Mechanism-Guided Selective Unlearning for RLVR-Induced Reasoning
Pith reviewed 2026-06-26 21:12 UTC · model grok-4.3
The pith
MAST ranks attention-projection tensors to forget RLVR-induced math reasoning while leaving retain sets intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
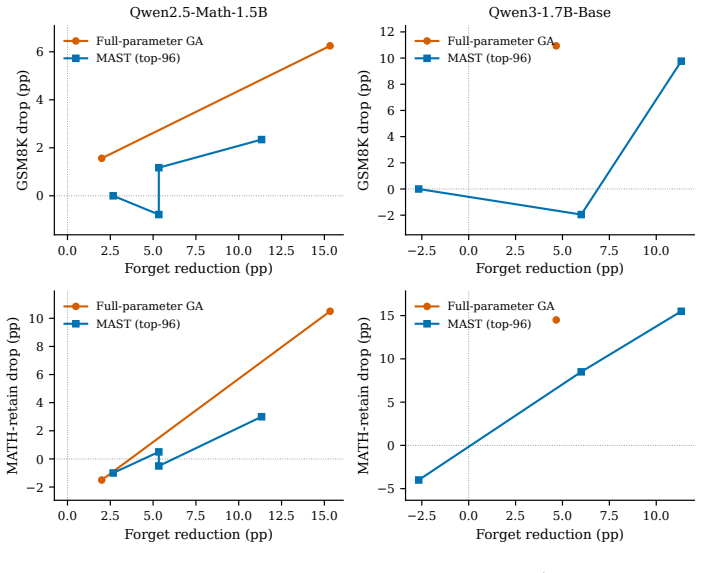
In matched SFT-to-RLVR checkpoints the token-level delta-log-probability increment differs sharply from the SFT update. Full-parameter ascent forgets only by harming retain sets. MAST ranks attention-projection tensors by off-principal energy, update magnitude, and forget-gradient coupling magnitude, updates only the top subset, and thereby induces statistically significant target forgetting (MATH forget 45/150 to 37/150, McNemar p=0.0078) while preserving GSM8K (+0.8 pp) and MATH retain (-0.5 pp). The advantage reproduces across seeds, NPO/SimNPO objectives, and Qwen3.
What carries the argument
MAST ranks attention-projection tensors by off-principal energy, update magnitude, and forget-gradient coupling magnitude to select a subset for update that isolates RLVR-induced changes.
If this is right
- Target forgetting reaches statistical significance on the MATH forget set (45/150 to 37/150, McNemar p=0.0078).
- GSM8K accuracy is preserved or slightly improved (+0.8 pp).
- MATH retain set changes by only -0.5 pp.
- The selective advantage reproduces across random seeds, NPO/SimNPO objectives, and the Qwen3 model family.
Where Pith is reading between the lines
- The same three-metric ranking could be tested on non-math unlearning tasks such as removing specific factual associations or unsafe response patterns.
- If the off-principal energy and coupling metrics locate training-phase effects in other architectures, the approach might reduce the cost of capability editing more broadly.
- The observed difference between SFT and RLVR increments in token-level delta-log-probability suggests that distinct training stages may affect largely separate parameter subsets.
Load-bearing premise
The ranking of attention-projection tensors by off-principal energy, update magnitude, and forget-gradient coupling magnitude identifies parameters whose selective update produces the desired forgetting without collateral damage to retain sets.
What would settle it
Updating the top-ranked tensors under MAST yet observing either no statistically significant drop on the MATH forget set or a large drop on the GSM8K or MATH retain sets would falsify the central claim.
Figures


read the original abstract
We propose MAST (Mechanism-Aligned Selective Targeting), a mechanism-guided method for unlearning RLVR-induced reasoning with substantially lower collateral damage than standard full-parameter updates. In matched SFT/RLVR checkpoints on Qwen2.5-Math-1.5B and Qwen3-1.7B-Base, the SFT-to-RLVR increment differs sharply from the SFT update in token-level delta-log-probability, and full-parameter gradient ascent forgets only by damaging retain MATH and GSM8K. MAST ranks attention-projection tensors by off-principal energy, update magnitude, and forget-gradient coupling magnitude, then updates only the top-ranked subset. On the primary model, MAST induces statistically significant target forgetting (MATH forget 45/150 to 37/150; McNemar p=0.0078) while preserving GSM8K (+0.8 pp) and MATH retain (-0.5 pp). The advantage reproduces across seeds, NPO/SimNPO objectives, and Qwen3, where MAST preserves GSM8K while full-parameter unlearning collapses it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MAST (Mechanism-Aligned Selective Targeting), a selective unlearning method for RLVR-induced reasoning. It identifies attention-projection tensors via a three-metric ranking (off-principal energy, update magnitude, forget-gradient coupling magnitude) and performs targeted updates on only the top-ranked subset. On Qwen2.5-Math-1.5B and Qwen3 models, MAST produces statistically significant forgetting on a MATH forget set (45/150 to 37/150, McNemar p=0.0078) while preserving GSM8K (+0.8 pp) and MATH retain (-0.5 pp), outperforming full-parameter gradient ascent which damages retain sets; the advantage holds across seeds, NPO/SimNPO objectives, and model variants.
Significance. If the central result holds, the work demonstrates a practical route to mechanism-guided unlearning that reduces collateral damage relative to full-parameter methods, addressing a key limitation in safety applications of RL-trained models. The reproduction across seeds, objectives, and two model families provides some robustness evidence. No parameter-free derivations or machine-checked proofs are present, but the quantitative evaluation with explicit p-values and cross-setting consistency is a strength.
major comments (1)
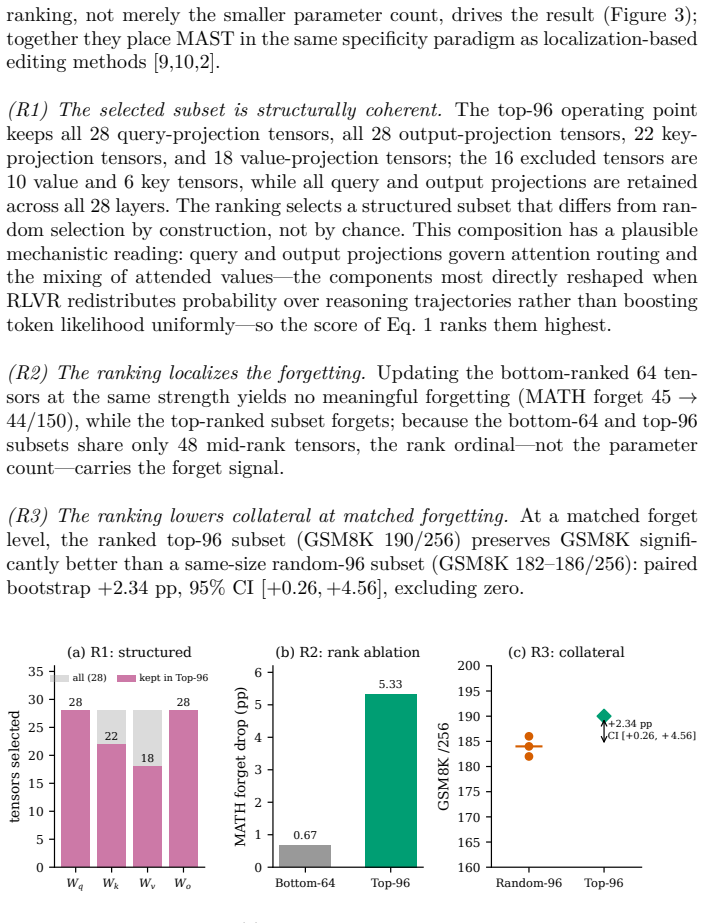
- [Experiments] Experiments section (and associated tables/figures): the manuscript reports no ablation comparing the three-metric ranking against random subset selection of the same size or against single-metric rankings. This omission leaves open whether the observed preservation of GSM8K and MATH retain is attributable to mechanism-specific alignment or merely to the reduced number of updated parameters; the claim that the ranking isolates RLVR-induced reasoning mechanisms is therefore untested and load-bearing for the central contribution.
minor comments (1)
- [Abstract] The abstract states the McNemar test result but does not specify the exact contingency table construction or correction for multiple comparisons; adding these details in the main text would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for ablations on the ranking procedure. We agree this strengthens the central claim and will incorporate the requested comparisons.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and associated tables/figures): the manuscript reports no ablation comparing the three-metric ranking against random subset selection of the same size or against single-metric rankings. This omission leaves open whether the observed preservation of GSM8K and MATH retain is attributable to mechanism-specific alignment or merely to the reduced number of updated parameters; the claim that the ranking isolates RLVR-induced reasoning mechanisms is therefore untested and load-bearing for the central contribution.
Authors: We agree that the absence of these ablations leaves the mechanism-specific contribution of the three-metric ranking untested relative to parameter count alone. The manuscript motivates the metrics from observed differences in token-level delta-log-probability between SFT and RLVR updates and from gradient-coupling analysis, but does not empirically isolate their joint effect. In revision we will add (i) random subset selection of identical cardinality and (ii) single-metric rankings, each evaluated on the same forget/retain splits, seeds, and objectives. These results will be reported in an expanded Experiments section with the same McNemar and accuracy metrics. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines MAST explicitly as a ranking procedure over attention-projection tensors using three stated metrics (off-principal energy, update magnitude, forget-gradient coupling magnitude), then applies selective updates and reports empirical outcomes on held-out benchmarks (MATH forget set, GSM8K, MATH retain). No equations, fitted parameters, or self-citations are shown to reduce the reported forgetting/preservation statistics to the ranking inputs by construction; the advantage over full-parameter baselines is presented as an observed experimental result rather than a definitional identity. The derivation chain therefore remains self-contained against external evaluation data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.07163 (2024)
Fan, C., Liu, J., Lin, L., Jia, J., Zhang, R., Mei, S., Liu, S.: Simplicity prevails: Rethinking negative preference optimization for LLM unlearning. arXiv preprint arXiv:2410.07163 (2024)
arXiv 2024
-
[2]
knowledge edit- ing in language models
Hase, P., Bansal, M., Kim, B., Ghandeharioun, A.: Does localization inform editing? surprising differences in causality-based localization vs. knowledge edit- ing in language models. In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[3]
In: International Con- ference on Learning Representations (ICLR) (2021)
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Con- ference on Learning Representations (ICLR) (2021)
2021
-
[4]
arXiv preprint arXiv:2603.22117 (2026)
Huang, K., Meng, H., Wu, J., et al.: On the direction of RLVR updates for LLM reasoning: Identification and exploitation. arXiv preprint arXiv:2603.22117 (2026)
arXiv 2026
-
[5]
arXiv preprint arXiv:2603.04426 (2026)
Kassem, A., Jiralerspong, T., Rostamzadeh, N., Farnadi, G.: Delta-Crosscoder: Robust crosscoder model diffing in narrow fine-tuning regimes. arXiv preprint arXiv:2603.04426 (2026)
arXiv 2026
-
[6]
arXiv preprint arXiv:2507.21084 (2025)
Kassem, A.M., Shi, Z., Rostamzadeh, N., Farnadi, G.: Reviving your MNEME: Predicting the side effects of LLM unlearning and fine-tuning via sparse model diffing. arXiv preprint arXiv:2507.21084 (2025)
arXiv 2025
-
[7]
arXiv preprint arXiv:2403.03218 (2024)
Li, N., Pan, A., Gopal, A., et al.: The WMDP benchmark: Measuring and reducing malicious use with unlearning. arXiv preprint arXiv:2403.03218 (2024)
Pith/arXiv arXiv 2024
-
[8]
arXiv preprint arXiv:2401.06121 (2024)
Maini, P., Feng, Z., Schwarzschild, A., Lipton, Z.C., Kolter, J.Z.: TOFU: A task of fictitious unlearning for LLMs. arXiv preprint arXiv:2401.06121 (2024)
Pith/arXiv arXiv 2024
-
[9]
In: Advances in Neural Information Processing Systems (NeurIPS) (2022)
Meng, K., Bau, D., Andonian, A., Belinkov, Y.: Locating and editing factual associ- ations in GPT. In: Advances in Neural Information Processing Systems (NeurIPS) (2022)
2022
-
[10]
In: International Conference on Learning Representations (ICLR) (2023)
Meng, K., Sharma, A.S., Andonian, A., Belinkov, Y., Bau, D.: Mass-editing mem- ory in a transformer. In: International Conference on Learning Representations (ICLR) (2023)
2023
-
[11]
arXiv preprint arXiv:2402.03300 (2024)
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
Pith/arXiv arXiv 2024
-
[12]
arXiv preprint arXiv:2402.15159 (2024)
Yao, J., Chien, E., Du, M., et al.: Machine unlearning of pre-trained large language models. arXiv preprint arXiv:2402.15159 (2024)
arXiv 2024
-
[13]
Yue, Y., Chen, Z., Lu, R., et al.: Does reinforcement learning really incentivize rea- soning capacity in LLMs beyond the base model? arXiv preprint arXiv:2504.13837 (2025)
Pith/arXiv arXiv 2025
-
[14]
arXiv preprint arXiv:2601.09361 (2026)
Zhang, J., Shi, L., Li, J., et al.: GeoRA: Geometry-aware low-rank adaptation for RLVR. arXiv preprint arXiv:2601.09361 (2026)
Pith/arXiv arXiv 2026
-
[15]
arXiv preprint arXiv:2404.05868 (2024)
Zhang, R., Lin, L., Bai, Y., Mei, S.: Negative preference optimization: From catas- trophic collapse to effective unlearning. arXiv preprint arXiv:2404.05868 (2024)
Pith/arXiv arXiv 2024
-
[16]
arXiv preprint arXiv:2511.08567 (2025)
Zhu, H., Zhang, Z., Huang, H., et al.: The path not taken: RLVR provably learns off the principals. arXiv preprint arXiv:2511.08567 (2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.