Speaking in Self-Assessing Tongues: On the Verbalized Confidence of LLMs in Machine Translation
Pith reviewed 2026-06-27 03:13 UTC · model grok-4.3
The pith
Verbalized confidence scores from LLMs match internal signals in detecting translation errors and calibration but show little correlation with them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that for both fine-grained error detection and calibration, internal and verbalized methods perform similarly, although results vary by model, and there is little to no correlation between internal and verbalized methods.
What carries the argument
Five verbalized methods for extracting per-token confidence from the LLM's output text without relying on internal probability signals.
If this is right
- Verbalized methods can serve as a substitute for internal signals when model internals are inaccessible.
- Both verbalized and internal methods support token-level alignment to translation errors.
- Reliability in error detection and calibration is comparable between the approaches.
- Performance differences appear across different LLMs.
Where Pith is reading between the lines
- Combining verbalized and internal scores could yield more independent information for confidence estimation since they track separate signals.
- The lack of correlation suggests verbalized methods may capture aspects of correctness that internal probabilities miss.
- The approach could be tested on other text generation tasks where token-level reliability matters.
Load-bearing premise
The five verbalized extraction methods produce confidence scores that can be meaningfully aligned to translation errors and to actual correctness at token level.
What would settle it
An experiment in which verbalized methods show markedly lower alignment to token-level translation errors or poorer calibration than internal signals, or in which the two methods exhibit strong positive correlation.
Figures

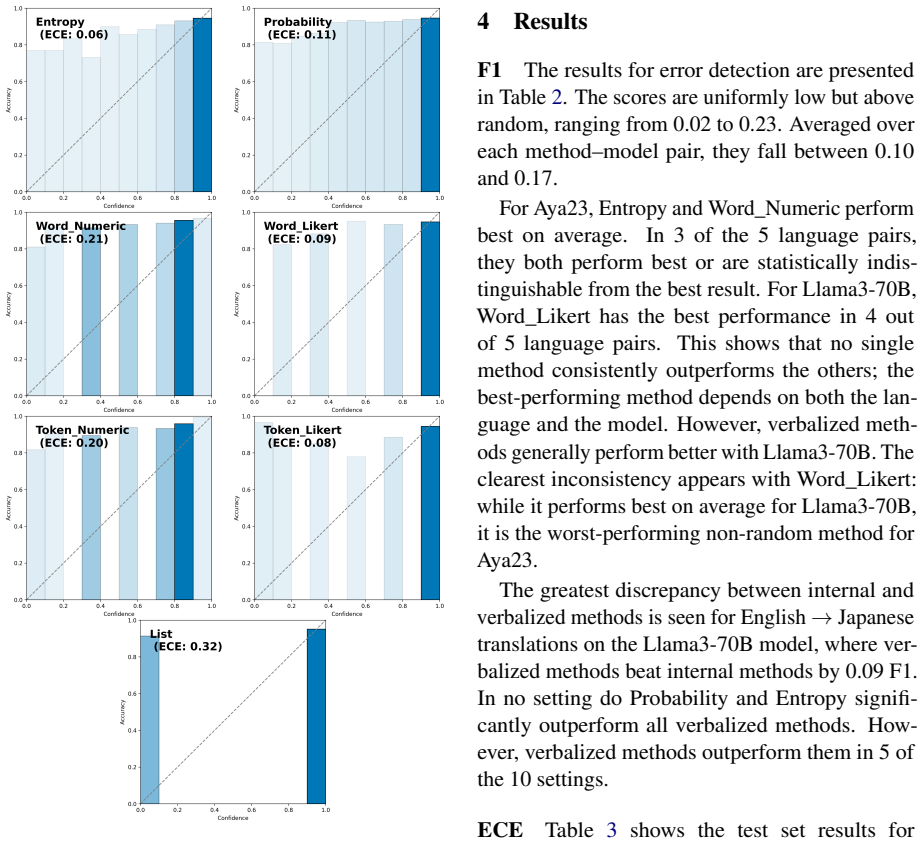




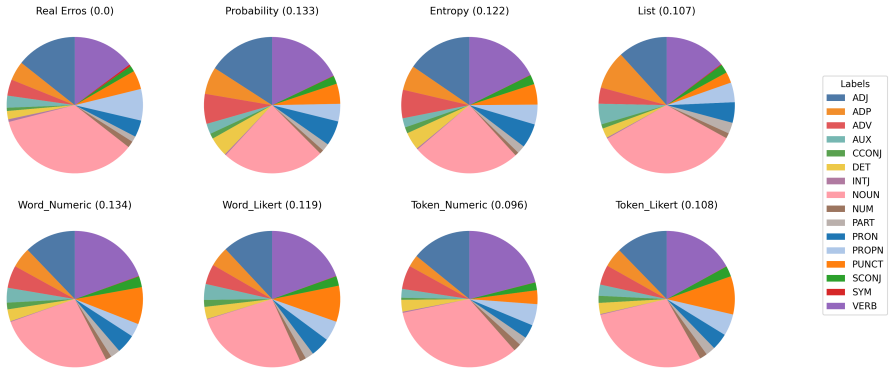






read the original abstract
The rapid rise in popularity of large language models (LLMs) for translation calls for a thorough study of the reliability of their confidence in their own outputs. Unlike many generation tasks, translation errors and confidence levels can be useful at different levels of granularity (tokens, words, or spans). Unsupervised approaches based on internal signals like predicted probabilities can be misleading because they reflect certainty among alternatives rather than correctness. In addition, they require access to such internal signals. Here, we devise five verbalized methods of extracting an LLM's per-token confidence without those shortcomings and compare their reliability with that of the model's internal signals of certainty. We evaluate reliability using two forms of alignment: fine-grained error detection and calibration. For both, internal and verbalized methods perform similarly, although results vary by model. Interestingly, we find little to no correlation between internal and verbalized methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that five verbalized methods for extracting per-token confidence from LLMs in machine translation perform similarly to internal probability signals on fine-grained error detection and calibration (with results varying by model), yet exhibit little to no correlation with internal methods. It positions verbalized approaches as accessible alternatives that avoid reliance on internal signals.
Significance. If the empirical comparisons hold after methodological clarification, the work provides evidence that verbalized confidence can substitute for internal signals in MT reliability assessment and that the two families capture distinct uncertainty information. This has practical value for black-box LLM use and could motivate hybrid confidence estimators.
major comments (2)
- [Evaluation section (paragraph on two forms of alignment)] Evaluation section (paragraph on two forms of alignment): The central claim that verbalized and internal methods perform similarly for error detection and calibration depends on the five verbalized extraction methods yielding numeric per-token scores that can be aligned to actual translation errors. The manuscript provides no details on parsing natural-language verbal responses into per-token confidences or on the alignment protocol to error annotations, raising the possibility that extraction noise explains both the similarity and the reported lack of correlation.
- [Results (abstract claim of 'little to no correlation')] Results (abstract claim of 'little to no correlation'): The lack of correlation between internal and verbalized methods is load-bearing for the interpretation that the methods are complementary. The manuscript must specify the correlation metric, whether it is computed at token or sentence level, and include per-model statistical tests to substantiate both the 'little to no correlation' finding and the statement that results vary by model.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: Evaluation section (paragraph on two forms of alignment): The central claim that verbalized and internal methods perform similarly for error detection and calibration depends on the five verbalized extraction methods yielding numeric per-token scores that can be aligned to actual translation errors. The manuscript provides no details on parsing natural-language verbal responses into per-token confidences or on the alignment protocol to error annotations, raising the possibility that extraction noise explains both the similarity and the reported lack of correlation.
Authors: We agree that the manuscript should have included explicit details on parsing and alignment. In the revision we will expand the Evaluation section with a dedicated subsection describing the five verbalized extraction methods, the exact parsing rules used to convert natural-language responses into numeric per-token scores, and the token-level alignment protocol to the error annotations. These additions will demonstrate that the numeric scores are obtained in a reproducible manner and will allow readers to assess whether extraction noise could affect the reported similarity or lack of correlation. revision: yes
-
Referee: Results (abstract claim of 'little to no correlation'): The lack of correlation between internal and verbalized methods is load-bearing for the interpretation that the methods are complementary. The manuscript must specify the correlation metric, whether it is computed at token or sentence level, and include per-model statistical tests to substantiate both the 'little to no correlation' finding and the statement that results vary by model.
Authors: We accept that the correlation analysis requires fuller specification. The correlation is Pearson's r computed at the token level across all tokens in the test set. In the revised Results section we will state the metric and granularity explicitly and will add per-model correlation coefficients together with statistical significance tests (including p-values and confidence intervals) to support both the 'little to no correlation' claim and the observation that outcomes vary by model. These changes will strengthen the evidence that the two families capture distinct information. revision: yes
Circularity Check
No circularity: direct empirical comparison without derivations or self-referential fits
full rationale
The paper is an empirical study comparing internal probability signals to five verbalized confidence extraction methods for LLM translation outputs. It evaluates both via alignment to error annotations and calibration metrics. No equations, parameter fitting presented as prediction, uniqueness theorems, or self-citation chains appear in the provided abstract or description. The central claims rest on direct measurement against external error data rather than any reduction to the paper's own inputs by construction. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Viraat Aryabumi, John Dang, Dwarak Talupuru, Saurabh Dash, David Cairuz, Hangyu Lin, Bharat Venkitesh, Madeline Smith, Jon Ander Campos, Yi Chern Tan, and 1 others. 2024. Aya 23: Open weight releases to further multilingual progress. arXiv preprint arXiv:2405.15032
arXiv 2024
-
[2]
Taylor Berg-Kirkpatrick, David Burkett, and Dan Klein. 2012. https://aclanthology.org/D12-1091/ An empirical investigation of statistical significance in NLP . In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 995--1005, Jeju Island, Korea. Association for Com...
2012
-
[3]
Tu Anh Dinh and Jan Niehues. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.166 Are generative models underconfident? better quality estimation with boosted model probability . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3364--3382, Suzhou, China. Association for Computational Linguistics
-
[4]
Marina Fomicheva, Shuo Sun, Erick Fonseca, Chrysoula Zerva, Fr \'e d \'e ric Blain, Vishrav Chaudhary, Francisco Guzm \'a n, Nina Lopatina, Lucia Specia, and Andr \'e F. T. Martins. 2022. https://aclanthology.org/2022.lrec-1.530/ MLQE - PE : A multilingual quality estimation and post-editing dataset . In Proceedings of the Thirteenth Language Resources an...
2022
-
[5]
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2023. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738
Pith/arXiv arXiv 2023
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[7]
Zhixiong Han, Yaru Hao, Li Dong, Yutao Sun, and Furu Wei. 2022. Prototypical calibration for few-shot learning of language models. arXiv preprint arXiv:2205.10183
arXiv 2022
-
[8]
Ari Holtzman, Peter West, Vered Shwartz, Yejin Choi, and Luke Zettlemoyer. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.564 Surface form competition: Why the highest probability answer isn ' t always right . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7038--7051, Online and Punta Cana, Dominican Re...
-
[9]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, and 1 others. 2022. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221
Pith/arXiv arXiv 2022
-
[10]
Tom Kocmi, Ekaterina Artemova, Eleftherios Avramidis, Rachel Bawden, Ond r ej Bojar, Konstantin Dranch, Anton Dvorkovich, Sergey Dukanov, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, Barry Haddow, Marzena Karpinska, Philipp Koehn, Howard Lakougna, Jessica Lundin, Christof Monz, Kenton Murray, and 10 others. 2025. https://doi.org/10.18653...
-
[11]
Tom Kocmi, Eleftherios Avramidis, Rachel Bawden, Ond r ej Bojar, Anton Dvorkovich, Christian Federmann, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, Barry Haddow, Marzena Karpinska, Philipp Koehn, Benjamin Marie, Christof Monz, Kenton Murray, Masaaki Nagata, Martin Popel, Maja Popovi \'c , and 3 others. 2024 a . https://doi.org/10.18653/...
-
[12]
Tom Kocmi, Vil \'e m Zouhar, Eleftherios Avramidis, Roman Grundkiewicz, Marzena Karpinska, Maja Popovi \'c , Mrinmaya Sachan, and Mariya Shmatova. 2024 b . https://doi.org/10.18653/v1/2024.wmt-1.131 Error span annotation: A balanced approach for human evaluation of machine translation . In Proceedings of the Ninth Conference on Machine Translation, pages ...
-
[13]
Abhishek Kumar, Robert Morabito, Sanzhar Umbet, Jad Kabbara, and Ali Emami. 2024. https://doi.org/10.18653/v1/2024.acl-long.20 Confidence under the hood: An investigation into the confidence-probability alignment in large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[14]
Aviral Kumar and Sunita Sarawagi. 2019. Calibration of encoder decoder models for neural machine translation. arXiv preprint arXiv:1903.00802
Pith/arXiv arXiv 2019
-
[15]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Teaching models to express their uncertainty in words. arXiv preprint arXiv:2205.14334
Pith/arXiv arXiv 2022
-
[16]
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei. 2025. Uncertainty quantification and confidence calibration in large language models: A survey. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, pages 6107--6117
2025
-
[17]
Charles Lovering, Michael Krumdick, Viet Dac Lai, Seth Ebner, Nilesh Kumar, Varshini Reddy, Rik Koncel-Kedziorski, and Chris Tanner. 2024. Language model probabilities are not calibrated in numeric contexts. arXiv preprint arXiv:2410.16007
arXiv 2024
-
[18]
Charles Lovering, Michael Krumdick, Viet Dac Lai, Varshini Reddy, Seth Ebner, Nilesh Kumar, Rik Koncel-Kedziorski, and Chris Tanner. 2025. https://doi.org/10.18653/v1/2025.acl-long.1417 Language model probabilities are not calibrated in numeric contexts . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1:...
-
[19]
Yu Lu, Jiali Zeng, Jiajun Zhang, Shuangzhi Wu, and Mu Li. 2022. https://doi.org/10.18653/v1/2022.acl-long.167 Learning confidence for transformer-based neural machine translation . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2353--2364, Dublin, Ireland. Association for Computati...
-
[20]
Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.557 S elf C heck GPT : Zero-resource black-box hallucination detection for generative large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004--9017, Singapore. Association for Computational...
-
[21]
Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau
Sabrina J. Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau. 2022. https://doi.org/10.1162/tacl_a_00494 Reducing conversational agents' overconfidence through linguistic calibration . Transactions of the Association for Computational Linguistics, 10:857--872
-
[22]
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. 2015. Obtaining well calibrated probabilities using bayesian binning. In Proceedings of the AAAI conference on artificial intelligence, volume 29
2015
-
[23]
Shiyu Ni, Keping Bi, Lulu Yu, and Jiafeng Guo. 2024. Are large language models more honest in their probabilistic or verbalized confidence? In China Conference on Information Retrieval, pages 124--135. Springer
2024
-
[24]
Alexandru Niculescu-Mizil and Rich Caruana. 2005. Predicting good probabilities with supervised learning. In Proceedings of the 22nd international conference on Machine learning, pages 625--632
2005
-
[25]
Myle Ott, Michael Auli, David Grangier, and Marc’Aurelio Ranzato. 2018. Analyzing uncertainty in neural machine translation. In International Conference on Machine Learning, pages 3956--3965. PMLR
2018
-
[26]
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, and Christopher D. Manning. 2020. https://doi.org/10.18653/v1/2020.acl-demos.14 S tanza: A python natural language processing toolkit for many human languages . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 101--108, Online. Associat...
-
[27]
Qi Qi, Youzhi Luo, Zhao Xu, Shuiwang Ji, and Tianbao Yang. 2021. Stochastic optimization of areas under precision-recall curves with provable convergence. Advances in neural information processing systems, 34:1752--1765
2021
-
[28]
Gabriele Sarti, Arianna Bisazza, Ana Guerberof-Arenas, and Antonio Toral. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.532 D iv EMT : Neural machine translation post-editing effort across typologically diverse languages . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 7795--7816, Abu Dhabi, United Ara...
-
[29]
Gabriele Sarti, Vil \'e m Zouhar, Grzegorz Chrupa a, Ana Guerberof-Arenas, Malvina Nissim, and Arianna Bisazza. 2025 a . Qe4pe: Word-level quality estimation for human post-editing. Transactions of the Association for Computational Linguistics, 13:1410--1435
2025
-
[30]
Gabriele Sarti, Vil \'e m Zouhar, Malvina Nissim, and Arianna Bisazza. 2025 b . https://doi.org/10.18653/v1/2025.emnlp-main.924 Unsupervised word-level quality estimation for machine translation through the lens of annotators (dis)agreement . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18320--18337, Suz...
-
[31]
Matthew Snover, Bonnie Dorr, Rich Schwartz, Linnea Micciulla, and John Makhoul. 2006. https://aclanthology.org/2006.amta-papers.25/ A study of translation edit rate with targeted human annotation . In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers, pages 223--231, Cambridge, Massachusetts, US...
2006
-
[32]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.330 Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback . In Proceedings of the 2023 Conference on Em...
-
[33]
Yao-Hung Hubert Tsai, Walter Talbott, and Jian Zhang. 2024. Efficient non-parametric uncertainty quantification for black-box large language models and decision planning. arXiv preprint arXiv:2402.00251
arXiv 2024
-
[34]
Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, and Seong Oh. 2024. https://doi.org/10.18653/v1/2024.acl-long.824 Calibrating large language models using their generations only . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15440--15459, Bangkok, Thailand. Association for Co...
-
[35]
Cheng Wang, Gyuri Szarvas, Georges Balazs, Pavel Danchenko, and Patrick Ernst. 2024. Calibrating verbalized probabilities for large language models. arXiv preprint arXiv:2410.06707
arXiv 2024
-
[36]
Shuo Wang, Zhaopeng Tu, Shuming Shi, and Yang Liu. 2020. https://doi.org/10.18653/v1/2020.acl-main.278 On the inference calibration of neural machine translation . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3070--3079, Online. Association for Computational Linguistics
-
[37]
Ziyu Wang and Chris Holmes. 2024. On subjective uncertainty quantification and calibration in natural language generation. arXiv preprint arXiv:2406.05213
arXiv 2024
-
[38]
Sarah Wiegreffe, Matthew Finlayson, Oyvind Tafjord, Peter Clark, and Ashish Sabharwal. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.522 Increasing probability mass on answer choices does not always improve accuracy . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8392--8417, Singapore. Association for...
-
[39]
Di Wu, Yibin Lei, and Christof Monz. 2025. Calibrating translation decoding with quality estimation on llms. arXiv preprint arXiv:2504.19044
arXiv 2025
-
[40]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2023. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. arXiv preprint arXiv:2306.13063
Pith/arXiv arXiv 2023
-
[41]
Daniel Yang, Yao-Hung Hubert Tsai, and Makoto Yamada. 2024. On verbalized confidence scores for llms. arXiv preprint arXiv:2412.14737
Pith/arXiv arXiv 2024
-
[42]
Zhen Yang, Fandong Meng, Yuanmeng Yan, and Jie Zhou. 2023. https://doi.org/10.18653/v1/2023.findings-acl.126 Rethinking the word-level quality estimation for machine translation from human judgement . In Findings of the Association for Computational Linguistics: ACL 2023, pages 2012--2025, Toronto, Canada. Association for Computational Linguistics
-
[43]
Mozhi Zhang, Mianqiu Huang, Rundong Shi, Linsen Guo, Chong Peng, Peng Yan, Yaqian Zhou, and Xipeng Qiu. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.173 Calibrating the confidence of large language models by eliciting fidelity . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2959--2979, Miami, Florida...
-
[44]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595--46623
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.