Explaining Attention with Program Synthesis
Pith reviewed 2026-06-30 10:17 UTC · model grok-4.3
The pith
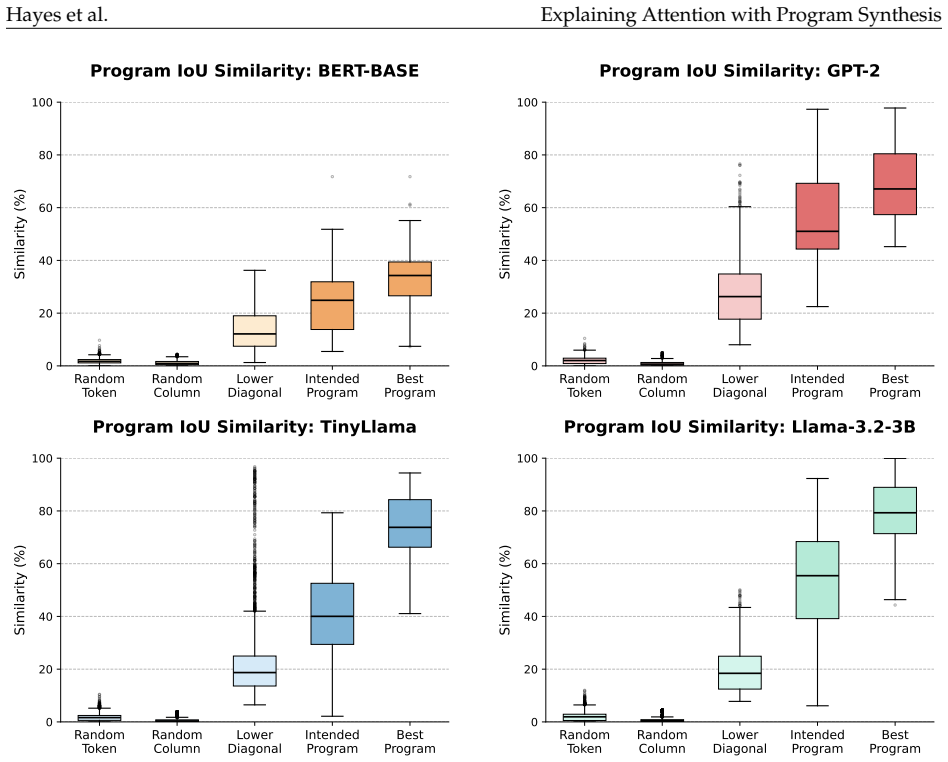
Fewer than 1,000 synthesized Python programs can reproduce attention patterns in GPT-2, TinyLlama, and Llama models at over 75% IoU while allowing replacement of 25% of heads with only 16% perplexity increase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
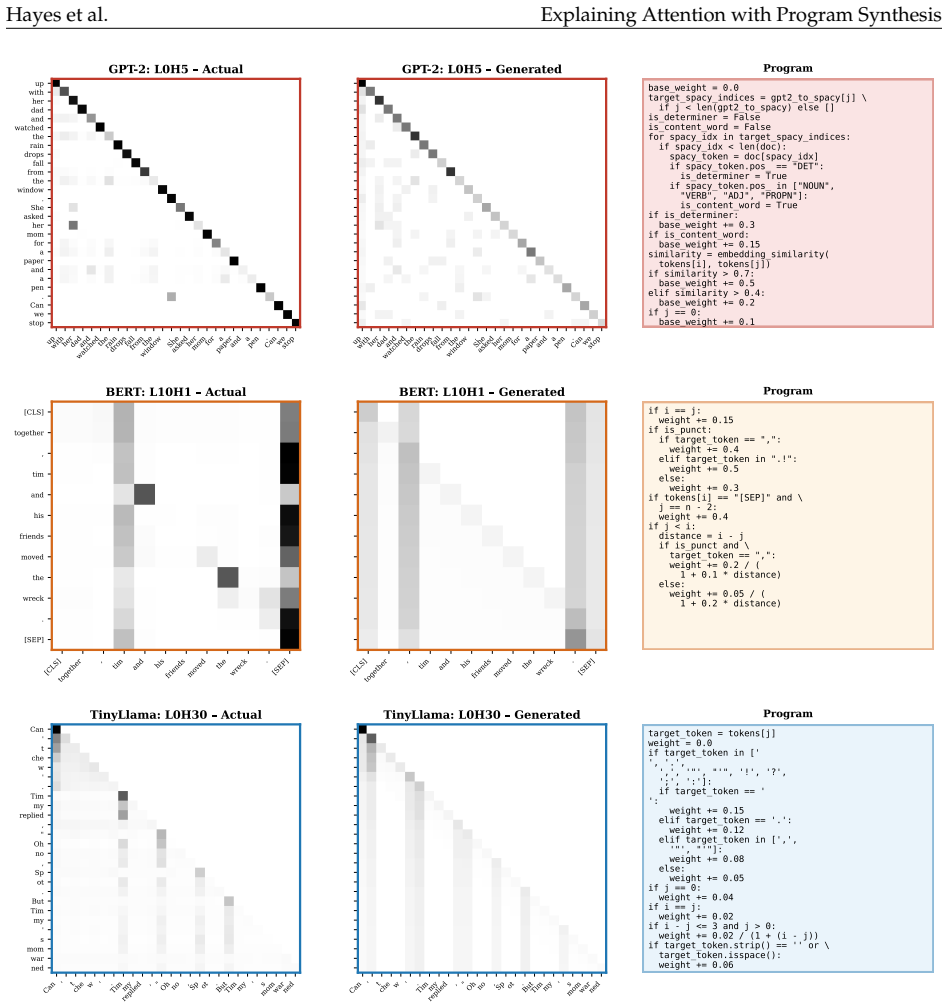
We demonstrate that a set of fewer than 1,000 such generated programs can reproduce the attention patterns of heads in GPT-2, TinyLlama-1.1B, and Llama-3B, achieving an average Intersection-over-Union similarity above 75% on TinyStories. Moreover, the best-fit programs can replace neural attention heads without substantially affecting model behavior: replacing 25% of attention heads with programmatic surrogates across the three models incurs only a 16% average perplexity increase, while maintaining performance on a variety of downstream question answering benchmarks.
What carries the argument
The synthesis pipeline that summarizes attention matrices from training examples, prompts a pre-trained LM to generate Python programs reproducing those patterns from input text, and re-ranks candidates by held-out prediction accuracy.
If this is right
- Attention heads can be swapped for code surrogates while preserving most of the model's next-token prediction behavior.
- A modest number of programs suffices to cover the observed patterns across multiple model scales.
- The same pipeline produces surrogates that keep downstream question-answering accuracy intact.
- Symbolic replacements are feasible for at least one quarter of heads without retraining the rest of the network.
Where Pith is reading between the lines
- The method could be applied to synthesize programs for other transformer components such as feed-forward layers.
- Common program structures across heads might reveal reusable motifs in how attention selects information.
- Hybrid models mixing neural and programmatic heads could allow targeted editing or verification of specific behaviors.
- Extending the synthesis prompt with more diverse examples might reduce the number of programs needed per head.
Load-bearing premise
Attention matrices from a modest set of randomly chosen training examples, once summarized, contain enough information for the generated programs to match the original head on new inputs.
What would settle it
Applying the final programs to a fresh dataset drawn from a different distribution and finding that average IoU similarity falls substantially below 75% or that replacement causes perplexity to rise far above 16%.
Figures






read the original abstract
A longstanding goal of research on interpretable deep learning is to replace opaque neural computations with human-meaningful symbolic descriptions. In this paper, we propose an approach for approximating the behavior of components of deep networks with executable programs. We focus on attention heads in transformer language models. For a given head, we first compute its associated attention matrices on a collection of randomly selected training examples. Next, we prompt a pre-trained language model with a summary of these matrices, and instruct it to generate a set of Python programs that can reproduce the associated attention patterns given only text from the input sentence. Finally, we re-rank programs according to how well our final set of programs predict behavior on held-out inputs. We demonstrate that a set of fewer than 1,000 such generated programs can reproduce the attention patterns of heads in GPT-2, TinyLlama-1.1B, and Llama-3B, achieving an average Intersection-over-Union similarity above 75% on TinyStories. Moreover, the best-fit programs can replace neural attention heads without substantially affecting model behavior: replacing 25% of attention heads with programmatic surrogates across the three models incurs only a 16% average perplexity increase, while maintaining performance on a variety of downstream question answering benchmarks. This work contributes a scalable pipeline for reverse-engineering attention heads in transformer models using human-readable, executable code, advancing a path toward symbolic transparency in neural models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a pipeline to approximate transformer attention heads with executable Python programs: attention matrices are computed on random training examples, summarized, and used to prompt an LM to synthesize candidate programs; programs are re-ranked on held-out inputs. The central empirical claim is that fewer than 1,000 such programs reproduce attention patterns of heads in GPT-2, TinyLlama-1.1B and Llama-3B at >75% average IoU on TinyStories held-out data, and that replacing 25% of heads with the best-fit programs raises perplexity by only 16% on average while preserving downstream QA performance.
Significance. If the quantitative results are reproducible and the programs truly generalize beyond the sampled examples, the work supplies a concrete, scalable route from opaque attention matrices to human-readable, executable surrogates. The replacement experiments (full-model perplexity and QA benchmarks) are a strength, as is the use of held-out data for program selection. The approach could materially advance mechanistic interpretability if the summary step preserves the token-level dependencies that determine attention weights.
major comments (3)
- [Abstract] Abstract: the reported 75% IoU and 16% perplexity figures are given without error bars, exact numbers of examples used for summarization or evaluation, or any ablation on summary construction; these omissions make it impossible to assess whether the numbers support the claim that the programs are faithful drop-in replacements rather than artifacts of the particular sample.
- [Method (summary construction)] The load-bearing step is the construction of the 'summary of these matrices' that is fed to the program-synthesis LM. If the summary is lossy (e.g., averages, qualitative descriptors, or aggregated statistics), programs can match the sampled distribution while failing to recover the original head's token-level computation on held-out inputs; the manuscript must specify the exact summary format and demonstrate that it is informationally sufficient for generalization.
- [Replacement experiments] The replacement experiment replaces 25% of heads yet reports only average perplexity increase; without per-head or per-layer breakdowns, or controls that replace heads with random or constant programs, it is unclear whether the modest degradation is due to the quality of the synthesized programs or to the redundancy already present in the original model.
minor comments (2)
- [Abstract / Experiments] Clarify the exact number of random training examples used to compute the attention matrices and the size of the held-out set used for re-ranking.
- [Method] Provide the precise prompt template and any few-shot examples given to the synthesis LM so that the program-generation step is reproducible.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below and indicate revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 75% IoU and 16% perplexity figures are given without error bars, exact numbers of examples used for summarization or evaluation, or any ablation on summary construction; these omissions make it impossible to assess whether the numbers support the claim that the programs are faithful drop-in replacements rather than artifacts of the particular sample.
Authors: We agree that additional reporting details are needed. The revised manuscript will report mean IoU and perplexity with standard deviations across models and random seeds, specify the exact counts (200 examples for summarization, 1000 for held-out ranking), and add a brief ablation on summary variants in the appendix to demonstrate that results are robust to sampling choices. revision: yes
-
Referee: [Method (summary construction)] The load-bearing step is the construction of the 'summary of these matrices' that is fed to the program-synthesis LM. If the summary is lossy (e.g., averages, qualitative descriptors, or aggregated statistics), programs can match the sampled distribution while failing to recover the original head's token-level computation on held-out inputs; the manuscript must specify the exact summary format and demonstrate that it is informationally sufficient for generalization.
Authors: The current manuscript describes the summary at a high level in Section 3.2. We will expand this to give the precise format (tokenized examples plus extracted high-attention pattern descriptions) and add experiments testing generalization on held-out inputs containing novel token dependencies absent from the summary set, confirming that the programs recover the underlying rule rather than fitting only the sampled distribution. revision: yes
-
Referee: [Replacement experiments] The replacement experiment replaces 25% of heads yet reports only average perplexity increase; without per-head or per-layer breakdowns, or controls that replace heads with random or constant programs, it is unclear whether the modest degradation is due to the quality of the synthesized programs or to the redundancy already present in the original model.
Authors: We will add per-layer and per-model breakdowns of the perplexity changes. While the >75% held-out IoU already indicates fidelity beyond random replacement, we will include a control replacing an equal number of heads with uniform-attention programs, which produces substantially larger degradation (>100% perplexity increase), supporting that the synthesized programs preserve functionality beyond existing model redundancy. revision: partial
Circularity Check
No significant circularity; evaluation on held-out data keeps results independent of generation inputs
full rationale
The pipeline computes attention matrices on random training examples, summarizes them to prompt an LM for candidate programs, then re-ranks and evaluates those programs on held-out inputs using IoU and perplexity. Because final similarity and replacement metrics are computed on data excluded from both the summary and the generation step, the reported >75% IoU and 16% perplexity figures are not equivalent to the input summaries by construction. No equations, fitted parameters, or self-citations are described that would reduce the central claims to definitional identities or load-bearing prior results from the same authors. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention patterns produced by a transformer head on random training examples are representative enough for program synthesis to generalize.
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Language models can explain neurons in language models
Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu, and William Saunders. Language models can explain neurons in language models. OpenAI Blog, 2023
2023
-
[3]
PIQA: Reasoning about physical common- sense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. PIQA: Reasoning about physical common- sense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[4]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Cammarata, Catherine Olsson, Christopher Olah, et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023. 10 Hayes et al. Explaining Attention with Program Synthesis
2023
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. What does bert look at? an analysis of bert’s attention.arXiv preprint, June 2019. arXiv:1906.04341
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge. arXiv preprint, 2018. arXiv:1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint, 2023. arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
What is one grain of sand in the desert? analyzing individual neurons in deep nlp models
Fahim Dalvi, Nadir Durrani, Hassan Sajjad, Yonatan Belinkov, Anthony Bau, and James Glass. What is one grain of sand in the desert? analyzing individual neurons in deep nlp models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6309–6317, 2019
2019
-
[10]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2019
2019
-
[11]
Abhimanyu Dubey, Akhil Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english?arXiv preprint, 2023. arXiv:2305.07759
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Lefkowitz, Christopher Olah, et al
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Schiefer, Tristan Hume, Josh S. Lefkowitz, Christopher Olah, et al. A mathematical framework for transformer circuits.Transformer Circuits Thread, 2021
2021
-
[14]
Visualizing higher-layer features of a deep network
Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent. Visualizing higher-layer features of a deep network. Technical Report 1341, University of Montreal, 2009
2009
-
[15]
Learning transformer programs.arXiv preprint arXiv:2306.01128, 2023
Dan Friedman, Alexander Wettig, and Danqi Chen. Learning transformer programs.arXiv preprint arXiv:2306.01128, 2023
-
[16]
Causal abstraction for the inter- pretability of deep learning models
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. Causal abstraction for the inter- pretability of deep learning models. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[17]
Natural language descriptions of deep visual features.International Conference on Learning Representations (ICLR), 2022
Evan Hernandez, Sarah Schwettmann, David Bau, Teona Bagashvili, Antonio Torralba, and Jacob Andreas. Natural language descriptions of deep visual features.International Conference on Learning Representations (ICLR), 2022. arXiv preprint
2022
-
[18]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2019
2019
-
[19]
Sarthak Jain and Byron C. Wallace. Attention is not explanation.arXiv preprint, May 2019. arXiv:1902.10186
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
Can interpretation predict behavior on unseen data?arXiv preprint arXiv:2507.06445, 2025
Victoria R Li, Jenny Kaufmann, Martin Wattenberg, David Alvarez-Melis, and Naomi Saphra. Can interpretation predict behavior on unseen data?arXiv preprint arXiv:2507.06445, 2025. 11 Hayes et al. Explaining Attention with Program Synthesis
-
[21]
Eric J. Michaud, Isaac Liao, Vedang Lad, Ziming Liu, Anish Mudide, Caden Juang, Nikolay Bultakov, and Max Tegmark. Opening the AI black box: Program synthesis via mechanistic interpretability.arXiv preprint arXiv:2402.05110, 2024
-
[22]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
Compositional explanations of neurons
Jesse Mu and Jacob Andreas. Compositional explanations of neurons. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[24]
Progress measures for grokking via mechanistic interpretability.arXiv preprint, 2023
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability.arXiv preprint, 2023. arXiv:2304.14997
-
[25]
Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama
Theo X. Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama. Is self-repair a silver bullet for code generation?arXiv preprint arXiv:2306.09896, 2023
-
[26]
Language models are unsupervised multitask learners.OpenAI Blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 2019
2019
-
[27]
Social IQa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Social IQa: Commonsense reasoning about social interactions. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019
2019
-
[28]
Bert rediscovers the classical nlp pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. Bert rediscovers the classical nlp pipeline. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019
2019
-
[29]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[30]
A multiscale visualization of attention in the transformer model
Jesse Vig. A multiscale visualization of attention in the transformer model. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 2019
2019
-
[31]
The bottom-up evolution of representations in the trans- former: A study with machine translation and language modeling objectives
Elena Voita, Rico Sennrich, and Ivan Titov. The bottom-up evolution of representations in the trans- former: A study with machine translation and language modeling objectives. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019
2019
-
[32]
Analyzing multi-head self- attention: Specialized heads do the heavy lifting, the rest can be pruned
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self- attention: Specialized heads do the heavy lifting, the rest can be pruned. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 5797–5808, 2019
2019
-
[33]
Thinking like transformers
Gail Weiss, Yoav Goldberg, and Eran Yahav. Thinking like transformers. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[34]
Crowdsourcing Multiple Choice Science Questions
Johannes Welbl, Nelson F. Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. arXiv preprint, 2017. arXiv:1707.06209
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Which attention heads matter for in-context learning?arXiv preprint, February 2025
Kayo Yin and Jacob Steinhardt. Which attention heads matter for in-context learning?arXiv preprint, February 2025. arXiv:2502.14010
-
[36]
Zeiler and Rob Fergus
Matthew D. Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. InEuropean Conference on Computer Vision (ECCV), pages 818–833. Springer, 2014
2014
-
[37]
HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019
2019
-
[38]
TinyLlama: An Open-Source Small Language Model
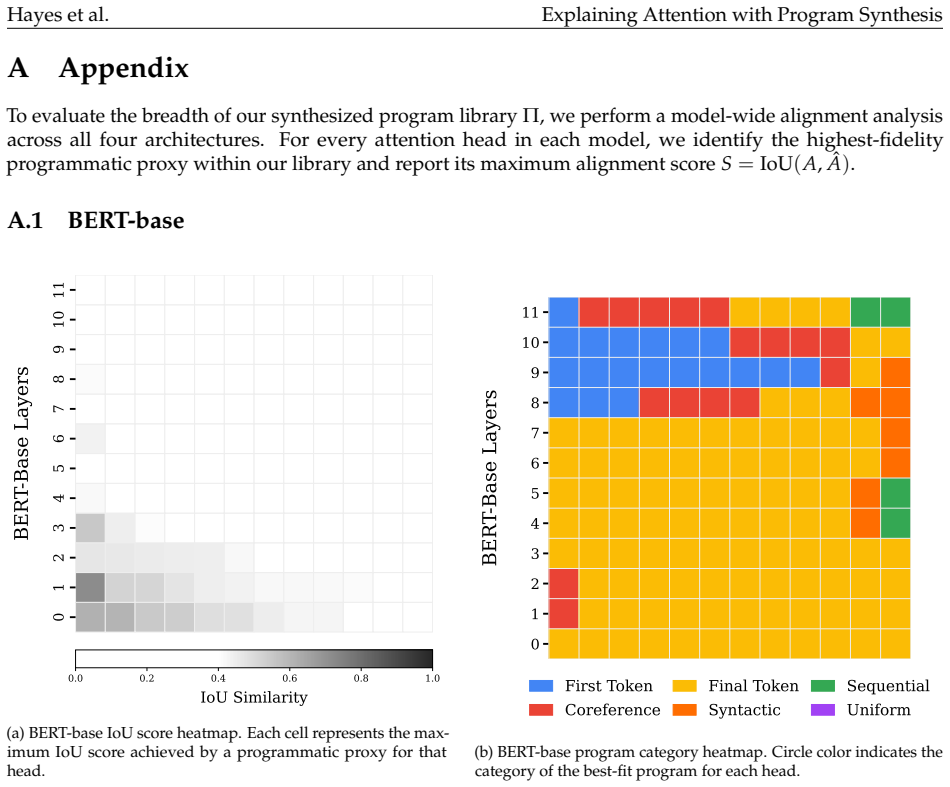
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. TinyLlama: An open-source small language model.arXiv preprint, 2024. arXiv:2401.02385. 12 Hayes et al. Explaining Attention with Program Synthesis A Appendix To evaluate the breadth of our synthesized program library Π, we perform a model-wide alignment analysis across all four architectures. For eve...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.