Model-Free Reinforcement Learning Control for Resilient Cyber-Physical Systems
Pith reviewed 2026-06-26 19:29 UTC · model grok-4.3
The pith
Lyapunov-based rewards in model-free RL yield the strongest resilience to cyberattacks on nonlinear systems with minimal tracking error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
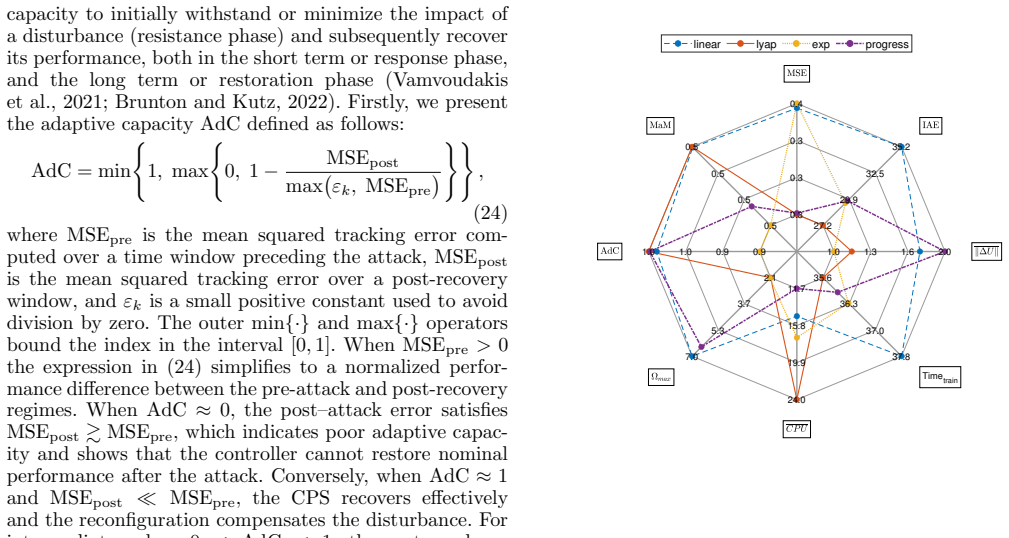
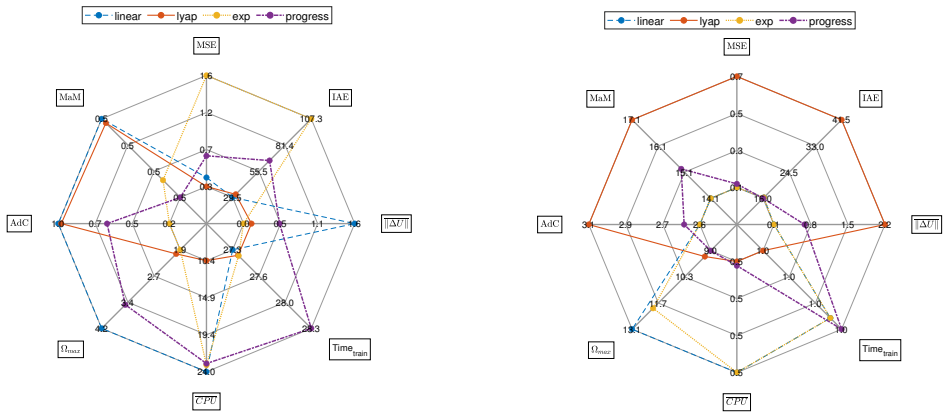
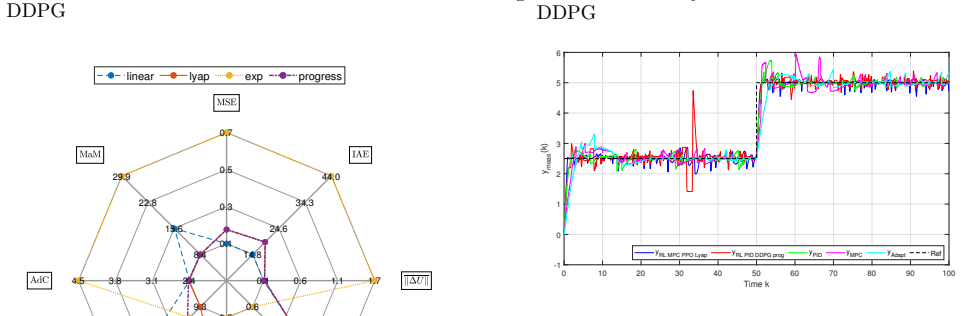
Through simulation experiments, the authors establish that Lyapunov reward functions deliver superior resilience and low tracking error in model-free RL control of nonlinear cyber-physical systems under cyberattacks, outperforming exponential, progressive, and linear rewards, with PPO providing lower variance than DDPG and RL-MPC offering strong steady-state performance at higher training cost.
What carries the argument
Four RL reward types—Lyapunov, exponential, progressive, and linear—applied within PPO and DDPG algorithms to RL-PID and RL-MPC controllers for resilience evaluation.
Load-bearing premise
The simulation setup and attack models used accurately represent the behavior of real nonlinear cyber-physical systems under actual cyberattacks.
What would settle it
Running the same controllers on physical hardware exposed to real false data injection and denial-of-service attacks and measuring if the Lyapunov reward still achieves the lowest tracking error.
Figures


read the original abstract
This paper compares the performance of model-free controllers on a nonlinear system under cyberattacks, including false data injection and denial-of-service attacks. Four RL reward types are analyzed for accuracy, cost, and resilience. Results show that the Lyapunov reward offers the best resilience with low tracking error. Exponential mode also provides good trade-offs with acceptable resilience under moderate training conditions. Progressive and linear rewards converge faster but are less robust. RL-MPCs show strong steady-state resilience but require longer training times; RL-PID controllers are faster with significantly less training time. Proximal Policy Optimization outperforms Deep Deterministic Policy Gradient with a significant reduction in KPI variance. This study serves to highlight how well-designed RL rewards can improve performance and resilience against cyber threats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares model-free RL controllers (PPO and DDPG) using four reward functions (Lyapunov, exponential, progressive, linear) plus RL-MPC and RL-PID variants on a nonlinear cyber-physical system subject to false data injection and denial-of-service attacks. It claims that the Lyapunov reward yields the best resilience with low tracking error, the exponential reward offers acceptable trade-offs under moderate training, progressive and linear rewards converge faster but are less robust, RL-MPC provides strong steady-state resilience at the cost of longer training, RL-PID trains faster, and PPO significantly reduces KPI variance relative to DDPG.
Significance. The topic of reward shaping for resilient RL control of CPS under cyberattacks is relevant to the systems and control community. If the reported orderings prove robust across plants and attack realizations, the work could inform practical reward design. The comparison of multiple reward types and algorithms is a reasonable contribution, but the absence of any system equations, attack-parameter ranges, trial counts, or sensitivity results in the provided description substantially reduces the strength of the claims.
major comments (2)
- [Abstract] Abstract: the performance rankings (Lyapunov best for resilience + low tracking error; PPO better than DDPG on KPI variance) are stated without any description of the nonlinear plant equations, sensor/actuator channels, FDI/DoS injection mechanisms, attack-parameter ranges, number of trials, error bars, or statistical tests, so the ordering cannot be assessed for reproducibility or robustness.
- [Results] Results section: the comparative claims rest entirely on closed-loop simulations of one unspecified nonlinear plant under two stylized attack models; without system dynamics, attack timing/bandwidth details, or sensitivity analysis, any mismatch in nonlinearity strength or attack realization directly alters which reward produces the reported trade-offs, making the headline ordering conditional on unstated modeling choices.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater detail to support reproducibility and robustness assessment. We address each major comment below and will revise the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance rankings (Lyapunov best for resilience + low tracking error; PPO better than DDPG on KPI variance) are stated without any description of the nonlinear plant equations, sensor/actuator channels, FDI/DoS injection mechanisms, attack-parameter ranges, number of trials, error bars, or statistical tests, so the ordering cannot be assessed for reproducibility or robustness.
Authors: We agree that the abstract, being concise, omits key experimental details. In the revised manuscript we will expand the abstract to briefly state the nonlinear plant (including reference to its equations), the FDI/DoS mechanisms with parameter ranges, the number of independent trials, and the use of error bars/statistical comparisons underlying the reported rankings. revision: yes
-
Referee: [Results] Results section: the comparative claims rest entirely on closed-loop simulations of one unspecified nonlinear plant under two stylized attack models; without system dynamics, attack timing/bandwidth details, or sensitivity analysis, any mismatch in nonlinearity strength or attack realization directly alters which reward produces the reported trade-offs, making the headline ordering conditional on unstated modeling choices.
Authors: The manuscript provides the plant dynamics and attack models in the problem formulation and simulation sections, but we acknowledge that explicit attack timing/bandwidth ranges and sensitivity results are not sufficiently highlighted in the results. We will add a dedicated sensitivity subsection that varies nonlinearity strength and attack parameters to demonstrate that the reported reward ordering remains consistent within the tested ranges, thereby clarifying the scope of the claims. revision: yes
Circularity Check
No circularity; results are empirical simulation outcomes
full rationale
The paper reports comparative performance metrics obtained from closed-loop simulations of model-free RL controllers (PPO, DDPG) with four reward formulations on an unspecified nonlinear plant subject to stylized FDI and DoS attacks. No derivation chain, uniqueness theorem, fitted-parameter prediction, or self-citation load-bearing step is present; the headline ordering (Lyapunov reward best for resilience) is presented strictly as an experimental finding rather than a quantity defined in terms of the inputs or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
(eds.) (2021)
Belousov, B., Abdulsamad, H., Klink, P., Parisi, S., and Peters, J. (eds.) (2021). Reinforcement Learning Algorithms: Analysis and Applications, volume 883 of Studies in Computational Intelligence. Springer, Cham, Switzerland
2021
-
[2]
and Kutz, J.N
Brunton, S.L. and Kutz, J.N. (2022). Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control. Cambridge University Press, 2nd edition
2022
-
[3]
del Real Torres, A., Andreiana, D.S., Ojeda Roldan, A., Hernandez Bustos, A., and Acevedo Galicia, L.E. (2022). A review of deep reinforcement learning approaches for smart manufacturing in industry 4.0 and 5.0 framework. Applied Sciences, 12(23), 12377
2022
-
[4]
Guerraoui, R., Gupta, N., and Pinot, R. (2024). Robust Machine Learning, Distributed methods for safe AI. Springer
2024
-
[5]
and Pavi \'c , I
Hrgovi \'c , I. and Pavi \'c , I. (2025). Reward design for intelligent deep reinforcement learning based power flow control using topology optimization. Sustainable energy, grids and networks, 41, 101580
2025
-
[6]
Ibrahim, S., Mostafa, M., Jnadi, A., Salloum, H., and Osinenko, P. (2024). Comprehensive overview of reward engineering and shaping in advancing reinforcement learning applications. IEEE Access, 12, 175473--175500
2024
-
[7]
Khaki - Sedigh, A. (2024). An Introduction to Data-Driven Control Systems. IEEE Press / John Wiley & Sons, Hoboken, NJ
2024
-
[8]
Lawrence, N.P., Gopaluni, R.B., Huang, B., and Lee, J.M. (2024). Machine learning for industrial sensing and control: A survey and practical perspective. Control Engineering Practice, 145, 105841
2024
-
[9]
and Qiu, M
Li, C. and Qiu, M. (2019). Reinforcement Learning for Cyber-Physical Systems: With Cybersecurity Case Studies. CRC Press, Boca Raton, FL
2019
-
[10]
Li, J., Lewis, F.L., and Fan, J. (2023). Reinforcement Learning: Optimal Feedback Control with Industrial Applications. Advances in Industrial Control. Springer, Cham, Switzerland
2023
-
[11]
Lian, B., Xue, W., Lewis, F.L., Modares, H., and Kiumarsi, B. (2024). Integral and Inverse Reinforcement Learning for Optimal Control Systems and Games. Advances in Industrial Control. Springer, Cham, Switzerland
2024
-
[12]
McClement, D.G., Lawrence, N.P., Backström, J.U., Loewen, P.D., Forbes, B.G., and Gopaluni, R.B. (2022). Meta-reinforcement learning for the tuning of pi controllers: An offline approach. Journal of Process Control, 118, 139--152
2022
-
[13]
Precup, R., Roman, R., and Safaei, A. (2022). Data-Driven Model-Free Controllers. CRC Press, Boca Raton, FL
2022
-
[14]
Rieger, C.G., McQueen, M., and Gertman, D. (2021). Resilient control systems—basis, benchmarking, and benefit. IEEE Access, 9, 57564--57580
2021
-
[15]
Spielberg, E., Tulsyan, A., and Gopaluni, R. (2019). Toward self-driving processes: A deep reinforcement learning approach to control. AIChE Journal, 65(10), e16689
2019
-
[16]
(eds.) (2021)
Vamvoudakis, K.G., Wan, Y., Lewis, F.L., and Cansever, D. (eds.) (2021). Handbook of Reinforcement Learning and Control, volume 325 of Studies in Systems, Decision and Control. Springer
2021
-
[17]
Yin, C.W. (2025). Model-free sliding mode resilient control of cyber-physical system based on reinforcement learning. Applied Intelligence, 55(11), 824
2025
-
[18]
Zhu, X., Wang, Y., and Wu, Z. (2025). Reinforcement learning for optimal control of stochastic nonlinear systems. AIChE Journal, 71(7), e18840
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.