Understanding and Debugging Failures in N-Gram-Based Generative Retrieval
Pith reviewed 2026-06-26 22:40 UTC · model grok-4.3
The pith
N-gram generative retrieval systems fail when document IDs are ambiguous or lack diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
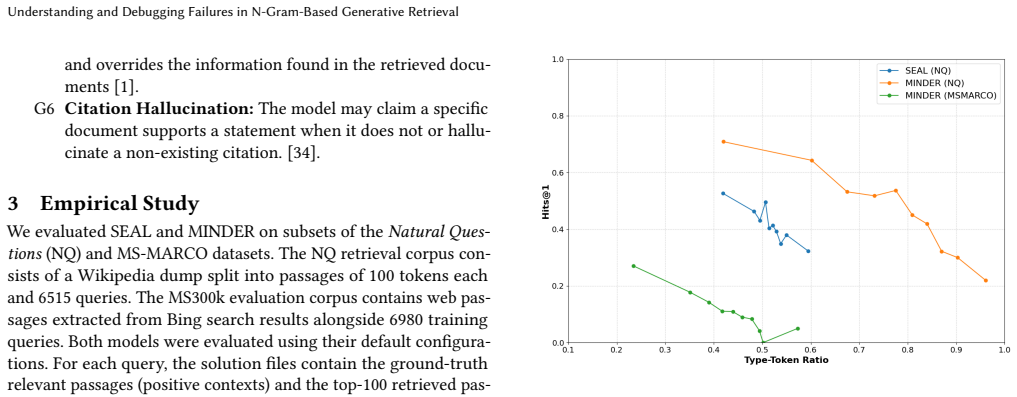
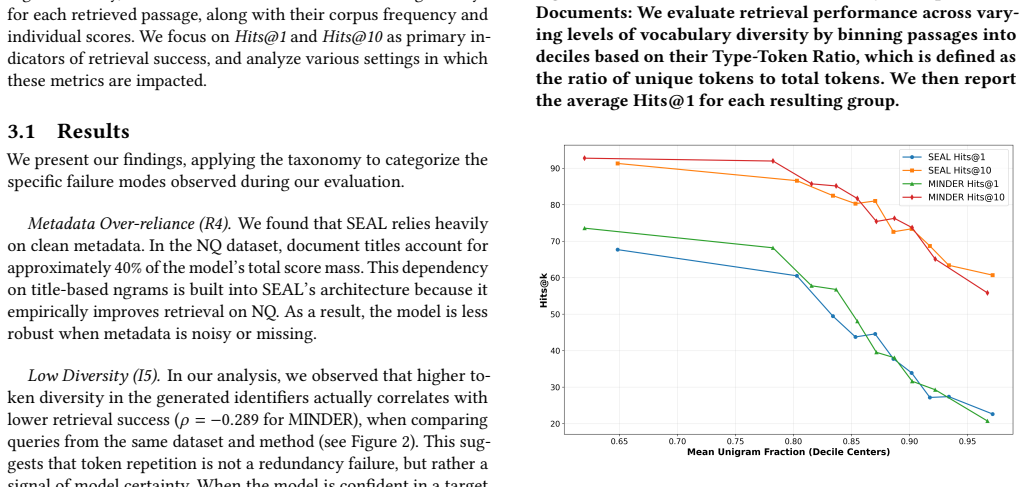
By examining SEAL and MINDER the authors show that n-gram generative retrieval repeatedly produces ambiguous document identifiers, low identifier diversity, and rankings that are disproportionately controlled by a small set of identifiers; a taxonomy of GR failure modes organizes these observations and a browser-based inspection tool makes the contribution of each generated n-gram visible.
What carries the argument
The taxonomy of GR failure modes together with the per-ngram contribution viewer that surfaces which generated sequences determine the ranked list.
If this is right
- Improving diversity among generated identifiers should reduce the observed ranking distortions.
- The released inspection tool can be used to locate and remove high-impact but low-quality n-grams during development.
- Design choices that increase identifier ambiguity can be measured and avoided at training time.
- Debugging effort can shift from overall model accuracy to targeted fixes on the identifier generation step.
Where Pith is reading between the lines
- The same identifier-level diagnostics could be applied to non-n-gram generative retrievers to test whether ambiguity remains the dominant failure.
- If low diversity is the root issue, training objectives that explicitly reward distinct identifier sets become a direct next step.
- The taxonomy may serve as a checklist for evaluating new GR architectures before large-scale deployment.
Load-bearing premise
The failure patterns found in the two studied n-gram systems also appear in other n-gram generative retrieval methods.
What would settle it
Run the same analysis on a third n-gram GR system and observe no ambiguous docids, high identifier diversity, and even impact across identifiers.
Figures



read the original abstract
Generative Retrieval (GR) is an emerging Information Retrieval (IR) paradigm that is motivated by increasingly capable language models. In GR, a model directly generates identifiers for relevant documents. While these systems offer unique advantages, they also introduce distinct failure mechanisms. We explore these failure modes in three contributions: (1) We present a taxonomy of GR failure modes based on GR literature. (2) We empirically investigate failure in a subset of GR: ngram-based methods, more specifically, SEAL and MINDER. Our analysis reveals common issues, such as ambiguous docids, low identifier diversity, and the disproportionate impact of specific identifiers. (3) We introduce a new web-based tool that helps the IR community analyze generated ngrams and their respective contribution to the final ranking, providing an intuitive interface to identify where such GR methods go wrong.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to advance understanding of failures in generative retrieval by providing a taxonomy of failure modes based on GR literature, empirically investigating failures in n-gram-based methods specifically using SEAL and MINDER to reveal common issues such as ambiguous docids, low identifier diversity, and the disproportionate impact of specific identifiers, and introducing a new web-based tool for analyzing generated ngrams and their contribution to the final ranking.
Significance. If the identified issues prove representative of n-gram-based generative retrieval, the taxonomy provides a structured framework for categorizing failures in an emerging IR paradigm, while the web-based tool offers a practical debugging resource for the community. The work highlights distinct failure mechanisms in GR systems that differ from traditional retrieval, potentially guiding future method development.
major comments (1)
- [Empirical investigation of SEAL and MINDER] Contribution (2) and the associated empirical analysis: The claim that the observed issues constitute 'common issues' in n-gram-based generative retrieval is based solely on analysis of SEAL and MINDER. Without additional independent n-gram GR systems or a parameter-free argument that these issues necessarily arise from any n-gram docid construction, the generalization to the broader class remains under-supported. This is load-bearing for the paper's assertion of commonality.
minor comments (1)
- [Abstract] The abstract and introduction could more explicitly qualify the scope of the empirical findings as applying to the two examined systems rather than implying class-wide properties without further qualification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Empirical investigation of SEAL and MINDER] Contribution (2) and the associated empirical analysis: The claim that the observed issues constitute 'common issues' in n-gram-based generative retrieval is based solely on analysis of SEAL and MINDER. Without additional independent n-gram GR systems or a parameter-free argument that these issues necessarily arise from any n-gram docid construction, the generalization to the broader class remains under-supported. This is load-bearing for the paper's assertion of commonality.
Authors: We acknowledge the validity of this point: the empirical analysis is confined to SEAL and MINDER, the two primary n-gram-based GR systems in the literature at the time of writing. The manuscript already qualifies the scope as 'ngram-based methods, more specifically, SEAL and MINDER,' but the phrasing 'common issues' can be read as implying broader generality. To address this, we will revise the relevant sections to (a) explicitly state that the issues are observed in these representative systems, (b) provide a brief discussion of why n-gram docid construction (overlapping n-grams, identifier ambiguity, and ranking sensitivity) may produce similar effects in other n-gram approaches, and (c) add a limitations paragraph noting that validation on additional independent systems would further strengthen the claims. This revision directly mitigates the load-bearing concern without overstating the current evidence. revision: yes
Circularity Check
No circularity; purely empirical taxonomy and case study on two systems
full rationale
The paper contains no mathematical derivations, fitted parameters, predictions, or equations. Contribution (1) is a taxonomy drawn from existing GR literature; contribution (2) reports direct observations on the two concrete systems SEAL and MINDER; contribution (3) is a new analysis tool. None of these steps reduce to self-definition, fitted-input renaming, or load-bearing self-citation chains. The representativeness concern raised by the skeptic is a question of external validity, not circularity. The work is therefore self-contained as a descriptive study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Garima Agrawal, Tharindu Kumarage, Zeyad Alghamdi, and Huan Liu. 2024. Mindful-RAG: A Study of Points of Failure in Retrieval Augmented Generation. arXiv:2407.12216 [cs.IR] https://arxiv.org/abs/2407.12216
arXiv 2024
-
[2]
Md Abdul Aowal, Maliha T Islam, Priyanka Mary Mammen, and Sandesh Shetty. 2023. Detecting Natural Language Biases with Prompt-based Learn- ing. arXiv:2309.05227 [cs.CL] https://arxiv.org/abs/2309.05227
arXiv 2023
-
[3]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. arXiv:2310.11511 [cs.CL] https://arxiv.org/abs/2310.11511
Pith/arXiv arXiv 2023
-
[4]
Scott Barnett, Stefanus Kurniawan, Srikanth Thudumu, Zach Brannelly, and Mohamed Abdelrazek. 2024. Seven Failure Points When Engineering a Retrieval Augmented Generation System. arXiv:2401.05856 [cs.SE] https://arxiv.org/abs/ 2401.05856
arXiv 2024
-
[5]
Michele Bevilacqua, Giuseppe Ottaviano, Patrick Lewis, Scott Yih, Sebastian Riedel, and Fabio Petroni. 2022. Autoregressive search engines: Generating substrings as document identifiers.Advances in Neural Information Processing Systems35 (2022), 31668–31683
2022
-
[6]
Adrian Bracher and Svitlana Vakulenko. 2026. Generative Retrieval Overcomes Limitations of Dense Retrieval but Struggles with Identifier Ambiguity.arXiv preprint arXiv:2604.05764(2026)
Pith/arXiv arXiv 2026
-
[7]
Jiehan Cheng, Zhicheng Dou, Yutao Zhu, and Xiaoxi Li. 2025. Descriptive and Discriminative Document Identifiers for Generative Retrieval.Proceedings of the AAAI Conference on Artificial Intelligence39, 11 (Apr. 2025), 11518–11526. doi:10.1609/aaai.v39i11.33253
-
[8]
N De Cao, G Izacard, S Riedel, and F Petroni. 2020. Autoregressive Entity Retrieval. InICLR 2021-9th International Conference on Learning Representations, Vol. 2021. ICLR
2020
-
[9]
P. Ferragina and G. Manzini. 2000. Opportunistic data structures with applica- tions. InProceedings 41st Annual Symposium on Foundations of Computer Science. 390–398. doi:10.1109/SFCS.2000.892127
-
[10]
Nikita Nangia, Clara Vania, Rasika Bhalerao, and Samuel R
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K. Ahmed. 2024. Bias and Fairness in Large Language Models: A Survey.Computational Linguistics50, 3 (September 2024), 1097–1179. doi:10.1162/coli_a_00524
-
[11]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Transactions on Information Systems43, 2 (January 2025), 1–55. doi:10.1145/3703155
-
[12]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering.. InEMNLP (1). 6769–6781
2020
-
[13]
Tzu-Lin Kuo, Tzu-Wei Chiu, Tzung-Sheng Lin, Sheng-Yang Wu, Chao-Wei Huang, and Yun-Nung Chen. 2024. A Survey of Generative Information Retrieval. arXiv:2406.01197 [cs.IR] https://arxiv.org/abs/2406.01197
arXiv 2024
-
[14]
Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: a Benchmark for Question Answering Research.Tr...
2019
-
[15]
Sunkyung Lee, Minjin Choi, and Jongwuk Lee. 2023. GLEN: Generative Retrieval via Lexical Index Learning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 7693–7704
2023
-
[16]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mo- hamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2019. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.arXiv preprint arXiv:1910.13461(2019)
Pith/arXiv arXiv 2019
-
[17]
Xiaoxi Li, Jiajie Jin, Yujia Zhou, Yuyao Zhang, Peitian Zhang, Yutao Zhu, and Zhicheng Dou. 2025. From Matching to Generation: A Survey on Generative Information Retrieval. arXiv:2404.14851 [cs.IR] https://arxiv.org/abs/2404.14851
arXiv 2025
-
[18]
Yongqi Li, Nan Yang, Liang Wang, Furu Wei, and Wenjie Li. 2023. Multiview Identifiers Enhanced Generative Retrieval. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 6636–6648
2023
-
[19]
Yongqi Li, Nan Yang, Liang Wang, Furu Wei, and Wenjie Li. 2024. Learning to Rank in Generative Retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 8716–8723. https://doi.org/10.1609/aaai.v38i8.28717
-
[20]
Yongqi Li, Zhen Zhang, Wenjie Wang, Liqiang Nie, Wenjie Li, and Tat-Seng Chua
-
[21]
Distillation Enhanced Generative Retrieval. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 11119–11129. doi:10.18653/v1/2024.findings-acl.662
-
[22]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics12 (2024), 157–173
2024
-
[23]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Changjiang Zhou, Maarten de Rijke, and Xueqi Cheng. 2024. On the Robustness of Generative Information Retrieval Models. arXiv:2412.18768 [cs.IR] https://arxiv.org/abs/2412.18768
arXiv 2024
-
[24]
Tran, Jinfeng Rao, Marc Najork, Emma Strubell, and Donald Metzler
Sanket Vaibhav Mehta, Jai Gupta, Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Jinfeng Rao, Marc Najork, Emma Strubell, and Donald Metzler. 2023. DSI++: Updating Transformer Memory with New Documents. arXiv:2212.09744 [cs.CL] https://arxiv.org/abs/2212.09744
arXiv 2023
-
[25]
Kidist Amde Mekonnen, Yubao Tang, and Maarten de Rijke. 2025. Light- weight and Direct Document Relevance Optimization for Generative Infor- mation Retrieval. InProceedings of the 48th International ACM SIGIR Confer- ence on Research and Development in Information Retrieval (SIGIR ’25). https: //arxiv.org/abs/2504.05181 Introduces direct pairwise ranking ...
Pith/arXiv arXiv 2025
-
[26]
Donald Metzler, Yi Tay, Dara Bahri, and Marc Najork. 2021. Rethinking search: making domain experts out of dilettantes.ACM SIGIR Forum55, 1 (June 2021), 1–27. doi:10.1145/3476415.3476428
-
[27]
Tarek Naous, Michael J. Ryan, Alan Ritter, and Wei Xu. 2024. Having Beer after Prayer? Measuring Cultural Bias in Large Language Models. arXiv:2305.14456 [cs.CL] https://arxiv.org/abs/2305.14456
arXiv 2024
-
[28]
Roberto Navigli, Simone Conia, and Björn Ross. 2023. Biases in Large Language Models: Origins, Inventory, and Discussion.J. Data and Information Quality15, 2, Article 10 (June 2023), 21 pages. doi:10.1145/3597307
-
[29]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. Ms marco: A human-generated machine reading comprehension dataset. (2016)
2016
-
[30]
Lelkes, Honglei Zhuang, Jimmy Lin, Donald Metzler, and Vinh Q
Ronak Pradeep, Kai Hui, Jai Gupta, Adam D. Lelkes, Honglei Zhuang, Jimmy Lin, Donald Metzler, and Vinh Q. Tran. 2023. How Does Generative Retrieval Scale to Millions of Passages? arXiv:2305.11841 [cs.IR] https://arxiv.org/abs/2305.11841
arXiv 2023
-
[31]
Weiwei Sun, Keyi Kong, Xinyu Ma, Shuaiqiang Wang, Dawei Yin, Maarten de Rijke, Zhaochun Ren, and Yiming Yang. 2025. ZeroGR: A Generalizable and Scalable Framework for Zero-Shot Generative Retrieval.arXiv preprint arXiv:2510.10419(2025)
Pith/arXiv arXiv 2025
-
[32]
Weiwei Sun, Lingyong Yan, Zheng Chen, Shuaiqiang Wang, Haichao Zhu, Pengjie Ren, Zhumin Chen, Dawei Yin, Maarten Rijke, and Zhaochun Ren. 2023. Learning to tokenize for generative retrieval.Advances in Neural Information Processing Systems36 (2023), 46345–46361
2023
-
[33]
Yubao Tang, Ruqing Zhang, Weiwei Sun, Jiafeng Guo, and Maarten De Rijke
-
[34]
InCompanion Proceedings of the ACM Web Conference 2024(Singapore, Singapore)(WWW ’24)
Recent Advances in Generative Information Retrieval. InCompanion Proceedings of the ACM Web Conference 2024(Singapore, Singapore)(WWW ’24). Association for Computing Machinery, New York, NY, USA, 1238–1241. doi:10.1145/3589335.3641239
-
[35]
Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. 2022. Transformer memory as a differentiable search index.Advances in Neural Information Processing Systems 35 (2022), 21831–21843
2022
-
[36]
Jonas Wallat, Maria Heuss, Maarten de Rijke, and Avishek Anand. 2025. Cor- rectness is not Faithfulness in Retrieval Augmented Generation Attributions. InProceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR). 22–32
2025
-
[37]
Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, et al . 2022. A neural corpus indexer for document retrieval.Advances in Neural Information Processing Systems35 (2022), 25600–25614
2022
-
[38]
Ye Wang, Xinrun Xu, and Zhiming Ding. 2025. MindRef: Mimicking Human Mem- ory for Hierarchical Reference Retrieval with Fine-Grained Location Awareness. arXiv:2402.17010 [cs.CL] https://arxiv.org/abs/2402.17010
arXiv 2025
-
[39]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903 [cs.CL] https: //arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2023
-
[40]
Peiwen Yuan, Xinglin Wang, Shaoxiong Feng, Boyuan Pan, Yiwei Li, Heda Wang, Xupeng Miao, and Kan Li. 2024. Generative Dense Retrieval: Memory Can Be a Burden. arXiv:2401.10487 [cs.IR] https://arxiv.org/abs/2401.10487 Richard Takacs, Adrian Bracher, and Svitlana Vakulenko
arXiv 2024
-
[41]
Hansi Zeng, Chen Luo, Bowen Jin, Sheikh Muhammad Sarwar, Tianxin Wei, and Hamed Zamani. 2024. Scalable and effective generative information retrieval. In Proceedings of the ACM Web Conference 2024. 1441–1452
2024
-
[42]
Hansi Zeng, Chen Luo, and Hamed Zamani. 2024. Planning ahead in generative retrieval: Guiding autoregressive generation through simultaneous decoding. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 469–480
2024
-
[43]
Fuwei Zhang, Xiaoyu Liu, Xinyu Jia, Yingfei Zhang, Shuai Zhang, Xiang Li, Fuzhen Zhuang, Wei Lin, and Zhao Zhang. 2025. Multi-level Relevance Document Identifier Learning for Generative Retrieval. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutov...
-
[44]
Peitian Zhang, Zheng Liu, Yujia Zhou, Zhicheng Dou, Fangchao Liu, and Zhao Cao. 2024. Generative retrieval via term set generation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 458–468
2024
-
[45]
Zhen Zhang, Xinyu Ma, Weiwei Sun, Pengjie Ren, Zhumin Chen, Shuaiqiang Wang, Dawei Yin, Maarten de Rijke, and Zhaochun Ren. 2025. Replication and Exploration of Generative Retrieval over Dynamic Corpora. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3325–3334
2025
-
[46]
Yujia Zhou, Jing Yao, Zhicheng Dou, Ledell Wu, Peitian Zhang, and Ji-Rong Wen
-
[47]
Ultron: An ultimate retriever on corpus with a model-based indexer.arXiv preprint arXiv:2208.09257(2022)
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.