One-Step Token-to-Waveform Generation with MeanFlow in Latent Space
Pith reviewed 2026-06-26 22:43 UTC · model grok-4.3
The pith
Modeling average velocity in latent space enables true one-step token-to-waveform generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying MeanFlow to model the average velocity rather than the instantaneous velocity field inside a highly compressed latent space, the Token2Wav decoder achieves true one-step generation from tokens to waveforms. This approach sidesteps the memory and stability problems of waveform-level flows and produces up to a 17× gain in Real-Time Factor relative to multi-step baselines while incurring negligible quality loss. Additional refinement via decoder-only fine-tuning of the frozen MeanFlow generator and end-to-end joint fine-tuning further reduces latent mismatch and raises fidelity without any added inference-time cost.
What carries the argument
MeanFlow, the mechanism that models average velocity instead of the instantaneous velocity field to permit one-step sampling when placed in compressed latent space.
If this is right
- Iterative sampling is replaced by a single forward pass in the decoder.
- Real-Time Factor improves by up to 17 times compared with conventional multi-step flow-matching baselines.
- Latent-space operation removes the memory and numerical stability barriers that appear at full waveform resolution.
- Decoder-only and joint fine-tuning raise output fidelity while leaving inference speed unchanged.
Where Pith is reading between the lines
- The speed gain could support lower-latency real-time speech interfaces in resource-constrained devices if the latent codec remains fixed.
- Similar average-velocity modeling might be tested in other token-to-signal pipelines such as image or video generation where iterative flows currently dominate latency.
Load-bearing premise
Fine-tuning steps can close any mismatch between the latent MeanFlow generator and the final waveform decoder without raising inference cost or harming quality.
What would settle it
Head-to-head evaluation on standard TTS test sets showing whether perceptual quality scores remain within negligible range of multi-step baselines once RTF reaches the claimed 17× improvement.
Figures
read the original abstract
Neural audio codecs are central to modern LLM-based Text-to-Speech (TTS) and multimodal systems. As low-bitrate semantic codecs gain prominence, the Token-to-Waveform (Token2Wav) decoder becomes a bottleneck determining both perceptual quality and system efficiency. Conventional multi-step flow-matching decoders offer superior quality but suffer from high inference latency due to iterative sampling, creating a severe quality-speed trade-off. In this paper, we propose a novel Token2Wav architecture that overcomes this limitation by applying MeanFlow in a highly compressed latent space. By modeling the average velocity rather than the instantaneous velocity field, MeanFlow enables true one-step generation. Operating in the latent domain mitigates the memory and stability issues of waveform-level flows, yielding up to a 17$\times$ improvement in Real-Time Factor (RTF) compared to multi-step baselines with negligible quality degradation. Furthermore, we introduce refinement strategies that mitigate latent mismatch, including decoder-only fine-tuning with the MeanFlow generator frozen and end-to-end joint fine-tuning, improving fidelity without increasing inference-time cost. Code and demo are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MeanFlow, which models average velocity rather than the instantaneous velocity field, applied within a compressed latent space for one-step Token-to-Waveform (Token2Wav) generation in neural audio codecs. It claims this yields up to a 17× improvement in Real-Time Factor (RTF) over multi-step flow-matching baselines with negligible quality degradation. Refinement strategies (decoder-only fine-tuning with the MeanFlow generator frozen, and end-to-end joint fine-tuning) are introduced to mitigate latent mismatch without increasing inference cost. Code and demos are stated to be publicly available.
Significance. If the empirical results hold under rigorous evaluation, the approach would meaningfully advance efficiency in LLM-based TTS and multimodal systems by resolving the quality-speed trade-off in token-to-waveform decoding. Public code release supports reproducibility and potential adoption.
major comments (1)
- [Abstract] The central empirical claims (17× RTF improvement and negligible quality degradation) are stated in the abstract without any accompanying metrics, baselines, evaluation protocols, or dataset details. This prevents verification of whether the evidence supports the claims of one-step generation superiority.
Simulated Author's Rebuttal
We thank the referee for highlighting this issue with the abstract. We address the comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] The central empirical claims (17× RTF improvement and negligible quality degradation) are stated in the abstract without any accompanying metrics, baselines, evaluation protocols, or dataset details. This prevents verification of whether the evidence supports the claims of one-step generation superiority.
Authors: We agree that the abstract would benefit from additional specificity to allow immediate assessment of the claims. In the revised version, we will expand the abstract to briefly reference the key evaluation metrics (RTF and perceptual quality scores such as PESQ/MOS), the multi-step flow-matching baselines, the datasets used for training and testing, and the evaluation protocols (including the latent-space setup and refinement strategies). These details are already provided in Sections 4 and 5 of the manuscript; the abstract revision will point readers to them without altering the core claims or length substantially. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claim is that MeanFlow (modeling average velocity) applied in a compressed latent space enables one-step Token2Wav generation with improved RTF, supported by refinement strategies for latent mismatch. No load-bearing derivation, prediction, or uniqueness result is shown to reduce by construction to fitted inputs, self-citations, or renamed empirical patterns; the abstract and described architecture present the performance gains as empirical outcomes of the proposed method rather than tautological redefinitions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
MeanFlow
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction Large language model (LLM)-based text-to-speech (TTS) sys- tems [1, 2, 3, 4] increasingly adopt a discrete-token formula- tion: an upstream model predicts a sequence of speech tokens, and a downstream neural decoder converts these tokens into a waveform. Neural audio codecs [5, 2, 6] provide a practical interface for such systems by discretiz...
Pith/arXiv arXiv 2026
-
[2]
Given semantic tokenss= {s1,
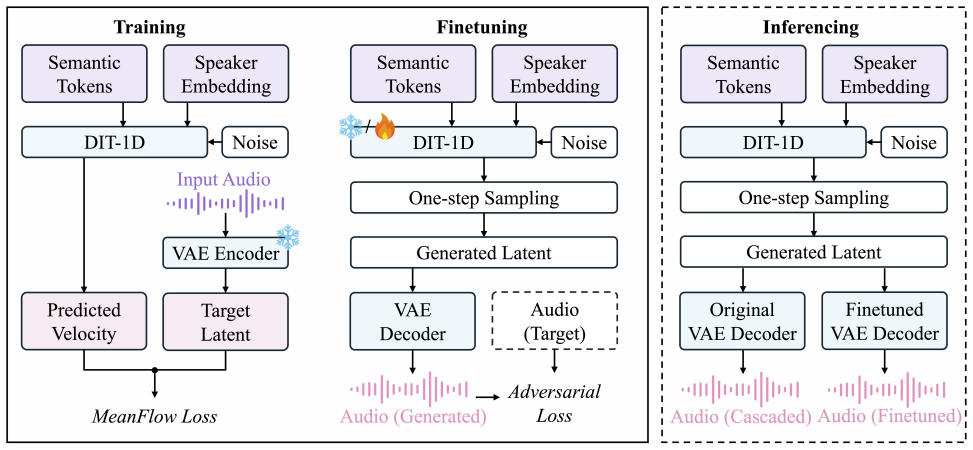
Method As shown in Figure 1, our Token2Wav decoder synthesizes waveform speech in two stages. Given semantic tokenss= {s1, . . . , sT }and a speaker embeddinge, we denote the con- ditioning asc= (s,e)and aim to generate a waveformx∈ RL. To achieve low latency, we (i) generate a compressed la- tent sequence in one step using a latent MeanFlow generator, an...
-
[3]
Experimental Setup and Metrics Datasets.We train all models on LibriTTS [17] and evaluate on thetest-cleansubset of LibriSpeech [18]
Experiment 3.1. Experimental Setup and Metrics Datasets.We train all models on LibriTTS [17] and evaluate on thetest-cleansubset of LibriSpeech [18]. Tokenization and speaker conditioning.For fair compar- ison, we use the same semantic tokenization as the CosyV oice2 baseline [1]. Semantic tokens are extracted at 25 Hz us- ing the CosyV oice2 tokenizer (s...
2048
-
[4]
Conclusion We presented a one-step Token2Wav decoder that applies MeanFlow in a highly compressed latent space to eliminate the iterative sampling overhead of flow-matching decoders. The proposed system combines a latent MeanFlow generator (DiT- 1D) that performs token-to-latent generation in a single net- work evaluation with a deterministic V AE decoder...
-
[5]
All authors are responsible and accountable for the work and content of this paper
Generative AI Use Disclosure Generative AI tools were used for manuscript editing and pol- ishing. All authors are responsible and accountable for the work and content of this paper
-
[6]
Cosyvoice 2: Scalable stream- ing speech synthesis with large language models,
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “Cosyvoice 2: Scalable stream- ing speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
Pith/arXiv arXiv 2024
-
[7]
J. Li, G. Zhang, Z. Ye, and Y . Guo, “Msr-codec: A low- bitrate multi-stream residual codec for high-fidelity speech generation with information disentanglement,”arXiv preprint arXiv:2509.13068, 2025
arXiv 2025
-
[8]
Llasa: Scaling train-time and inference-time compute for llama-based speech synthesis,
Z. Ye, X. Zhu, C.-M. Chan, X. Wang, X. Tan, J. Lei, Y . Peng, H. Liu, Y . Jin, Z. Daiet al., “Llasa: Scaling train-time and inference-time compute for llama-based speech synthesis,”arXiv preprint arXiv:2502.04128, 2025
arXiv 2025
-
[9]
H.-H. Guo, Y . Hu, K. Liu, F.-Y . Shen, X. Tang, Y .-C. Wu, F.- L. Xie, K. Xie, and K.-T. Xu, “Fireredtts: A foundation text-to- speech framework for industry-level generative speech applica- tions,”arXiv preprint arXiv:2409.03283, 2024
arXiv 2024
-
[10]
Snac: Multi- scale neural audio codec,
H. Siuzdak, F. Gr ¨otschla, and L. A. Lanzend ¨orfer, “Snac: Multi- scale neural audio codec,” inAudio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation, 2024
2024
-
[11]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2021
2021
-
[12]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Transactions on Machine Learning Research, 2023
2023
-
[13]
Hubert: Self-supervised speech rep- resentation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “Hubert: Self-supervised speech rep- resentation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[14]
Semanticodec: An ultra low bitrate semantic audio codec for general sound,
H. Liu, X. Xu, Y . Yuan, M. Wu, W. Wang, and M. D. Plumb- ley, “Semanticodec: An ultra low bitrate semantic audio codec for general sound,”IEEE Journal of Selected Topics in Signal Pro- cessing, 2024
2024
-
[15]
High-fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,” inAd- vances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[16]
V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis,
H. Siuzdak, “V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis,” in12th International Conference on Learning Representations, ICLR 2024, 2024
2024
-
[17]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” in11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[18]
Mean flows for one-step generative modeling,
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He, “Mean flows for one-step generative modeling,”arXiv preprint arXiv:2505.13447, 2025
Pith/arXiv arXiv 2025
-
[19]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 684–10 695
2022
-
[20]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,” in11th Inter- national Conference on Learning Representations, ICLR 2023, 2023
2023
-
[21]
Scalable diffusion models with transform- ers,
W. Peebles and S. Xie, “Scalable diffusion models with transform- ers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4195–4205
2023
-
[22]
Libritts: A corpus derived from librispeech for text- to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text- to-speech,” inProc. Interspeech 2019, 2019, pp. 1526–1530
2019
-
[23]
Lib- rispeech: An asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An asr corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5206–5210
2015
-
[24]
Cam++: A fast and efficient network for speaker verification using context- aware masking,
H. Wang, S. Zheng, Y . Chen, L. Cheng, and Q. Chen, “Cam++: A fast and efficient network for speaker verification using context- aware masking,” inInterspeech 2023, 2023, pp. 5301–5305
2023
-
[25]
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Stable audio open,”arXiv preprint arXiv:2407.14358, 2024
arXiv 2024
-
[26]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[27]
Utmos: Utokyo-sarulab system for voicemos challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,”Interspeech 2022, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.