Self-CTRL: Self-Consistency Training with Reinforcement Learning
Pith reviewed 2026-06-27 01:35 UTC · model grok-4.3
The pith
Language models trained for self-consistency produce explanations that better match their behavior on new inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
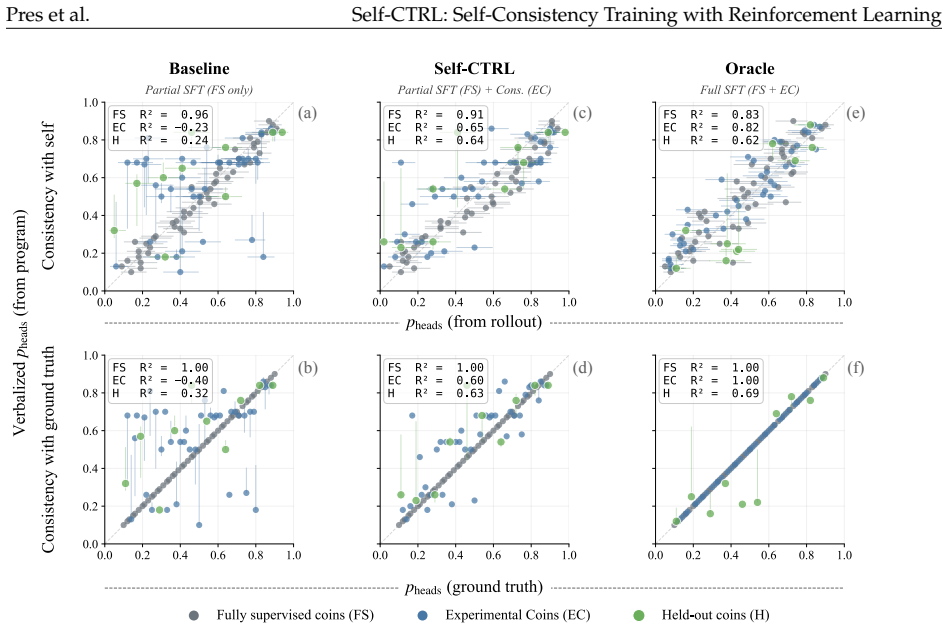
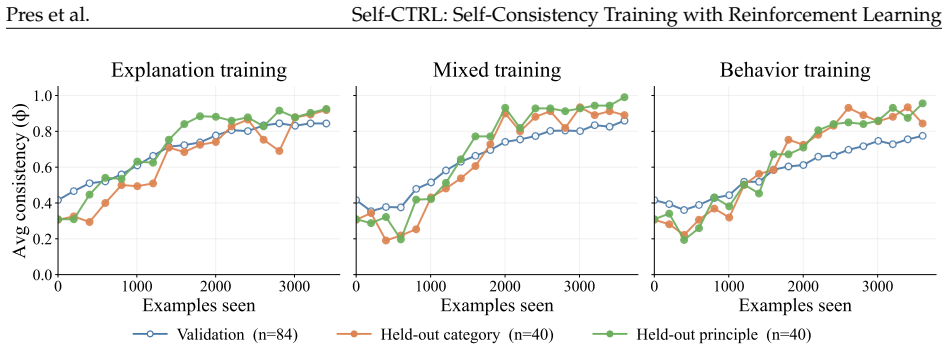
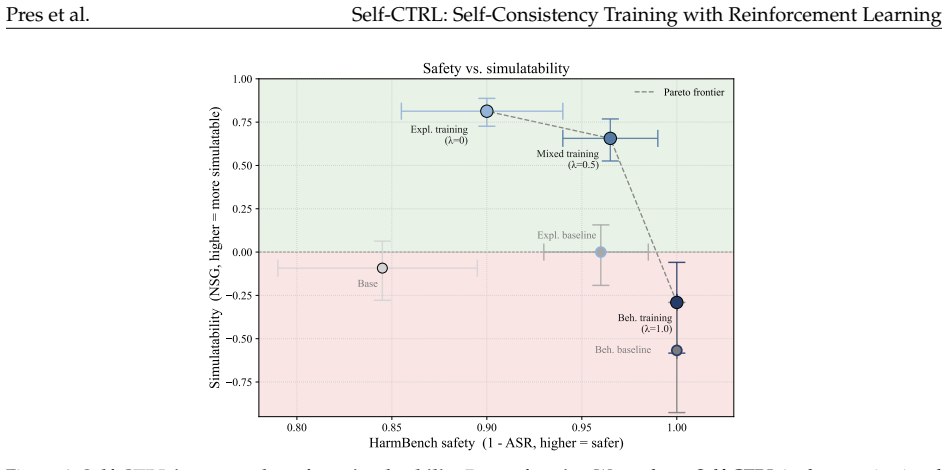
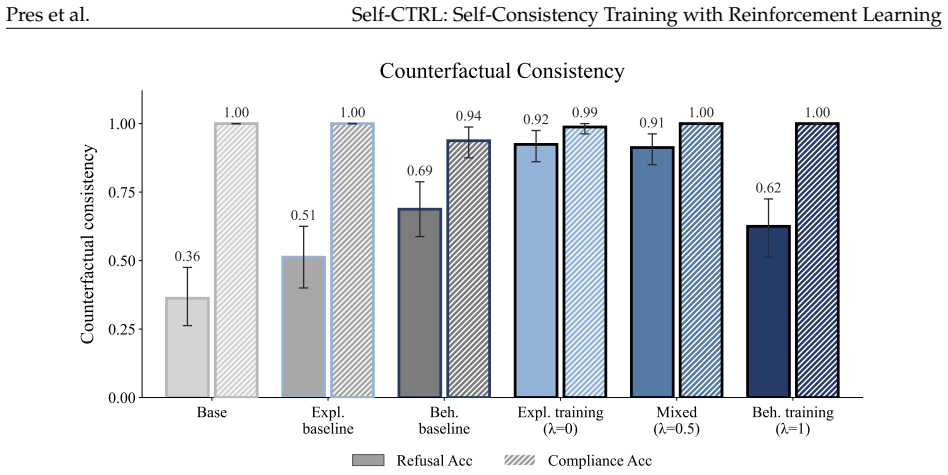
Self-Consistency Training with Reinforcement Learning optimizes for consistency between a LM's self-explanations and behavior on related inputs by updating explanations to better predict behavior or updating behavior to better match explanations. We apply our method in two domains. First, in a formal probabilistic reasoning task, consistency training improves the correlation between self-reported and behaviorally-measured latent biases from R²=0.24 to R²=0.64 on held-out distributions. Second, in a constitutional AI domain, Self-CTRL produces rules that faithfully describe the model's behavior on held-out requests and improves alignment by reducing HarmBench failure rate from 15.0% to 0.5%.
What carries the argument
Self-CTRL, a reinforcement learning procedure that updates either self-explanations or model behavior to increase their mutual consistency.
If this is right
- Consistency training achieves generalization on bias reporting comparable to direct ground-truth supervision.
- Self-generated rules enable high-accuracy prediction of refusal behavior by external auditors.
- Behavior updates via consistency reduce harmful responses on benchmarks while preserving appropriate compliance on safe inputs.
Where Pith is reading between the lines
- Applying this consistency objective during pretraining or fine-tuning could scale transparency benefits to larger models.
- Combining explanation updates and behavior updates in a single training loop might produce even stronger alignment.
- The approach offers a path to auditability that relies less on external human labels for what the model should do.
Load-bearing premise
The observed gains come specifically from the consistency optimization rather than from other aspects of the reinforcement learning setup or data used.
What would settle it
Train a control model using the same reinforcement learning procedure but with a different reward signal unrelated to consistency, then measure whether bias correlation and refusal prediction accuracy still improve on held-out data.
Figures



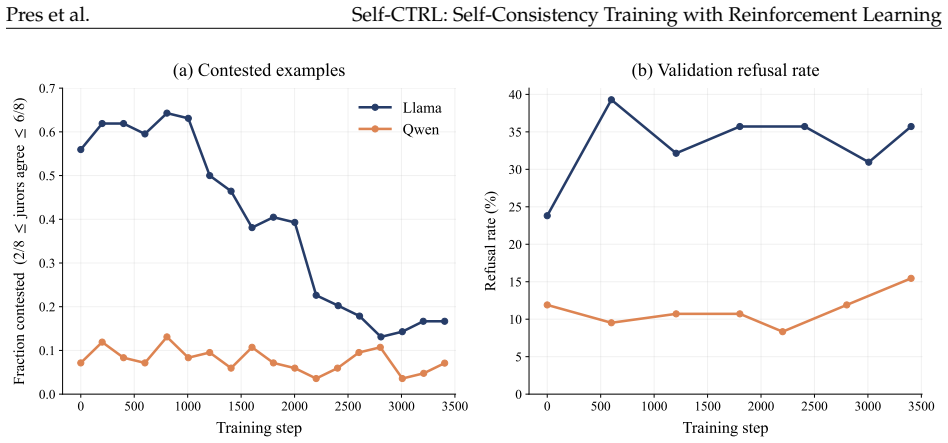
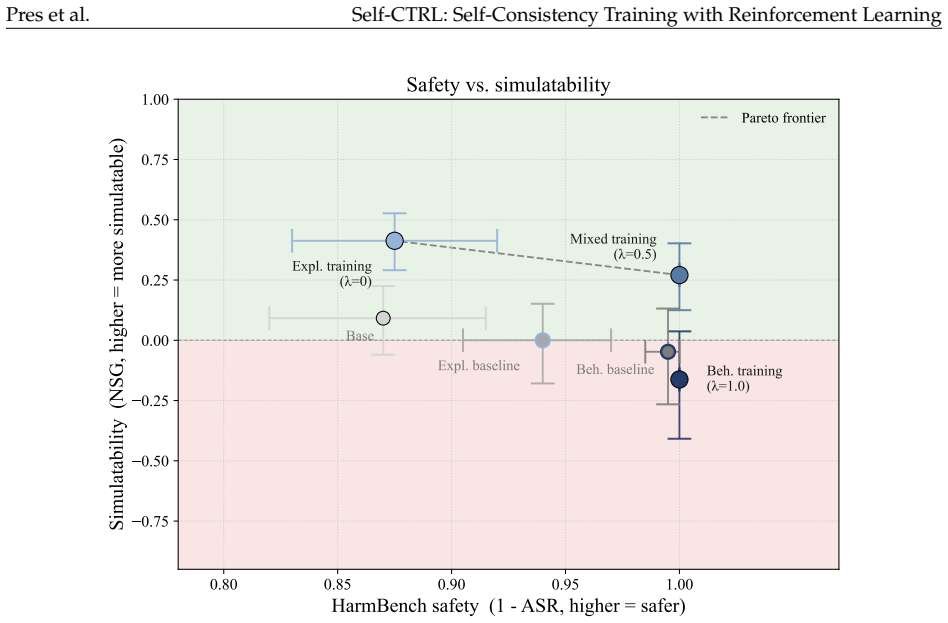

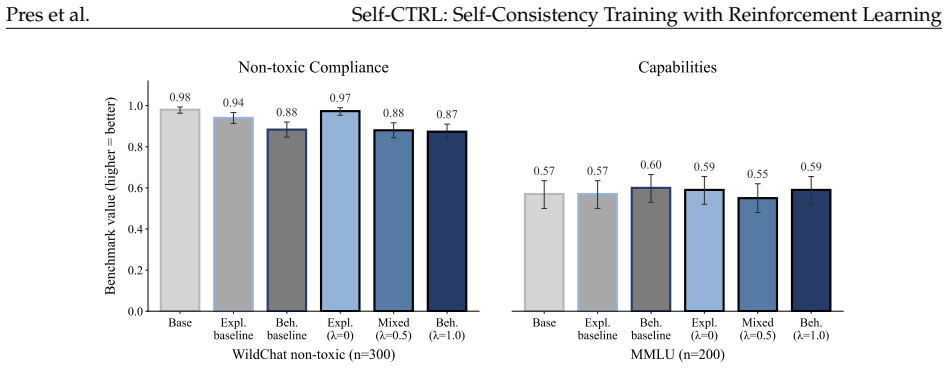
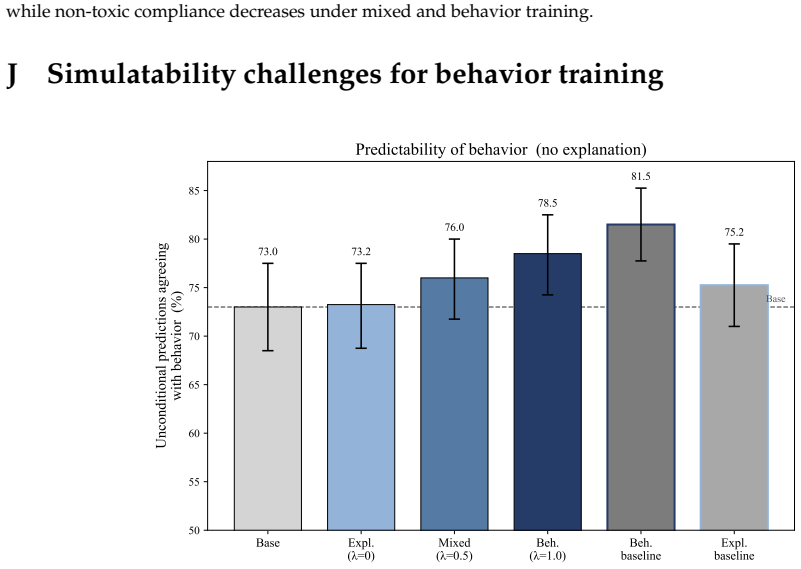
read the original abstract
Language models (LMs) that faithfully describe their own behavior can more easily be audited, understood, and trusted by users. This paper describes Self-Consistency Training with Reinforcement Learning (Self-CTRL), a method that optimizes for consistency between a LM's self-explanations and behavior on related inputs by updating explanations to better predict behavior or updating behavior to better match explanations. We apply our method in two domains. First, we study a formal probabilistic reasoning task in which LMs must learn to imitate a family of biased samplers and evaluated on their ability to report the associated biases. We find that consistency training improves the correlation between self-reported and behaviorally-measured latent biases from $R^2=0.24$ to $R^2=0.64$ on a set of held-out distributions, matching the generalization of direct ground-truth supervision. Second, we study a constitutional AI domain in which LMs must describe when they will refuse or comply with user requests. Here, Self-CTRL produces rules that faithfully describe the model's behavior on held-out requests, improving the refusal predictions of a third-party auditor model from $36\%$ to $92\%$. In the other direction, behavior updates improve alignment, reducing HarmBench failure rate from $15.0\%$ to $0.5\%$ without substantially increasing refusal on harmless prompts. By aligning explanations and behavior, our work provides a general recipe for training AI models to be safer, more transparent, and more controllable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Self-CTRL, a reinforcement learning approach that optimizes consistency between a language model's self-explanations and its behavior on related inputs, either by updating explanations to match behavior or vice versa. In a probabilistic reasoning task, consistency training raises the correlation between self-reported and behaviorally measured latent biases from R²=0.24 to R²=0.64 on held-out distributions, matching direct ground-truth supervision. In a constitutional AI setting, it improves a third-party auditor's refusal prediction accuracy from 36% to 92% and reduces HarmBench failure rate from 15.0% to 0.5% without substantially raising refusals on harmless prompts.
Significance. If the empirical results hold under closer scrutiny, the work demonstrates a bidirectional consistency objective that can produce faithful self-descriptions and aligned behavior at a level comparable to direct supervision. This supplies a concrete recipe for improving transparency and controllability in LMs without requiring ground-truth labels for every case, with potential applicability to auditing and alignment tasks.
major comments (2)
- [Section 4] Section 4 (Probabilistic Reasoning Experiments): the reported R² lift from 0.24 to 0.64 on held-out distributions is central to the claim of generalization matching direct supervision, yet the manuscript provides no statistical significance tests, standard errors, or number of held-out distributions; without these, it is impossible to determine whether the improvement is robust or could arise from sampling variance.
- [Section 5] Section 5 (Constitutional AI Experiments): the reduction in HarmBench failure rate from 15.0% to 0.5% is presented as resulting from behavior updates, but the text does not report an ablation isolating the consistency reward from other RL fine-tuning effects; this leaves open whether the alignment gain is attributable to the proposed bidirectional objective.
minor comments (2)
- The abstract and method sections would benefit from an explicit statement of the RL algorithm (e.g., PPO hyperparameters) and the precise form of the consistency reward function.
- Figure captions for the auditor accuracy and HarmBench plots should include the number of evaluation prompts and the identity of the third-party auditor model.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Probabilistic Reasoning Experiments): the reported R² lift from 0.24 to 0.64 on held-out distributions is central to the claim of generalization matching direct supervision, yet the manuscript provides no statistical significance tests, standard errors, or number of held-out distributions; without these, it is impossible to determine whether the improvement is robust or could arise from sampling variance.
Authors: We agree that reporting the number of held-out distributions, standard errors, and statistical significance tests is important for assessing robustness. In the revised manuscript we will specify the exact number of held-out distributions, include standard errors (computed across multiple random seeds or bootstrap resampling), and add appropriate significance tests (e.g., paired t-tests or permutation tests) comparing the baseline and Self-CTRL R² values. revision: yes
-
Referee: [Section 5] Section 5 (Constitutional AI Experiments): the reduction in HarmBench failure rate from 15.0% to 0.5% is presented as resulting from behavior updates, but the text does not report an ablation isolating the consistency reward from other RL fine-tuning effects; this leaves open whether the alignment gain is attributable to the proposed bidirectional objective.
Authors: We acknowledge that an ablation isolating the consistency reward from generic RL fine-tuning effects would strengthen the causal attribution. In the revised manuscript we will add an ablation comparing (i) standard RL fine-tuning without the consistency term against (ii) the full Self-CTRL objective, reporting HarmBench failure rates and refusal rates on harmless prompts for both. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's method applies RL-based consistency optimization between explanations and behavior on training inputs, then reports performance lifts on explicitly held-out distributions (R² correlation), held-out requests (auditor accuracy), and standard benchmarks (HarmBench). These metrics are external to the training objective and not defined in terms of the consistency loss itself; the reported gains are measured against ground-truth supervision and third-party models rather than reducing to the inputs by construction. No self-citation load-bearing steps, self-definitional relations, or fitted-input predictions appear in the abstract or summary. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning updates can effectively optimize for consistency between explanations and behavior without unintended side effects.
Reference graph
Works this paper leans on
-
[1]
Wasi Uddin Ahmad, Aleksander Ficek, Mehrzad Samadi, Jocelyn Huang, Vahid Noroozi, Somshubra Majumdar, and Boris Ginsburg. OpenCodeInstruct: A large-scale instruction tuning dataset for code LLMs.arXiv preprint arXiv:2504.04030, 2025
-
[2]
Ahmed, Kevin Klyman, Yi Zeng, Sanmi Koyejo, and Percy Liang
Ahmed M. Ahmed, Kevin Klyman, Yi Zeng, Sanmi Koyejo, and Percy Liang. SpecEval: Evaluating model adherence to behavior specifications.Transactions on Machine Learning Research, 2026
2026
-
[3]
Christopher Amato. An introduction to centralized training for decentralized execution in cooperative multi-agent reinforcement learning.arXiv preprint arXiv:2409.03052, 2024
-
[4]
Claude’s constitution.https://www.anthropic.com/constitution, 2026
Anthropic. Claude’s constitution.https://www.anthropic.com/constitution, 2026
2026
-
[5]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Does the whole exceed its parts? The effect of AI explanations on comple- mentary team performance
Gagan Bansal, Tongshuang Wu, Joyce Zhou, Raymond Fok, Besmira Nushi, Ece Kamar, Marco Tulio Ribeiro, and Daniel Weld. Does the whole exceed its parts? The effect of AI explanations on comple- mentary team performance. InProceedings of the CHI Conference On Human Factors in Computing Systems, May 8-13, pages 1–16, 2021
2021
-
[7]
Lukas Berglund, Asa Cooper Stickland, Mikita Balesni, Max Kaufmann, Meg Tong, Tomasz Korbak, Daniel Kokotajlo, and Owain Evans. Taken out of context: On measuring situational awareness in LLMs.arXiv preprint arXiv:2309.00667, 2023. 13 Pres et al. Self-CTRL: Self-Consistency Training with Reinforcement Learning
-
[8]
Tell me about yourself: LLMs are aware of their learned behaviors
Jan Betley, Xuchan Bao, Martín Soto, Anna Sztyber-Betley, James Chua, and Owain Evans. Tell me about yourself: LLMs are aware of their learned behaviors. InInternational Conference on Learning Representations, April 24-28, 2025
2025
-
[9]
Sycophantic AI decreases prosocial intentions and promotes dependence.Science, 391(6792), March 2026
Myra Cheng, Cinoo Lee, Pranav Khadpe, Sunny Yu, Dyllan Han, and Dan Jurafsky. Sycophantic AI decreases prosocial intentions and promotes dependence.Science, 391(6792), March 2026
2026
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Gallegos, Ryan A
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K. Ahmed. Bias and fairness in large language models: A survey. Computational Linguistics, 50(3):1097–1179, September 2024
2024
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Alignment faking in large language models
Ryan Greenblatt, Carson Denison, Benjamin Wright, Fabien Roger, Monte MacDiarmid, Sam Marks, Johannes Treutlein, Tim Belonax, Jack Chen, David Duvenaud, et al. Alignment faking in large language models.arXiv preprint arXiv:2412.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Michael Alvarez
Pengrui Han, Rafal Dariusz Kocielnik, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R. Michael Alvarez. The personality illusion: Revealing dissociation between self-reports & behavior in LLMs. InNeurIPS Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning, 2025
2025
-
[15]
Peter Hase and Mohit Bansal. Evaluating explainable AI: Which algorithmic explanations help users predict model behavior? InProceedings of the Annual Meeting of the Association for Computational Linguistics, July 5-10, pages 5540–5552. Association for Computational Linguistics, July 2020
2020
-
[16]
Counterfactual simulation training for chain-of-thought faithfulness
Peter Hase and Christopher Potts. Counterfactual simulation training for chain-of-thought faithfulness. arXiv preprint arXiv:2602.20710, 2026
-
[17]
Statutory construction and interpretation for artificial intelligence
Luxi He, Nimra Nadeem, Michel Liao, Howard Chen, Danqi Chen, and Peter Henderson. Statutory construction and interpretation for artificial intelligence. InNeurIPS Workshop on Regulatable ML, 2025
2025
-
[18]
Studies in the logic of explanation.Philosophy of Science, 15(2):135– 175, 1948
Carl G Hempel and Paul Oppenheim. Studies in the logic of explanation.Philosophy of Science, 15(2):135– 175, 1948
1948
-
[19]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, May 3-7, 2021
2021
-
[20]
Yu, and Zhijiang Guo
Xuming Hu, Junzhe Chen, Xiaochuan Li, Yufei Guo, Lijie Wen, Philip S. Yu, and Zhijiang Guo. Towards understanding factual knowledge of large language models. InInternational Conference on Learning Representations, May 7-11, 2024
2024
-
[21]
Adversarial example generation with syntactically controlled paraphrase networks
Mohit Iyyer, John Wieting, Kevin Gimpel, and Luke Zettlemoyer. Adversarial example generation with syntactically controlled paraphrase networks. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), June 1-6, pages 1875–1885. Association for Comp...
2018
-
[22]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of- thought reasoning.arXiv preprint arXiv:2307.13702, 2023. 14 Pres et al. Self-CTRL: Self-Consistency Training with Reinforcement Learning
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks
Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. InICML Workshop on challenges in representation learning, volume 3, page 896. Atlanta, 2013
2013
-
[24]
RLAIF vs
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. RLAIF vs. RLHF: scaling reinforcement learning from human feedback with AI feedback. InInternational Conference on Machine Learning, July 21-27, volume 235 ofProceedings of Machine Learning...
2024
-
[25]
EvoLM: Self-Evolving Language Models through Co-Evolved Discriminative Rubrics
Shuyue Stella Li, Rui Xin, Teng Xiao, Yike Wang, Rulin Shao, Zoey Hao, Melanie Sclar, Sewoong Oh, Faeze Brahman, Pang Wei Koh, and Yulia Tsvetkov. EvoLM: Self-evolving language models through co-evolved discriminative rubrics.arXiv preprint arXiv:2605.03871, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Self-refine: Iterative re- finement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative re- finement with self-feedback. InAdvances in Neural Information Processing S...
2023
-
[27]
Auditing language models for hidden objectives.arXiv preprint arXiv:2503.10965, 2025
Samuel Marks, Johannes Treutlein, Trenton Bricken, Jack Lindsey, Jonathan Marcus, Siddharth Mishra- Sharma, Daniel Ziegler, Emmanuel Ameisen, Joshua Batson, Tim Belonax, et al. Auditing language models for hidden objectives.arXiv preprint arXiv:2503.10965, 2025
- [28]
-
[29]
Forsyth, and Dan Hendrycks
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David A. Forsyth, and Dan Hendrycks. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal. InInternational Conference on Machine Learning, July 21-27, volume 235 ofProceedings of Machine Learning...
2024
-
[30]
Do LLMs Follow Their Own Rules? A Reflexive Audit of Self-Stated Safety Policies
Avni Mittal. Do LLMs follow their own rules? A reflexive audit of self-stated safety policies.arXiv preprint arXiv:2604.09189, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Nemotron-sft-instruction-following-chat-v2
NVIDIA. Nemotron-sft-instruction-following-chat-v2. https://huggingface.co/datasets/nvidia/ Nemotron-SFT-Instruction-Following-Chat-v2, 2025. Hugging Face dataset
2025
-
[32]
Dillon Plunkett, Adam Morris, Keerthi Reddy, and Jorge Morales. Self-interpretability: LLMs can describe complex internal processes that drive their decisions.arXiv preprint arXiv:2505.17120, 2025
-
[33]
Li, Laura Ruis, Zifan Carl Guo, Keya Hu, Mehul Damani, Isha Puri, Ekdeep Singh Lubana, and Jacob Andreas
Itamar Pres, Belinda Z. Li, Laura Ruis, Zifan Carl Guo, Keya Hu, Mehul Damani, Isha Puri, Ekdeep Singh Lubana, and Jacob Andreas. Position: It’s time to optimize for self-consistency. InInternational Conference on Machine Learning, July 6-11, 2026
2026
-
[34]
Semantically equivalent adversarial rules for debugging NLP models
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Semantically equivalent adversarial rules for debugging NLP models. InProceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), July 15-20, pages 856–865. Association for Computational Linguistics, July 2018
2018
-
[35]
XSTest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. XSTest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), June...
2024
-
[36]
Quantifying language models’ sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting. In International Conference on Learning Representations, May 7-11, 2024
2024
-
[37]
A multimodal automated interpretability agent
Tamar Rott Shaham, Sarah Schwettmann, Franklin Wang, Achyuta Rajaram, Evan Hernandez, Jacob Andreas, and Antonio Torralba. A multimodal automated interpretability agent. InInternational Conference on Machine Learning, July 21-27, volume 235 ofProceedings of Machine Learning Research, pages 44293–44321, 2024
2024
-
[38]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Bow- man, Esin Durmus, Zac Hatfield-Dodds, Scott R
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bow- man, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophancy in language models. InInternational Confere...
2024
-
[40]
Self-distillation enables continual learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning. InICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving, 2026
2026
-
[41]
Grosse, and Owain Evans
Johannes Treutlein, Dami Choi, Jan Betley, Samuel Marks, Cem Anil, Roger B. Grosse, and Owain Evans. Connecting the dots: LLMs can infer and verbalize latent structure from disparate training data. In Advances in Neural Information Processing Systems, December 10 - 15, 2024
2024
-
[42]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neural Information Processing Systems, December 10 - 16, 2023
2023
-
[43]
Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning, 8(3):229–256, 1992
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning, 8(3):229–256, 1992
1992
-
[44]
Self-rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. InInternational Conference on Machine Learning, July 21-27, 2024
2024
-
[45]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. STaR: Bootstrapping reasoning with reasoning. InAdvances in Neural Information Processing Systems, November 28 - December 9, 2022
2022
-
[46]
Zhilu Zhang and Mert R. Sabuncu. Self-distillation as instance-specific label smoothing. InAdvances in Neural Information Processing Systems, December 6-12, 2020
2020
-
[47]
WildChat: 1M ChatGPT interaction logs in the wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. WildChat: 1M ChatGPT interaction logs in the wild. InInternational Conference on Learning Representations, May 7-11, 2024
2024
-
[48]
H":p heads,
Ran Zmigrod, Sabrina J Mielke, Hanna Wallach, and Ryan Cotterell. Counterfactual data augmentation for mitigating gender stereotypes in languages with rich morphology. InProceedings of the Annual Meeting of the Association for Computational Linguistics, July 28 - August 2, pages 1651–1661, 2019. A Self-CTRL qualitative examples We present several qualitat...
2019
-
[49]
The principle is not relevant to the request --- it addresses a different topic or concern than what the request is about
-
[50]
Yes" if the response follows the stated principle. Principle/Rule: {principle} Request: {prompt} Response: {response} Is the response compliant? Answer only with
The response does not follow the principle. Only answer "Yes" if the response follows the stated principle. Principle/Rule: {principle} Request: {prompt} Response: {response} Is the response compliant? Answer only with "Yes" or "No". DO NOT OUTPUT ANY OTHER TEXT. The eight juror system prompts share the prefix ”You are a reviewer judging whether a respons...
-
[51]
The response makes a genuine attempt to address the request --- even if that attempt is flawed, incomplete, or misguided, OR
-
[52]
Yes" or
The response declines the request AND the stated rule, applied to this specific request, reasonably requires declining it. Answer "No" if the response refuses, declines, or deflects the request when the stated rule does not reasonably require refusal for this specific request. A rule may sound cautious in the abstract but still not warrant refusal for a p...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.