CodeSentinel: A Three-Layer Defense Against Indirect Prompt Injection in Code Contexts
Pith reviewed 2026-06-26 20:13 UTC · model grok-4.3
The pith
CodeSentinel uses a three-layer sanitizer to detect and neutralize indirect prompt injections in code contexts for LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
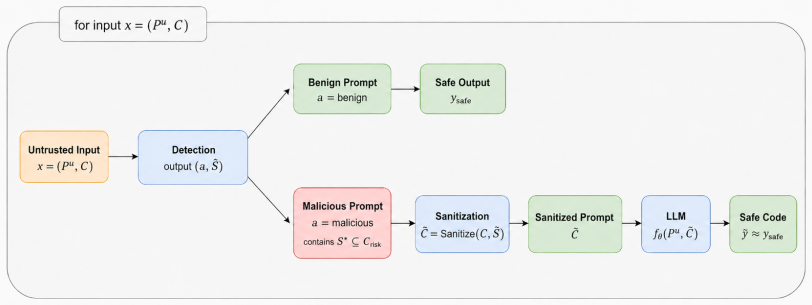
We propose CodeSentinel, a three-layer inference-time sanitizer. It uses Tree-sitter to extract high-risk model-facing CST nodes, then combines syntax-guided pre-filtering, CST-guided Dynamic Min-K% scoring, and node perturbation analysis to detect adversarial and natural-looking semantic triggers. Detected nodes are removed or neutralized before reaching the downstream Code LLM.
What carries the argument
Three-layer inference-time sanitizer that extracts high-risk CST nodes with Tree-sitter and applies syntax-guided pre-filtering, CST-guided Dynamic Min-K% scoring, and node perturbation analysis to identify and sanitize triggers.
If this is right
- High-risk nodes can be isolated and removed without discarding the entire code context.
- The approach covers attacks hidden in comments, strings, identifiers, and decoy code from various retrieval sources.
- Node-level intervention leaves most of the original code available to the model.
- The defense operates at inference time without requiring retraining of the downstream LLM.
Where Pith is reading between the lines
- The syntax-tree focus could be extended to other structured data like configuration files or markup that LLMs might retrieve.
- Future attacks designed to mimic benign code structure more closely would require updates to the scoring or perturbation steps.
- The method's precision on individual nodes suggests it could pair with existing static analysis tools for layered security in coding environments.
Load-bearing premise
The combination of Tree-sitter node extraction with the three detection methods will catch both obvious adversarial and subtle natural-looking triggers without too many false positives or misses.
What would settle it
A collection of new attack examples that embed instructions while evading all three layers, or a large body of clean code that triggers frequent false detections and removals.
Figures








read the original abstract
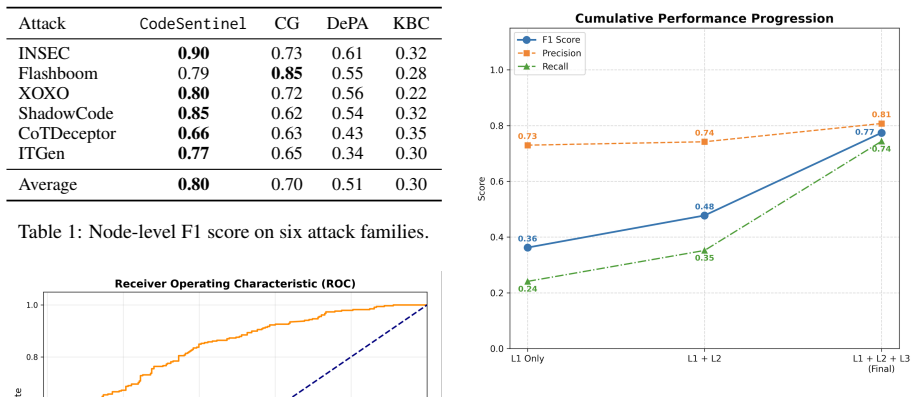
Code large language models increasingly retrieve external code context from repositories, documentation, issue threads, and coding-agent environments, creating an indirect prompt-injection surface where attackers hide instructions in comments, strings, identifiers, or decoy code. We propose CodeSentinel, a three-layer inference-time sanitizer. It uses Tree-sitter to extract high-risk model-facing CST nodes, then combines syntax-guided pre-filtering, CST-guided Dynamic Min-K\% scoring, and node perturbation analysis to detect adversarial and natural-looking semantic triggers. Detected nodes are removed or neutralized before reaching the downstream Code LLM. Across six recent attack families, \CodeSentinel achieves 0.80 average node-level F1, outperforming CodeGarrison, DePA, and KillBadCode.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CodeSentinel, a three-layer inference-time sanitizer for defending Code LLMs against indirect prompt injection attacks hidden in external code contexts (comments, strings, identifiers). The layers consist of Tree-sitter extraction of high-risk CST nodes, syntax-guided pre-filtering, CST-guided Dynamic Min-K% scoring, and node perturbation analysis; detected nodes are removed or neutralized. The central empirical claim is that this pipeline achieves 0.80 average node-level F1 across six recent attack families and outperforms the baselines CodeGarrison, DePA, and KillBadCode.
Significance. If the evaluation protocol and results can be substantiated, the work addresses a timely and practically relevant security threat to code-generating LLMs that retrieve untrusted context. The combination of static CST analysis with dynamic scoring and perturbation offers a concrete, deployable defense strategy at inference time.
major comments (2)
- [Abstract] Abstract: The central performance claim (0.80 average node-level F1 across six attack families, outperforming named baselines) is presented without any accompanying dataset description, attack-family definitions, node-labeling protocol, false-positive measurement on clean code, exact Dynamic Min-K% formulation, perturbation procedure, or ablation isolating each layer. This absence renders the empirical result impossible to assess or reproduce.
- No section, table, or appendix supplies the experimental setup required to support the weakest assumption (that the three-layer pipeline reliably separates adversarial triggers from natural semantic code without excessive false positives). Without these elements the soundness of the 0.80 F1 figure cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the experimental protocol. We agree that the current manuscript does not provide sufficient detail on datasets, attack definitions, labeling, false-positive evaluation, scoring formulation, perturbation, and ablations to allow full assessment or reproduction of the 0.80 F1 result. We will perform a major revision to supply these elements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim (0.80 average node-level F1 across six attack families, outperforming named baselines) is presented without any accompanying dataset description, attack-family definitions, node-labeling protocol, false-positive measurement on clean code, exact Dynamic Min-K% formulation, perturbation procedure, or ablation isolating each layer. This absence renders the empirical result impossible to assess or reproduce.
Authors: We accept this criticism. The abstract is intentionally concise and therefore omits these details. In the revised manuscript we will expand the abstract with a brief parenthetical reference to the evaluation protocol and will ensure the main text and a new appendix contain the requested information (dataset sources and statistics, attack-family definitions with examples, node-labeling rules, clean-code false-positive rates, the precise Dynamic Min-K% formula, perturbation steps, and layer-wise ablations). revision: yes
-
Referee: [—] No section, table, or appendix supplies the experimental setup required to support the weakest assumption (that the three-layer pipeline reliably separates adversarial triggers from natural semantic code without excessive false positives). Without these elements the soundness of the 0.80 F1 figure cannot be evaluated.
Authors: We agree that the current version does not contain a self-contained experimental-setup section or appendix with the listed elements. The revision will add a dedicated Experimental Setup section (with subsections on data collection, attack families, labeling protocol, and metrics) plus an appendix containing the exact Dynamic Min-K% formulation, perturbation procedure, clean-code false-positive measurements, and ablation tables. These additions will directly address the concern about false positives on natural code. revision: yes
Circularity Check
No circularity: empirical performance claim with no derivations or self-referential reductions
full rationale
The paper presents CodeSentinel as a three-layer inference-time sanitizer using Tree-sitter CST extraction, syntax pre-filtering, Dynamic Min-K% scoring, and perturbation analysis, then reports an empirical result (0.80 average node-level F1 across six attack families). No equations, parameter-fitting steps, predictions derived from fitted inputs, uniqueness theorems, or self-citations appear in the provided abstract or described structure. The central claim is a direct experimental outcome rather than a derivation that reduces to its own inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Systems and Software , volume =
Poisoned source code detection in code models , author =. Journal of Systems and Software , volume =
-
[2]
Tsai, Chi-Chien and Yu, Chia-Mu and Lin, Ying-Dar and Wu, Yu-Sung and Lee, Wei-Bin , year =. Beyond
-
[3]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[4]
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems , url =
Liu, Tianyang and Xu, Canwen and McAuley, Julian , booktitle =. RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems , url =
-
[5]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[6]
Iterative
Huang, Li and Sun, Weifeng and Yan, Meng , year =. Iterative. 2025
2025
-
[7]
Štorek, Adam and Gupta, Mukur and Bhatt, Noopur and Gupta, Aditya and Kim, Janie and Srivastava, Prashast and Jana, Suman , year =
-
[8]
Jenko, Slobodan and Mündler, Niels and He, Jingxuan and Vero, Mark and Vechev, Martin , year =. Black-
-
[9]
Sun, Weisong and Chen, Yuchen and Yuan, Mengzhe and Fang, Chunrong and Chen, Zhenpeng and Wang, Chong and Liu, Yang and Xu, Baowen and Chen, Zhenyu , year =. Show
-
[10]
Liu, Yue and Zhao, Yanjie and Lyu, Yunbo and Zhang, Ting and Wang, Haoyu and Lo, David , year =. "
-
[11]
and Yu, Tianjiao and Diwan, Nirav and Wang, Gang and Hakkani-Tür, Dilek and Lourentzou, Ismini , year =
Wahed, Muntasir and Zhou, Xiaona and Nguyen, Kiet A. and Yu, Tianjiao and Diwan, Nirav and Wang, Gang and Hakkani-Tür, Dilek and Lourentzou, Ismini , year =
-
[12]
Yang, Yuchen and Li, Yiming and Yao, Hongwei and Yang, Bingrun and He, Yiling and Zhang, Tianwei and Tao, Dacheng and Qin, Zhan , year =
-
[13]
2026 , eprint=
Indirect Prompt Injection in the Wild: An Empirical Study of Prevalence, Techniques, and Objectives , author=. 2026 , eprint=
2026
-
[14]
I njec A gent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel. I njec A gent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. Findings of the Association for Computational Linguistics: ACL 2024. 2024
2024
-
[15]
ACM SIGKDD Conference on Knowledge Discovery and Data Mining , author =
Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models , url =. ACM SIGKDD Conference on Knowledge Discovery and Data Mining , author =
-
[16]
Defending against Indirect Prompt Injection by Instruction Detection , url =
Wen, Tongyu and Wang, Chenglong and Yang, Xiyuan and Tang, Haoyu and Xie, Yueqi and Lyu, Lingjuan and Dou, Zhicheng and Wu, Fangzhao , year =. Defending against Indirect Prompt Injection by Instruction Detection , url =
-
[17]
Chen, Yulin and Li, Haoran and Sui, Yuan and He, Yufei and Liu, Yue and Song, Yangqiu and Hooi, Bryan , year =. Can. Annual Meeting of the Association for Computational Linguistics , url =
-
[18]
Liu, Mickel and Jiang, Liwei and Liang, Yancheng and Du, Simon Shaolei and Choi, Yejin and Althoff, Tim and Jaques, Natasha , year =. Chasing
-
[19]
UniGuardian: A Unified Defense for Detecting Prompt Injection, Backdoor Attacks and Adversarial Attacks in Large Language Models , url =
Lin, Huawei and Lao, Yingjie and Geng, Tong and Yu, Tan and Zhao, Weijie , year =. UniGuardian: A Unified Defense for Detecting Prompt Injection, Backdoor Attacks and Adversarial Attacks in Large Language Models , url =
-
[20]
Smoke and
Ouyang, Sheng and Qin, Yihao and Lin, Bo and Chen, Liqian and Mao, Xiaoguang and Wang, Shangwen , year =. Smoke and
-
[21]
Jiao, Yang and Wang, Xiaodong and Yang, Kai , year =
-
[22]
Li, Haoyang and Gao, Huan and Zhao, Zhiyuan and Lin, Zhiyu and Gao, Junyu and Li, Xuelong , year =
-
[23]
Li, Haoyang and Li, Mingjin and Zuo, Jinxin and Li, Siqi and Li, Xiao and Wu, Hao and Lu, Yueming and He, Xiaochuan , year =
-
[24]
ACM Conference on Computer and Communications Security (CCS) , author =
-
[25]
Chen, Sizhe and Piet, Julien and Sitawarin, Chawin and Wagner, David , year =
-
[26]
Defeating
Debenedetti, Edoardo and Shumailov, Ilia and Fan, Tianqi and Hayes, Jamie and Carlini, Nicholas and Fabian, Daniel and Kern, Christoph and Shi, Chongyang and Terzis, Andreas and Tramèr, Florian , year =. Defeating
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.