
ACL , year=
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning , author=. ACL , year=
-
[63]
NeurIPS , year=
Im2text: Describing images using 1 million captioned photographs , author=. NeurIPS , year=
-
[64]
Pali: A jointly-scaled multilingual language-image model , author=. arXiv:2209.06794 , year=
-
[65]
ICML , year=
Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework , author=. ICML , year=
-
[66]
NeurIPS , year=
Training language models to follow instructions with human feedback , author=. NeurIPS , year=
-
[67]
Palm 2 technical report , author=. arXiv:2305.10403 , year=
-
[68]
ICCV , year=
nocaps: novel object captioning at scale , author=. ICCV , year=
-
[69]
CVPR , year=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. CVPR , year=
-
[70]
ECCV , year=
Textcaps: a dataset for image captioning with reading comprehension , author=. ECCV , year=
-
[71]
CVPR , year=
Imagenet: A large-scale hierarchical image database , author=. CVPR , year=
-
[72]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension , author=. arXiv:2307.16125 , year=
-
[73]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , author=. arXiv:2306.13394 , year=
-
[74]
Opt: Open pre-trained transformer language models , author=. arXiv:2205.01068 , year=
-
[75]
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena , author=. arXiv:2306.05685 , year=
-
[76]
OpenAI blog , year=
Language models are unsupervised multitask learners , author=. OpenAI blog , year=
-
[77]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. arXiv:1810.04805 , year=
-
[78]
JMLR , year=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. JMLR , year=
-
[79]
CVPR , year=
Masked autoencoders are scalable vision learners , author=. CVPR , year=
-
[80]
Beit: Bert pre-training of image transformers , author=. arXiv:2106.08254 , year=
-
[81]
OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models , author=. arXiv:2212.04408 , year=
-
[82]
ICML , year=
Generative pretraining from pixels , author=. ICML , year=
-
[83]
Language is not all you need: Aligning perception with language models , author=. arXiv:2302.14045 , year=
-
[84]
ECCV , year=
Microsoft coco: Common objects in context , author=. ECCV , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.