HANSEL: Extracting Breadcrumbs from Web Agent Trajectories for Interactive Verification
Pith reviewed 2026-06-26 19:56 UTC · model grok-4.3
The pith
Extracting interactive evidence links from web agent trajectories lets users verify agent answers faster than reading full logs or summaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
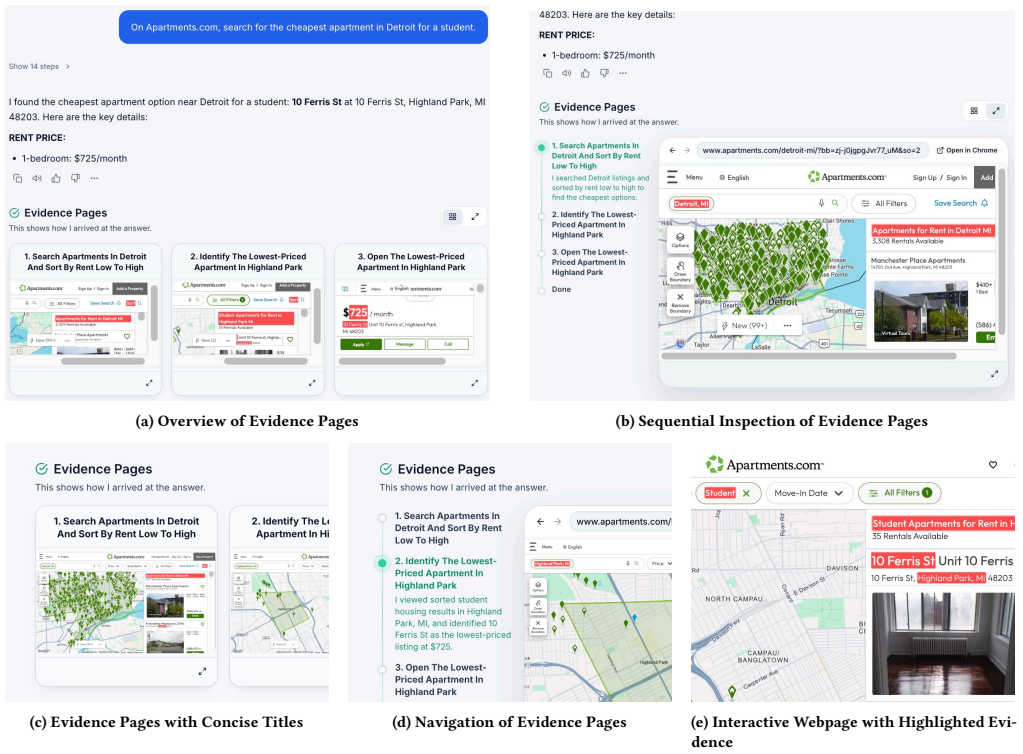
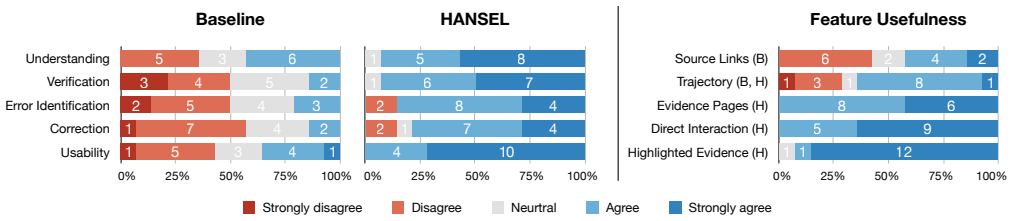
HANSEL extracts evidence pages and snippets from an agent trajectory and renders them as navigable interactive views that preserve page state. On 45 tasks from AssistantBench and Online-Mind2Web it reaches 83.7 percent precision and 88.8 percent recall while cutting the reviewed trajectory volume by 61.6 percent. In a study with 14 participants the interactive views produced shorter task times, lower perceived effort, and higher ratings for usability, verification ease, and error identification than a standard agent interface.
What carries the argument
HANSEL, the extraction pipeline that selects relevant visited pages and snippets then rebuilds them as state-preserving evidence links for direct user inspection.
If this is right
- Verification task completion time drops compared with full logs or summaries.
- Perceived effort and cognitive load decrease for oversight tasks.
- Users rate the system higher for ease of spotting mistakes in agent outputs.
- Trajectory data volume presented to the user shrinks by roughly 62 percent without loss of key evidence.
- When an answer lacks traceable support the system surfaces the gap explicitly.
Where Pith is reading between the lines
- The same extraction approach could apply to agent trajectories outside web browsing if action logs contain comparable page or state references.
- Designing agents to log richer state information would make evidence extraction more reliable by default.
- Interactive verification interfaces might become a default layer in agent deployment platforms rather than an add-on.
- The method suggests that future agent benchmarks could include verification accuracy as a core metric alongside task success.
Load-bearing premise
The extracted evidence pages, snippets, and preserved page states supply enough detail for users to correctly decide whether an agent's answer is backed by its trajectory.
What would settle it
A controlled test measuring whether users given HANSEL evidence links correctly flag unsupported agent answers at a lower rate than users given the complete unfiltered trajectory logs.
Figures

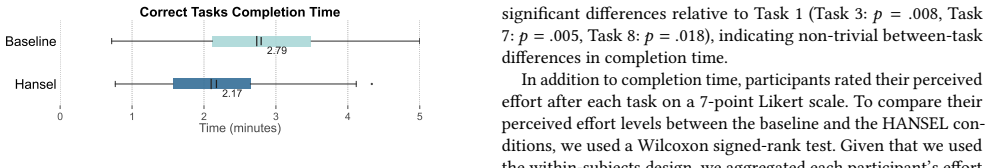

read the original abstract
AI web agents can perform complex, multi-step tasks such as searching for products, comparing options, and making purchases on behalf of users. However, verifying the correctness of an agent's output remains difficult. Existing transparency mechanisms, including full trajectory logs, source links, screenshots, and LLM-generated summaries, treat verification as a passive reading task, leaving users to sift through overwhelming logs or trust potentially unfaithful explanations. We present HANSEL (Highlighting Agent Navigation Steps as Evidence Links), a system that extracts interactive, verifiable evidence from web-agent trajectories. Given an agent trajectory, HANSEL extracts evidence pages and snippets and presents them as navigable, interactive views with relevant page state preserved (e.g., applied filters, search queries, and scroll positions), enabling users to verify how the agent arrived at its answer. When the agent's answer cannot be traced to any visited page, HANSEL explicitly flags this gap. A technical evaluation on 45 tasks from AssistantBench and Online-Mind2Web shows that HANSEL achieves 83.7% precision and 88.8% recall in identifying evidence pages, while reducing trajectory volume by 61.6%. In a controlled user study with 14 participants, HANSEL significantly reduced task completion time and perceived effort compared to a standard agent interface, while participants rated it significantly higher on usability, verification ease, and error identification. Our results demonstrate that reframing verification as an interactive activity, rather than passive consumption of agent explanations, leads to more efficient human oversight of AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HANSEL, a system that extracts interactive evidence pages, snippets, and preserved page states from web-agent trajectories to support verification of agent outputs. It reports a technical evaluation on 45 tasks from AssistantBench and Online-Mind2Web yielding 83.7% precision and 88.8% recall in evidence identification with 61.6% volume reduction, plus a controlled user study (n=14) showing reduced task time, lower perceived effort, and higher ratings for usability, verification ease, and error identification versus a standard agent interface. The central claim is that reframing verification as an interactive activity improves human oversight efficiency.
Significance. If the extraction quality and usability gains hold, the work provides a concrete, deployable mechanism for making agent trajectories more verifiable without requiring users to consume full logs or unfaithful summaries. The technical metrics are standard IR measures and the interactive design (navigable views with state preservation and explicit gap flagging) is a clear advance over passive transparency methods. The absence of objective accuracy data in the user study, however, limits claims about end-to-end verification fidelity.
major comments (2)
- [Abstract / Evaluation] Abstract (user-study paragraph) and Evaluation section: The study reports statistically significant improvements in task completion time, perceived effort, usability, verification ease, and error identification, yet provides no ground-truth labels on whether each agent's answer is supported by its trajectory and no accuracy metric (e.g., precision/recall or agreement with oracle judgments) for participants' support decisions under HANSEL versus baseline. This leaves the weakest assumption—that preserved pages and snippets suffice for correct verification—untested by the quantitative results.
- [Abstract] Abstract (final sentence) and User Study description: The claim that the approach 'leads to more efficient human oversight' is supported only by efficiency and subjective metrics; without an accuracy component, it is unclear whether the observed speed gains come at the cost of verification errors, which would undermine the oversight benefit.
minor comments (2)
- [Abstract] The abstract states concrete precision/recall and user-study statistics but supplies no methods detail, error bars, exclusion criteria, or full protocol; this should be expanded in the main text for reproducibility.
- [User Study] Clarify how 'error identification' was measured in the user study (e.g., did participants flag specific unsupported claims, or was it a binary judgment?).
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below, acknowledging the limitations of our user study while providing the strongest honest defense of the manuscript's contributions.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract (user-study paragraph) and Evaluation section: The study reports statistically significant improvements in task completion time, perceived effort, usability, verification ease, and error identification, yet provides no ground-truth labels on whether each agent's answer is supported by its trajectory and no accuracy metric (e.g., precision/recall or agreement with oracle judgments) for participants' support decisions under HANSEL versus baseline. This leaves the weakest assumption—that preserved pages and snippets suffice for correct verification—untested by the quantitative results.
Authors: We agree that the user study lacks objective ground-truth accuracy metrics for participants' verification decisions. The evaluation was scoped to efficiency, effort, and subjective usability measures, as collecting oracle judgments on support decisions would require additional annotation effort beyond the reported design. We will revise the Evaluation section and add an explicit limitations paragraph stating that accuracy of verification outcomes remains unmeasured and that the results demonstrate efficiency gains rather than end-to-end fidelity improvements. revision: partial
-
Referee: [Abstract] Abstract (final sentence) and User Study description: The claim that the approach 'leads to more efficient human oversight' is supported only by efficiency and subjective metrics; without an accuracy component, it is unclear whether the observed speed gains come at the cost of verification errors, which would undermine the oversight benefit.
Authors: The abstract claim is grounded in the statistically significant reductions in completion time and effort plus higher subjective ratings for error identification. We accept that this does not demonstrate correctness of oversight and that speed gains could theoretically mask errors. We will revise the abstract's final sentence and the user-study description to qualify the claim as improvements in efficiency and perceived verification support, while noting the missing accuracy evaluation. revision: yes
- Objective accuracy metrics for verification decisions cannot be added without new experiments involving ground-truth labels on agent answers.
Circularity Check
No circularity; empirical system evaluation is self-contained
full rationale
The paper introduces the HANSEL system for extracting interactive evidence from agent trajectories and reports two independent evaluations: (1) precision/recall on evidence-page identification across 45 tasks from AssistantBench and Online-Mind2Web, and (2) a controlled user study (n=14) using standard HCI metrics (task time, perceived effort, usability, verification ease). No equations, fitted parameters, or predictions appear anywhere in the described work. No self-citations, uniqueness theorems, or ansatzes are invoked to justify core claims. The technical metrics and user-study outcomes are measured against external benchmarks and participant responses rather than being statistically forced by the system's own extraction logic, so the reported results do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User-study tasks and metrics are representative of real verification needs
Reference graph
Works this paper leans on
-
[1]
Gagan Bansal, Jennifer Wortman Vaughan, Saleema Amershi, Eric Horvitz, Adam Fourney, Hussein Mozannar, Victor Dibia, and Daniel S. Weld. 2024. Challenges in Human-Agent Communication.CoRRabs/2412.10380 (2024). arXiv:2412.10380 doi:10.48550/ARXIV.2412.10380
-
[2]
Gagan Bansal, Tongshuang Wu, Joyce Zhou, Raymond Fok, Besmira Nushi, Ece Kamar, Marco Tulio Ribeiro, and Daniel Weld. 2021. Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). Association for Computing Machinery, Article...
-
[3]
Oliver Bentham, Nathan Stringham, and Ana Marasovic. 2024. Chain-of-Thought Unfaithfulness as Disguised Accuracy.Transactions on Machine Learning Re- search(2024). https://openreview.net/forum?id=ydcrP55u2e Reproducibility Certification
2024
-
[4]
Samuel R. Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamil˙e Lukoši¯ut˙e, Amanda Askell, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Christopher Olah, Daniela Amodei, Dario Amodei, Dawn Drain, Dustin Li, Eli Tran-Johnson, Jackson Kernion, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau,...
Pith/arXiv arXiv 2022
-
[5]
browser-use. 2024. browser-use: Browser automation framework. https://github. com/browser-use/browser-use
2024
-
[6]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z. Gajos. 2021. To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI- assisted Decision-making.Proc. ACM Hum.-Comput. Interact.5, CSCW1, Article 188 (April 2021). doi:10.1145/3449287
work page internal anchor Pith review doi:10.1145/3449287 2021
-
[7]
Alan Chan, Carson Ezell, Max Kaufmann, Kevin Wei, Lewis Hammond, Her- bie Bradley, Emma Bluemke, Nitarshan Rajkumar, David Krueger, Noam Kolt, Lennart Heim, and Markus Anderljung. 2024. Visibility into AI Agents. arXiv:2401.13138 [cs.CY] https://arxiv.org/abs/2401.13138
arXiv 2024
-
[8]
Andy Chung, Yichi Zhang, Kaixiang Lin, Aditya Rawal, Qiaozi Gao, and Joyce Chai. 2025. Evaluating Long-Context Reasoning in LLM-Based WebAgents. arXiv:2512.04307 [cs.LG] https://arxiv.org/abs/2512.04307
arXiv 2025
-
[9]
Victoria Clarke and Virginia Braun. 2017. Thematic analysis.The Journal of Positive Psychology12, 3 (2017), 297–298
2017
-
[10]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a Generalist Agent for the Web. arXiv:2306.06070 [cs.CL] https://arxiv.org/abs/2306.06070
Pith/arXiv arXiv 2023
-
[11]
Electron Team. 2025. Electron. https://www.electronjs.org/
2025
-
[12]
Will Epperson, Gagan Bansal, Victor C Dibia, Adam Fourney, Jack Gerrits, Erkang (Eric) Zhu, and Saleema Amershi. 2025. Interactive Debugging and Steering of Multi-Agent AI Systems. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). ACM, 1–15. doi:10.1145/3706598. 3713581
-
[13]
Martin Eppler and Jeanne Mengis. 2004. The Concept of Information Over- load: A Review of Literature From Organization Science, Accounting, Market- ing, MIS, and Related Disciplines.Inf. Soc.20 (11 2004), 325–344. doi:10.1080/ 01972240490507974
2004
-
[14]
K. J. Kevin Feng, Kevin Pu, Matt Latzke, Tal August, Pao Siangliulue, Jonathan Bragg, Daniel S. Weld, Amy X. Zhang, and Joseph Chee Chang. 2025. Cocoa: Co-Planning and Co-Execution with AI Agents. arXiv:2412.10999 [cs.HC] https: //arxiv.org/abs/2412.10999
arXiv 2025
-
[15]
Krzysztof Z. Gajos and Lena Mamykina. 2022. Do People Engage Cognitively with AI? Impact of AI Assistance on Incidental Learning. In27th International Conference on Intelligent User Interfaces (IUI ’22). ACM, 794–806. doi:10.1145/ 3490099.3511138
arXiv 2022
-
[16]
Google. 2025. Gemini Deep Research. https://gemini.google/overview/deep- research/
2025
-
[17]
Google. 2025. Get started with Gemini. https://support.google.com/gemini/ answer/14143489
arXiv 2025
-
[18]
Izzeddin Gur, Ulrich Rueckert, Aleksandra Faust, and Dilek Hakkani-Tur. 2018. Learning to Navigate the Web. arXiv:1812.09195 [cs.LG] https://arxiv.org/abs/ 1812.09195
Pith/arXiv arXiv 2018
-
[19]
Gaole He, Gianluca Demartini, and Ujwal Gadiraju. 2025. Plan-Then-Execute: An Empirical Study of User Trust and Team Performance When Using LLM Agents As A Daily Assistant. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). ACM, 1–22. doi:10.1145/3706598.3713218
-
[20]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. arXiv:2401.13919 [cs.CL] https: //arxiv.org/abs/2401.13919
Pith/arXiv arXiv 2024
-
[21]
Xu, Tianyue Ou, Shuyan Zhou, Jeffrey P
Faria Huq, Zora Zhiruo Wang, Frank F. Xu, Tianyue Ou, Shuyan Zhou, Jeffrey P. Bigham, and Graham Neubig. 2025. CowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation. InProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System...
-
[22]
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, Franck Ndzomga, Dheeraj Oruganty, Sophie Luskin, Kangheng Liu, Botao Yu, Amit Arora, Dongy- oon Hahm, Harsh Trivedi, Huan Sun, Juyong Lee, Tengjun Jin, Yifan Mai, Yifei Zhou, Yuxuan Zhu, Rishi Bommasani, Daniel Kang, ...
arXiv 2025
-
[23]
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Deni- son, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamil˙e Lukoši¯ut˙e, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy M...
Pith/arXiv arXiv 2023
-
[24]
Brian Y. Lim, Anind K. Dey, and Daniel Avrahami. 2009. Why and why not explanations improve the intelligibility of context-aware intelligent systems. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’09). Association for Computing Machinery, 2119–2128. doi:10.1145/1518701. 1519023
-
[25]
Xing Han Lù, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Alejandra Zambrano, Karolina Stanczak, Peter Shaw, Christopher Pal, and Siva Reddy. 2025. AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories. arXiv:2504.08942 [cs.CL] https://arxiv.org/abs/2504.08942
arXiv 2025
-
[26]
Brian Lubars and Chenhao Tan. 2019. Ask Not What AI Can Do, But What AI Should Do: Towards a Framework of Task Delegability. arXiv:1902.03245 [cs.AI] 12 https://arxiv.org/abs/1902.03245
arXiv 2019
-
[27]
Andreas Madsen, Sarath Chandar, and Siva Reddy. 2024. Are self-explanations from Large Language Models faithful?. InFindings of the Association for Com- putational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 (Findings of ACL). Association for Computational Linguistics, 295–337. doi:10.18653/V1/2024.FINDINGS-ACL.19
-
[28]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. GAIA: a benchmark for General AI Assistants. arXiv:2311.12983 [cs.CL] https://arxiv.org/abs/2311.12983
Pith/arXiv arXiv 2023
-
[29]
Hussein Mozannar, Gagan Bansal, Cheng Tan, Adam Fourney, Victor Dibia, Jingya Chen, Jack Gerrits, Tyler Payne, Matheus Kunzler Maldaner, Madeleine Grunde-McLaughlin, Eric Zhu, Griffin Bassman, Jacob Alber, Peter Chang, Ricky Loynd, Friederike Niedtner, Ece Kamar, Maya Murad, Rafah Hosn, and Saleema Amershi. 2025. Magentic-UI: Towards Human-in-the-loop Age...
arXiv 2025
-
[30]
Shikhar Murty, Hao Zhu, Dzmitry Bahdanau, and Christopher D. Manning. 2025. NNetNav: Unsupervised Learning of Browser Agents Through Environment Interaction in the Wild. arXiv:2410.02907 [cs.CL] https://arxiv.org/abs/2410.02907
arXiv 2025
-
[31]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. 2022. WebGPT: Browser-assisted question-answering with human feedback. arXiv:2112.09...
Pith/arXiv arXiv 2022
-
[32]
Liangbo Ning, Ziran Liang, Zhuohang Jiang, Haohao Qu, Yujuan Ding, Wenqi Fan, Xiao yong Wei, Shanru Lin, Hui Liu, Philip S. Yu, and Qing Li. 2025. A Survey of WebAgents: Towards Next-Generation AI Agents for Web Automation with Large Foundation Models. arXiv:2503.23350 [cs.AI] https://arxiv.org/abs/2503.23350
arXiv 2025
-
[33]
OpenAI. 2025. Introducing Operator. https://openai.com/index/introducing- operator/
2025
-
[34]
OpenHands. 2025. Trajectory Visualizer. https://github.com/OpenHands/ trajectory-visualizer
2025
-
[35]
Tianyue Ou, Wanyao Guo, Apurva Gandhi, Graham Neubig, and Xiang Yue. 2025. AgentDiagnose: An Open Toolkit for Diagnosing LLM Agent Trajectories. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Computational Linguistics, 207–215. doi:10.18653/v1/2025.emnlp-demos.15
-
[36]
Marvin Pafla, Kate Larson, and Mark Hancock. 2024. Unraveling the Dilemma of AI Errors: Exploring the Effectiveness of Human and Machine Explanations for Large Language Models. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, Article 839. doi:10.1145/3613904.3642934
-
[37]
Yi-Hao Peng, Dingzeyu Li, Jeffrey P Bigham, and Amy Pavel. 2025. Morae: Proactively Pausing UI Agents for User Choices. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Association for Computing Machinery, New York, NY, USA, Article 198, 14 pages. doi:10. 1145/3746059.3747797
arXiv 2025
-
[38]
Peter Pirolli and Stuart Card. 2005. The sensemaking process and leverage points for analyst technology as identified through cognitive task analysis. In Proceedings of international conference on intelligence analysis. McLean, VA, USA
2005
-
[39]
Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang
-
[40]
In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol
World of Bits: An Open-Domain Platform for Web-Based Agents. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 70). PMLR, 3135–3144. https://proceedings. mlr.press/v70/shi17a.html
-
[41]
Chenglei Si, Navita Goyal, Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daumé Iii, and Jordan Boyd-Graber. 2024. Large Language Models Help Humans Verify Truthfulness – Except When They Are Convincingly Wrong. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume...
-
[42]
John Sweller. 1988. Cognitive Load During Problem Solving: Effects on Learning. Cognitive Science12, 2 (1988), 257–285
1988
-
[43]
Sree Harsha Tanneru, Dan Ley, Chirag Agarwal, and Himabindu Lakkaraju. 2024. On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models. arXiv:2406.10625 [cs.CL] https://arxiv.org/abs/2406.10625
arXiv 2024
-
[44]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Lan- guage models don’t always say what they think: unfaithful explanations in chain-of-thought prompting. InProceedings of the 37th International Conference on Neural Information Processing Systems (NIPS ’23). Curran Associates Inc., Arti- cle 3275
2023
-
[45]
Karthik Valmeekam, Sarath Sreedharan, Matthew Marquez, Alberto Olmo, and Subbarao Kambhampati. 2023. On the Planning Abilities of Large Language Models (A Critical Investigation with a Proposed Benchmark). arXiv:2302.06706 [cs.AI] https://arxiv.org/abs/2302.06706
arXiv 2023
-
[46]
Helena Vasconcelos, Matthew Jörke, Madeleine Grunde-McLaughlin, Tobias Ger- stenberg, Michael Bernstein, and Ranjay Krishna. 2023. Explanations Can Reduce Overreliance on AI Systems During Decision-Making. arXiv:2212.06823 [cs.HC] https://arxiv.org/abs/2212.06823
arXiv 2023
-
[47]
Xinru Wang, Ming Yin, Eunyee Koh, and Mustafa Doga Dogan. 2026. XAgen: An Explainability Tool for Identifying and Correcting Failures in Multi-Agent Workflows. arXiv:2512.17896 [cs.HC] https://arxiv.org/abs/2512.17896
arXiv 2026
-
[48]
Tongshuang Wu, Michael Terry, and Carrie J. Cai. 2022. AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts. arXiv:2110.01691 [cs.HC] https://arxiv.org/abs/2110.01691
arXiv 2022
-
[49]
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu. 2025. AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web Tutorials. arXiv:2412.09605 [cs.CL] https://arxiv.org/ abs/2412.09605
arXiv 2025
-
[50]
Tianci Xue, Weijian Qi, Tianneng Shi, Chan Hee Song, Boyu Gou, Dawn Song, Huan Sun, and Yu Su. 2025. An Illusion of Progress? Assessing the Current State of Web Agents. arXiv:2504.01382 [cs.AI] https://arxiv.org/abs/2504.01382
arXiv 2025
-
[51]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2023. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. arXiv:2207.01206 [cs.CL] https://arxiv.org/abs/2207.01206
arXiv 2023
-
[52]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview. net/forum?id=WE_vluYUL-X
2023
-
[53]
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. 2024. AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks? arXiv:2407.15711 [cs.CL] https://arxiv.org/abs/2407. 15711
arXiv 2024
-
[54]
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. 2024. GPT-4V(ision) is a Generalist Web Agent, if Grounded. arXiv:2401.01614 [cs.IR] https://arxiv. org/abs/2401.01614
Pith/arXiv arXiv 2024
-
[55]
Runtao Zhou, Giang Nguyen, Nikita Kharya, Anh Totti Nguyen, and Chirag Agarwal. 2026. Improving Human Verification of LLM Reasoning through Inter- active Explanation Interfaces. arXiv:2510.22922 [cs.HC] https://arxiv.org/abs/ 2510.22922
arXiv 2026
-
[56]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv:2307.13854 [cs.AI] https://arxiv.org/abs/2307.13854 13
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.