DeepInsight: A Unified Evaluation Infrastructure Across the Physical AI Stack
Pith reviewed 2026-06-27 01:26 UTC · model grok-4.3
The pith
DeepInsight provides a single runtime for evaluating the entire Physical AI stack using three shared abstractions that enable tracing regressions across layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeepInsight serves this full spectrum on a single runtime with three narrow abstractions -- task, resource, and result -- each realized as one invariant shared by every subsystem, enabling cross-layer diagnostics no federation of per-segment harnesses can reproduce. Deployed in production across all three layers of an embodied humanoid stack, this single set of invariants onboards new benchmarks largely by configuration. Where mature peer orchestrators exist it reproduces published references and peer-framework readings within their own spread, runs the same suites faster on a single node, and scales near-linearly across nodes. Its distinctive return is diagnostic: because every layer writes
What carries the argument
Three narrow abstractions—task, resource, and result—each realized as one invariant: one episode driver, one resource-handle protocol implemented by every expensive backend, and one trace identity scheme under which every event is written.
Load-bearing premise
The wide differences in how operators work, including their modalities, rewards, and resource needs, can still be handled by the three abstractions while keeping both their individual accuracy and the common identity for finding cross-layer issues.
What would settle it
A test case where a regression starting in the model layer cannot be traced back through the shared trace when it appears in the control layer, or where onboarding a new benchmark requires changes beyond configuration that break the invariants.
Figures









read the original abstract
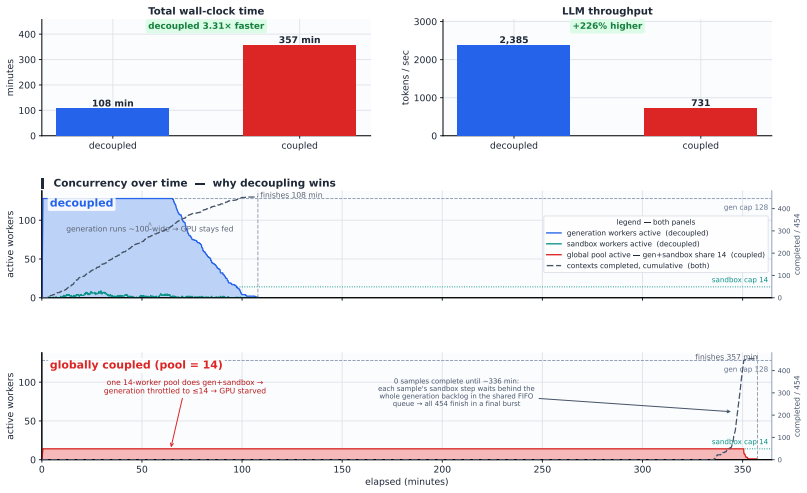
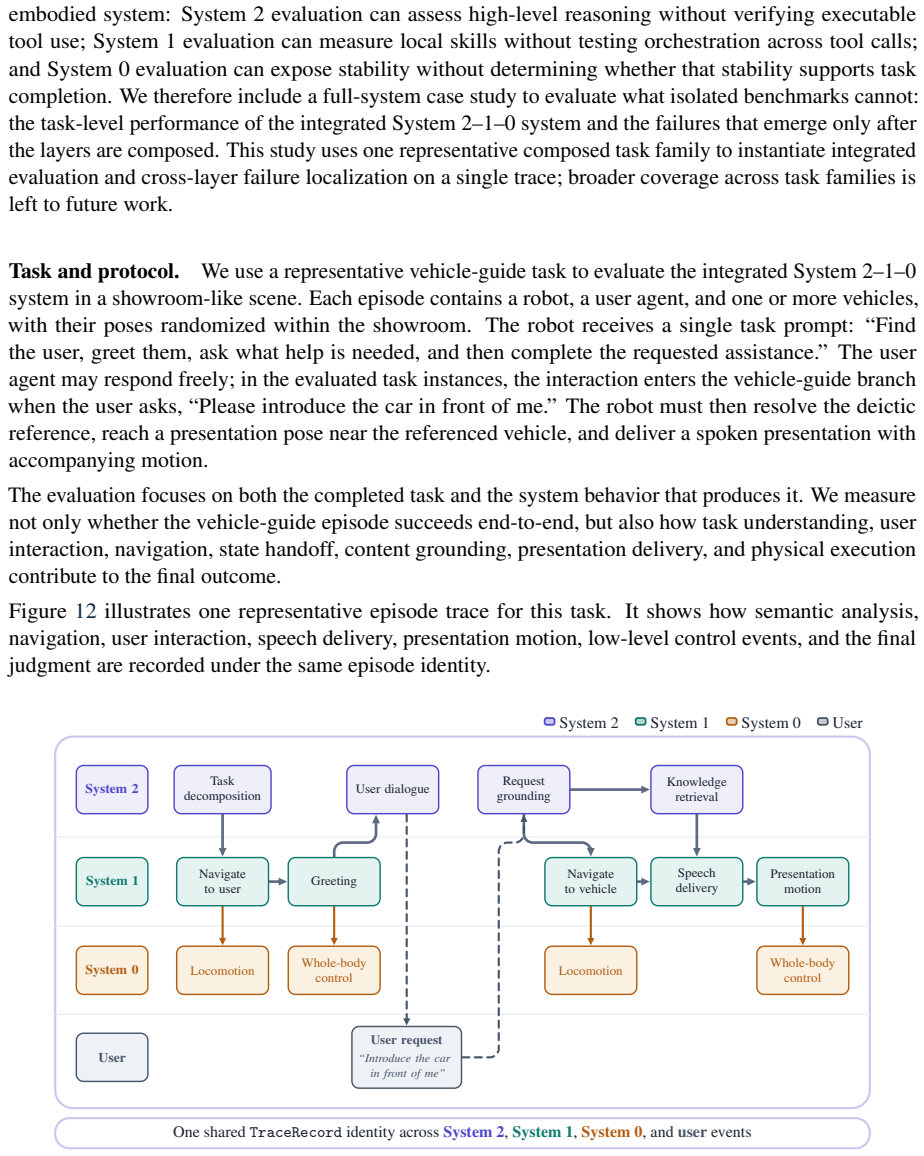
Evaluating a Physical AI stack spans operators that differ by more than three orders of magnitude -- from a single foundation-model decoding step to thousands of physics ticks of whole-body control -- varying orthogonally in modality, reward semantics, and resource profile. No existing framework spans this range, so the stack is evaluated today by stitching together separate harnesses that share neither runtime nor scoring, preserving each segment's local validity but losing the shared identity needed to diagnose cross-layer regressions. We present DeepInsight, an evaluation infrastructure that serves this full spectrum on a single runtime. Rather than homogenize the regimes, it preserves their heterogeneity behind three narrow abstractions -- task, resource, and result -- each realized as one invariant shared by every subsystem: one episode driver, one resource-handle protocol implemented by every expensive backend (LLM inference and sandboxed runtimes alike), and one trace identity scheme under which every event is written. Deployed in production across all three layers of an embodied humanoid stack, this single set of invariants onboards new benchmarks largely by configuration. Where mature peer orchestrators exist -- at the foundation-model end -- it reproduces published references and peer-framework readings within their own spread, runs the same suites faster on a single node, and scales near-linearly across nodes. Its distinctive return is diagnostic: because every layer writes into one shared trace, a regression that begins in one layer and surfaces in another stays localizable on that trace -- a cross-layer payoff no federation of per-segment harnesses can reproduce.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DeepInsight as a unified evaluation infrastructure for the Physical AI stack spanning operators that differ by more than three orders of magnitude in modality, reward semantics, and resource profile. It claims that three narrow abstractions—task, resource, and result—realized as invariants (one episode driver, one resource-handle protocol for all backends, and one trace identity scheme) allow a single runtime to preserve local heterogeneity without homogenization, enabling cross-layer regression diagnostics via shared traces that federated per-segment harnesses cannot provide. The system is reported to reproduce published references at the foundation-model layer, run suites faster on a single node, scale near-linearly, onboard new benchmarks largely by configuration, and deliver distinctive diagnostic value when deployed across all three layers of an embodied humanoid stack.
Significance. If the central claim holds, the work could have substantial impact on evaluation of integrated Physical AI systems by providing a common runtime and shared trace identity for cross-layer localization of regressions. The production deployment, reproduction of peer-framework readings within their own spread, and single-node speedups are concrete strengths that would be valuable to the community if the abstractions are shown to maintain local validity.
major comments (1)
- [Abstract] Abstract: The load-bearing claim that the three invariants preserve local validity (e.g., token-level log-probability rewards for LLM decoding and torque-integral or stability rewards for physics ticks) without per-layer escape hatches that would break the shared trace identity is asserted but not supported by any concrete mapping or example; without such a demonstration the cross-layer diagnostic payoff cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the careful review and for recognizing the potential impact of a unified runtime for cross-layer diagnostics in Physical AI. We address the single major comment below.
read point-by-point responses
-
Referee: The load-bearing claim that the three invariants preserve local validity (e.g., token-level log-probability rewards for LLM decoding and torque-integral or stability rewards for physics ticks) without per-layer escape hatches that would break the shared trace identity is asserted but not supported by any concrete mapping or example; without such a demonstration the cross-layer diagnostic payoff cannot be assessed.
Authors: We agree that the abstract asserts the preservation of local validity via the three invariants without supplying a concrete mapping. While the body of the manuscript (Sections 3.2–3.3 and 4) specifies the episode driver, resource-handle protocol, and trace identity scheme and shows how each backend implements them without escape hatches, the abstract itself lacks an illustrative example. In the revised version we will add a concise mapping to the abstract: the resource-handle protocol lets an LLM backend surface per-token log-probabilities as result records while a physics simulator surfaces per-tick torque integrals, both written under the identical trace identity; the episode driver remains unchanged across layers. This addition directly supports the cross-layer diagnostic claim without altering any technical content. revision: yes
Circularity Check
No circularity: system design with no derivations or fitted quantities
full rationale
The paper describes a software infrastructure using three abstractions (task, resource, result) realized as invariants. No equations, parameter fits, predictions, or derivation chains appear in the provided text. Claims about cross-layer diagnostics and reproduction of references are presented as engineering outcomes of the design rather than quantities derived from or equivalent to the inputs by construction. No self-citations or uniqueness theorems are invoked as load-bearing steps. The central claim reduces to the assertion that the invariants preserve heterogeneity, which is a design statement, not a self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Three narrow abstractions (task, resource, result) realized as invariants are sufficient to preserve heterogeneity across all layers while enabling shared trace identity for diagnostics.
invented entities (1)
-
Shared trace identity scheme
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introducing helix 02: Full-body autonomy.https://www.figure.ai/news/helix-02, 2026
Figure AI. Introducing helix 02: Full-body autonomy.https://www.figure.ai/news/helix-02, 2026
2026
-
[2]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021
2021
-
[3]
Training verifiers to solve math word problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. InarXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[4]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[5]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, 2024
2024
-
[6]
GAIA: A benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general ai assistants. InInternational Conference on Learning Representations, 2024
2024
-
[7]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information P...
2024
-
[8]
τ-bench: A benchmark for tool-agent-user interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains. InarXiv preprint arXiv:2406.12045, 2024
Pith/arXiv arXiv 2024
-
[9]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realis- tic web environment for building autonomous agents. InInternational Conference on Learning Representations, 2024
2024
-
[10]
CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 2022
2022
-
[11]
LIBERO: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[12]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on Robot Learning, 2020
2020
-
[13]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. RLBench: The robot learning benchmark and learning environment.IEEE Robotics and Automation Letters, 2020
2020
-
[14]
Open x-embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864, 2024
Open X-Embodiment Collaboration. Open x-embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864, 2024
Pith/arXiv arXiv 2024
-
[15]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishika Singh, Huy Ha, Quan Vuong, Ted Xiao, Sergey Levine, Chelsea Finn, and Jianlan Luo. SimplerEnv: Simulated manipulation policy evaluation environments for real robot setups.arXiv preprint arXiv:2405.05941, 2024
Pith/arXiv arXiv 2024
-
[16]
Carmelo Sferrazza, Dun-Ming Huang, Xingyu Lin, Yuke Zhu, and Pieter Abbeel. HumanoidBench: Simulated humanoid benchmark for whole-body locomotion and manipulation.arXiv preprint arXiv:2403.10506, 2024
arXiv 2024
-
[17]
RoboHive: A unified framework for robot learning
Vikash Kumar, Rutav Shah, Gaoyue Zhou, Vincent Moens, Vittorio Caggiano, Abhishek Gupta, and Aravind Rajeswaran. RoboHive: A unified framework for robot learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[18]
Orbit: A unified simulation framework for interactive robot learning environments.IEEE Robotics and Automation Letters, 2023
Mayank Mittal, Caleb Yu, Quan Ho Vuong, Arthur Allshire, Viktor Makoviychuk, Jérôme Hillaire, Nima Rudin, David Hoeller, Ankur Handa, Gavriel State, Marco Hutter, and Animesh Garg. Orbit: A unified simulation framework for interactive robot learning environments.IEEE Robotics and Automation Letters, 2023. 25
2023
-
[19]
Michaelov, Hanwool Albert Lee, Janna, Leonid Sinev, Khalid, Kiersten Stokes, Zden ˇek Kasner, and KonradSzafer
Lintang Sutawika, Hailey Schoelkopf, Leo Gao, Baber Abbasi, Stella Biderman, Jonathan Tow, ben fattori, Charles Lovering, farzanehnakhaee70, Jason Phang, Anish Thite, Fazz, Thomas Wang, Niklas, Aflah, sdtblck, nopperl, gakada, tttyuntian, researcher2, Julen Etxaniz, Chris, James A. Michaelov, Hanwool Albert Lee, Janna, Leonid Sinev, Khalid, Kiersten Stoke...
2026
-
[20]
OpenCompass: A universal evaluation platform for foundation models
OpenCompass Contributors. OpenCompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass, 2023
2023
-
[21]
Manning, Christopher Ré, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
Pith/arXiv arXiv 2022
-
[22]
Haodong Duan, Xinyu Fang, Junming Yang, Xiangyu Zhao, Yuxuan Qiao, Mo Li, Amit Agarwal, Zhe Chen, Lin Chen, Yuan Liu, Yubo Ma, Hailong Sun, Yifan Zhang, Shiyin Lu, Tack Hwa Wong, Weiyun Wang, Peiheng Zhou, Xiaozhe Li, Chaoyou Fu, Junbo Cui, Jixuan Chen, Enxin Song, Song Mao, Shengyuan Ding, Tianhao Liang, Zicheng Zhang, Xiaoyi Dong, Yuhang Zang, Pan Zhang...
arXiv 2024
-
[23]
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. LMMs-Eval: Reality check on the evaluation of large multimodal models.arXiv preprint arXiv:2407.12772, 2024
Pith/arXiv arXiv 2024
-
[24]
Inspect AI: Framework for large language model evaluations, 2024
UK AI Security Institute. Inspect AI: Framework for large language model evaluations, 2024. URL https://doi.org/10.5281/zenodo.18434279
-
[25]
DeepSeek-V4: Technical report
DeepSeek-AI. DeepSeek-V4: Technical report. https://www.alphaxiv.org/abs/ deepseek-v4, 2025
2025
-
[26]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368, 2024
Pith/arXiv arXiv 2024
-
[27]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems, 2024
2024
-
[28]
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, Claire Barale, Robert McHardy, Joshua Harris, Jean Kaddour, Emile van Krieken, and Pasquale Minervini. Are we done with MMLU? InProceedings of the 2025 Conference of the Nations of ...
2025
-
[29]
Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, Kang Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, Chujie Zheng, Kaixin Deng, Shian Jia, Sichao Jiang, Yiyan Liao, Rui Li, Qinrui Li, Sirun Li, Yizhi Li, Yunwen Li, Dehua Ma, Yuansheng Ni, Haoran Que, Qiyao 26 Wang, Zhoufutu Wen, Siwei Wu, Tianshun Xing, Ming Xu, Zhenzhu Yang, Zekun...
Pith/arXiv arXiv 2025
-
[30]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof Q&A benchmark. InInternational Conference on Machine Learning, 2024
2024
-
[31]
C-Eval: A multi-level multi-discipline chinese evaluation suite for foundation models
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. C-Eval: A multi-level multi-discipline chinese evaluation suite for foundation models. InAdvances in Neural Information Processing Systems, 2023
2023
-
[32]
Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
Pith/arXiv arXiv 2025
-
[33]
MathArena: Evaluating LLMs on uncontaminated math competitions.Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2025
Mislav Balunovic, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovic, and Martin Vechev. MathArena: Evaluating LLMs on uncontaminated math competitions.Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2025
2025
-
[34]
LiveCodeBench: Holistic and contamination free eval- uation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamination free eval- uation of large language models for code. InInternational Conference on Learning Representations, 2025
2025
-
[35]
LiveBench: A challenging, contamination-limited LLM benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz- Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. LiveBench: A challenging, contamination-limited LLM benchmark. InInternation...
2025
-
[36]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[37]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations, 2024
2024
-
[38]
Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
Pith/arXiv arXiv 2023
-
[39]
Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pa...
2025
-
[40]
MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for exp...
2024
-
[41]
MMMU-Pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. MMMU-Pro: A more robust multi-discipline multimodal understanding benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, 2025
2025
-
[42]
MathVista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learning Representations, 2024
2024
-
[43]
DynaMath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models
Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. DynaMath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models. InInternational Conference on Learning Representations, 2025
2025
-
[44]
Vision language models are blind: Failing to translate detailed visual features into words
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, and Anh Totti Nguyen. Vision language models are blind: Failing to translate detailed visual features into words. InAsian Conference on Computer Vision, 2024
2024
-
[45]
MMBench: Is your multi-modal model an all-around player? InEuropean Conference on Computer Vision, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. MMBench: Is your multi-modal model an all-around player? InEuropean Conference on Computer Vision, 2024
2024
-
[46]
Are we on the right way for evaluating large vision-language models? InAdvances in Neural Information Processing Systems, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, and Dahua Lin. Are we on the right way for evaluating large vision-language models? InAdvances in Neural Information Processing Systems, 2024
2024
-
[47]
RealWorldQA.https://huggingface.co/datasets/xai-org/RealworldQA, 2024
xAI. RealWorldQA.https://huggingface.co/datasets/xai-org/RealworldQA, 2024
2024
-
[48]
SimpleVQA: Multimodal factuality evaluation for multimodal large language models
Xianfu Cheng, Wei Zhang, Shiwei Zhang, Jian Yang, Xiangyuan Guan, Xianjie Wu, Xiang Li, Ge Zhang, Jiaheng Liu, Yuying Mai, Yutao Zeng, Zhoufutu Wen, Ke Jin, Baorui Wang, Weixiao Zhou, Yunhong Lu, Tongliang Li, Wenhao Huang, and Zhoujun Li. SimpleVQA: Multimodal factuality evaluation for multimodal large language models. InIEEE/CVF International Conference...
2025
-
[49]
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, Alexis Chevalier, Sanjeev Arora, and Danqi Chen. CharXiv: Charting gaps in realistic chart understanding in multimodal LLMs.arXiv preprint arXiv:2406.18521, 2024
arXiv 2024
-
[50]
OCRBench: On the hidden mystery of OCR in large multimodal models.Science China Information Sciences, 2024
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xucheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. OCRBench: On the hidden mystery of OCR in large multimodal models.Science China Information Sciences, 2024
2024
-
[51]
Teaching CLIP to count to ten
Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. Teaching CLIP to count to ten. InIEEE/CVF International Conference on Computer Vision, 2023
2023
-
[52]
Berg, and Tamara L
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg. Modeling context in referring expressions. InEuropean Conference on Computer Vision, 2016
2016
-
[53]
Gemini robotics: Bringing AI into the physical world.arXiv preprint arXiv:2503.20020, 2025
Gemini Robotics Team. Gemini robotics: Bringing AI into the physical world.arXiv preprint arXiv:2503.20020, 2025
Pith/arXiv arXiv 2025
-
[54]
Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Rongrong Ji, and Xing Sun. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis. InIEEE/CVF C...
2025
-
[55]
LibriSpeech: An ASR corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. LibriSpeech: An ASR corpus based on public domain audio books. InIEEE International Conference on Acoustics, Speech and Signal Processing, pages 5206–5210, 2015
2015
-
[56]
WenetSpeech: A 10000+ hours multi-domain mandarin corpus for speech recognition
Binbin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, Di Wu, and Zhendong Peng. WenetSpeech: A 10000+ hours multi-domain mandarin corpus for speech recognition. InIEEE International Conference on Acoustics, Speech and Signal Processing, pages 6182–6186, 2022
2022
-
[57]
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. WorldSense: Evaluating real-world omnimodal understanding for multimodal LLMs.arXiv preprint arXiv:2502.04326, 2025
Pith/arXiv arXiv 2025
-
[58]
Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
Qwen Team. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
Pith/arXiv arXiv 2025
-
[59]
Beyond the nav-graph: Vision and language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision and language navigation in continuous environments. InEuropean Conference on Computer Vision, 2020. 29 A System 1 Modality and Extensibility Details Table 9.Audio-conditioned motion-generation preference evaluation over 20 clips. Ten blind raters compare ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.