Environment-Grounded Automated Prompt Optimization for LLM Game Agents
Pith reviewed 2026-06-27 00:28 UTC · model grok-4.3
The pith
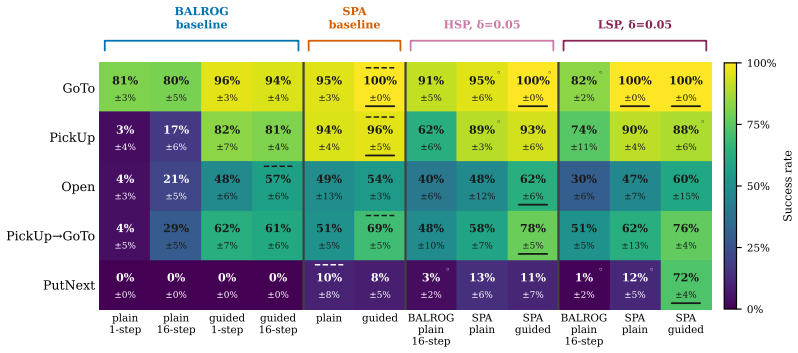
Automated prompt optimization lets the same LLM agent reach 72.5 percent success on tasks where fixed prompts score zero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
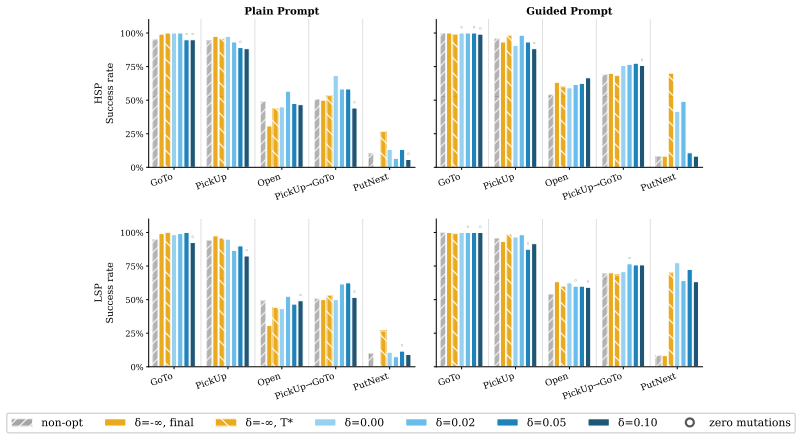
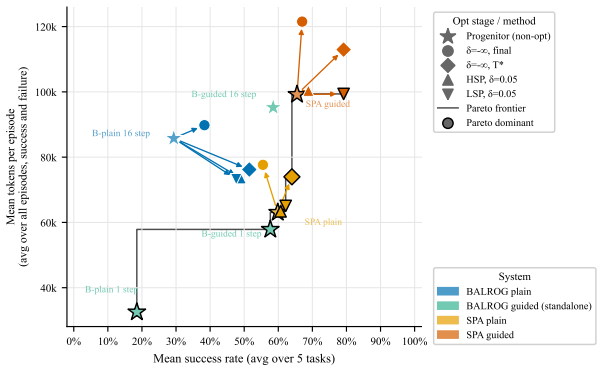
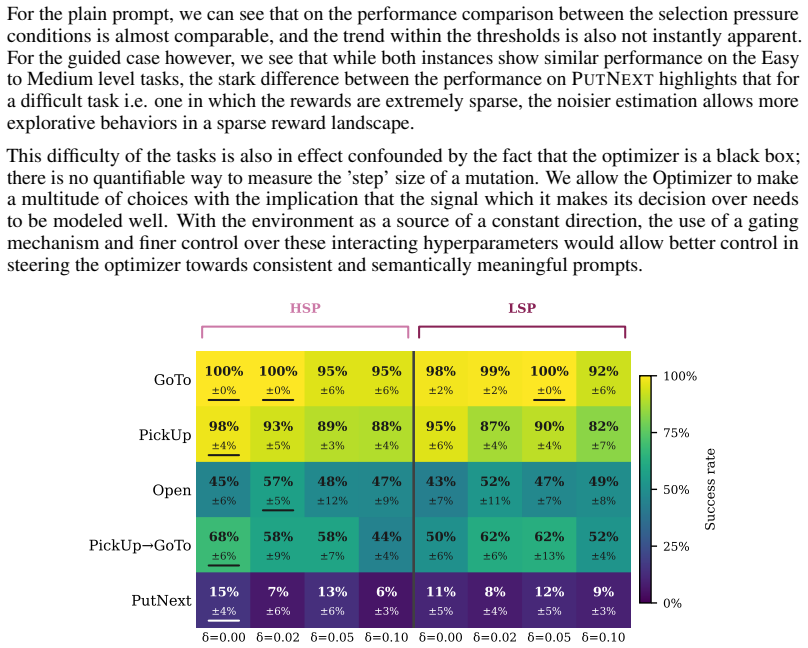
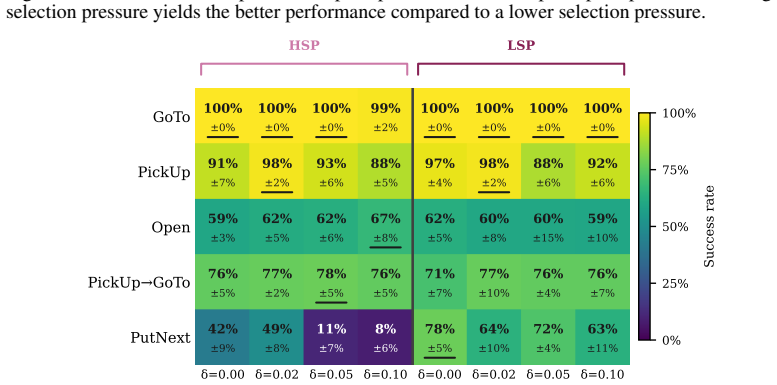
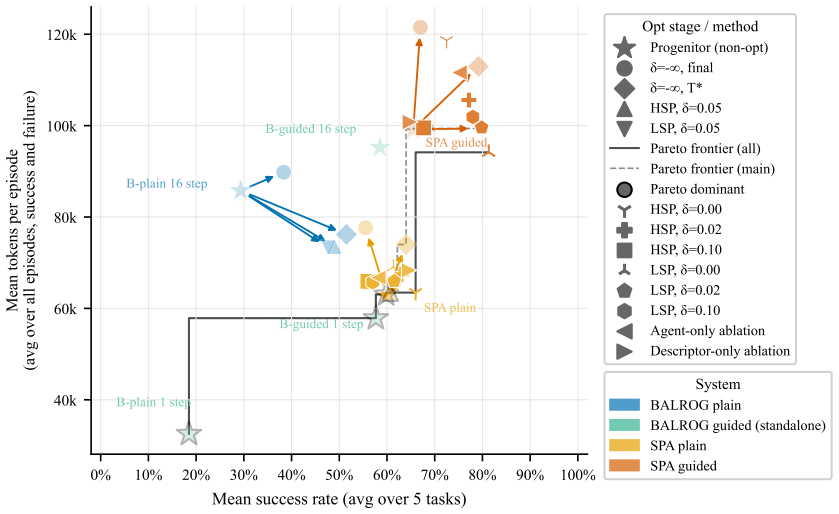
The authors demonstrate that an environment-grounded evolutionary loop, driven by a behavior analyzer that attributes outcomes to prompt components and a mutator that generates targeted revisions, produces optimized prompts that consistently outperform the RobustCoTAgent baseline on all five BabyAI tasks, reaching 72.5 percent success on PutNext where the baseline records zero percent.
What carries the argument
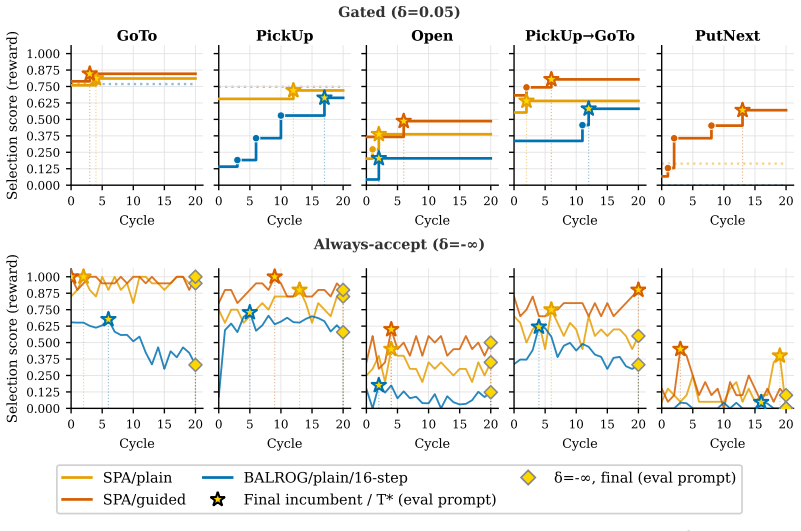
The behavior analyzer and mutator operating inside an LLM-driven evolutionary loop that validates every candidate prompt through direct environment rollouts.
If this is right
- Performance gains appear under both plain and guided initial prompts.
- No model-weight updates are required for the reported improvements.
- The multi-agent decomposition supports refinement on coordination-heavy tasks.
- The same loop can be applied to every task in the BALROG benchmark.
Where Pith is reading between the lines
- The approach could be tested on non-grid environments to check whether environment returns remain sufficient guidance.
- If the analyzer scales, it might reduce the need for task-specific human prompt writing in new games.
- Combining the loop with occasional fine-tuning steps remains an open direction the paper does not explore.
Load-bearing premise
The behavior analyzer can correctly link each episode result to the specific prompt parts that caused it.
What would settle it
Running the full pipeline on a new BabyAI level or similar grid-world task and finding that the final optimized prompts produce no measurable gain over the unoptimized baseline.
Figures



read the original abstract
LLM agents in interactive environments are highly sensitive to their prompts, yet prompt engineering remains a manual, task-specific process. We introduce an automated prompt optimization framework for LLM agents that decomposes the observation-to-action pipeline into a goal-conditioned descriptor agent and an action selection agent, and iteratively refines each module's prompt through an LLM-driven evolutionary loop guided by environment returns. We propose a behavior analyzer to attribute episode outcomes to specific prompt components, and a mutator to propose targeted revisions to the prompt, before validating them through environment rollouts. We evaluate on all five BabyAI tasks in the BALROG benchmark, comparing our pipeline against BALROG's RobustCoTAgent under both plain and guided prompt initializations. Optimization improves performance consistently across tasks and conditions, without requiring updates to the model weights. On PutNext, a multi-step coordination task where the RobustCoTAgent achieves 0% success, our framework reaches up to 72.5% success rate using the same underlying LLM with optimized prompts. These results suggest that a multi-agent framework, combined with automatic prompt optimization, enhances LLMs without the need for fine-tuning or extensive human supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an automated prompt optimization framework for LLM agents in interactive environments. It decomposes the observation-to-action pipeline into a goal-conditioned descriptor agent and an action selection agent, then refines each via an LLM-driven evolutionary loop that uses a behavior analyzer to attribute episode outcomes to prompt components and a mutator to propose revisions, all validated by environment rollouts. Experiments on the five BabyAI tasks from the BALROG benchmark show consistent gains over RobustCoTAgent baselines under plain and guided initializations, with the largest reported improvement being an increase from 0% to 72.5% success on the PutNext task using the same underlying LLM and no weight updates.
Significance. If the results hold after verification of the analyzer and experimental details, the work would be significant for demonstrating that environment-grounded prompt optimization can produce large gains on multi-step coordination tasks without model fine-tuning or extensive human supervision. The use of actual environment returns rather than fitted or self-referential metrics is a clear strength that reduces circularity risk.
major comments (2)
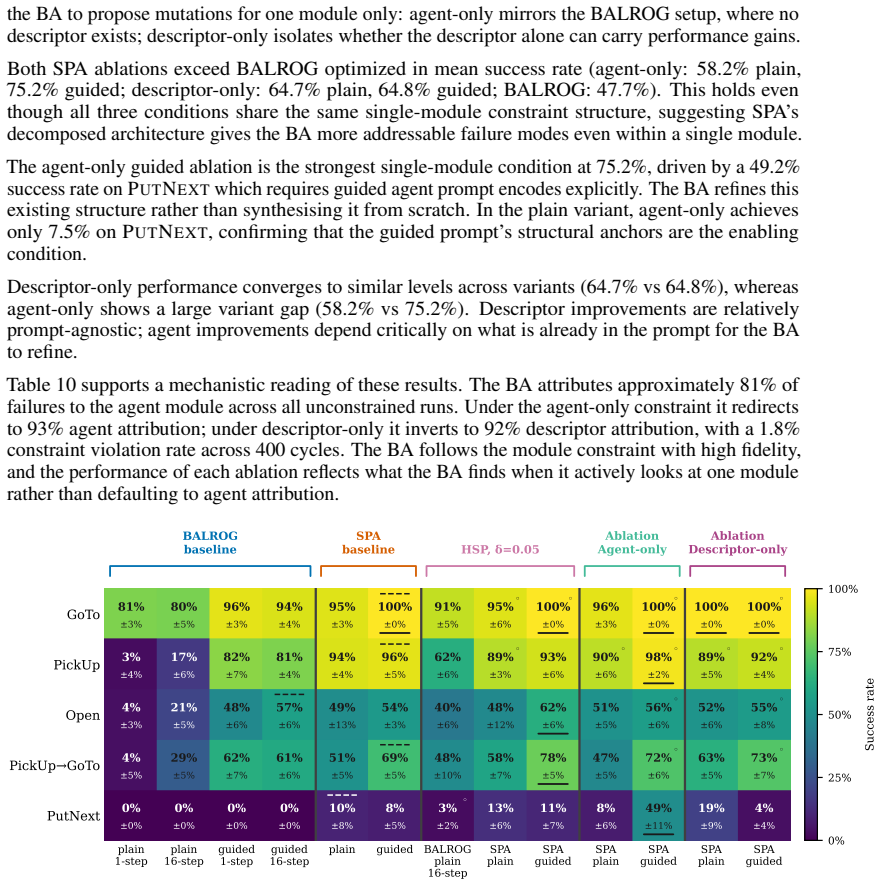
- [Behavior Analyzer] Behavior Analyzer subsection: the central claim that targeted revisions explain the jump from 0% to 72.5% on PutNext rests on the analyzer accurately mapping trajectories to specific prompt components. No human validation, inter-annotator agreement, or ablation is reported to establish that the attributions are reliable rather than heuristic or noisy; without this, the observed gains could arise from repeated sampling of variants under environment feedback alone.
- [Experimental Evaluation] Experimental Evaluation section: the abstract and results report performance improvements but provide no details on the number of runs, variance across seeds, statistical tests, or the precise implementation of the evolutionary loop (population size, selection criteria, termination). This information is required to assess whether the 72.5% figure is robust.
minor comments (1)
- [Method] The decomposition into descriptor and action agents is described at a high level; adding pseudocode or a diagram of the full pipeline would improve clarity of the multi-agent structure.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the significance of environment-grounded prompt optimization. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Behavior Analyzer] Behavior Analyzer subsection: the central claim that targeted revisions explain the jump from 0% to 72.5% on PutNext rests on the analyzer accurately mapping trajectories to specific prompt components. No human validation, inter-annotator agreement, or ablation is reported to establish that the attributions are reliable rather than heuristic or noisy; without this, the observed gains could arise from repeated sampling of variants under environment feedback alone.
Authors: We acknowledge that the manuscript does not report human validation or inter-annotator agreement for the LLM-based Behavior Analyzer. Its attributions are heuristic in nature and the primary safeguard is downstream validation via environment rollouts. To directly test whether targeted attributions drive the gains, the revised manuscript will add an ablation that replaces the analyzer with random or untargeted mutations while keeping the rest of the evolutionary loop identical. This will quantify the contribution of the analyzer beyond repeated sampling under environment feedback. revision: yes
-
Referee: [Experimental Evaluation] Experimental Evaluation section: the abstract and results report performance improvements but provide no details on the number of runs, variance across seeds, statistical tests, or the precise implementation of the evolutionary loop (population size, selection criteria, termination). This information is required to assess whether the 72.5% figure is robust.
Authors: We agree these details are necessary for reproducibility and robustness assessment. The revised Experimental Evaluation section will report the number of independent runs (with different random seeds for both LLM sampling and environment stochasticity), standard deviations, any statistical tests performed, and the full evolutionary-loop hyperparameters: population size, selection mechanism (top-k by success rate), and termination criteria (fixed generations or plateau). These values are already fixed in our released code and will be explicitly documented in the paper. revision: yes
Circularity Check
No circularity: empirical loop uses external environment returns for validation
full rationale
The paper presents an empirical prompt-optimization pipeline whose performance claims rest on measured success rates in the BALROG BabyAI environments after iterative refinement. The behavior analyzer and mutator are internal heuristics, but final outcomes are scored by independent environment rollouts rather than by any fitted parameter, self-referential metric, or prior self-citation. No equations, uniqueness theorems, or ansatzes are introduced that reduce to the inputs by construction. The reported gains (0 % → 72.5 % on PutNext) are therefore falsifiable against the external benchmark and do not collapse into a renaming or re-fitting of the same data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can effectively follow structured prompts for agent behavior in environments
- domain assumption Environment returns provide reliable signal for prompt improvement
invented entities (2)
-
behavior analyzer
no independent evidence
-
mutator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[2]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[3]
Transactions on Machine Learning Research , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[4]
International conference on machine learning , pages=
Grounding large language models in interactive environments with online reinforcement learning , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2024 , publisher=
2024
-
[6]
Advances in neural information processing systems , volume=
Optimus-1: Hybrid multimodal memory empowered agents excel in long-horizon tasks , author=. Advances in neural information processing systems , volume=
-
[7]
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , booktitle=. Expel:
-
[8]
Advances in Neural Information Processing Systems , volume=
Autoguide: Automated generation and selection of context-aware guidelines for large language model agents , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Automanual: Constructing instruction manuals by
Chen, Minghao and Li, Yihang and Yang, Yanting and Yu, Shiyu and Lin, Binbin and He, Xiaofei , journal=. Automanual: Constructing instruction manuals by
-
[10]
The eleventh international conference on learning representations , year=
Large language models are human-level prompt engineers , author=. The eleventh international conference on learning representations , year=
-
[11]
gradient descent
Automatic prompt optimization with “gradient descent” and beam search , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[12]
2023 , booktitle=
Large language models as optimizers , author=. 2023 , booktitle=
2023
-
[13]
2023 , eprint=
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author=. 2023 , eprint=
2023
-
[14]
arXiv preprint arXiv:2406.11132 , year=
Reprompt: Planning by automatic prompt engineering for large language models agents , author=. arXiv preprint arXiv:2406.11132 , year=
-
[15]
Lakshya A Agrawal and Shangyin Tan and Dilara Soylu and Noah Ziems and Rishi Khare and Krista Opsahl-Ong and Arnav Singhvi and Herumb Shandilya and Michael J Ryan and Meng Jiang and Christopher Potts and Koushik Sen and Alex Dimakis and Ion Stoica and Dan Klein and Matei Zaharia and Omar Khattab , booktitle=
-
[16]
Evotool: Self-evolving tool-use policy optimization in
Yang, Shuo and Han, Soyeon Caren and Ma, Xueqi and Li, Yan and Madani, Mohammad Reza Ghasemi and Hovy, Eduard , journal=. Evotool: Self-evolving tool-use policy optimization in
-
[17]
arXiv preprint arXiv:2509.03312 , year=
AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems? , author=. arXiv preprint arXiv:2509.03312 , year=
-
[18]
BALROG: Benchmarking Agentic
Paglieri, D and Cupia. BALROG: Benchmarking Agentic. 13th International Conference on Learning Representations Iclr 2025 , pages=. 2025 , organization=
2025
-
[19]
International Conference on Learning Representations , year=
BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning , author=. International Conference on Learning Representations , year=
-
[20]
2026 , eprint=
The PokeAgent Challenge: Competitive and Long-Context Learning at Scale , author=. 2026 , eprint=
2026
-
[21]
arXiv preprint arXiv:2604.00830 , year=
Learning to Learn-at-Test-Time: Language Agents with Learnable Adaptation Policies , author=. arXiv preprint arXiv:2604.00830 , year=
-
[22]
Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) , year =
Heinrich K. Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[23]
2026 , url =
Gao, Huan-ang and Geng, Jiayi and Hua, Wenyue and Hu, Mengkang and Juan, Xinzhe and Liu, Hongzhang and Liu, Shilong and Qiu, Jiahao and Qi, Xuan and Ren, Qihan and Wu, Yiran and Wang, Hongru and Xiao, Han and Zhou, Yuhang and Zhang, Shaokun and Zhang, Jiayi and Xiang, Jinyu and Fang, Yixiong and Zhao, Qiwen and Liu, Dongrui and Qian, Cheng and Wang, Zhenh...
2026
-
[24]
Improving Deep Agents with harness engineering , author =
-
[25]
General Modular Harness for
Yuxuan Zhang and Haoyang Yu and Lanxiang Hu and Haojian Jin and Hao Zhang , booktitle=. General Modular Harness for
-
[26]
CoRR , volume =
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. CoRR , volume =. 2017 , url =
2017
-
[27]
Forty-first International Conference on Machine Learning,
Jianliang He and Siyu Chen and Fengzhuo Zhang and Zhuoran Yang , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[28]
Aske Plaat and Max J. van Duijn and Niki van Stein and Mike Preuss and Peter van der Putten and Kees Joost Batenburg , title =. J. Artif. Intell. Res. , volume =. 2025 , url =. doi:10.1613/JAIR.1.18675 , timestamp =
-
[29]
Devon Hjelm and Alexander T
Martin Klissarov and R. Devon Hjelm and Alexander T. Toshev and Bogdan Mazoure , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[30]
ArXiv , year=
Language Models can Solve Computer Tasks , author=. ArXiv , year=
-
[31]
ArXiv , year=
Reinforcing Language Agents via Policy Optimization with Action Decomposition , author=. ArXiv , year=
-
[32]
Simon Zhai and Hao Bai and Zipeng Lin and Jiayi Pan and Peter Tong and Yifei Zhou and Alane Suhr and Saining Xie and Yann LeCun and Yi Ma and Sergey Levine , title =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
2024
-
[33]
MPO: Boosting
Weimin Xiong and Yifan Song and Qingxiu Dong and Bingchan Zhao and Feifan Song and Xun Wang and Sujian Li , booktitle=. MPO: Boosting. 2025 , url=
2025
-
[34]
ArXiv , year=
Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies , author=. ArXiv , year=
-
[35]
Describe, Explain, Plan and Select: Interactive Planning with
Zihao Wang and Shaofei Cai and Guanzhou Chen and Anji Liu and Xiaojian Ma and Yitao Liang , journal=. Describe, Explain, Plan and Select: Interactive Planning with. 2023 , url=
2023
-
[36]
Foerster and Yoram Bachrach and William Yang Wang and Roberta Raileanu , title =
Deepak Nathani and Lovish Madaan and Nicholas Roberts and Nikolay Bashlykov and Ajay Menon and Vincent Moens and Amar Budhiraja and Despoina Magka and Vladislav Vorotilov and Gaurav Chaurasia and Dieuwke Hupkes and Ricardo Silveira Cabral and Tatiana Shavrina and Jakob N. Foerster and Yoram Bachrach and William Yang Wang and Roberta Raileanu , title =. Co...
-
[37]
The Fourteenth International Conference on Learning Representations , year=
MedAgentGym: A Scalable Agentic Training Environment for Code-Centric Reasoning in Biomedical Data Science , author=. The Fourteenth International Conference on Learning Representations , year=
-
[38]
ArXiv , year=
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery , author=. ArXiv , year=
-
[39]
ArXiv , year=
Training Software Engineering Agents and Verifiers with SWE-Gym , author=. ArXiv , year=
-
[40]
ArXiv , year=
Self-evolving Agents with reflective and memory-augmented abilities , author=. ArXiv , year=
-
[41]
Liu and Gao Huang , booktitle=
Andrew Zhao and Daniel Huang and Quentin Xu and Matthieu Lin and Y. Liu and Gao Huang , booktitle=. ExpeL:. 2023 , url=
2023
-
[42]
LogicGuard: Improving Embodied
Anand Gokhale and Vaibhav Srivastava and Francesco Bullo , year=. LogicGuard: Improving Embodied
-
[43]
AutoManual: Constructing Instruction Manuals by
Minghao Chen and Yihang Li and Yanting Yang and Shiyu Yu and Binbin Lin and Xiaofei He , journal=. AutoManual: Constructing Instruction Manuals by. 2024 , url=
2024
-
[44]
Deterministic POMDPs Revisited , booktitle =
Blai Bonet , editor =. Deterministic POMDPs Revisited , booktitle =. 2009 , url =
2009
-
[45]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto , title =. 2018 , url =
2018
-
[46]
Artificial Intelligence , volume =
Leslie Pack Kaelbling and Michael L. Littman and Anthony R. Cassandra , title =. Artif. Intell. , volume =. 1998 , url =. doi:10.1016/S0004-3702(98)00023-X , timestamp =
-
[47]
2012 , DOI =
Grondman, Ivo and Busoniu, Lucian and Lopes, Gabriel and Babuska, Robert , URL =. 2012 , DOI =
2012
-
[48]
2025 , journal =
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , journal =
2025
-
[49]
Evolutionary Multi-objective Optimization of Large Language Model Prompts for Balancing Sentiments
Baumann, Jill and Kramer, Oliver. Evolutionary Multi-objective Optimization of Large Language Model Prompts for Balancing Sentiments. Applications of Evolutionary Computation. 2024
2024
-
[50]
International Conference on Learning Representations , volume=
Limits to scalable evaluation at the frontier: Llm as judge won’t beat twice the data , author=. International Conference on Learning Representations , volume=
-
[51]
Nelson, Herbie Bradley, Adam Gaier, Arash Moradi, Amy K
Meyerson, Elliot and Nelson, Mark J. and Bradley, Herbie and Gaier, Adam and Moradi, Arash and Hoover, Amy K. and Lehman, Joel , title =. ACM Trans. Evol. Learn. Optim. , month = nov, articleno =. 2024 , issue_date =. doi:10.1145/3694791 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.