Dissecting model behavior through agent trajectories
Pith reviewed 2026-06-27 01:25 UTC · model grok-4.3
The pith
Representing agent trajectories in code state-spaces reveals model-level differences in problem-solving behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
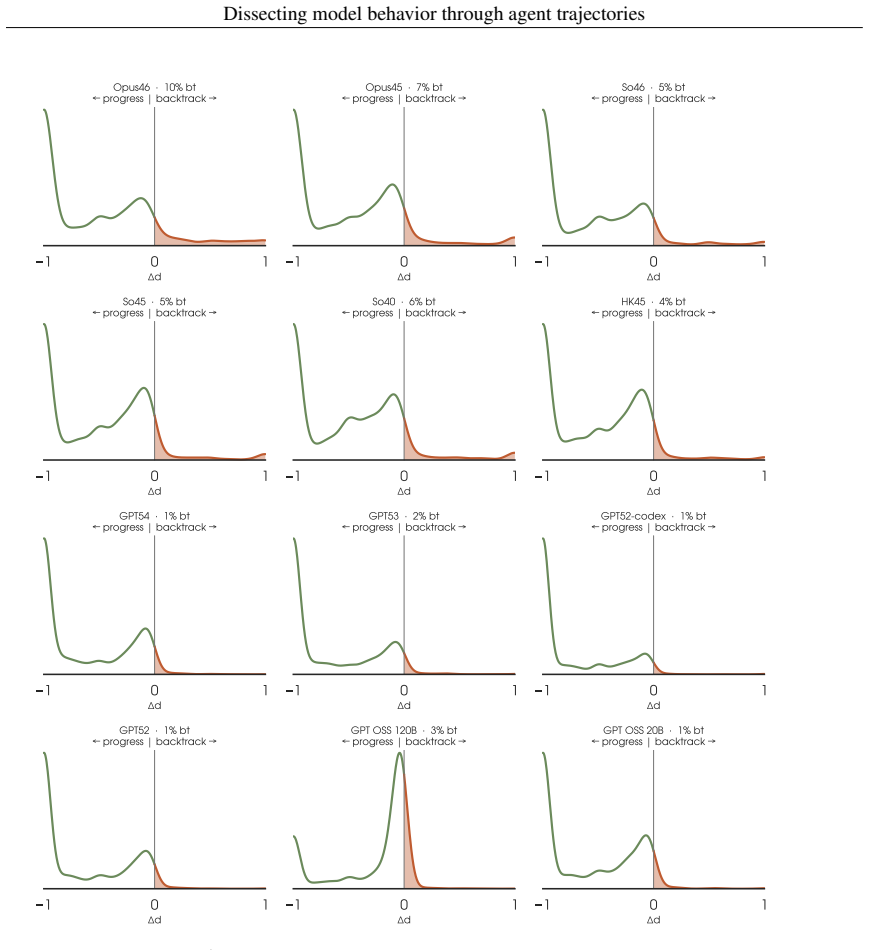
By representing agent trajectories in code state-spaces, models exhibit observable differences in problem-solving behavior through metrics such as edit frequency, testing activity, and phase-transitions, which indicate how individual models allocate effort across stages of autonomous problem solving even when pass@1 scores are comparable.
What carries the argument
Code state-space representation of agent trajectories, which encodes sequences of code states to quantify metrics like edit frequency and testing activity.
Load-bearing premise
The chosen code state-space representation and SSA harness do not systematically distort observed differences so that trajectories reflect model intent rather than harness artifacts.
What would settle it
Finding that different models produce statistically indistinguishable distributions of edit frequencies, testing activities, and phase-transitions when run in the same SSA harness on the same benchmarks.
Figures
















































read the original abstract
AI agent performance is not just a modeling problem, it is fundamentally a systems problem. The advanced capabilities of models are realized through agent harnesses. Therefore, a gap between model assumptions and harness behavior can easily prevent the model's full capabilities from translating into agent performance. We formalize this as the `intent-execution' gap: the mismatch between what the model intends and what the harness executes, and vice versa. We argue that minimizing this intent-execution gap is as important as other aspects of harness design such as tools and execution loops. To illustrate the impact of this harness-model alignment, we develop a simple and customizable harness called `Simple Strands Agent' (SSA). SSA aims to find the bulk of common patterns which generalize across different model families (such as Claude, Gemini, GPT, Grok, Qwen), as well as a small number of model-specific preferences. We make two contributions: (i) we reproduce or improve on the pass@1 performance reported by diverse model-provider families on popular agentic benchmarks (SWE-Pro, SWE-Verified and Terminal-Bench-2), and (ii) building on an analysis of 138k trajectories generated by SSA, we look beyond the pass@1 numbers which tend to be relatively even across frontier models. By representing agent trajectories in code state-spaces, we observe model-level differences in problem-solving behavior. Finer-grained metrics such as edit frequency, testing activity, and phase-transitions reveal how individual models allocate effort across different stages of autonomous problem solving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the 'intent-execution' gap between model intent and harness execution in AI agents. It introduces the Simple Strands Agent (SSA) harness, reports reproducing or improving pass@1 on SWE-Pro, SWE-Verified, and Terminal-Bench-2 across model families (Claude, Gemini, GPT, Grok, Qwen), and analyzes 138k trajectories represented in code state-spaces to identify model-level differences in finer-grained behaviors including edit frequency, testing activity, and phase transitions.
Significance. If the reported behavioral differences prove robust beyond the specific SSA harness, the work would offer a concrete methodology for moving past aggregate pass@1 metrics to understand how models allocate effort across problem-solving stages, directly supporting harness-model alignment research.
major comments (1)
- [Trajectory analysis and experimental setup] The central claim that model-level differences in edit frequency, testing activity, and phase-transitions are observable via code state-spaces rests on trajectories generated exclusively by the single SSA harness (fixed state representation, loop structure, and prompting). Given the paper's own observation of roughly comparable pass@1 across families, systematic harness-model coupling could produce the divergences without reflecting intrinsic strategies; no cross-harness ablation or variation control is described to isolate model effects.
minor comments (1)
- [Methods / Results] The abstract provides no detail on trajectory sampling procedure, precise definition of the code state-spaces, or application of multiple-testing correction to the reported metric differences.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Trajectory analysis and experimental setup] The central claim that model-level differences in edit frequency, testing activity, and phase-transitions are observable via code state-spaces rests on trajectories generated exclusively by the single SSA harness (fixed state representation, loop structure, and prompting). Given the paper's own observation of roughly comparable pass@1 across families, systematic harness-model coupling could produce the divergences without reflecting intrinsic strategies; no cross-harness ablation or variation control is described to isolate model effects.
Authors: We agree this is a valid concern. The 138k trajectories were generated exclusively with the SSA harness, and no cross-harness ablations or controlled variations in state representation, loop structure, or prompting were performed. SSA was designed as a minimal, general-purpose harness to reduce the intent-execution gap and enable consistent comparison across model families, with the similar pass@1 scores providing some evidence of harness parity. Nevertheless, the possibility of harness-model interactions cannot be ruled out from the current data alone. We will revise the manuscript to explicitly acknowledge this limitation in the experimental setup and trajectory analysis sections and to identify cross-harness validation as an important direction for future work. revision: yes
Circularity Check
No circularity: empirical trajectory analysis is self-contained
full rationale
The paper reports new experimental runs of 138k trajectories on public benchmarks using the SSA harness, followed by direct observation of metrics such as edit frequency and phase transitions. No equations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on fresh data collection and comparison across models rather than any reduction of outputs to inputs by construction, satisfying the default expectation of non-circularity for empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Amazon Nova family of foundation models
Amazon AGI. The Amazon Nova family of foundation models. https://aws.amazon.com/ nova/, 2024
2024
-
[2]
A general path-based representation for predicting program properties, 2018
Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. A general path-based representation for predicting program properties, 2018. URLhttps://arxiv.org/abs/1803.09544. 14 Dissecting model behavior through agent trajectories
Pith/arXiv arXiv 2018
-
[3]
The Claude 4 model family: System cards and capability notes
Anthropic. The Claude 4 model family: System cards and capability notes. https://www. anthropic.com/claude, 2025
2025
-
[4]
Strands Agents: A model-driven SDK for building AI agents.https://strandsagents
AWS. Strands Agents: A model-driven SDK for building AI agents.https://strandsagents. com, 2025. Open-source SDK
2025
-
[5]
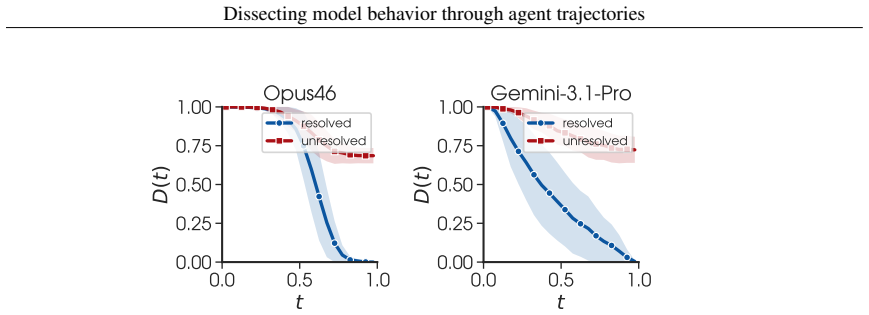
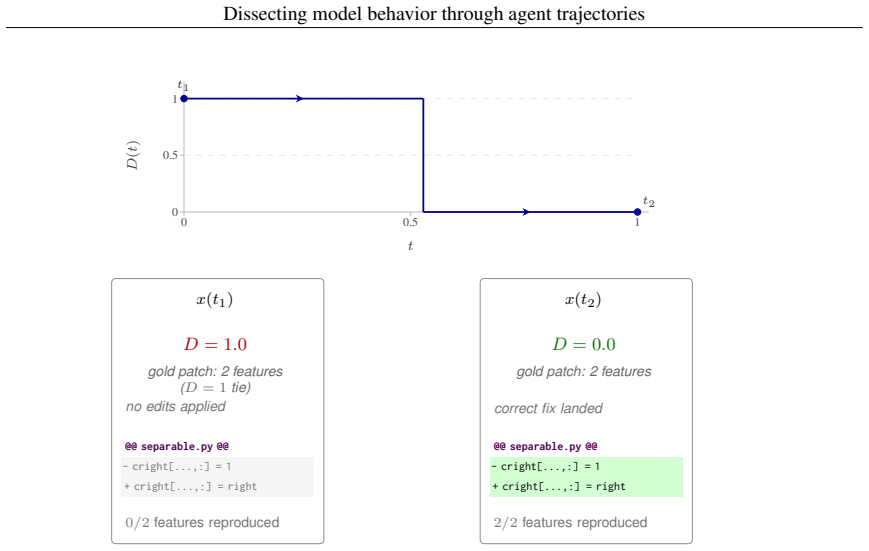
Barr, Yuriy Brun, Premkumar Devanbu, Mark Harman, and Federica Sarro
Earl T. Barr, Yuriy Brun, Premkumar Devanbu, Mark Harman, and Federica Sarro. The plastic surgery hypothesis. InProceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, FSE 2014, page 306–317, New York, NY , USA, 2014. Association for Computing Machinery. ISBN 9781450330565. doi: 10.1145/2635868.2635898. URLhttps...
-
[6]
LiteLLM: A unified gateway and proxy for LLM APIs
BerriAI. LiteLLM: A unified gateway and proxy for LLM APIs. https://github.com/ BerriAI/litellm, 2023. Open-source library
2023
-
[7]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al. Language models are few-shot learners, 2020. URL https://arxiv.org/abs/2005. 14165
2020
-
[8]
Evaluating large language models trained on code, 2021
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, et al. Evaluating large language models trained on code, 2021. URL https: //arxiv.org/abs/2107.03374
Pith/arXiv arXiv 2021
-
[9]
Gemini 3: Pro and Flash
Google DeepMind. Gemini 3: Pro and Flash. https://deepmind.google/technologies/ gemini/, 2025
2025
-
[10]
Deepseek-v3 technical report, 2025
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, et al. Deepseek-v3 technical report, 2025. URLhttps://arxiv.org/abs/2412.19437
Pith/arXiv arXiv 2025
-
[11]
SWE- Bench Pro: Can AI agents solve long-horizon software engineering tasks?, 2025
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, et al. SWE- Bench Pro: Can AI agents solve long-horizon software engineering tasks?, 2025. URL https: //arxiv.org/abs/2509.16941
Pith/arXiv arXiv 2025
-
[12]
Agentic RL: Token-in, token-out done right, 2026
Quentin Gallouédec and Kashif Rasul. Agentic RL: Token-in, token-out done right, 2026. Accessed 2026-06-07
2026
-
[13]
GraphCodeBERT: Pre-training code representations with data flow, 2021
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, et al. GraphCodeBERT: Pre-training code representations with data flow, 2021. URLhttps://arxiv.org/abs/2009. 08366
2021
-
[14]
Deepseek- r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638,
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, et al. Deepseek- r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638,
-
[15]
Deng, J., Li, T.-W., Zhang, S., Liu, S., Pan, Y ., Huang, H., Wang, X., Hu, P., Zhang, X., et al
ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. URL http://dx.doi.org/10. 1038/s41586-025-09422-z
-
[16]
Qwen2.5-coder technical report, 2024
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, et al. Qwen2.5-coder technical report, 2024. URLhttps://arxiv.org/abs/2409.12186
Pith/arXiv arXiv 2024
-
[17]
LiveCodeBench: Holistic and contami- nation free evaluation of large language models for code, 2024
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contami- nation free evaluation of large language models for code, 2024. URL https://arxiv.org/ abs/2403.07974
Pith/arXiv arXiv 2024
-
[18]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024. URLhttps://arxiv.org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[19]
CODESTRUCT: Code agents over structured action spaces, 2026
Myeongsoo Kim, Joe Hsu, Dingmin Wang, Shweta Garg, Varun Kumar, and Murali Krishna Ramanathan. CODESTRUCT: Code agents over structured action spaces, 2026. URL https: //arxiv.org/abs/2604.05407
Pith/arXiv arXiv 2026
-
[20]
Large language models are zero-shot reasoners, 2023
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners, 2023. URL https://arxiv.org/abs/2205.11916. 15 Dissecting model behavior through agent trajectories
Pith/arXiv arXiv 2023
-
[21]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention, 2023. URL https://arxiv.org/abs/2309. 06180
2023
-
[22]
A systematic study of automated program repair: fixing 55 out of 105 bugs for $8 each
Claire Le Goues, Michael Dewey-V ogt, Stephanie Forrest, and Westley Weimer. A systematic study of automated program repair: fixing 55 out of 105 bugs for $8 each. InProceedings of the 34th International Conference on Software Engineering, ICSE ’12, page 3–13. IEEE Press,
-
[23]
Claire Le Goues, Michael Pradel, and Abhik Roychoudhury. Automated program repair. Commun. ACM, 62(12):56–65, November 2019. ISSN 0001-0782. doi: 10.1145/3318162. URL https://doi.org/10.1145/3318162
-
[24]
Repobench: Benchmarking repository-level code auto-completion systems, 2023
Tianyang Liu, Canwen Xu, and Julian McAuley. Repobench: Benchmarking repository-level code auto-completion systems, 2023. URLhttps://arxiv.org/abs/2306.03091
Pith/arXiv arXiv 2023
-
[25]
Agentbench: Evaluating llms as agents, 2025
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, et al. Agentbench: Evaluating llms as agents, 2025. URLhttps://arxiv.org/abs/2308.03688
Pith/arXiv arXiv 2025
-
[26]
An analysis of the search spaces for generate and validate patch generation systems, 2016
Fan Long and Martin Rinard. An analysis of the search spaces for generate and validate patch generation systems, 2016. URLhttps://arxiv.org/abs/1602.05643
Pith/arXiv arXiv 2016
-
[27]
GPT-4.1 prompting guide
Noah MacCallum and Julian Lee. GPT-4.1 prompting guide. https://cookbook.openai. com/examples/gpt4-1_prompting_guide/, 2025. OpenAI Cookbook
2025
-
[28]
Data contamination: From memorization to exploitation, 2022
Inbal Magar and Roy Schwartz. Data contamination: From memorization to exploitation, 2022. URLhttps://arxiv.org/abs/2203.08242
arXiv 2022
-
[29]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces, 2026. URLhttps://arxiv.org/abs/2601.11868
Pith/arXiv arXiv 2026
-
[30]
MiniMax-M2: A foundation model with extended context and tool use
MiniMax AI. MiniMax-M2: A foundation model with extended context and tool use. https: //huggingface.co/MiniMaxAI, 2025
2025
-
[31]
Alberto Moraglio, Krzysztof Krawiec, and Colin G. Johnson. Geometric semantic genetic programming. InParallel Problem Solving from Nature - PPSN XII, pages 21–31, Berlin, Heidelberg, 2012. Springer Berlin Heidelberg. ISBN 978-3-642-32937-1
2012
-
[32]
The GPT-5 model family and the gpt-oss open-weights release
OpenAI. The GPT-5 model family and the gpt-oss open-weights release. https://openai. com/, 2025
2025
-
[33]
openai-harmony: Response format for the gpt-oss models
OpenAI. openai-harmony: Response format for the gpt-oss models. https://github.com/ openai/harmony, 2025. Accessed 2026-06-07
2025
-
[34]
ToolLLM: Facilitating large language models to master 16000+ real-world apis, 2023
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, et al. ToolLLM: Facilitating large language models to master 16000+ real-world apis, 2023. URLhttps://arxiv.org/abs/2307.16789
Pith/arXiv arXiv 2023
-
[35]
Swe-polybench: A multi-language benchmark for repository level evaluation of coding agents, 2025
Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buchholz, Tim Esler, Simon Valentin, Luca Franceschi, et al. Swe-polybench: A multi-language benchmark for repository level evaluation of coding agents, 2025. URL https://arxiv.org/abs/2504. 08703
2025
-
[36]
Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark, 2023
Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark, 2023. URLhttps://arxiv.org/abs/2310.18018
arXiv 2023
-
[37]
Toolformer: Language models can teach themselves to use tools, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023. URLhttps://arxiv.org/abs/2302.04761
Pith/arXiv arXiv 2023
-
[38]
Building effective agents
Erik Schluntz and Barry Zhang. Building effective agents. https://www.anthropic.com/ research/building-effective-agents, 2024. Anthropic engineering blog. 16 Dissecting model behavior through agent trajectories
2024
-
[39]
Reflexion: Language agents with verbal reinforcement learning, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366
Pith/arXiv arXiv 2023
-
[40]
Gradient-based program repair: Fixing bugs in continuous program spaces, 2026
André Silva, Gustav Thorén, and Martin Monperrus. Gradient-based program repair: Fixing bugs in continuous program spaces, 2026. URLhttps://arxiv.org/abs/2505.17703
arXiv 2026
-
[41]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), 2024. URLhttps://arxiv.org/abs/2308.11432
Pith/arXiv arXiv 2024
-
[42]
Executable code actions elicit better LLM agents.arXiv preprint arXiv:2402.01030, 2024
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM agents.arXiv preprint arXiv:2402.01030, 2024. URL https://arxiv.org/abs/2402.01030
arXiv 2024
-
[43]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, et al
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, et al. Openhands: An open platform for ai software developers as generalist agents, 2025. URLhttps://arxiv.org/abs/2407.16741
Pith/arXiv arXiv 2025
-
[44]
Emergent abilities of large language models, 2022
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, et al. Emergent abilities of large language models, 2022. URL https://arxiv.org/abs/2206.07682
Pith/arXiv arXiv 2022
-
[45]
Chain-of-thought prompting elicits reasoning in large language models, 2023
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URLhttps://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2023
-
[46]
AutoGen: Enabling next-gen llm applications via multi-agent conversation, 2023
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, et al. AutoGen: Enabling next-gen llm applications via multi-agent conversation, 2023. URL https://arxiv. org/abs/2308.08155
Pith/arXiv arXiv 2023
-
[47]
Grok 4.20 reasoning model.https://x.ai/, 2025
xAI. Grok 4.20 reasoning model.https://x.ai/, 2025
2025
-
[48]
The rise and potential of large language model based agents: A survey, 2023
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, et al. The rise and potential of large language model based agents: A survey, 2023. URL https://arxiv.org/ abs/2309.07864
Pith/arXiv arXiv 2023
-
[49]
Agentless: Demystifying llm-based software engineering agents, 2024
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying llm-based software engineering agents, 2024. URLhttps://arxiv.org/abs/2407.01489
Pith/arXiv arXiv 2024
-
[50]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024. URLhttps://arxiv.org/abs/2404.07972
Pith/arXiv arXiv 2024
-
[51]
Hydra – a framework for elegantly configuring complex applications
Omry Yadan. Hydra – a framework for elegantly configuring complex applications. https: //github.com/facebookresearch/hydra, 2019. GitHub repository
2019
-
[52]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, et al. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[53]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering, 2024. URLhttps://arxiv.org/abs/2405.15793
Pith/arXiv arXiv 2024
-
[54]
John Yang, Carlos E. Jimenez, Alex L. Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R. Narasimhan, Diyi Yang, Sida I. Wang, and Ofir Press. Swe-bench multimodal: Do ai systems generalize to visual software domains?, 2024. URLhttps://arxiv.org/abs/2410.03859
arXiv 2024
-
[55]
React: Synergizing reasoning and acting in language models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https: //arxiv.org/abs/2210.03629. 17 Dissecting model behavior through agent trajectories
Pith/arXiv arXiv 2023
-
[56]
Autocoderover: Au- tonomous program improvement, 2024
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. Autocoderover: Au- tonomous program improvement, 2024. URLhttps://arxiv.org/abs/2404.05427
arXiv 2024
-
[57]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023. URL https://arxiv.org/ abs/2306.05685
Pith/arXiv arXiv 2023
-
[58]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024. URLhttps://arxiv.org/abs/2307. 13854. 18 Dissecting model behavior through agent trajectories Appendix Contents The appendi...
2024
-
[59]
no match
Forced tool-use output.The judge cannot reply with free-form text. Its only allowed output is a single call to thesubmit_classifications tool whose schema only accepts anenum. Outputs are validated client-side before acceptance. A.1.2 Classification rubric Table 4 lists every field the judge assigns to a call. R1–R5 carry the bulk of the behavioural signa...
-
[60]
fraction-of-fix-achieved
Textual overlap, not semantics.The recall fraction in Eq. 6 counts matching changed lines. A correct-but-textually-different fix, i.e., a different identifier choice, a refactored expression, a guard placed elsewhere scores <1 against reference modes it does not textually match. The empirical subsets and the self-anchor for resolved endpoints mitigate thi...
-
[61]
Empirical subset ̸= solution space.The space is defined by the test oracle and ˜Si approximates it with the patches we happened to observe (using 21 models run 5 times). A unique correct solution found by nobody else, a real possibility on novel instances, can be far from the observed empirical modes, which is why the self-anchor is reserved for resolved ...
-
[62]
˜Si is dense on easy instances (for example, in SWE-Bench-Verified80+ reference modes) and sparse on hard ones
Reference-set sparsity scales with difficulty. ˜Si is dense on easy instances (for example, in SWE-Bench-Verified80+ reference modes) and sparse on hard ones. Instances that no model in our sweep solved have only the gold patch as a reference (or no reference if gold is also missing). Don these instances reads against a thin reference set and should be in...
-
[63]
Replay fidelity. d(t) is reconstructed from the edit-tool calls we parse (Table 5). Therefore, exotic shell rewrites (e.g. Python scripts that open a source file in write mode) are not fully parsed. Self-anchor fixes the resolved endpoint, but it cannot recover the exact intermediate state of an unparsed edit, so a small number of trajectories’ mid-run sh...
arXiv 2025
-
[68]
User: <uploaded_files> {{project_path}} </uploaded_files> I’ve uploaded a python code repository in the directory {{project_path}} (not in /tmp/inputs)
Think about edgecases and make sure your fix handles them as well Your thinking should be thorough and so it’s fine if it’s very long. User: <uploaded_files> {{project_path}} </uploaded_files> I’ve uploaded a python code repository in the directory {{project_path}} (not in /tmp/inputs). Consider the following PR description: <pr_description> {{git_issue}}...
-
[73]
User: <uploaded_files> {{project_path}} </uploaded_files> I’ve uploaded a code repository in the directory {{project_path}} (not in /tmp/inputs)
Think about edgecases and make sure your fix handles them as well Your thinking should be thorough and so it’s fine if it’s very long. User: <uploaded_files> {{project_path}} </uploaded_files> I’ve uploaded a code repository in the directory {{project_path}} (not in /tmp/inputs). Consider the following PR description: <pr_description> {{git_issue}} </pr_d...
-
[75]
Create a script to reproduce the error and execute it using the BashTool, to confirm the error
-
[78]
If any test fails, diagnose the failure and fix your implementation
Run the existing test suite for the affected module. If any test fails, diagnose the failure and fix your implementation
-
[79]
IMPORTANT rules: - You MUST run the tests frequently, and verify correctness of changes by running relevant tests
Think about edgecases and make sure your fix handles them as well. IMPORTANT rules: - You MUST run the tests frequently, and verify correctness of changes by running relevant tests. If tests fail, analyze failures and revise your patch. - Failing to test sufficiently rigorously is the NUMBER ONE failure mode. - There are hidden tests beyond what is visibl...
-
[87]
- If any test fails, diagnose the failure, revise your fix, and rerun until they all pass
Find and run the repository’s own existing tests for the files and functions you modified (e.g., ‘pytest path/to/test_file.py‘, the project’s tests, etc.). - If any test fails, diagnose the failure, revise your fix, and rerun until they all pass. - Do not finish until the relevant repo tests pass. Your thinking should be thorough and so it’s fine if it’s ...
-
[88]
Before exploring anything, use the ‘think‘ tool to write up: - the task restated in your own words - 3-5 hypotheses for the root cause, ranked by likelihood
-
[89]
Explore the repo to familiarize yourself with its structure
-
[91]
Use the ‘think‘ tool to list 2-3 candidate fixes in 1-2 lines each, then pick the simplest one
-
[93]
Rerun your reproduce script and confirm that the error is fixed
-
[94]
Use the ‘think‘ tool to enumerate 3-5 edge cases for the changed code, then exercise each via the reproduction script or shell
-
[95]
- If any test fails, diagnose the failure, revise your fix, and rerun until they all pass
Find and run the repository’s own existing tests for the files and functions you modified (e.g., ‘pytest path/to/test_file.py‘, the project’s tests, etc.). - If any test fails, diagnose the failure, revise your fix, and rerun until they all pass. - Do not finish until the relevant repo tests pass. Your thinking should be thorough and so it’s fine if it’s ...
-
[100]
ideally more than 100 times
Think about edgecases and make sure your fix handles them as well Your thinking should be thorough and so it’s fine if it’s very long. In this environment, you can run ‘<apply_patch_command>‘ to execute a diff/patch against a file, where <apply_patch_command> is a specially formatted apply patch command representing the diff you wish to execute. A valid <...
-
[102]
Create a script to reproduce the error and execute it with ‘python <filename.py>‘ using the BashTool, to confirm the error
-
[103]
Edit the sourcecode of the repo to resolve the issue
-
[104]
Rerun your reproduce script and confirm that the error is fixed!
-
[105]
User: <uploaded_files> {{project_path}} </uploaded_files> I’ve uploaded a python code repository in the directory {{project_path}} (not in /tmp/inputs)
Think about edgecases and make sure your fix handles them as well Your thinking should be thorough and so it’s fine if it’s very long. User: <uploaded_files> {{project_path}} </uploaded_files> I’ve uploaded a python code repository in the directory {{project_path}} (not in /tmp/inputs). Consider the following PR description: <pr_description> {{git_issue}}...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.