Experimental Analysis of Neural Network-Based Image Classification on the CIFAR-10 Dataset
Pith reviewed 2026-06-26 21:23 UTC · model grok-4.3
The pith
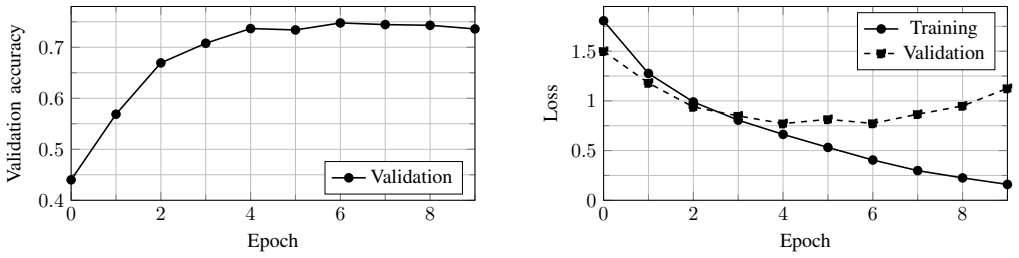
A six-layer convolutional network reaches 74.77 percent validation accuracy on CIFAR-10 after ten epochs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
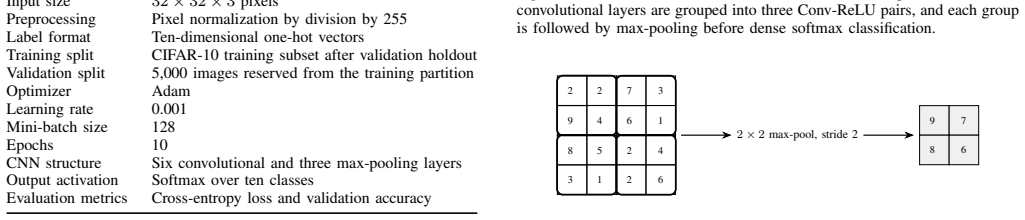
The central claim is that the described six-layer convolutional architecture with three max-pooling stages, trained for ten epochs at batch size 128 with Adam at learning rate 0.001, reaches a validation accuracy of approximately 74.77 percent on CIFAR-10. Validation loss starts to increase after the middle of training even as training loss keeps decreasing, which demonstrates the practical distinction between learning general representations and memorizing the training examples.
What carries the argument
The six convolutional layer architecture with three max-pooling stages, which performs successive feature extraction from input images before final classification.
If this is right
- The setup supplies a compact experimental baseline that later studies can use when testing regularization methods or data augmentation.
- The pipeline description supports educational use for demonstrating the full supervised image-classification process.
- The observed rise in validation loss while training loss falls shows the value of tracking generalization metrics during training.
- Deeper architectures or longer training runs can be compared directly against these ten-epoch results.
Where Pith is reading between the lines
- Adding regularization such as dropout to the same architecture would likely delay or reduce the observed validation loss increase.
- Reproducing the experiment on a different dataset could reveal how data complexity shifts the point at which validation loss begins to rise.
- Extending training beyond ten epochs without changes to the model would probably widen the gap between training and validation performance.
Load-bearing premise
The reported accuracy and loss curves assume the six-layer architecture, preprocessing steps, and training loop were coded and executed without implementation errors that would change the measured validation performance.
What would settle it
Re-running the identical six-layer convolutional training procedure on CIFAR-10 and measuring a validation accuracy substantially different from 74.77 percent would falsify the reported result.
Figures



read the original abstract
An experimental investigation of neural image classification on the CIFAR-10 benchmark is presented through fully connected and convolutional network formulations. The analysis emphasizes the complete learning pipeline: image vectorization, normalization, one-hot class encoding, supervised loss minimization, learning-rate selection, mini-batch training, convolutional feature extraction, max-pooling, and validation-based generalization assessment. A convolutional architecture with six convolutional layers and three max-pooling stages is evaluated for ten training epochs using a batch size of 128 and an Adam optimizer with a learning rate of 0.001. The validation accuracy reaches approximately 74.77%, while the validation loss begins to increase after the middle of training despite continued reduction in training loss. The resulting behavior illustrates the practical difference between representation learning and memorization, and it provides a compact experimental baseline for future studies on regularization, data augmentation, deeper architectures, and reproducible image-classification education.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an experimental investigation of neural network image classification on CIFAR-10, covering the full pipeline from vectorization and normalization through one-hot encoding and supervised training. It evaluates a convolutional architecture with six convolutional layers and three max-pooling stages trained for ten epochs (batch size 128, Adam optimizer with learning rate 0.001), reporting approximately 74.77% validation accuracy. The observed divergence—validation loss increasing after the middle of training while training loss continues to decrease—is interpreted as illustrating the difference between representation learning and memorization, and positioned as a compact baseline for future regularization and architecture studies.
Significance. If the reported accuracy and curves are produced by the exact architecture and procedure described, the work supplies a simple, self-contained empirical baseline for CIFAR-10 classification and overfitting behavior that could be useful in educational settings. However, the experiment follows well-established practices with no novel methodological contribution, ablation studies, or comparisons to prior baselines, so its significance remains modest even if fully specified.
major comments (2)
- [Abstract] Abstract: The central numerical claim (74.77% validation accuracy and the specific loss divergence) rests on an implementation whose details are not provided; the manuscript gives no channel counts, kernel sizes, strides, padding, or activation functions for the six convolutional layers, nor any code or random seed. Without these, the reported performance cannot be verified or reproduced and is therefore not load-bearing evidence for the claimed illustration of representation learning versus memorization.
- [Abstract] Abstract: The manuscript states that the analysis covers both fully connected and convolutional formulations, yet reports quantitative results and loss curves only for the convolutional network; the fully connected results are absent, weakening the scope of the pipeline analysis.
minor comments (1)
- The abstract and text would benefit from explicit citation of the original CIFAR-10 reference and standard preprocessing practices to situate the baseline.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on reproducibility and scope. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central numerical claim (74.77% validation accuracy and the specific loss divergence) rests on an implementation whose details are not provided; the manuscript gives no channel counts, kernel sizes, strides, padding, or activation functions for the six convolutional layers, nor any code or random seed. Without these, the reported performance cannot be verified or reproduced and is therefore not load-bearing evidence for the claimed illustration of representation learning versus memorization.
Authors: We agree that the architectural hyperparameters and training details must be fully specified for the numerical claims to be reproducible. In the revised manuscript we will add an explicit architecture table listing channel counts, kernel sizes, strides, padding, and activation functions for each of the six convolutional layers, together with the precise random seed and a statement that code will be released in a public repository. revision: yes
-
Referee: [Abstract] Abstract: The manuscript states that the analysis covers both fully connected and convolutional formulations, yet reports quantitative results and loss curves only for the convolutional network; the fully connected results are absent, weakening the scope of the pipeline analysis.
Authors: The abstract describes the overall pipeline that includes both formulations, but the quantitative experiments and loss curves focus on the convolutional case that supplies the reported baseline. We will revise the abstract and introduction to make this scope explicit and, if space permits, add a brief comparison of a fully-connected baseline or clearly state that only the convolutional results are quantified in the present study. revision: yes
Circularity Check
No circularity: purely experimental reporting of measured training outcomes
full rationale
The paper describes a six-layer CNN architecture, preprocessing, and training loop (Adam, lr=0.001, batch=128, 10 epochs) then directly reports measured validation accuracy (~74.77%) and loss curves from that procedure. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the load-bearing claims. The central observation (training loss decreases while validation loss rises) is presented as an empirical outcome of the explicit implementation, not as a result derived from or equivalent to its own inputs by construction. This is self-contained experimental reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Toronto, ON, Canada, Tech. Rep., 2009
2009
-
[2]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”Nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[3]
Learning representations by back-propagating errors,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back-propagating errors,”Nature, vol. 323, no. 6088, pp. 533–536, 1986
1986
-
[4]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278– 2324, 1998
1998
-
[5]
Goodfellow, Y
I. Goodfellow, Y . Bengio, and A. Courville,Deep Learning. Cambridge, MA, USA: MIT Press, 2016
2016
-
[6]
Rectified linear units improve restricted Boltzmann machines,
V . Nair and G. E. Hinton, “Rectified linear units improve restricted Boltzmann machines,” inProc. 27th Int. Conf. Machine Learning, 2010, pp. 807–814
2010
-
[7]
Understanding the difficulty of training deep feedfor- ward neural networks,
X. Glorot and Y . Bengio, “Understanding the difficulty of training deep feedfor- ward neural networks,” inProc. 13th Int. Conf. Artificial Intelligence and Statistics, 2010, pp. 249–256
2010
-
[8]
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,
K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,” inProc. IEEE Int. Conf. Computer Vision, 2015, pp. 1026–1034
2015
-
[9]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inProc. Int. Conf. Learning Representations, 2015
2015
-
[10]
Adaptive subgradient methods for online learning and stochastic optimization,
J. Duchi, E. Hazan, and Y . Singer, “Adaptive subgradient methods for online learning and stochastic optimization,”Journal of Machine Learning Research, vol. 12, pp. 2121–2159, 2011
2011
-
[11]
Dropout: A simple way to prevent neural networks from overfitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,”Journal of Machine Learning Research, vol. 15, no. 56, pp. 1929–1958, 2014
1929
-
[12]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” inProc. 32nd Int. Conf. Machine Learning, 2015, pp. 448–456
2015
-
[13]
A survey on image data augmentation for deep learning,
C. Shorten and T. M. Khoshgoftaar, “A survey on image data augmentation for deep learning,”Journal of Big Data, vol. 6, no. 60, 2019
2019
-
[14]
ImageNet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” inAdvances in Neural Information Processing Systems, vol. 25, 2012, pp. 1097–1105
2012
-
[15]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[16]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszkeet al., “PyTorch: An imperative style, high-performance deep learning library,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[17]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” inProc. Int. Conf. Learning Representations, 2015
2015
-
[18]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2017, pp. 2261–2269
2017
-
[19]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. Int. Conf. Learning Representations, 2019
2019
-
[20]
mixup: Beyond empirical risk minimization,
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” inProc. Int. Conf. Learning Representations, 2018
2018
-
[21]
AutoAugment: Learning augmentation strategies from data,
E. D. Cubuk, B. Zoph, D. Mane, V . Vasudevan, and Q. V . Le, “AutoAugment: Learning augmentation strategies from data,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2019, pp. 113–123
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.