Shift-Left High-Level Synthesis Verification via Knowledge-Augmented LLM Agent
Pith reviewed 2026-06-27 02:45 UTC · model grok-4.3
The pith
A knowledge-augmented LLM agent with dual-tier checks verifies functional consistency between original C and HLS-C code before synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
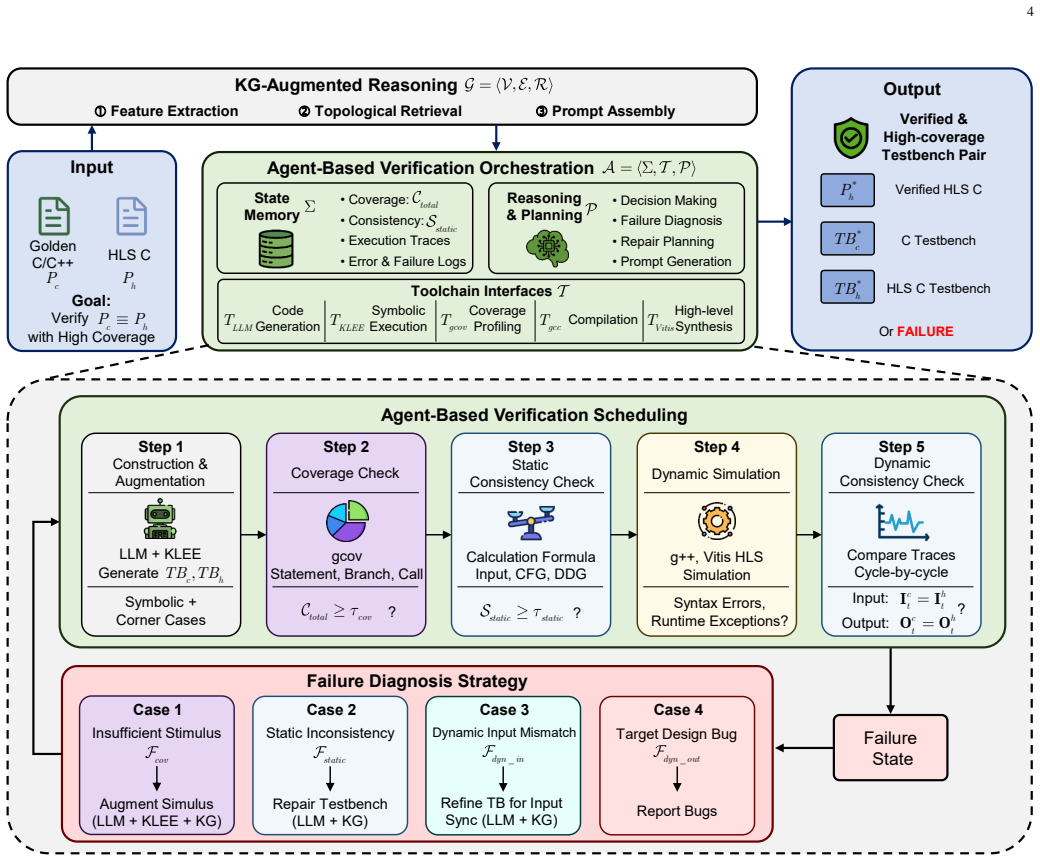
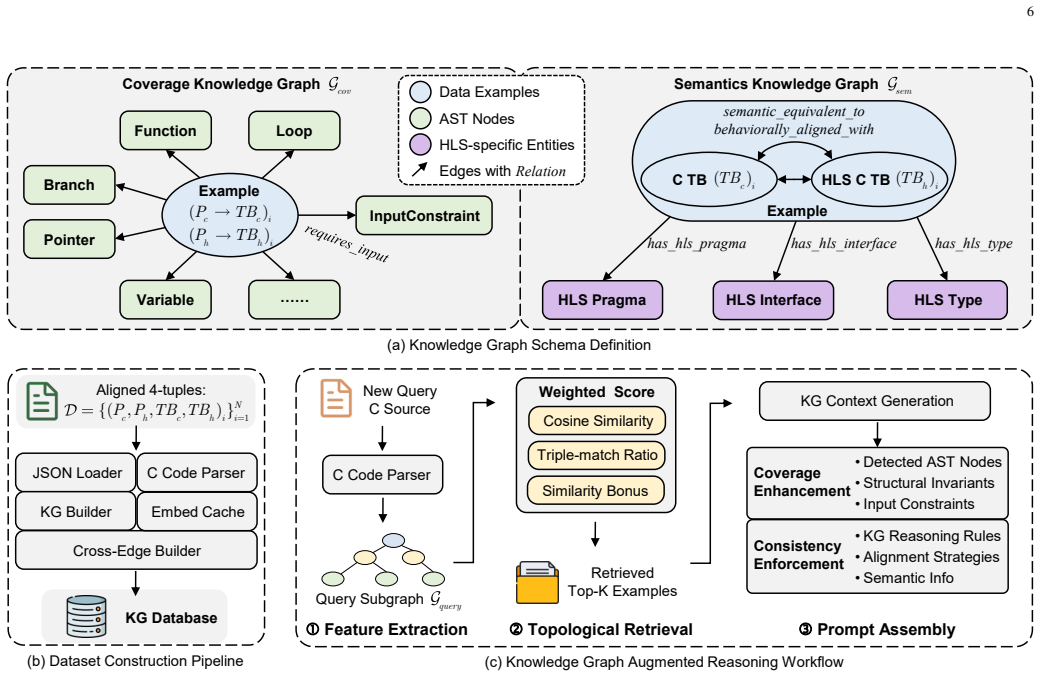
The framework introduces a Dual-Tier Consistency Checking mechanism that jointly enforces static structural alignment and dynamic behavioral equivalence between paired testbenches, while integrating symbolic execution and coverage-driven refinement to improve verification completeness. Furthermore, we construct a heterogeneous HLS Verification Knowledge Graph to provide topology-aware reasoning priors for testbench generation, and design an autonomous verification agent to orchestrate iterative refinement and failure diagnosis across heterogeneous toolchains. Experimental results on 107 HLS benchmark pairs demonstrate that the proposed framework achieves 0.9826 average coverage and 0.9533 dy
What carries the argument
Dual-Tier Consistency Checking mechanism that jointly enforces static structural alignment and dynamic behavioral equivalence, supported by a heterogeneous HLS Verification Knowledge Graph for topology-aware reasoning priors.
If this is right
- Verification moves before synthesis, enabling earlier detection of functional mismatches in the HLS flow.
- The autonomous agent performs iterative refinement and cross-toolchain failure diagnosis without manual intervention.
- Coverage-driven refinement combined with symbolic execution raises average coverage above 0.98 on benchmark pairs.
- Dynamic consistency reaches 0.95 while outperforming AST-based, retrieval-augmented, and plain iterative agent baselines.
Where Pith is reading between the lines
- The same dual-tier structure and knowledge-graph priors could be adapted to verify other source-to-source transformations such as compiler passes or domain-specific language translations.
- Extending the knowledge graph with additional hardware-specific equivalence rules might further reduce false consistency signals on edge-case arithmetic or pointer behaviors.
- Integration into commercial HLS tools could shorten the manual testbench creation loop that currently dominates early design effort.
Load-bearing premise
The Dual-Tier Consistency Checking mechanism together with the heterogeneous HLS Verification Knowledge Graph supplies unbiased, sufficiently complete priors that do not systematically miss equivalence failures or produce false consistency signals.
What would settle it
A pair of original C and HLS-C implementations that differ in observable behavior yet receive high structural alignment and dynamic consistency scores from the framework.
Figures

read the original abstract
High-Level Synthesis (HLS) relies on transforming original C specifications into synthesizable HLS-oriented C (HLS-C) implementations. Functional consistency verification between original C specifications and HLS-C implementations is a critical yet labor-intensive task in HLS design flows. While Large Language Models (LLMs) have recently shown promise in automated testbench generation, their stochastic nature often leads to insufficient coverage, inconsistent verification environments, and unreliable equivalence checking results. To address these limitations, we propose a knowledge-augmented, agent-driven shift-left verification framework for automated functional consistency checking between original C and HLS-C implementations before synthesis. The framework introduces a Dual-Tier Consistency Checking mechanism that jointly enforces static structural alignment and dynamic behavioral equivalence between paired testbenches, while integrating symbolic execution and coverage-driven refinement to improve verification completeness. Furthermore, we construct a heterogeneous HLS Verification Knowledge Graph to provide topology-aware reasoning priors for testbench generation, and design an autonomous verification agent to orchestrate iterative refinement and failure diagnosis across heterogeneous toolchains. Experimental results on 107 HLS benchmark pairs demonstrate that the proposed framework achieves 0.9826 average coverage and 0.9533 dynamic consistency, outperforming representative AST-based, retrieval-augmented, and iterative agent-based baselines. https://github.com/cz-5f/HLS-LeVeri.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a knowledge-augmented LLM agent framework for shift-left functional consistency verification between original C specifications and HLS-C implementations. It introduces a Dual-Tier Consistency Checking mechanism (static structural alignment plus dynamic behavioral equivalence via symbolic execution and coverage refinement), a heterogeneous HLS Verification Knowledge Graph for topology-aware priors, and an autonomous verification agent for iterative refinement and diagnosis. On 107 HLS benchmark pairs the framework reports 0.9826 average coverage and 0.9533 dynamic consistency, outperforming AST-based, retrieval-augmented, and iterative agent baselines. The GitHub repository is provided for reproducibility.
Significance. If the empirical results hold under rigorous validation, the work could meaningfully reduce manual verification effort in HLS design flows by combining LLM agents with structured knowledge and dual-tier checks. The open-source code release is a clear strength that supports reproducibility and future extensions.
major comments (2)
- [Abstract / §4] Abstract / §4 (Experimental Results): The headline performance numbers (0.9826 coverage, 0.9533 consistency on 107 pairs) are presented without any description of benchmark selection criteria, re-implementation details for the three baseline categories, statistical significance testing, or analysis of failure cases. These omissions make it impossible to determine whether the reported superiority is load-bearing for the central claim.
- [§3.2 / §3.3] §3.2 (Dual-Tier Consistency Checking) and §3.3 (Knowledge Graph): The paper supplies no independent validation set of known non-equivalent C/HLS-C pairs. Without such a test, it remains unclear whether the static/dynamic checks and graph priors systematically miss equivalence failures (e.g., data-dependent control flow or synthesis-induced transformations) or produce false consistency signals, directly affecting the reliability of the 0.9533 dynamic consistency metric.
minor comments (1)
- [Abstract] The abstract states the GitHub link but the manuscript does not indicate which artifacts (benchmarks, scripts, or trained models) are actually released.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested details and validation experiments.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract / §4 (Experimental Results): The headline performance numbers (0.9826 coverage, 0.9533 consistency on 107 pairs) are presented without any description of benchmark selection criteria, re-implementation details for the three baseline categories, statistical significance testing, or analysis of failure cases. These omissions make it impossible to determine whether the reported superiority is load-bearing for the central claim.
Authors: We agree that these details are necessary to substantiate the empirical claims. In the revised manuscript we will expand §4 to include: (1) explicit benchmark selection criteria, describing how the 107 pairs were drawn from standard HLS suites (CHStone, PolyBench, and representative industrial designs) with diversity requirements on control-flow complexity and data dependencies; (2) re-implementation details for the AST-based, RAG, and iterative-agent baselines, including the concrete algorithms, retrieval configurations, and prompt templates employed; (3) statistical significance testing (paired t-tests and bootstrap confidence intervals) on the reported differences; and (4) a failure-case analysis that categorizes the small number of pairs where full consistency was not reached and discusses root causes. These additions will make the superiority claims verifiable. revision: yes
-
Referee: [§3.2 / §3.3] §3.2 (Dual-Tier Consistency Checking) and §3.3 (Knowledge Graph): The paper supplies no independent validation set of known non-equivalent C/HLS-C pairs. Without such a test, it remains unclear whether the static/dynamic checks and graph priors systematically miss equivalence failures (e.g., data-dependent control flow or synthesis-induced transformations) or produce false consistency signals, directly affecting the reliability of the 0.9533 dynamic consistency metric.
Authors: This is a fair and important observation. Our current evaluation uses pairs that are intended to be functionally equivalent after HLS transformation. To directly address the concern, we will add a controlled validation experiment in the revised §4 (or an appendix). We will create a set of known non-equivalent pairs by injecting targeted discrepancies—such as altered loop bounds, modified conditional logic, or synthesis-incompatible constructs—into a subset of the benchmarks. We will then measure the framework’s detection rate for these inconsistencies, reporting both true-positive detection and any false-consistency signals. This will provide quantitative evidence on the sensitivity of the dual-tier checks and the 0.9533 metric. revision: yes
Circularity Check
No significant circularity: empirical evaluation on external benchmarks
full rationale
The paper proposes an LLM-agent framework with a Dual-Tier Consistency Checking mechanism and a heterogeneous HLS Verification Knowledge Graph, then reports empirical measurements (0.9826 average coverage, 0.9533 dynamic consistency) on 107 external HLS benchmark pairs. No derivation chain, fitted parameters, or self-citation load-bearing steps exist; the headline numbers are direct experimental outcomes rather than quantities forced by construction from the framework's own priors or inputs. The evaluation uses independent benchmarks and compares against external baselines, keeping the result self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A review on ai acceleration with fpga and asics: A comparative study,
M. Kotari, S. Kanabargi, S. Aloriet al., “A review on ai acceleration with fpga and asics: A comparative study,” in2025 IEEE 4th International Conference on Data, Decision and Systems (ICDDS). IEEE, 2025, pp. 212–215
2025
-
[2]
A survey on convolutional neural network accelerators: Gpu, fpga and asic,
Y . Hu, Y . Liu, and Z. Liu, “A survey on convolutional neural network accelerators: Gpu, fpga and asic,” in2022 14th International Conference on Computer Research and Development (ICCRD). IEEE, 2022, pp. 100–107
2022
-
[3]
Enhancing asic hls design optimization via knowledge transfer from fpga hls models,
S. Zheng, Z. Ding, C. Wang, B. Yu, M. Wong, Y . Sun, and J. Cong, “Enhancing asic hls design optimization via knowledge transfer from fpga hls models,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2026
2026
-
[4]
Hls-based optimization and design space explo- ration for applications with variable loop bounds,
Y .-k. Choi and J. Cong, “Hls-based optimization and design space explo- ration for applications with variable loop bounds,” in2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2018, pp. 1–8
2018
-
[5]
Universal verification methodology (uvm) 1.2 user’s guide,
A. Initiative, “Universal verification methodology (uvm) 1.2 user’s guide,”Accellera Systems Initiative: Elk Grove, CA, USA, 2015
2015
-
[6]
High-level synthesis: Past, present, and future,
G. Martin and G. Smith, “High-level synthesis: Past, present, and future,” IEEE Design & Test of Computers, vol. 26, no. 4, pp. 18–25, 2009
2009
-
[7]
Legup: high-level synthesis for fpga-based processor/accelerator systems,
A. Canis, J. Choi, M. Aldham, V . Zhang, A. Kammoona, J. H. An- derson, S. Brown, and T. Czajkowski, “Legup: high-level synthesis for fpga-based processor/accelerator systems,” inProceedings of the 19th ACM/SIGDA international symposium on Field programmable gate arrays, 2011, pp. 33–36
2011
-
[8]
Fpga- based solution for on-board verification of hardware modules using hls,
J. Caba, F. Rinc ´on, J. Barba, J. A. de la Torre, and J. C. L ´opez, “Fpga- based solution for on-board verification of hardware modules using hls,” Electronics, vol. 9, no. 12, p. 2024, 2020
2024
-
[9]
A shift-left approach in qualifi- cation of digital ips for socs by applying advanced automation and data analytics,
H. J. Chakraborty and D. K. Acharya, “A shift-left approach in qualifi- cation of digital ips for socs by applying advanced automation and data analytics,” in2024 28th International Symposium on VLSI Design and Test (VDAT). IEEE, 2024, pp. 1–5. 10
2024
-
[10]
A. Jain, D. H. Gupta, S. Jana, and K. Kumar, “Early development of uvm based verification environment of image signal processing designs using tlm reference model of rtl,”arXiv preprint arXiv:1408.1150, 2014
Pith/arXiv arXiv 2014
-
[11]
Hlstrans: Dataset for c-to-hls hardware code synthesis,
Q. Zou, N. Chen, Y . Chen, B. He, and W. Wong, “Hlstrans: Dataset for c-to-hls hardware code synthesis,” 2025. [Online]. Available: https://arxiv.org/abs/2507.04315
arXiv 2025
-
[12]
Hlstester: Efficient testing of behavioral discrepancies with llms for high-level synthesis,
K. Xu, B. Li, G. L. Zhang, and U. Schlichtmann, “Hlstester: Efficient testing of behavioral discrepancies with llms for high-level synthesis,” in 2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 2025, pp. 1–9
2025
-
[13]
Hls-eval: A benchmark and framework for evaluating llms on high-level synthesis design tasks,
S. Abi-Karam and C. Hao, “Hls-eval: A benchmark and framework for evaluating llms on high-level synthesis design tasks,” in2025 IEEE International Conference on LLM-Aided Design (ICLAD). IEEE, Jun. 2025, p. 219–226. [Online]. Available: http://dx.doi.org/10.1109/ ICLAD65226.2025.00021
arXiv 2025
-
[14]
Rtllm: An open-source benchmark for design rtl generation with large language model,
Y . Lu, S. Liu, Q. Zhang, and Z. Xie, “Rtllm: An open-source benchmark for design rtl generation with large language model,” in2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2024, pp. 722–727
2024
-
[15]
Llms will always hallucinate, and we need to live with this,
S. Banerjee, A. Agarwal, and S. Singla, “Llms will always hallucinate, and we need to live with this,” inIntelligent Systems Conference. Springer, 2025, pp. 624–648
2025
-
[16]
Formal verification of high-level synthesis,
Y . Herklotz, J. D. Pollard, N. Ramanathan, and J. Wickerson, “Formal verification of high-level synthesis,”Proceedings of the ACM on Pro- gramming Languages, vol. 5, no. OOPSLA, pp. 1–30, 2021
2021
-
[17]
Verification of scheduling of conditional behaviors in high-level synthesis,
R. Chouksey and C. Karfa, “Verification of scheduling of conditional behaviors in high-level synthesis,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 28, no. 7, pp. 1638–1651, 2020
2020
-
[18]
Hlspilot: Llm-based high-level synthesis,
C. Xiong, C. Liu, H. Li, and X. Li, “Hlspilot: Llm-based high-level synthesis,”arXiv preprint arXiv:2408.06810, 2024
arXiv 2024
-
[19]
Reliable graph-rag for codebases: Ast-derived graphs vs llm-extracted knowledge graphs,
M. R. Chinthareddy, “Reliable graph-rag for codebases: Ast-derived graphs vs llm-extracted knowledge graphs,” 2026. [Online]. Available: https://arxiv.org/abs/2601.08773
arXiv 2026
-
[20]
Knowledge graph based repository-level code generation,
M. Athale and V . Vaddina, “Knowledge graph based repository-level code generation,” in2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code), 2025, pp. 169–176
2025
-
[21]
Synthai: A multi agent generative ai framework for automated modular hls design generation,
S. A. Sheikholeslam and A. Ivanov, “Synthai: A multi agent generative ai framework for automated modular hls design generation,” 2024. [Online]. Available: https://arxiv.org/abs/2405.16072
arXiv 2024
-
[22]
R. Qiu, G. L. Zhang, R. Drechsler, T. Ho, U. Schlichtmann, and B. Li, “Confibench: Automatic testbench generation with confidence-based scenario mask and testbench ensemble using llms for hdl design,”ACM Trans. Des. Autom. Electron. Syst., Oct. 2025, just Accepted. [Online]. Available: https://doi.org/10.1145/3773087
-
[23]
Klee: unassisted and automatic generation of high-coverage tests for complex systems programs
C. Cadar, D. Dunbar, D. R. Engleret al., “Klee: unassisted and automatic generation of high-coverage tests for complex systems programs.” in OSDI, vol. 8, 2008, pp. 209–224
2008
-
[24]
A formal verification method of scheduling in high-level synthesis,
C. Karfa, C. Mandal, D. Sarkar, S. R. Pentakota, and C. Reade, “A formal verification method of scheduling in high-level synthesis,” in 7th International Symposium on Quality Electronic Design (ISQED’06). IEEE, 2006, pp. 6–pp
2006
-
[25]
A study about the effi- ciency of formal high-level synthesis applied to verification,
J. M. Mendias, R. Hermida, and O. Pe ˜nalba, “A study about the effi- ciency of formal high-level synthesis applied to verification,”Integration, vol. 31, no. 2, pp. 101–131, 2002
2002
-
[26]
C2hlsc: Leveraging large language models to bridge the software-to-hardware design gap,
L. Collini, S. Garg, and R. Karri, “C2hlsc: Leveraging large language models to bridge the software-to-hardware design gap,” ACM Transactions on Design Automation of Electronic Systems, vol. 30, no. 6, p. 1–24, Oct. 2025. [Online]. Available: http: //dx.doi.org/10.1145/3734524
-
[27]
Hlsdebugger: Identification and cor- rection of logic bugs in hls code with llm solutions,
J. Wang, S. Liu, Y . Lu, and Z. Xie, “Hlsdebugger: Identification and cor- rection of logic bugs in hls code with llm solutions,” in2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 2025, pp. 1–9
2025
-
[28]
Software unit test coverage and adequacy,
H. Zhu, P. A. Hall, and J. H. May, “Software unit test coverage and adequacy,”Acm computing surveys (csur), vol. 29, no. 4, pp. 366–427, 1997
1997
-
[29]
Llm4dv: Using large language models for hardware test stimuli generation,
Z. Zhang, B. Szekely, P. Gimenes, G. Chadwick, H. McNally, J. Cheng, R. Mullins, and Y . Zhao, “Llm4dv: Using large language models for hardware test stimuli generation,” in2025 IEEE 33rd Annual Interna- tional Symposium on Field-Programmable Custom Computing Machines (FCCM). IEEE, 2025, pp. 133–137
2025
-
[30]
Satisfiability modulo theories,
C. Barrett and C. Tinelli, “Satisfiability modulo theories,” inHandbook of model checking. Springer, 2018, pp. 305–343
2018
-
[31]
Cute: A concolic unit testing engine for c,
K. Sen, D. Marinov, and G. Agha, “Cute: A concolic unit testing engine for c,”ACM SIGSOFT software engineering notes, vol. 30, no. 5, pp. 263–272, 2005
2005
-
[32]
Arks: Active retrieval in knowledge soup for code generation,
H. Su, S. Jiang, Y . Lai, H. Wu, B. Shi, C. Liu, Q. Liu, and T. Yu, “Arks: Active retrieval in knowledge soup for code generation,”arXiv preprint arXiv:2402.12317, 2024
arXiv 2024
-
[33]
Context-augmented code generation using pro- gramming knowledge graphs,
I. Saberi and F. Fard, “Context-augmented code generation using pro- gramming knowledge graphs,”arXiv preprint arXiv:2410.18251, 2024
arXiv 2024
-
[34]
Knowledge graph-guided retrieval augmented generation,
X. Zhu, Y . Xie, Y . Liu, Y . Li, and W. Hu, “Knowledge graph-guided retrieval augmented generation,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Compu- tational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 8912–8924
2025
-
[35]
Y . Zhang, X. Zhao, Z. Z. Wang, C. Yang, J. Wei, and T. Wu, “cast: Enhancing code retrieval-augmented generation with structural chunking via abstract syntax tree,”arXiv preprint arXiv:2506.15655, 2025
arXiv 2025
-
[36]
An iteratively-refined dataset for high-level synthesis functional verification through llm-aided bug injection,
L. J. Wan, H. Ye, J. Wang, M. Jha, and D. Chen, “An iteratively-refined dataset for high-level synthesis functional verification through llm-aided bug injection,”2024 IEEE LLM Aided Design Workshop (LAD), pp. 1–6, 2024
2024
-
[37]
HLSFactory: A Framework Empowering High-Level Synthesis Datasets for Machine Learning and Beyond,
S. Abi-Karam, R. Sarkar, A. Seigler, S. Lowe, Z. Wei, H. Chen, N. Rao, L. John, A. Arora, and C. Hao, “HLSFactory: A Framework Empowering High-Level Synthesis Datasets for Machine Learning and Beyond,” in2024 ACM/IEEE 6th Symposium on Machine Learning for CAD (MLCAD). Salt Lake City (Snowbird), UT, USA: IEEE, Sep. 2024, pp. 1–9
2024
-
[38]
A. Wanna, H. Chen, and C. Hao, “Forgebench: A machine learning benchmark suite and auto-generation framework for next-generation hls tools,” 2025. [Online]. Available: https://arxiv.org/abs/2504.15185
arXiv 2025
-
[39]
Machsuite: Benchmarks for accelerator design and customized architectures,
B. Reagen, R. Adolf, Y . S. Shao, G.-Y . Wei, and D. Brooks, “Machsuite: Benchmarks for accelerator design and customized architectures,” in 2014 IEEE International Symposium on Workload Characterization (IISWC), 2014, pp. 110–119
2014
-
[40]
Parallel programming for fpgas,
R. Kastner, J. Matai, and S. Neuendorffer, “Parallel programming for fpgas,” 2018. [Online]. Available: https://arxiv.org/abs/1805.03648
Pith/arXiv arXiv 2018
-
[41]
Hlsdataset: Open-source dataset for ml-assisted fpga design using high level synthesis,
Z. Wei, A. Arora, R. Li, and L. John, “Hlsdataset: Open-source dataset for ml-assisted fpga design using high level synthesis,” in2023 IEEE 34th International Conference on Application-specific Systems, Archi- tectures and Processors (ASAP), 2023, pp. 197–204
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.