Finding Compiler-Platform Interaction Bugs in Deep Learning Pipelines via Cross-Layer Constraints
Pith reviewed 2026-06-26 23:27 UTC · model grok-4.3
The pith
Extracting full-stack constraints across compilation passes and hardware platforms reveals 2,034 interaction bugs in deep learning compilers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
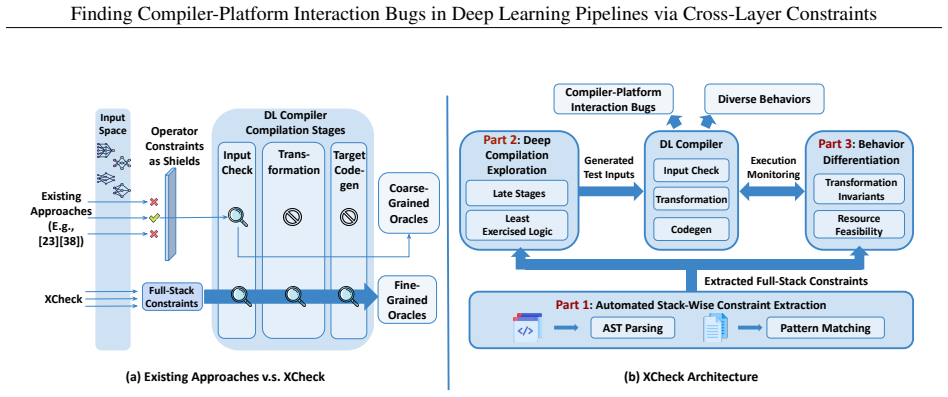
The central claim is that compiler-platform interaction bugs are caused by violated assumptions arising from interactions across compilation passes and hardware platforms, and that automatically extracting full-stack constraints to guide model generation, prioritize interaction-sensitive behaviors, and enable behavior equivalence partitioning via assertions will expose these bugs at scale.
What carries the argument
full-stack constraints extracted to jointly guide model generation and characterize compilation behaviors, with prioritization of those exposing interaction-sensitive behaviors and automatic insertion of assertions for monitoring
If this is right
- DL compilers contain thousands of previously undetected bugs rooted in cross-pass and cross-platform interactions.
- Behavior equivalence partitioning through assertions can detect symptoms that coverage metrics and pass/fail signals miss.
- Prioritizing constraints that exercise deep compilation logic increases the ability to trigger interaction bugs during testing.
Where Pith is reading between the lines
- The same constraint-extraction idea might help test other layered transformation systems where assumptions cross module boundaries.
- If the extracted constraints prove stable across compiler versions, they could serve as a basis for regression testing suites focused on platform interactions.
Load-bearing premise
Bugs arise from violated assumptions in interactions across compilation passes and hardware platforms rather than from type mismatches alone.
What would settle it
Generating models with only type constraints and observing the same rate of memory overflows, integer overflows, and silent unexpected compilations as when full-stack constraints are used.
Figures



read the original abstract
The growing deployment of artificial intelligence (AI) necessitates robust deep learning (DL) compilers, such as TVM and ONNX-MLIR. These compilers take as input high-level AI models, lower them through multi-layer transformations, and specialize them to diverse hardware. Testing such compilers is uniquely challenging as correctness depends on implicit constraints embedded throughout the compilation stack. Existing testing approaches largely take type constraints to restrict input model generation and therefore emphasize type validation and monitor compilation crashes or coverage gains. This focus overlooks compiler-platform interaction bugs that arise from interleaved effects across compilation and execution environments. In this work, we propose a scalable, automated DL compiler testing framework for, in tandem, (1) finding compiler-platform interaction bugs and (2) enabling behavior equivalence partitioning. Our key insight is that these bugs are caused by violated assumptions arising from interactions across compilation passes and hardware platforms. Therefore, we move beyond constraining input generation and derive full-stack constraints. Our approach is three-fold. First, we design an automated approach to extract full-stack constraints that jointly guide model generation and characterize compilation behaviors. Second, we prioritize constraints that expose interaction-sensitive behaviors, so our generated models are capable of exercising deep compilation logic. Third, we enable behavior equivalence partitioning by automatically inserting assertions to monitor distinct compilation symptoms that coverage or pass/fail signals miss. We evaluated our tool, XCheck, on three widely-used DL compilers and found 2,034 bug-revealing cases, including memory overflows, integer overflows, and silent unexpected compilations that were rooted in compiler-platform interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XCheck, a testing framework for deep learning compilers (e.g., TVM, ONNX-MLIR) that extracts full-stack constraints across compilation passes and hardware platforms. These constraints guide model generation, prioritize interaction-sensitive behaviors, and insert assertions for behavior equivalence partitioning. The central empirical claim is that this approach revealed 2,034 bug-revealing cases (memory overflows, integer overflows, silent unexpected compilations) rooted in compiler-platform interactions on three widely-used compilers.
Significance. If the reported cases are confirmed as true positives with rigorous verification, the work would offer a practical advance over type-constraint-focused testing by targeting cross-layer interaction bugs that current methods miss. The emphasis on full-stack constraints and equivalence partitioning could improve coverage of deep compilation logic in DL pipelines, with potential for broader adoption in compiler testing.
major comments (2)
- [Abstract/Evaluation] Abstract and Evaluation: The central claim of 2,034 bug-revealing cases provides no details on the bug verification process, false-positive filtering criteria, or independent validation of the extracted constraints. This leaves the soundness of the reported bugs (and thus the effectiveness of the prioritization step) weakly supported by the presented evidence.
- [Approach] Approach description: The three-fold method (constraint extraction, prioritization, assertion insertion) is outlined at a high level, but without concrete examples of how a full-stack constraint is derived from a specific compilation pass and platform interaction or how prioritization scores are computed, it is difficult to assess whether the generated tests actually exercise the claimed deep logic.
minor comments (1)
- [Abstract] The abstract uses 'silent unexpected compilations' without defining the observable symptom or how it differs from a normal successful compilation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the major points below and will revise the manuscript to improve clarity and evidence presentation.
read point-by-point responses
-
Referee: [Abstract/Evaluation] Abstract and Evaluation: The central claim of 2,034 bug-revealing cases provides no details on the bug verification process, false-positive filtering criteria, or independent validation of the extracted constraints. This leaves the soundness of the reported bugs (and thus the effectiveness of the prioritization step) weakly supported by the presented evidence.
Authors: We agree this is a valid concern and that the abstract and high-level evaluation summary would benefit from more explicit details. The full manuscript describes the verification process (manual inspection of symptoms, cross-checks against known compiler issues, and filtering of non-interaction bugs) in the evaluation section, but we will revise to expand the abstract with a brief mention of verification steps and add a dedicated paragraph detailing false-positive criteria (e.g., symptom-based manual review with inter-rater agreement) and any independent validation performed. This will better substantiate the reported cases. revision: yes
-
Referee: [Approach] Approach description: The three-fold method (constraint extraction, prioritization, assertion insertion) is outlined at a high level, but without concrete examples of how a full-stack constraint is derived from a specific compilation pass and platform interaction or how prioritization scores are computed, it is difficult to assess whether the generated tests actually exercise the claimed deep logic.
Authors: We acknowledge that concrete examples would aid assessment of the approach. We will revise Section 3 to include a running example deriving a full-stack constraint from a specific pass (e.g., in TVM or ONNX-MLIR) and its platform interaction, plus the exact computation of prioritization scores based on interaction sensitivity. This will demonstrate how tests target deep logic without altering the core method. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical testing framework (XCheck) that extracts cross-layer constraints from DL compilers, prioritizes them for test generation, inserts assertions, and evaluates the resulting cases on external compilers (TVM, ONNX-MLIR, etc.). No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The central results (2,034 bug cases) are obtained by executing generated tests on third-party systems and are therefore independently falsifiable. No self-citations or ansatzes are invoked as load-bearing premises. The methodology is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Full-stack constraints can be automatically extracted to jointly guide model generation and characterize compilation behaviors
Reference graph
Works this paper leans on
-
[1]
[ten(2026)]
Glow.https://github.com/pytorch/glow. [ten(2026)]
2026
-
[2]
[onn(2026a)] 2026a
NVIDIA TensorRT.https://developer.nvidia.com/tensorrt. [onn(2026a)] 2026a. ONNX Abs Operator Documentation. https://onnx.ai/onnx/operators/onnx__Abs. html#l-onnx-doc-abs. [onn(2026b)] 2026b. ONNX Documentation.https://onnx.ai/onnx/operators/index.html. [onn(2026c)] 2026c. ONNX: Open Neural Network Exchange.https://onnx.ai/. [tre(2026)]
2026
-
[3]
Tree-sitter.https://tree-sitter.github.io/tree-sitter/. [Abadi et al.(2016)] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warde...
2016
-
[4]
InProceedings of the 12th USENIX Conference on Operating Systems Design and Implementation(Savannah, GA, USA)(OSDI’16)
TensorFlow: a system for large-scale machine learning. InProceedings of the 12th USENIX Conference on Operating Systems Design and Implementation(Savannah, GA, USA)(OSDI’16). USENIX Association, USA, 265–283. [Chen et al.(2018)] Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Cez...
2018
-
[5]
InProceedings of the 13th USENIX Conference on Operating Systems Design and Implementation(Carlsbad, CA, USA)(OSDI’18)
TVM: an automated end-to-end optimizing compiler for deep learning. InProceedings of the 13th USENIX Conference on Operating Systems Design and Implementation(Carlsbad, CA, USA)(OSDI’18). USENIX Association, USA, 579–594. [Chen et al.(2016)] Yu-Hsin Chen, Joel Emer, and Vivienne Sze
2016
-
[6]
Eyeriss: a spatial architecture for energy- efficient dataflow for convolutional neural networks. InProceedings of the 43rd International Symposium on Computer Architecture(Seoul, Republic of Korea)(ISCA ’16). IEEE Press, 367–379. doi: 10.1109/ISCA.2016. 40 [Danial(2021)] Albert Danial. 2021.cloc: v1.92. doi:10.5281/zenodo.5760077 [Das et al.(2020)] Sapta...
-
[7]
In2020 IEEE International Symposium on Circuits and Systems (ISCAS)
A Systolic Dataflow Based Accelerator for CNNs. In2020 IEEE International Symposium on Circuits and Systems (ISCAS). 1–5. doi:10.1109/ISCAS45731.2020.9180403 [Deng et al.(2023)] Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang
-
[8]
Large Language Models Are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis(Seattle, W A, USA)(ISSTA 2023). Association for Computing Machinery, New York, NY , USA, 423–435. doi:10.1145/ 3597926.3598067 [Deng et al.(2024)] Yinlin Deng...
arXiv 2023
-
[9]
Large Language Models are Edge-Case Generators: Crafting Unusual Programs for Fuzzing Deep Learning Libraries. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY , USA, Article 70, 13 pages. doi:10.1145/3597503.3623343 [Deng et al.(2022)] Yinlin...
-
[10]
Fuzzing deep-learning libraries via automated relational API inference. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Singapore, Singapore) (ESEC/FSE 2022). Association for Computing Machinery, New York, NY , USA, 44–56. doi:10.1145/3540250. 3549085 [Fowers et al.(2018...
-
[11]
In2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA)
A Configurable Cloud-Scale DNN Processor for Real-Time AI. In2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). 1–14. doi:10.1109/ISCA.2018.00012 [Genc et al.(2021)] Hasan Genc, Seah Kim, Alon Amid, Ameer Haj-Ali, Vighnesh Iyer, Pranav Prakash, Jerry Zhao, Daniel Grubb, Harrison Liew, Howard Mao, Albert Ou, Colin Schmidt, S...
-
[12]
In2021 58th ACM/IEEE Design Automation Conference (DAC)
Gemmini: Enabling 13 Finding Compiler-Platform Interaction Bugs in Deep Learning Pipelines via Cross-Layer Constraints Systematic Deep-Learning Architecture Evaluation via Full-Stack Integration. In2021 58th ACM/IEEE Design Automation Conference (DAC). 769–774. doi:10.1109/DAC18074.2021.9586216 [Ghodrati et al.(2024)] Soroush Ghodrati, Sean Kinzer, Hanyan...
-
[13]
Tandem Processor: Grappling with Emerging Operators in Neural Networks. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(La Jolla, CA, USA)(ASPLOS ’24). Association for Computing Machinery, New York, NY , USA, 1165–1182. doi:10.1145/3620665.3640365 [Gu et al.(2022)] J...
-
[14]
Muffin: testing deep learning libraries via neural architecture fuzzing. InProceedings of the 44th International Conference on Software Engineering (Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY , USA, 1418–1430. doi:10.1145/3510003.3510092 [Guo et al.(2021)] Qianyu Guo, Xiaofei Xie, Yi Li, Xiaoyu Zhang, Yang Liu, ...
-
[15]
Audee: automated testing for deep learning frameworks. InProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering(Virtual Event, Australia)(ASE ’20). Association for Computing Machinery, New York, NY , USA, 486–498. doi:10.1145/3324884.3416571 [Jin et al.(2020)] Tian Jin, Gheorghe-Teodor Bercea, Tung D Le, Tong Chen, Gon...
-
[16]
arXiv preprint arXiv:2008.08272(2020)
Compiling onnx neural network models using mlir. arXiv preprint arXiv:2008.08272(2020). [Kung et al.(2019)] H.T. Kung, Bradley McDanel, and Sai Qian Zhang
arXiv 2008
-
[17]
Packing Sparse Convolutional Neural Networks for Efficient Systolic Array Implementations: Column Combining Under Joint Optimization. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems(Providence, RI, USA)(ASPLOS ’19). Association for Computing Machinery, New York, NY , USA...
-
[18]
In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)
Graph- Based Fuzz Testing for Deep Learning Inference Engines. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). 288–299. doi:10.1109/ICSE43902.2021.00037 [Lym and Erez(2020)] Sangkug Lym and Mattan Erez
-
[19]
FlexSA: Flexible Systolic Array Architecture for Efficient Pruned DNN Model Training.CoRRabs/2004.13027 (2020). arXiv:2004.13027 https://arxiv.org/abs/ 2004.13027 [Ma et al.(2023)] Haoyang Ma, Qingchao Shen, Yongqiang Tian, Junjie Chen, and Shing-Chi Cheung
arXiv 2004
-
[20]
Fuzzing Deep Learning Compilers with HirGen. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis(Seattle, WA, USA)(ISSTA 2023). Association for Computing Machinery, New York, NY , USA, 248–260. doi:10.1145/3597926.3598053 [Mu et al.(2025)] Yanzhou Mu, Juan Zhai, Chunrong Fang, Xiang Chen, Zhixiang Cao, Peiran Yan...
-
[21]
Improving Deep Learning Framework Testing with Model-Level Metamorphic Testing.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA095 (June 2025), 23 pages. doi:10.1145/3728972 [Parashar et al.(2019)] Angshuman Parashar, Priyanka Raina, Yakun Sophia Shao, Yu-Hsin Chen, Victor A. Ying, Anurag Mukkara, Rangharajan Venkatesan, Brucek Khailany, Stephen W. Keckler, a...
-
[22]
In2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)
Timeloop: A Systematic Approach to DNN Accelerator Evaluation. In2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 304–315. doi:10.1109/ISPASS.2019.00042 [Paszke et al.(2019)] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca A...
-
[23]
In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE)
CRADLE: Cross-Backend Validation to Detect and Localize Bugs in Deep Learning Libraries. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). 1027–1038. doi:10.1109/ICSE.2019.00107 [Shen et al.(2021)] Qingchao Shen, Haoyang Ma, Junjie Chen, Yongqiang Tian, Shing-Chi Cheung, and Xiang Chen
-
[24]
A comprehensive study of deep learning compiler bugs. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (Athens, Greece)(ESEC/FSE 2021). Association for Computing Machinery, New York, NY , USA, 968–980. doi:10.1145/3468264.3468591 [Shen et al.(2025)] Qingchao Sh...
-
[25]
Optimization-Aware Test Generation for Deep Learning Compilers. arXiv:2511.18918 [cs.SE]https://arxiv.org/abs/2511.18918 [Steinhöfel and Zeller(2022)] Dominic Steinhöfel and Andreas Zeller
arXiv 2022
-
[26]
Input invariants. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 583–594. [Steinhöfel and Smytzek(2022)] Dominic Steinhöfel and Marius Smytzek. 2022.rindPHI/islearn: ISLearn 0.2.13. doi:10.5281/zenodo.7035007 [Wang et al.(2024)] Haoyu Wang, Junjie Chen, Chuyue Xie, Shu...
-
[27]
In: 2020 IEEE 20th International Working Conference on Source Code Analysis and Manipulation
MLIRSmith: Random Program Generation for Fuzzing MLIR Compiler Infrastructure. InProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering(Echternach, Luxembourg) (ASE ’23). IEEE Press, 1555–1566. doi:10.1109/ASE56229.2023.00120 [Wang et al.(2023)] Zihan Wang, Pengbo Nie, Xinyuan Miao, Yuting Chen, Chengcheng Wan, Lei Bu,...
-
[28]
GenCoG: A DSL-Based Approach to Generating Computation Graphs for TVM Testing. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis(Seattle, W A, USA)(ISSTA 2023). Association for Computing Machinery, New York, NY , USA, 904–916. doi:10.1145/ 3597926.3598105 [Wang et al.(2020)] Zan Wang, Ming Yan, Junjie Chen, Sh...
arXiv 2023
-
[29]
Deep learning library testing via effective model generation. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Virtual Event, USA) (ESEC/FSE 2020). Association for Computing Machinery, New York, NY , USA, 788–799. doi: 10.1145/ 3368089.3409761 [Xie et al.(2022)...
arXiv 2020
-
[30]
DocTer: documentation-guided fuzzing for testing deep learning API functions. InProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis(Virtual, South Korea)(ISSTA 2022). Association for Computing Machinery, New York, NY , USA, 176–188. doi:10.1145/3533767.3534220 [Xu et al.(2023)] Rui Xu, Sheng Ma, Yang Guo, and Dongsheng Li
-
[31]
Surv.56, 1, Article 20 (aug 2023), 37 pages
A Survey of Design and Optimization for Systolic Array-based DNN Accelerators.ACM Comput. Surv.56, 1, Article 20 (aug 2023), 37 pages. doi:10.1145/3604802 [Yang et al.(2024)] Chenyuan Yang, Yinlin Deng, Runyu Lu, Jiayi Yao, Jiawei Liu, Reyhaneh Jabbarvand, and Lingming Zhang
-
[32]
WhiteFox: White-Box Compiler Fuzzing Empowered by Large Language Models.Proc. ACM Program. Lang.8, OOPSLA2, Article 296 (Oct. 2024), 27 pages. doi:10.1145/3689736 [Yu et al.(2026)] Guangba Yu, Zirui Wang, Yujie Huang, Renyi Zhong, Yuedong Zhong, Yilun Wang, and Michael R. Lyu
-
[33]
Why Does the LLM Stop Computing: An Empirical Study of User-Reported Failures in Open-Source LLMs. arXiv:2601.13655 [cs.SE]https://arxiv.org/abs/2601.13655 [Zamudio Amaya et al.(2025)] José Antonio Zamudio Amaya, Marius Smytzek, and Andreas Zeller
arXiv 2025
-
[34]
FAN- DANGO: Evolving Language-Based Testing.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA040 (June 2025), 23 pages. doi:10.1145/3728915 [Zhou et al.(2024)] Chijin Zhou, Bingzhou Qian, Gwihwan Go, Quan Zhang, Shanshan Li, and Yu Jiang
-
[35]
PolyJuice: Detecting Mis-compilation Bugs in Tensor Compilers with Equality Saturation Based Rewriting.Proc. ACM Program. Lang.8, OOPSLA2, Article 317 (Oct. 2024), 27 pages. doi:10.1145/3689757 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.