Forged Calamity: Benchmark for Cross-Domain Synthetic Disaster Detection in the Age of Diffusion
Pith reviewed 2026-06-26 21:30 UTC · model grok-4.3
The pith
Detectors for AI-generated disaster images lose up to 50% accuracy when tested on new diffusion models or disaster types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
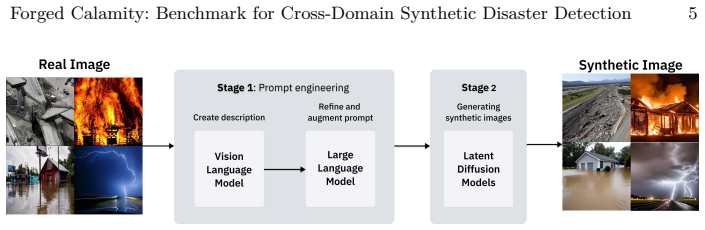
The Forged Calamity benchmark contains 6,000 real images and 24,000 synthetic ones from four diffusion models across multiple disaster categories. Comprehensive tests show fine-tuned detectors achieve strong in-distribution performance but suffer accuracy losses of up to 50% on unseen generators or disaster types due to overfitting on model-specific cues. Zero-shot generalized detectors maintain only limited and unstable accuracy, with few models showing any resilience. These results establish persistent cross-domain and cross-model generalization gaps in current forensic approaches.
What carries the argument
The Forged Calamity benchmark dataset together with its cross-generator and cross-disaster evaluation protocol, which measures how detection accuracy changes when both the image source and the disaster category are held out.
If this is right
- Fine-tuned detectors cannot be trusted for real-world use because they overfit to artifacts unique to each diffusion model.
- Zero-shot detectors lack the stability needed to handle the growing variety of text-to-image generators.
- Detection methods must move beyond model-specific cues toward features that remain consistent across generators.
- The benchmark exposes the need for new training strategies that explicitly target cross-domain robustness.
Where Pith is reading between the lines
- Future detectors might improve by training on mixtures of many generators rather than single ones.
- Similar generalization failures likely appear in other domains such as synthetic medical or news imagery.
- The benchmark could serve as a standard testbed for any new forensic method claiming broad applicability.
Load-bearing premise
The four selected diffusion models and the chosen disaster categories form a representative sample of all possible synthetic disaster images.
What would settle it
A detector that keeps accuracy above 85% on every held-out combination of generator and disaster type within the 30,000-image benchmark.
Figures



read the original abstract
The rapid advancement of text-to-image diffusion models has enabled the creation of highly photorealistic synthetic images that closely resemble real photographs, making it increasingly difficult to distinguish authentic content from AI-generated fabrications. This poses challenges for cybersecurity, digital forensics, and disaster response, where fake imagery of floods, fires, or earthquakes can spread misinformation or disrupt emergency operations. To address this, we introduce Forged Calamity, a benchmark dataset for synthetic disaster detection containing 30,000 images, including 6,000 real and 24,000 synthetic samples generated by four diffusion models. Comprehensive experiments across fine-tuned and zero-shot settings reveal consistent weaknesses in current forensic approaches. Fine-tuned detectors perform well in-distribution but lose up to 50\% accuracy on unseen generators or disaster types, showing overfitting to model-specific artifacts. Zero-shot generalized detectors also struggle to maintain stable accuracy, with only limited resilience in a few representation-robust models. These findings highlight persistent generalization gaps and the urgent need for domain- and model-agnostic detection methods to ensure visual authenticity in the diffusion era.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Forged Calamity benchmark dataset of 30,000 images (6,000 real photographs and 24,000 synthetic disaster images generated by four diffusion models) and reports experiments showing that fine-tuned detectors achieve strong in-distribution performance but suffer accuracy drops of up to 50% on unseen generators or disaster types due to overfitting to model-specific artifacts, while zero-shot detectors also exhibit unstable accuracy across domains.
Significance. If the reported cross-domain and cross-model generalization gaps are confirmed with additional controls, the work would provide a useful domain-specific benchmark for synthetic disaster imagery detection and empirically document concrete limitations of current forensic methods in a high-stakes application area.
major comments (2)
- [Abstract] Abstract: the central claim of up to 50% accuracy drops on unseen generators rests on the four diffusion models being representative of the broader space of synthetic disaster imagery; no justification is given for model selection or diversity of training corpora and artifact patterns, which directly affects whether the observed overfitting generalizes beyond the chosen set.
- [Abstract] Abstract: the reported accuracy drops and overfitting observations lack accompanying details on data splits, statistical tests, or controls for confounds such as image resolution or disaster-type balance, which are required to verify the generalization claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the need for stronger support of our generalization claims. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of up to 50% accuracy drops on unseen generators rests on the four diffusion models being representative of the broader space of synthetic disaster imagery; no justification is given for model selection or diversity of training corpora and artifact patterns, which directly affects whether the observed overfitting generalizes beyond the chosen set.
Authors: We agree the abstract provides no justification for selecting the four diffusion models or for claiming they represent broader artifact diversity. In revision we will add a concise statement to the abstract noting the models span open-source and closed-source systems with distinct training regimes, and we will expand the methods section with explicit discussion of their coverage of artifact patterns. This directly addresses whether the reported drops generalize. revision: yes
-
Referee: [Abstract] Abstract: the reported accuracy drops and overfitting observations lack accompanying details on data splits, statistical tests, or controls for confounds such as image resolution or disaster-type balance, which are required to verify the generalization claims.
Authors: We acknowledge the abstract omits these details. The full manuscript already specifies an 80/20 per-domain split, uniform resizing to 512x512, and balanced disaster-type sampling, but we will revise the abstract to reference these controls explicitly and add statistical significance testing (paired t-tests across runs) to the experiments section to substantiate the accuracy drops. revision: yes
Circularity Check
Empirical benchmark study with no derivations or self-referential predictions
full rationale
The paper introduces the Forged Calamity dataset (30k images from 4 diffusion models) and reports direct experimental results on fine-tuned and zero-shot detectors. No equations, fitted parameters, predictions, or uniqueness theorems are present. All claims (e.g., up to 50% accuracy drop) are empirical measurements on the introduced data, with no reduction to inputs by construction or self-citation chains. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI@Meta: Llama 3 model card.https://github.com/meta-llama/llama3/blob/ main/MODEL_CARD.md(2024)
2024
-
[2]
CrisisMMD: Multimodal Twitter Datasets from Natural Disasters
Alam,F.,Ofli,F.,Imran,M.:Crisismmd:Multimodaltwitterdatasetsfromnatural disasters. arXiv preprint arXiv:1805.00713 (2018),https://arxiv.org/abs/1805. 00713
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
arXiv preprint arXiv:2403.04692 (2024),https://arxiv.org/ abs/2403.04692
Chen, J., Ge, C., Xie, E., Wu, Y., Yao, L., Ren, X., Wang, Z., Luo, P., Lu, H., Li, Z.: PixArt-Sigma: Weak-to-strong training of diffusion transformer for 4k text-to- image generation. arXiv preprint arXiv:2403.04692 (2024),https://arxiv.org/ abs/2403.04692
-
[4]
Cioni, D., Tzelepis, C., Seidenari, L., Patras, I.: Are clip features all you need for universal synthetic image origin attribution? (2024)
2024
-
[5]
arXiv preprint arXiv:2211.00680 (2022),https://arxiv.org/abs/2211.00680
Corvi, R., Cozzolino, D., Zingarini, G., Poggi, G., Nagano, K., Verdoliva, L.: On the detection of synthetic images generated by diffusion models. arXiv preprint arXiv:2211.00680 (2022),https://arxiv.org/abs/2211.00680
-
[6]
Diffusion Models Beat GANs on Image Synthesis
Dhariwal, P., Nichol, A.: Diffusion models beat GANs on image synthesis. arXiv preprint arXiv:2105.05233 (2021),https://arxiv.org/abs/2105.05233
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
arXiv preprint arXiv:2003.08685 (2020),https://arxiv.org/abs/2003.08685
Frank, J., Eisenhofer, T., Sch¨ onherr, L., Fischer, A., Kolossa, D., Holz, T.: Leveraging frequency analysis for deep fake image recognition. arXiv preprint arXiv:2003.08685 (2020),https://arxiv.org/abs/2003.08685
-
[8]
Generative Adversarial Networks
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. arXiv preprint arXiv:1406.2661 (2014),https://arxiv.org/abs/1406.2661
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[9]
Journal of Imaging8(10), 263 (Sep 2022).https://doi.org/10.3390/ jimaging8100263
Guarnera, L., Giudice, O., Guarnera, F., et al.: The face deepfake detection chal- lenge. Journal of Imaging8(10), 263 (Sep 2022).https://doi.org/10.3390/ jimaging8100263
2022
-
[10]
Gupta, R., Hosfelt, R., Sajeev, S., Patel, N., Goodman, B., Doshi, J., Heim, E., Choset, H., Gaston, M.: xbd: A dataset for assessing building damage from satellite imagery. arXiv preprint arXiv:1911.09296 (2019),https://arxiv.org/abs/arXiv: 1911.09296 14 Duc-Manh Phan et al
-
[11]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[12]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Karageorgiou, D., Papadopoulos, S., Kompatsiaris, I., Gavves, E.: Any-resolution ai-generated image detection by spectral learning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18706–18717 (2025)
2025
-
[13]
A Style-Based Generator Architecture for Generative Adversarial Networks
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. arXiv preprint arXiv:1812.04948 (2019),https://arxiv. org/abs/1812.04948
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[14]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Koutlis, C., Papadopoulos, S.: Leveraging representations from intermediate encoder-blocks for synthetic image detection. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 394–411. Springer Nature Switzerland, Cham (2025)
2024
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Liu, H., Tan, Z., Tan, C., Wei, Y., Wang, J., Zhao, Y.: Forgery-aware adaptive transformer for generalizable synthetic image detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[16]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin Transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030 (2021),https://arxiv.org/abs/2103.14030
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Monahan, L., Martin, M., Zaitsev, A., Bartelt, V., Noordeen, A.R.: Do I spy AI? The impact of AI-generated images on trust and donation behaviors. First Monday30(4) (Apr 2025).https://doi.org/10.5210/fm.v30i4.13799,https: //firstmonday.org/ojs/index.php/fm/article/view/13799
-
[18]
arXiv preprint arXiv:2506.19261 (2025)
Nguyen, Q.B., Hoang, T.V., Tran, N.D., Nguyen, T.V., Tran, M.T., Le, T.N.: Automated image recognition framework. arXiv preprint arXiv:2506.19261 (2025)
-
[19]
In: Buntine, W., Fjeld, M., Tran, T., Tran, M.T., Huynh Thi Thanh, B., Miyoshi, T
Nguyen, Y.H., Le, T.N.: Decoding deepfakes: Caption guided learning for robust deepfake detection. In: Buntine, W., Fjeld, M., Tran, T., Tran, M.T., Huynh Thi Thanh, B., Miyoshi, T. (eds.) Information and Communication Technol- ogy. pp. 77–87. Springer Nature Singapore (2025).https://doi.org/10.1007/ 978-981-96-4282-3_7
2025
-
[20]
Ojha, U., Li, Y., Lee, Y.J.: Towards universal fake image detectors that generalize across generative models (2023)
2023
-
[21]
Ojha, U., Li, Y., Lee, Y.J.: Towards universal fake image detectors that generalize acrossgenerativemodels.arXivpreprintarXiv:2302.10174(2024),https://arxiv. org/abs/2302.10174
-
[22]
Transactions on Ma- chine Learning Research (2024),https://openreview.net/forum?id=a68SUt6zFt
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Syn- naeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual fe...
2024
-
[23]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M¨ uller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. arXiv preprint arXiv:2307.01952 (2023),https://arxiv.org/abs/ 2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.00020 Forged Calamity: Benchmark for Cross-Domain Synthetic Disaster Detection 15
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
arXiv preprint arXiv:2012.02951 (2020),https://arxiv.org/abs/ arXiv:2012.02951
Rahnemoonfar, M., Chowdhury, T., Sarkar, A., Varshney, D., Yari, M., Murphy, R.: Floodnet: A high resolution aerial imagery dataset for post flood scene un- derstanding. arXiv preprint arXiv:2012.02951 (2020),https://arxiv.org/abs/ arXiv:2012.02951
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (June 2022)
2022
-
[27]
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Frequency-aware deepfake detection: Improving generalizability through frequency space learning (2024)
2024
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tan, C., Zhao, Y., Wei, S., Gu, G., Wei, Y.: Learning on gradients: Generalized artifacts representation for gan-generated images detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12105– 12114 (2023)
2023
-
[29]
Verdoliva, L.: Media forensics and DeepFakes: An overview. IEEE Journal of Se- lected Topics in Signal Processing14(5), 910–932 (Aug 2020).https://doi.org/ 10.1109/jstsp.2020.3002101
-
[30]
arXiv preprint arXiv:2411.06441 (2024)
Vesnin, D., Levshun, D., Chechulin, A.: Detecting autoencoder is enough to catch ldm generated images. arXiv preprint arXiv:2411.06441 (2024)
-
[31]
vikhyatk: moondream2 (Revision 92d3d73) (2024).https://doi.org/10.57967/ hf/3219,https://huggingface.co/vikhyatk/moondream2
2024
-
[32]
In: Buntine, W., Fjeld, M., Tran, T., Tran, M.T., Huynh Thi Thanh, B., Miyoshi, T
Vo, H.D., Le, T.N.: Minimalist preprocessing approach for image synthe- sis detection. In: Buntine, W., Fjeld, M., Tran, T., Tran, M.T., Huynh Thi Thanh, B., Miyoshi, T. (eds.) Information and Communication Technol- ogy. pp. 88–99. Springer Nature Singapore (2025).https://doi.org/10.1007/ 978-981-96-4282-3_8
2025
-
[33]
Wang, Z., Bao, J., Zhou, W., Wang, W., Hu, H., Chen, H., Li, H.: Dire for diffusion- generated image detection (2023)
2023
-
[34]
arXiv preprint arXiv:2201.04236 (2022),https://arxiv.org/abs/2201
Weber, E., Papadopoulos, D.P., Lapedriza, A., Ofli, F., Imran, M., Torralba, A.: Incidents1M: a large-scale dataset of images with natural disasters, damage, and incidents. arXiv preprint arXiv:2201.04236 (2022),https://arxiv.org/abs/2201. 04236
-
[35]
arXiv preprint arXiv:2301.00808 (2023)
Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon, I.S., Xie, S.: ConvNeXt V2: Co-designing and scaling ConvNets with masked autoencoders. arXiv preprint arXiv:2301.00808 (2023),https://arxiv.org/abs/2301.00808
-
[36]
arXiv preprint arXiv:2006.03677 (2020),https: //arxiv.org/abs/2006.03677
Wu, B., Xu, C., Dai, X., Wan, A., Zhang, P., Yan, Z., Tomizuka, M., Gonzalez, J., Keutzer, K., Vajda, P.: Visual transformers: Token-based image representation and processing for computer vision. arXiv preprint arXiv:2006.03677 (2020),https: //arxiv.org/abs/2006.03677
-
[37]
Sigmoid Loss for Language Image Pre-Training
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. arXiv preprint arXiv:2303.15343 (2023),https://arxiv.org/abs/ 2303.15343
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
arXiv preprint arXiv:2012.09311 (2021),https://arxiv
Zhao, T., Xu, X., Xu, M., Ding, H., Xiong, Y., Xia, W.: Learning self-consistency for deepfake detection. arXiv preprint arXiv:2012.09311 (2021),https://arxiv. org/abs/2012.09311
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.