From Bounding Boxes to Visual Reasoning: An On-Policy Data Annotation Tool for Vision-Language Models
Pith reviewed 2026-06-26 21:42 UTC · model grok-4.3
The pith
An on-policy annotation loop with a unified schema produces high-acceptance data that lifts VLM accuracy on flowcharts by 35 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
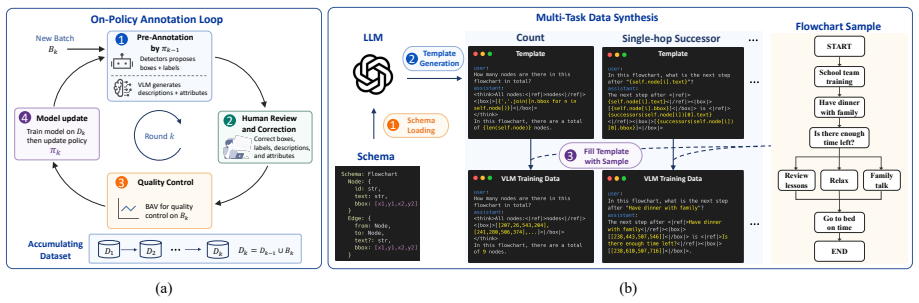
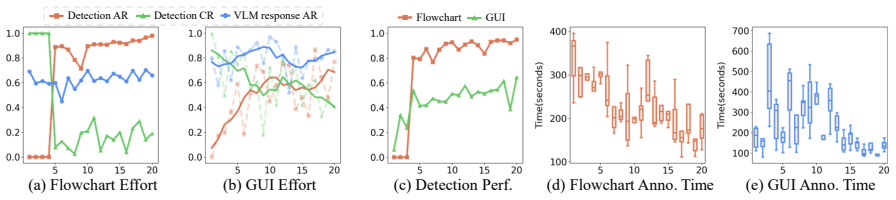
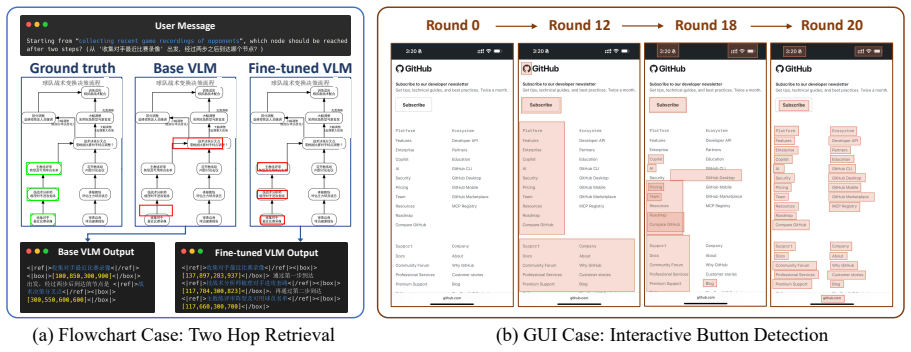
The paper establishes that an on-policy annotation loop embedded with a Bayesian Annotation Verifier, built on a unified annotation atom schema, drives annotation acceptance rates to nearly 100 percent on flowcharts and 77 percent on GUI screenshots while steadily decreasing per-image time as data accumulate; the same data, when used to fine-tune a VLM, yields 76.1 percent average accuracy, a 35.1-point absolute gain over the baseline.
What carries the argument
The unified annotation atom schema that binds spatial coordinates, open-vocabulary descriptions, structured attributes, and topological relationships into one unit, together with the on-policy annotation loop containing the Bayesian Annotation Verifier.
If this is right
- Annotation acceptance reaches nearly 100 percent on flowcharts and 77 percent on GUI screenshots without manual correction.
- Per-image annotation time declines as the volume of labeled data grows.
- Fine-tuning on the synthesized data raises VLM accuracy on flowchart reasoning to 76.1 percent.
- Template-driven synthesis generates multiple reasoning tasks from each static atom, removing the need for repeated annotation.
- The same schema and loop apply across flowchart and GUI domains without redesign.
Where Pith is reading between the lines
- The schema could be tested on additional visual domains such as diagrams or scene graphs to check whether acceptance rates and accuracy gains hold.
- If the verifier's Bayesian update is replaced by a simpler rule-based check, one could measure whether acceptance and time savings remain comparable.
- The multi-task synthesis templates might be extended to generate chain-of-thought reasoning examples directly from the atoms.
Load-bearing premise
The unified annotation atom schema binds spatial, semantic, and structural information into a representation that is sufficient and lossless for all downstream visual reasoning tasks.
What would settle it
Measure whether a VLM fine-tuned on data produced by this tool shows the same 35-point accuracy gain when evaluated on a new set of GUI screenshots or flowchart variants never seen during annotation.
Figures



read the original abstract
Vision-language models (VLMs) are rapidly advancing toward sophisticated grounded structured visual reasoning. Training models for such advanced capabilities demands a new genre of data that seamlessly unifies spatial coordinates, open-vocabulary descriptions, structured attributes, and topological relationships into a singular representation. However, existing data annotation tools fundamentally fail to meet these intricate demands, suffering from three systematic bottlenecks: limited expressiveness, severe annotation-training decoupling, and poor data reusability. To bridge this infrastructure gap, we introduce an open-source annotation tool, ScreenAnnotator. First, we define a unified annotation atom schema that binds spatial, semantic, and structural primitives into a single unit. Second, we implement an on-policy annotation loop embedded with a Bayesian Annotation Verifier (BAV). Finally, we design a template-driven multi-task data synthesis process dynamically transforms static atoms into diverse multi-dimensional reasoning tasks, eliminating redundant re-annotation. The on-policy loop drives the annotation accept rate to nearly 100% on flowcharts and 77% on GUI screenshots, while steadily reducing per-image annotation time as labeled data accumulate. In the flowchart scenario, fine-tuning a VLM yields 76.1% average accuracy, which is a 35.1% point absolute gain. Our code is available at: https://github.com/WnQinm/Annotator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScreenAnnotator, an open-source annotation tool for vision-language models that addresses bottlenecks in expressiveness, annotation-training decoupling, and data reusability. It defines a unified annotation atom schema integrating spatial coordinates, open-vocabulary descriptions, structured attributes, and topological relationships; implements an on-policy annotation loop with a Bayesian Annotation Verifier (BAV); and uses template-driven multi-task data synthesis to generate diverse reasoning tasks from static atoms. The authors report that the on-policy loop achieves nearly 100% accept rates on flowcharts and 77% on GUI screenshots while reducing per-image annotation time, and that fine-tuning a VLM on flowchart data yields 76.1% average accuracy (a 35.1 percentage point absolute gain).
Significance. If the reported performance gains are supported by rigorous, reproducible evaluation, the work could meaningfully advance VLM training infrastructure by enabling more expressive and reusable annotations for grounded visual reasoning. The open-source release and the on-policy loop design are concrete strengths that could support follow-on research.
major comments (3)
- [Abstract] Abstract: the manuscript states specific numeric outcomes (accept rates, time reduction, 35.1-point accuracy gain) but supplies no information on evaluation protocol, baseline comparisons, dataset sizes, statistical tests, or potential confounds, so the data-to-claim link cannot be assessed.
- [Introduction / Schema definition] The central claim that the unified annotation atom schema is sufficient and lossless for downstream visual reasoning tasks is load-bearing yet unsupported by any ablation or comparison showing that alternative representations would produce inferior VLM performance.
- [On-Policy Annotation Loop] The on-policy loop with BAV is presented as driving the reported accept rates, but the manuscript provides no implementation details, priors, or integration mechanics for BAV, preventing verification of how the loop produces the claimed efficiency gains.
minor comments (2)
- The term 'on-policy' is used without clarifying its relation to reinforcement-learning concepts or how the verifier influences the policy.
- Figure or diagram clarity: a visual example of an annotation atom and its transformation into multi-task templates would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states specific numeric outcomes (accept rates, time reduction, 35.1-point accuracy gain) but supplies no information on evaluation protocol, baseline comparisons, dataset sizes, statistical tests, or potential confounds, so the data-to-claim link cannot be assessed.
Authors: We agree that the abstract would be improved by briefly indicating the scale of the evaluation and the nature of the comparisons. In the revised version we will expand the abstract to note the number of images annotated, the VLM used for fine-tuning, the baseline model, and the evaluation split, while keeping the abstract concise. Full protocol details, including any statistical reporting, already appear in Section 4 and will be cross-referenced. revision: yes
-
Referee: [Introduction / Schema definition] The central claim that the unified annotation atom schema is sufficient and lossless for downstream visual reasoning tasks is load-bearing yet unsupported by any ablation or comparison showing that alternative representations would produce inferior VLM performance.
Authors: The empirical evidence for sufficiency is the 35.1-point accuracy improvement obtained when the synthesized tasks are derived from the atom schema. We did not, however, run an explicit ablation that replaces the atom schema with an alternative representation while holding all other factors fixed. In the revision we will add a short discussion subsection that contrasts the atom schema with common alternatives (e.g., separate bounding-box + caption pipelines) and explains the design rationale for unification; we will also note the absence of a controlled ablation as a limitation and outline how such an experiment could be conducted in future work. revision: partial
-
Referee: [On-Policy Annotation Loop] The on-policy loop with BAV is presented as driving the reported accept rates, but the manuscript provides no implementation details, priors, or integration mechanics for BAV, preventing verification of how the loop produces the claimed efficiency gains.
Authors: We acknowledge that the current manuscript text does not supply the concrete priors, update rules, or pseudocode for the Bayesian Annotation Verifier. The revision will include a new subsection (or expanded appendix) that specifies the prior distributions, the likelihood model, the decision threshold, and the exact integration points within the annotation loop. We will also add a short algorithmic description so that the efficiency claims can be reproduced. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces an annotation tool (ScreenAnnotator) with a unified atom schema, on-policy loop, and Bayesian Annotation Verifier, then reports measured empirical outcomes including accept rates (nearly 100% on flowcharts, 77% on GUI), per-image time reduction, and a 35.1-point accuracy gain after fine-tuning. These quantities are presented as experimental results from running the tool and training, not as quantities defined in terms of fitted parameters, self-referential definitions, or derivations that reduce to inputs by construction. No equations, uniqueness theorems, or self-citations appear in the text; the central claims rest on externally verifiable performance metrics rather than internal redefinitions or ansatzes smuggled via prior work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing annotation tools suffer from limited expressiveness, severe annotation-training decoupling, and poor data reusability.
- domain assumption A single unified annotation atom schema can capture all required spatial, semantic, and structural primitives without loss for visual reasoning.
invented entities (1)
-
Bayesian Annotation Verifier (BAV)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In2020 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 87–93, Paris, France
Bayesod: A bayesian approach for uncertainty estimation in deep object detectors. In2020 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 87–93, Paris, France. IEEE. Elmar Haussmann, Michele Fenzi, Kashyap Chitta, Jan Ivanecky, Hanson Xu, Donna Roy, Akshita Mittel, Nicolas Koumchatzky, Clement Farabet, and Jose M. Alvarez. 2020. Sc...
2020
-
[2]
InProceedings of the 8th International Conference on Learning Representa- tions, Addis Ababa, Ethiopia
Dividemix: Learning with noisy labels as semi-supervised learning. InProceedings of the 8th International Conference on Learning Representa- tions, Addis Ababa, Ethiopia. Sheng Liu, Zhihui Zhu, Qing Qu, and Chong You
-
[3]
Robust training under label noise by over- parameterization. InProceedings of the 39th Inter- national Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 14153–14172. PMLR. Ruijie Lu, Yiyang Ma, Xiaokang Chen, Lingxiao Luo, Zhiyu Wu, Zizheng Pan, Xingchao Liu, Yutong Lin, Hao Li, Wen Liu, Zhewen Hao, Xi Gao, Shaoh...
-
[4]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824. Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Brij B. Gupta, Xiaojiang Chen, and Xin Wang. 2022. A survey of deep active learn- ing.ACM Computing Surveys, 54(9):1–40. Bryan C Russell, Antonio Torralba, Kevin P Murphy, and William T Freeman....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Text” denotes the textual answer component and “Box
Label Studio: Data labeling soft- ware. Open source software available from https://github.com/HumanSignal/label-studio. Xueying Zhan, Qingzhong Wang, Kuan-hao Huang, Haoyi Xiong, Dejing Dou, and Antoni B. Chan. 2022. A comparative survey of deep active learning.arXiv preprint arXiv:2203.13450. Yudian Zheng, Guoliang Li, Yuanbing Li, Caihua Shan, and Reyn...
-
[6]
Successor. Q: In this flowchart, what is the next step after {node.text }? A: The next step after {node.text} is <|ref|>{successors(node )[0].text}<|/ref|><|box|>{successors(node)[0].bbox}<|/ box|>
-
[7]
Q: In this flowchart, which step directly connects to {node
Predecessor. Q: In this flowchart, which step directly connects to {node. text}? A: The step that directly connects to {node.text} is <|ref|>{ predecessors(node)[0].text}<|/ref|><|box|>{predecessors (node)[0].bbox}<|/box|>. 13
-
[8]
Count.This task type has four variants: node count, edge count, out-degree, and in-degree. Q: How many nodes are there in this flowchart? A: There are {len(nodes)} nodes in this flowchart <|ref|>{len (nodes)} nodes<|/ref|><|box|>[{nodes[0].bbox}, {nodes [1].bbox}, ..., {nodes[n].bbox}]<|/box|>. Q: How many connecting edges are there in this flowchart? A: ...
-
[9]
Q: Starting from {path[0].text}, which node is reached after two steps? A: Starting from <|ref|>{path[0].text}<|/ref|><|box|>{path[0]
Two-hop. Q: Starting from {path[0].text}, which node is reached after two steps? A: Starting from <|ref|>{path[0].text}<|/ref|><|box|>{path[0]. bbox}<|/box|>, the first step reaches <|ref|>{path[1]. text}<|/ref|><|box|>{path[1].bbox}<|/box|>, and the second step reaches <|ref|>{path[2].text}<|/ref|><|box |>{path[2].bbox}<|/box|>
-
[10]
Q: List the complete path from {path[0].text} to {path[-1]
Path. Q: List the complete path from {path[0].text} to {path[-1]. text}. A: The complete path is: <|ref|>{path[0].text}<|/ref|><|box |>{path[0].bbox}<|/box|> -> <|ref|>{path[1].text}<|/ref |><|box|>{path[1].bbox}<|/box|> -> ... -> <|ref|>{path [-1].text}<|/ref|><|box|>{path[-1].bbox}<|/box|>
-
[11]
Q: When the decision result of {edge.from_node.text} is {edge
Condition. Q: When the decision result of {edge.from_node.text} is {edge. text}, where does the flow go? A: When the result of <|ref|>{edge.from_node.text}<|/ref|><| box|>{edge.from_node.bbox}<|/box|> is <|ref|>{edge.text }<|/ref|><|box|>{edge.bbox}<|/box|>, the flow goes to <|ref|>{edge.to_node.text}<|/ref|><|box|>{edge.to_node. bbox}<|/box|>
-
[12]
Q: Where is {node.text} located in the image? A: <|ref|>{node.text}<|/ref|><|box|>{node.bbox}<|/box|> is located in the {region(node.bbox)} region of the image
Spatial. Q: Where is {node.text} located in the image? A: <|ref|>{node.text}<|/ref|><|box|>{node.bbox}<|/box|> is located in the {region(node.bbox)} region of the image
-
[13]
Relative. Q: In which direction is {first_node.text} relative to { second_node.text}? A: <|ref|>{first_node.text}<|/ref|><|box|>{first_node.bbox }<|/box|> is located to the {relative_pos(first_node. bbox, second_node.bbox)} of <|ref|>{second_node.text }<|/ref|><|box|>{second_node.bbox}<|/box|>
-
[14]
Region. Q: Which nodes are located in the {target_region} region of the image? A: The nodes located in the {target_region} region are: { node_1.text}, {node_2.text}, ..., {node_k.text} <|ref |>{target_region} region nodes<|/ref|><|box|>[{node_1. bbox}, {node_2.bbox}, ..., {node_k.bbox}]<|/box|>
-
[15]
Nearest. Q: Which node is spatially closest to {node.text}? A: The node spatially closest to <|ref|>{node.text}<|/ref|><| box|>{node.bbox}<|/box|> is <|ref|>{nearest_node.text }<|/ref|><|box|>{nearest_node.bbox}<|/box|>
-
[16]
Q: List all nodes in spatial order from top to bottom
Sorting.This task has two variants: top-to- bottom and left-to-right. Q: List all nodes in spatial order from top to bottom. A: The top-to-bottom order of nodes is: <|ref|>{node_1.text }<|/ref|><|box|>{node_1.bbox}<|/box|> -> <|ref|>{node_2. text}<|/ref|><|box|>{node_2.bbox}<|/box|> -> ... -> <| ref|>{node_n.text}<|/ref|><|box|>{node_n.bbox}<|/box|>. Q: L...
-
[17]
Q: What are the coordinates of {node.text}? A: The coordinates of {node.text} are <|ref|>{node.text}<|/ ref|><|box|>{node.bbox}<|/box|>
Coordinate.This task has two variants: grounding (text → box) and degrounding (box → text). Q: What are the coordinates of {node.text}? A: The coordinates of {node.text} are <|ref|>{node.text}<|/ ref|><|box|>{node.bbox}<|/box|>. Q: Which node is located in the region with coordinates {node. bbox}? A: The node located in this region is <|ref|>{node.text}<|...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.