Test-Time Training for Robust Text-Guided Open-Vocabulary Object Counting
Pith reviewed 2026-06-27 01:14 UTC · model grok-4.3
The pith
A test-time training method makes text-guided open-vocabulary object counting robust to image corruptions by updating only a lightweight denoiser while freezing the main counter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
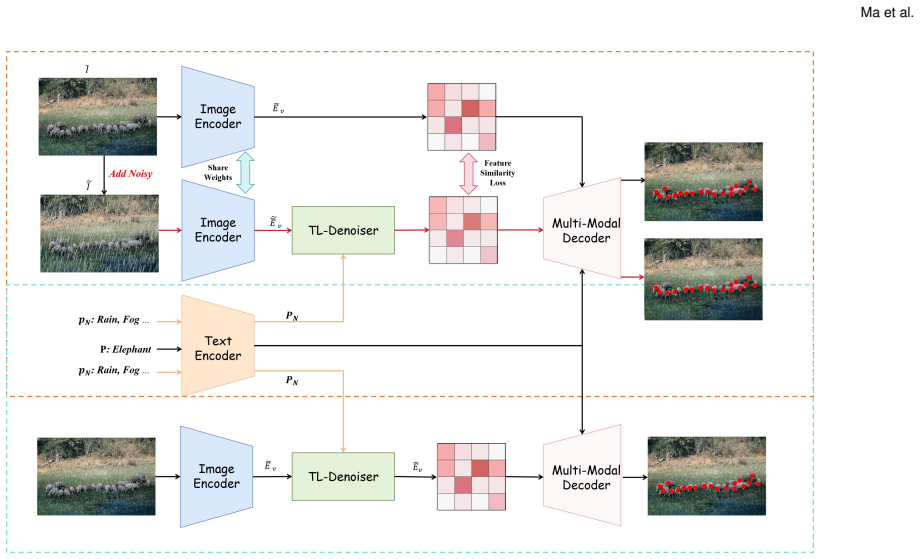
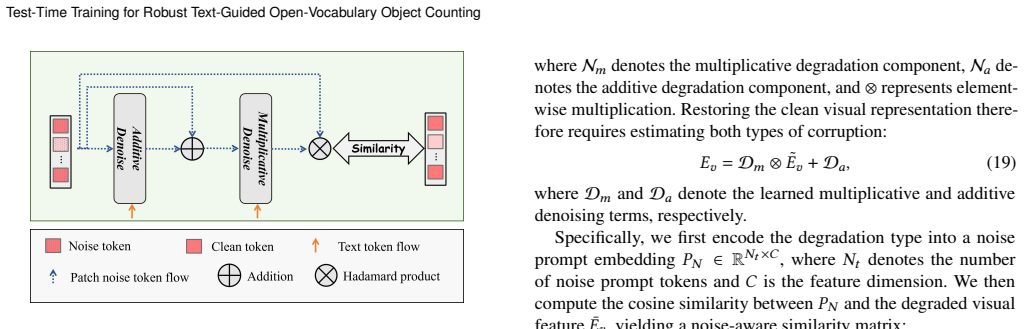
Dual-TTT improves robustness of text-guided open-vocabulary object counting by performing test-time training exclusively on the Text-guided Lightweight Denoising module to remove corruption-aware noise from image representations, while the original counting network stays frozen; the result is an annotation-free adaptation that integrates directly into any existing TOOC model without altering its structure.
What carries the argument
The Text-guided Lightweight Denoising module (TL-Denoiser), which is optimized at test time to remove corruption-aware noise from image representations while the counting network remains unchanged.
If this is right
- Existing TOOC models gain robustness to rain, fog, darkness, Gaussian noise, salt-and-pepper noise, and mixed corruption without any architecture modification.
- Adaptation requires no ground-truth counts or other labels at test time.
- The same Dual-TTT procedure can be applied to any current TOOC baseline while leaving its original performance on clean images intact.
- Only the lightweight TL-Denoiser parameters are updated, keeping the main counting network fixed.
Where Pith is reading between the lines
- The dual-architecture pattern could be reused for other vision-language tasks that face sudden distribution shifts at deployment.
- If the test-time step can be made faster, the same idea might support continuous adaptation in video streams with changing weather or lighting.
- The corruption-specific denoising objective might generalize to additional degradation types not covered in the current benchmark.
Load-bearing premise
Training the TL-Denoiser at test time on unlabeled corrupted images will improve the frozen counting network's accuracy without introducing new errors.
What would settle it
Running Dual-TTT on multiple TOOC baselines on the Robust-TOOC benchmark and finding that counting accuracy does not rise (or falls) relative to the original frozen models under the six corruption conditions.
Figures



read the original abstract
Text-guided Open-vocabulary Object Counting (TOOC) enables counting arbitrary object categories specified by text prompts, offering substantially greater flexibility than conventional closed-set counting. However, existing TOOC methods are developed and evaluated primarily on ideal images, while real-world scenes often suffer from adverse conditions such as rain, fog, darkness, and sensor noise, which severely degrade visual quality and impair vision-language alignment. To bridge this gap, we introduce Robust-TOOC, the first benchmark for evaluating TOOC under diverse corruption conditions, which covers six representative degradation types: rain, fog, darkness, Gaussian noise, salt-and-pepper noise, and mixed corruption. To improve robustness while preserving the original counting architecture, we propose Dual-TTT, a dual-architecture test-time training framework for TOOC. Specifically, during test-time training, Dual-TTT updates only the Text-guided Lightweight Denoising module (TL-Denoiser), while keeping the original counting network frozen. Inspired by diffusion models, the TL-Denoiser is optimized to remove corruption-aware noise from image representations under degraded conditions. Since only the TL-Denoiser is trained at test time, Dual-TTT is annotation-free and can be seamlessly integrated into existing TOOC models without modifying their original architecture. Extensive experiments on multiple recent TOOC baselines demonstrate the effectiveness of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Robust-TOOC benchmark covering six corruption types (rain, fog, darkness, Gaussian noise, salt-and-pepper noise, mixed) for evaluating text-guided open-vocabulary object counting (TOOC) under adverse conditions. It proposes Dual-TTT, a test-time training framework that optimizes only a Text-guided Lightweight Denoising module (TL-Denoiser) at inference time via a diffusion-inspired objective to remove corruption-aware noise from image representations, while freezing the original counting network. The approach is presented as annotation-free and architecture-preserving for integration into existing TOOC models, with claims of effectiveness supported by extensive experiments on recent baselines.
Significance. If validated, the benchmark would enable systematic robustness evaluation for TOOC, and Dual-TTT would offer a practical, annotation-free adaptation strategy that avoids retraining or modifying deployed counting networks. This could meaningfully extend TOOC applicability to real-world degraded imagery without requiring labeled data at test time.
major comments (2)
- [Dual-TTT framework description] The method description states that the TL-Denoiser is optimized solely via a diffusion-inspired objective on corruption-aware noise with the counting network frozen and no annotations used; however, no loss term, gradient pathway, or auxiliary objective is shown that directly connects the denoising updates to improved counting accuracy (as opposed to merely reducing a proxy noise loss). This leaves open the possibility that denoised features could distort cues relied upon by the frozen counter.
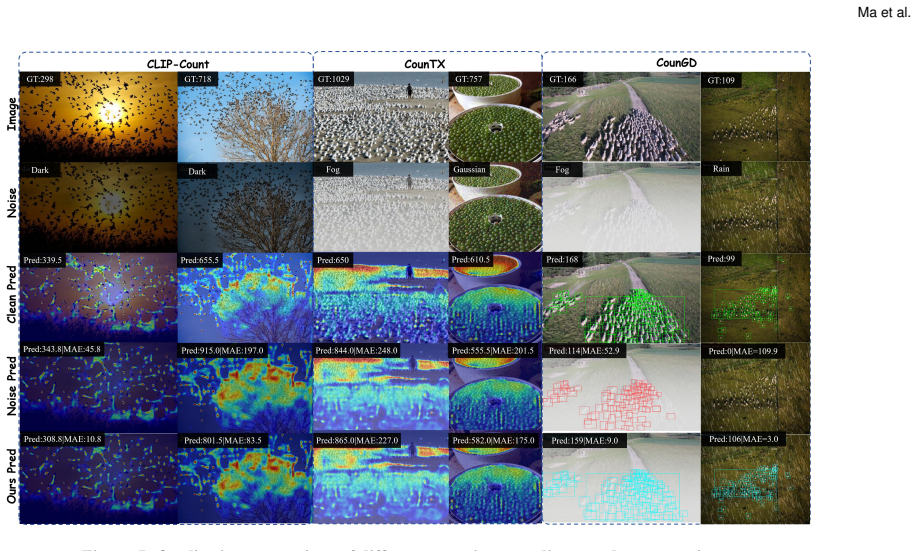
- [Abstract and experimental claims] The abstract asserts that 'extensive experiments on multiple recent TOOC baselines demonstrate the effectiveness of our method,' yet the manuscript contains no tables, figures, quantitative metrics (e.g., MAE, RMSE under each corruption), ablation studies, or implementation details that would allow verification of the claimed improvements or the annotation-free property.
minor comments (2)
- Clarify the precise architecture of the TL-Denoiser (e.g., number of layers, conditioning mechanism on text prompts) and how 'corruption-aware noise' is generated or estimated at test time.
- Add a diagram illustrating the dual-architecture flow (frozen counter vs. updated TL-Denoiser) and the test-time optimization loop.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the two major comments below and will incorporate clarifications and missing content in a revised manuscript.
read point-by-point responses
-
Referee: [Dual-TTT framework description] The method description states that the TL-Denoiser is optimized solely via a diffusion-inspired objective on corruption-aware noise with the counting network frozen and no annotations used; however, no loss term, gradient pathway, or auxiliary objective is shown that directly connects the denoising updates to improved counting accuracy (as opposed to merely reducing a proxy noise loss). This leaves open the possibility that denoised features could distort cues relied upon by the frozen counter.
Authors: We agree that the current description does not explicitly detail a loss term or gradient pathway that directly ties the denoising objective to counting accuracy. The TL-Denoiser is optimized via a diffusion-inspired proxy loss on corrupted representations, with the assumption that cleaner features will benefit the frozen counter; however, no auxiliary objective linking the two is presented. To address the valid concern about potential feature distortion, we will revise the method section to include a clearer explanation of the information flow and add an analysis (e.g., feature similarity or counting-relevant cue preservation) demonstrating that the updates do not harm the counter's performance. revision: yes
-
Referee: [Abstract and experimental claims] The abstract asserts that 'extensive experiments on multiple recent TOOC baselines demonstrate the effectiveness of our method,' yet the manuscript contains no tables, figures, quantitative metrics (e.g., MAE, RMSE under each corruption), ablation studies, or implementation details that would allow verification of the claimed improvements or the annotation-free property.
Authors: The referee is correct that the submitted manuscript lacks the experimental results, tables, figures, ablations, and implementation details needed to substantiate the abstract claims. We will add a full experimental section with quantitative metrics (MAE/RMSE per corruption type), comparisons against baselines, ablations on the TL-Denoiser, and details confirming the annotation-free and architecture-preserving properties. revision: yes
Circularity Check
No circularity: method is a proposed test-time framework without equations or self-referential reductions.
full rationale
The paper introduces Robust-TOOC benchmark and Dual-TTT framework as an annotation-free test-time optimization of a TL-Denoiser module while freezing the counting network. No mathematical derivations, equations, or predictions are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The approach is described architecturally and inspired by diffusion models, with effectiveness claimed via experiments on baselines; the central claim does not rely on load-bearing self-referential steps and remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimizing the TL-Denoiser to remove corruption-aware noise from image representations will improve downstream counting accuracy on degraded inputs.
invented entities (1)
-
TL-Denoiser
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amini-Naieni, K
N. Amini-Naieni, K. Amini-Naieni, T. Han, and A. Zisserman. 2023. Open-world Text-specified Object Counting. InBritish Machine Vision Conference (BMCV)
2023
-
[2]
Amini-Naieni, T
N. Amini-Naieni, T. Han, and A. Zisserman. 2024. CountGD: Multi-Modal Open-World Counting. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[3]
Ricardo Guerrero-Gómez-Olmedo, Beatriz Torre-Jiménez, Roberto López-Sastre, Saturnino Maldonado-Bascón, and Daniel O noro Rubio. 2015. Extremely Over- lapping Vehicle Counting. InIberian Conference on Pattern Recognition and Image Analysis (IbPRIA)
2015
-
[4]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems (NeurIPS)33 (2020), 6840–6851
2020
-
[5]
Meng-Ru Hsieh, Yen-Liang Lin, and Winston H Hsu. 2017. Drone-based object counting by spatially regularized regional proposal network. InProceedings of the IEEE international conference on computer vision (ICCV)
2017
-
[6]
Ruixiang Jiang, Lingbo Liu, and Changwen Chen. 2023. CLIP-Count: To- wards Text-Guided Zero-Shot Object Counting.arXiv preprint arXiv:2305.07304 (2023)
arXiv 2023
-
[7]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114(2013)
Pith/arXiv arXiv 2013
-
[8]
Ming Li, Yupeng Hu, Yinwei Wei, Hao Liu, Haocong Wang, and Weili Guan
-
[9]
InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM)
DCount: Decoupled Spatial Perception and Attribute Discrimination for Referring Expression Counting. InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM). 5306–5315
-
[10]
Hao-Yuan Ma and Li Zhang. 2024. Multi-head multi-scale pixel localization network for crowd counting with highly dense and small-scale samples. In2024 IEEE International Conference on Multimedia and Expo (ICME). 1–5
2024
-
[11]
Hao-Yuan Ma, Li Zhang, and Minjie Qiang. 2026. OVID: Text-Guided Open- V ocabulary Dense Object Counting and Localization.IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP)(2026)
2026
-
[12]
Hao-Yuan Ma, Li Zhang, and Shuai Shi. 2024. VMambaCC: A Visual State Space Model for Crowd Counting.arXiv preprint arXiv:2405.03978(2024)
arXiv 2024
-
[13]
Hao-Yuan Ma, Li Zhang, and Xiang-Yi Wei. 2024. FGENet: Fine-Grained Extraction Network for Congested Crowd Counting. InProceedings of the 30th International Conference on Multimedia Modeling (MMM)
2024
-
[14]
Cinthya Vanessa Muñoz Macas, Jorge Andrés Espinoza Aguirre, Rodrigo Arcentales-Carrión, and Mario Peña. 2021. Inventory management for retail companies: A literature review and current trends. In2021 second international conference on information systems and software technologies (ICISST). IEEE, 71–78
2021
-
[15]
Sarthak Kumar Maharana, Baoming Zhang, Leonid Karlinsky, Rogério Feris, and Yunhui Guo. 2024. Enhancing robustness of clip to common corruptions through bimodal test-time adaptation.arXiv preprint arXiv:2412.02837(2024)
arXiv 2024
-
[16]
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. 2022. Efficient Test-Time Model Adaptation without Forgetting. InThe Internetional Conference on Machine Learning (ICML)
2022
-
[17]
Viresh Ranjan, Udbhav Sharma, Thu Nguyen, and Minh Hoai. 2021. Learning to count everything. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3394–3403
2021
-
[18]
Xiaoqian Ruan and Wei Tang. 2024. Fully test-time adaptation for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1038–1047
2024
-
[19]
Ziqiang Shi, Rujie Liu, Jun Takahashi, and Shan Jiang. 2025. TrueCount: Improv- ing Open-World Object Counting with Visual-Language Models and Dynamic Multi-Modal Inputs. InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM). 1764–1773
2025
-
[20]
Samarth Sinha, Peter Gehler, Francesco Locatello, and Bernt Schiele. 2023. Test: Test-time self-training under distribution shift. InProceedings of the IEEE/CVF winter conference on applications of computer vision (WACV). 2759–2769
2023
-
[21]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli
-
[22]
In International conference on machine learning (ICML)
Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning (ICML). pmlr, 2256–2265
-
[23]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020)
Pith/arXiv arXiv 2020
-
[24]
Qingyu Song, Changan Wang, Zhengkai Jiang, Yabiao Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Yang Wu. 2021. Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 3365–3374
2021
-
[25]
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt
-
[26]
InInternational conference on machine learning (ICML)
Test-time training with self-supervision for generalization under distribution shifts. InInternational conference on machine learning (ICML). 9229–9248
-
[27]
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. 2021. Tent: Fully Test-Time Adaptation by Entropy Minimization. In International Conference on Learning Representations (ICLR)
2021
-
[28]
Qin Wang, Olga Fink, Luc Van Gool, and Dengxin Dai. 2022. Continual test-time domain adaptation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (ICCV). 7201–7211
2022
-
[29]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth anything v2.Advances in Neural Information Processing Systems (NeurIPS)37 (2024), 21875–21911
2024
-
[30]
Shiwei Zhang, Qi Zhou, and Wei Ke. 2025. Enhancing Zero-shot Object Counting via Text-guided Local Ranking and Number-evoked Global Attention. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 21097–21106
2025
-
[31]
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T Freeman, and Hao Tan. 2025. Test-time training done right.arXiv preprint arXiv:2505.23884(2025)
Pith/arXiv arXiv 2025
-
[32]
Yiming Zhao, Guorong Li, Laiyun Qing, Amin Beheshti, Jian Yang, Quan Z Sheng, Yuankai Qi, and Qingming Huang. 2025. SDVPT: Semantic-Driven Visual Prompt Tuning for Open-World Object Counting. InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM). 5413–5421
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.