Multiple cyclicity and Wavelet Decomposition with Channel Correlation for Long-term Time Series Forecasting
Pith reviewed 2026-06-27 01:52 UTC · model grok-4.3
The pith
The McWC model improves long-term time series forecasting by separately modeling multiple cyclicity, inter-channel correlations, and wavelet-based frequency components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
McWC first decouples cyclical information from data using a multi-layer cyclicity construction module. Then, it extracts inter-channel correlations using multi-layer perceptron. Next, it models and fuses the multi-layer high-frequency and low-frequency information from data using a multi-level wavelet decomposition module. Finally, it aggregates the results of different components to obtain the output. Simultaneously, it decouples intra-channel autocorrelations by calculating a loss function in the frequency domain. Experiments on six real-world datasets demonstrate that McWC achieves state-of-the-art performance, exhibiting excellent computational efficiency and historical information extra
What carries the argument
The McWC architecture that separately models multiple cyclicity via multi-layer construction, inter-channel correlations via MLP, and multi-level wavelet decomposition for frequency fusion, plus a frequency-domain loss for intra-channel autocorrelations.
If this is right
- McWC achieves state-of-the-art performance on six real-world datasets for long-term forecasting.
- The model exhibits excellent computational efficiency.
- McWC demonstrates strong capabilities in extracting historical information.
- Separating cyclicity, trend, and correlation modeling improves handling of multivariate dependencies in time series.
Where Pith is reading between the lines
- The separation of components could apply to other multivariate signal tasks where channels represent related variables like sensors in different locations.
- The multi-layer cyclicity and wavelet fusion might show larger gains on datasets with complex overlapping periodicities compared to simple seasonal ones.
- The frequency domain loss could help limit error growth when extending forecasts beyond the tested horizons.
Load-bearing premise
The premise that prior models neglect inter-channel correlations in a way that materially harms long-term forecasts and that the proposed separate modules will capture these correlations without introducing new overfitting or instability.
What would settle it
Running the McWC model on the same six real-world datasets and finding that its prediction errors are not lower than the best prior methods or that its runtime is not competitive would falsify the performance claims.
Figures

read the original abstract
Cyclicity and trend are important components of time series data and many studies based on cyclicity and trend have achieved good results in long-term time series forecasting. However, we believe that current work neglects the influence of real-world inter-channel correlations in time series data which leads to suboptimal predictions. Furthermore, these models rely on complex designs to capture diverse information so that resulting in low computational efficiency. To address this challenge, we propose McWC, a long-term time series forecasting model that separately models the cyclicity, trend, and inter-channel correlations. Specifically, McWC first decouples cyclical information from data using a multi-layer cyclicity construction module. Then, it extracts inter-channel correlations using multi-layer perceptron. Next, it models and fuses the multi-layer high-frequency and low-frequency information from data using a multi-level wavelet decomposition module. Finally, it aggregates the results of different components to obtain the output. Simultaneously, we decouple intra-channel autocorrelations by calculating a loss function in the frequency domain. Experiments on six real-world datasets demonstrate that McWC achieves state-of-the-art performance, exhibiting excellent computational efficiency and historical information extraction capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes McWC, a model for long-term time series forecasting that separately handles cyclicity via a multi-layer cyclicity construction module, inter-channel correlations via MLP, and multi-scale frequency content via multi-level wavelet decomposition, followed by aggregation and a frequency-domain loss to decouple intra-channel autocorrelations. It reports state-of-the-art results on six real-world datasets along with improved computational efficiency.
Significance. If the experimental claims hold under rigorous verification, the decomposition into separate cyclicity, channel-correlation, and wavelet components could offer a more efficient alternative to complex unified architectures in long-term forecasting. The frequency-domain loss and explicit separation of inter-channel effects represent a clear methodological contribution that merits follow-up if supported by reproducible ablations and baseline comparisons.
major comments (2)
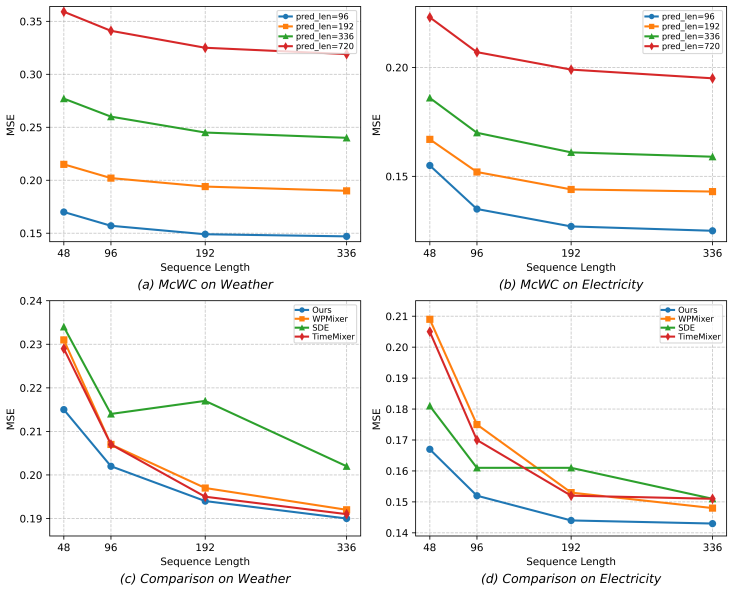
- [Experiments] Experiments section: the SOTA claim on six datasets is load-bearing for the central contribution, yet the manuscript supplies no named datasets, no table of quantitative results with error bars or statistical tests, and no ablation isolating the MLP channel-correlation module; without these the performance assertion cannot be evaluated.
- [Method] Method, multi-layer cyclicity construction and wavelet fusion: the description of how these modules are combined and trained lacks explicit equations or pseudocode showing the forward pass and loss terms; this prevents checking whether the frequency-domain loss introduces circular dependence on the training distribution itself.
minor comments (2)
- [Abstract] Abstract: the sentence 'so that resulting in low computational efficiency' is grammatically incomplete and should be revised for clarity.
- [Introduction] Introduction: the claim that prior work 'neglects the influence of real-world inter-channel correlations' would benefit from one or two concrete citations to recent models that omit channel mixing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments below and will revise the manuscript to strengthen the experimental validation and methodological presentation.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the SOTA claim on six datasets is load-bearing for the central contribution, yet the manuscript supplies no named datasets, no table of quantitative results with error bars or statistical tests, and no ablation isolating the MLP channel-correlation module; without these the performance assertion cannot be evaluated.
Authors: We agree that the current manuscript version lacks sufficient experimental detail to support the SOTA claims. In the revised version, we will explicitly name the six real-world datasets, include a results table reporting mean performance with standard deviations across multiple random seeds, add statistical significance tests against baselines, and incorporate a dedicated ablation study isolating the MLP channel-correlation module (with and without it, while keeping other components fixed). These additions will enable rigorous evaluation of the performance assertions. revision: yes
-
Referee: [Method] Method, multi-layer cyclicity construction and wavelet fusion: the description of how these modules are combined and trained lacks explicit equations or pseudocode showing the forward pass and loss terms; this prevents checking whether the frequency-domain loss introduces circular dependence on the training distribution itself.
Authors: We acknowledge the need for greater formalization. The revised manuscript will include explicit equations defining the multi-layer cyclicity construction, MLP-based inter-channel correlation extraction, multi-level wavelet decomposition and fusion, the aggregation step, and the full forward pass. We will also add pseudocode for the end-to-end training procedure. The frequency-domain loss is computed via FFT between the model's predicted output and the ground-truth targets (standard supervised regression in frequency space) and does not create circular dependence on the training distribution; it operates solely on label-prediction pairs without using training statistics beyond the supervised signal. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical model architecture (McWC) consisting of a multi-layer cyclicity module, MLP-based channel correlation extraction, multi-level wavelet decomposition for frequency fusion, and a frequency-domain loss term. No derivation chain, first-principles prediction, or uniqueness theorem is presented that reduces by construction to fitted inputs, self-citations, or renamed empirical patterns. All load-bearing elements are explicit design choices whose performance is evaluated externally via experiments on six real-world datasets. No self-citation load-bearing steps or ansatz smuggling appear in the provided text. The result is a standard engineering contribution whose validity rests on empirical outcomes rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Financial time series forecasting based on momentum-driven graph signal processing,
S. Zhang, X. Ma, Z. Fang, H. Pan, G. Yang, and G. R. Arce, “Financial time series forecasting based on momentum-driven graph signal processing,”Applied Intelligence, vol. 53, no. 18, pp. 20 950– 20 966, Sep. 2023
2023
-
[2]
Sageformer: Series-aware framework for long-term multivariate time-series forecasting,
Z. Zhang, L. Meng, and Y . Gu, “Sageformer: Series-aware framework for long-term multivariate time-series forecasting,”IEEE Internet of Things Journal, vol. 11, no. 10, pp. 18 435–18 448, 2024
2024
-
[3]
Decomposition dynamic multi-graph convolutional recurrent network for traffic forecasting,
L. Hu, L. Wei, and Y . Lin, “Decomposition dynamic multi-graph convolutional recurrent network for traffic forecasting,”Applied In- telligence, vol. 55, no. 7, p. 595, Mar. 2025
2025
-
[4]
Telling fortunes? Evaluation of traffic forecasting models using traffic and context features,
M. Hadry, A. Bauer, R. Leppich, V . Lesch, and S. Kounev, “Telling fortunes? Evaluation of traffic forecasting models using traffic and context features,”Applied Intelligence, vol. 55, no. 10, p. 755, Jun. 2025
2025
-
[5]
Forecasting short-term wind power with multi-view attention mechanism and dual recurrent neural networks,
C. Qin, J. Xie, Y . Cao, and B. Zhu, “Forecasting short-term wind power with multi-view attention mechanism and dual recurrent neural networks,”Expert Systems with Applications, vol. 297, p. 129472, 2026
2026
-
[6]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 2002
2002
-
[7]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[8]
Fed- former: Frequency enhanced decomposed transformer for long-term series forecasting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “Fed- former: Frequency enhanced decomposed transformer for long-term series forecasting,” inInternational conference on machine learning. PMLR, 2022, pp. 27 268–27 286
2022
-
[9]
Are transformers effective for time series forecasting?
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are transformers effective for time series forecasting?” inProceedings of the AAAI conference on artificial intelligence, vol. 37, 2023, pp. 11 121–11 128, issue: 9
2023
-
[10]
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecast- ing,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecast- ing,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 22 419–22 430
2021
-
[11]
MICN: Multi-scale Local and Global Context Modeling for Long-term Series Forecasting,
H. Wang, J. Peng, F. Huang, J. Wang, J. Chen, and Y . Xiao, “MICN: Multi-scale Local and Global Context Modeling for Long-term Series Forecasting,” inThe eleventh international conference on learning representations, 2023, pp. 13 014–13 035
2023
-
[12]
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis,
H. Wu, T. Hu, Y . Liu, H. Zhou, J. Wang, and M. Long, “TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis,” inThe Eleventh International Conference on Learning Representa- tions, 2023, pp. 6423–6445
2023
-
[13]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers,
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A Time Series is Worth 64 Words: Long-term Forecasting with Transformers,” inThe Eleventh International Conference on Learning Representations, 2023, pp. 33 132–33 155
2023
-
[14]
TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting,
S. Wang, H. Wu, X. Shi, T. Hu, H. Luo, L. Ma, J. Y . Zhang, and J. Zhou, “TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting,” inICLR, 2024, pp. 4166–4192
2024
-
[15]
TimeKAN: KAN-based Frequency Decomposition Learning Architecture for Long-term Time Series Forecasting,
S. Huang, Z. Zhao, C. Li, and L. Bai, “TimeKAN: KAN-based Frequency Decomposition Learning Architecture for Long-term Time Series Forecasting,” inThe Thirteenth International Conference on Learning Representations, 2025, pp. 93 540–93 555
2025
-
[16]
Frequency-domain mlps are more effective learners in time series forecasting,
K. Yi, Q. Zhang, W. Fan, S. Wang, P. Wang, H. He, N. An, D. Lian, L. Cao, and Z. Niu, “Frequency-domain mlps are more effective learners in time series forecasting,”Advances in Neural Information Processing Systems, vol. 36, pp. 76 656–76 679, 2023
2023
-
[17]
Wpmixer: Efficient multi-resolution mixing for long-term time series forecasting,
M. M. N. Murad, M. Aktukmak, and Y . Yilmaz, “Wpmixer: Efficient multi-resolution mixing for long-term time series forecasting,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 18, 2025, pp. 19 581–19 588
2025
-
[18]
CrossFormer: Cross-Modal Representation Learning via Heterogeneous Graph Transformer,
X. Liang, E. Yang, C. Deng, and Y . Yang, “CrossFormer: Cross-Modal Representation Learning via Heterogeneous Graph Transformer,”ACM Trans. Multim. Comput. Commun. Appl., vol. 20, no. 12, pp. 380:1– 380:21, Dec. 2024
2024
-
[19]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “iTransformer: Inverted Transformers Are Effective for Time Series Forecasting,” inThe Twelfth International Conference on Learning Representations, 2024, pp. 4004–4028
2024
-
[20]
Card: Channel aligned robust blend transformer for time series forecasting,
X. Wang, T. Zhou, Q. Wen, J. Gao, B. Ding, and R. Jin, “Card: Channel aligned robust blend transformer for time series forecasting,” inThe Twelfth International Conference on Learning Representations
-
[21]
Sde: A simplified and disentangled dependency encoding framework for state space models in time series forecasting,
Z. Weng, J. Han, W. Jiang, and H. Liu, “Sde: A simplified and disentangled dependency encoding framework for state space models in time series forecasting,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 3168–3179
2025
-
[22]
Fredf: Learning to forecast in frequency domain,
H. Wang, L. Pan, Z. Chen, D. Yang, S. Zhang, Y . Yang, X. Liu, H. Li, and D. Tao, “Fredf: Learning to forecast in frequency domain,” in The Thirteenth International Conference on Learning Representations, 2024, pp. 7329–7358
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.