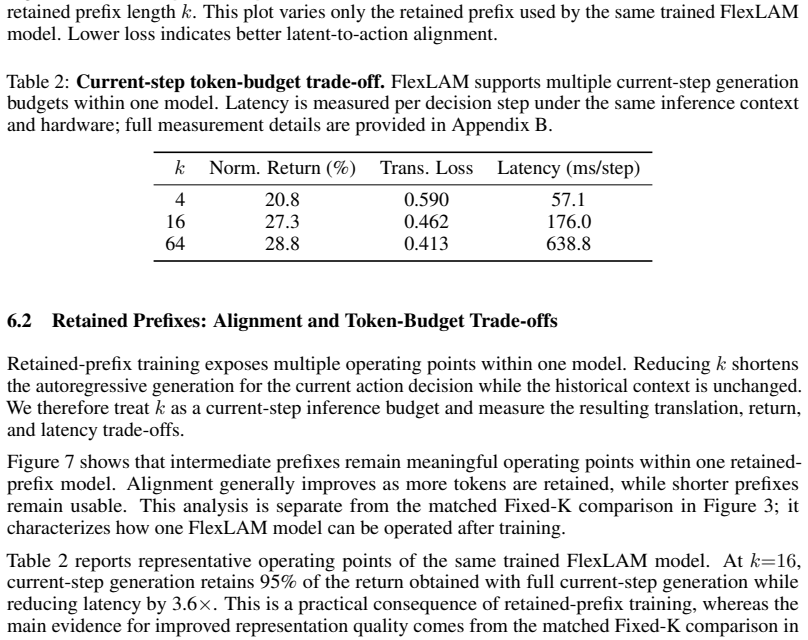
FlexLAM: Resolving the Bottleneck Trade-off in Latent Action Learning
Pith reviewed 2026-06-26 21:07 UTC · model grok-4.3
The pith
FlexLAM replaces fixed-capacity bottlenecks in latent action models with variable-length codes from nested dropout that match or exceed separate fixed models at every token budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
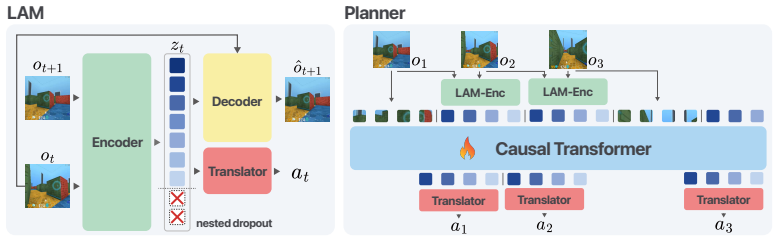
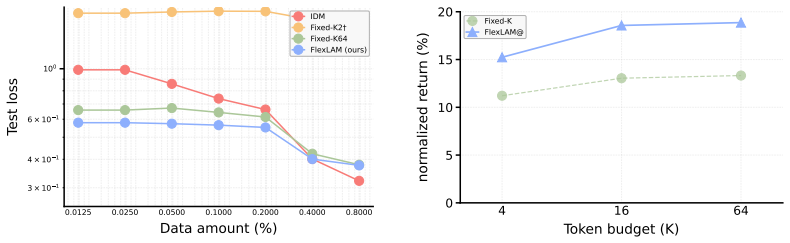
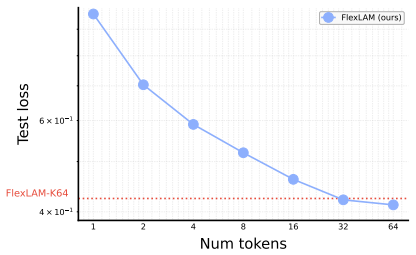
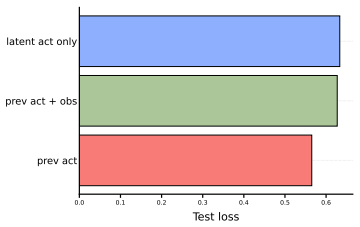
FlexLAM replaces the fixed-capacity bottleneck in latent action models with variable-length latent actions trained via nested dropout, yielding prefix-valid codes that capture compact transition structure first and add detail only when needed, without requiring new architectures or losses; a single FlexLAM matches or surpasses separately trained fixed-capacity LAMs at every evaluated token budget under scarce-label supervision and low-return alignment stress tests.
What carries the argument
Nested dropout on latent action encoders to generate prefix-valid variable-length codes that prioritize compact transition structure.
If this is right
- One trained model serves all token budgets instead of requiring separate fixed-capacity models for each budget.
- Inference-time token-budget adjustment becomes possible without retraining.
- Performance improves under scarce-label supervision and single-task alignment stress tests.
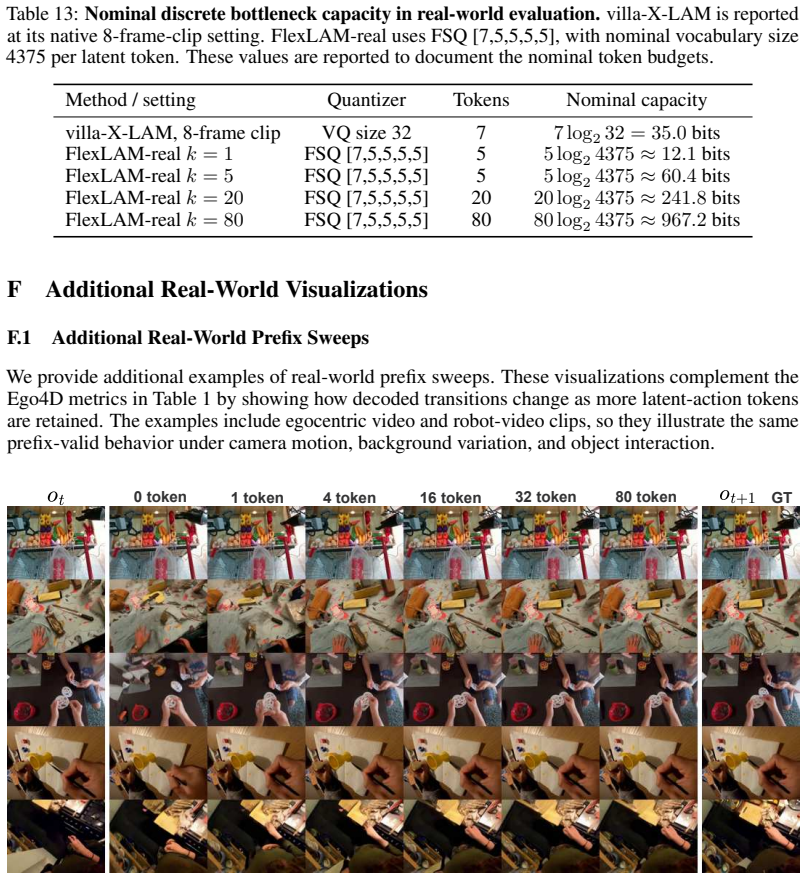
- Transition reconstruction accuracy increases on datasets such as Ego4D.
Where Pith is reading between the lines
- The approach may apply to other information-bottleneck problems in world models or sequence prediction where capacity must be chosen in advance.
- Consolidating multiple fixed models into one variable-length model could reduce total training compute for applications that need several operating points.
- If the prefix-valid property generalizes, deployment in environments with varying compute or bandwidth constraints becomes simpler.
Load-bearing premise
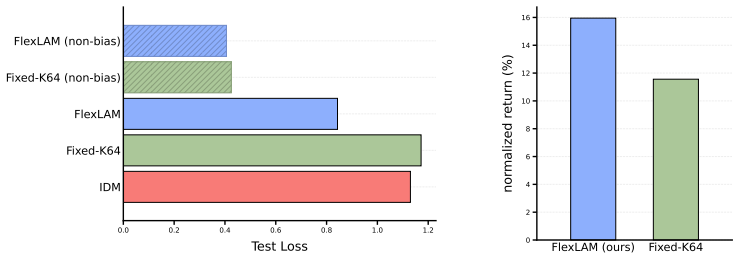
The extra tokens added by nested dropout supply transition detail that is genuinely useful for downstream alignment rather than residual variation that any comparable fixed model would ignore.
What would settle it
Train a fixed-capacity LAM at the average token length used by FlexLAM and compare it head-to-head on the same scarce-label alignment tasks; equal or superior performance would undermine the claim that the variable-length approach learns a better interface.
Figures






read the original abstract
Latent actions provide a compact interface between action-free video and downstream decision-making, yet existing Latent Action Models (LAMs) force every transition through a fixed-capacity bottleneck. We identify a bottleneck trade-off: overly tight codes can discard transition cues needed for action alignment, while overly loose codes preserve additional transition variation that must be resolved when alignment labels are scarce or narrowly distributed. FlexLAM replaces this fixed capacity with variable-length latent actions trained by nested dropout, yielding prefix-valid codes that capture compact transition structure first and add detail only when needed, without new architectures or losses. A single FlexLAM matches or surpasses separately trained fixed-capacity LAMs at every evaluated token budget under standard scarce-label supervision and under a low-return single-task alignment stress test, indicating that FlexLAM is not merely adjustable at inference time but learns a better latent-action interface at the same token budgets. The same model supports inference-time token-budget adjustment without retraining, and FlexLAM improves Ego4D transition reconstruction. These results suggest that variable-length latent actions are an architecture-free, drop-in upgrade to the fixed-capacity bottleneck in latent action models, latent-action world models, and video-pretrained action interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlexLAM, which applies nested dropout during training of latent action models (LAMs) to produce variable-length, prefix-valid latent action codes. These codes capture compact transition structure in early tokens and add detail only as needed. The central claim is that a single FlexLAM matches or surpasses separately trained fixed-capacity LAMs at every evaluated token budget under scarce-label supervision and a low-return single-task alignment stress test, improves Ego4D transition reconstruction, and supports inference-time token-budget adjustment without retraining, positioning variable-length codes as an architecture-free upgrade to the fixed bottleneck in LAMs and related video-pretrained interfaces.
Significance. If the empirical results and the assumption that nested dropout yields genuinely useful incremental structure hold, this would constitute a practical advance for latent action learning by eliminating the need to train separate models for different capacities while improving performance at matched budgets. The inference-time flexibility and lack of new losses or architectures make it a potentially drop-in improvement for downstream decision-making from action-free video.
major comments (2)
- [Abstract] Abstract: The claim that FlexLAM 'learns a better latent-action interface at the same token budgets' (rather than merely providing an adjustable code) is load-bearing for the contribution. This rests on consistent outperformance versus separately trained fixed-capacity LAMs, yet the abstract supplies no details on how token budgets are matched across models, the training protocol for the fixed baselines, or any ablation isolating whether later tokens supply alignment-useful structure beyond residual variation that a fixed model of matched average capacity would ignore.
- [Abstract] Abstract: The method description states that nested dropout yields 'prefix-valid codes that capture compact transition structure first,' but provides no formulation, loss term, or verification (e.g., no equation or procedure showing that essential transition cues are forced into early tokens while later tokens add only non-redundant detail). Without this, it remains possible that the reported gains arise from training dynamics rather than an improved interface, as noted in the stress-test concern.
minor comments (1)
- [Abstract] The abstract references 'standard scarce-label supervision' and 'Ego4D transition reconstruction' but does not name the primary datasets or tasks used for the main alignment experiments; adding these would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point by point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that FlexLAM 'learns a better latent-action interface at the same token budgets' (rather than merely providing an adjustable code) is load-bearing for the contribution. This rests on consistent outperformance versus separately trained fixed-capacity LAMs, yet the abstract supplies no details on how token budgets are matched across models, the training protocol for the fixed baselines, or any ablation isolating whether later tokens supply alignment-useful structure beyond residual variation that a fixed model of matched average capacity would ignore.
Authors: Token budgets are matched by evaluating the single FlexLAM model on its first k tokens while training separate fixed-capacity LAM baselines with a bottleneck of exactly size k, using identical data, scarce-label supervision, and optimization protocol. These details appear in Sections 3.2 and 4.1. The low-return single-task alignment stress test (Section 4.3) functions as the requested ablation, showing that later tokens supply alignment-useful structure because FlexLAM still outperforms the matched-capacity fixed model. We will revise the abstract to briefly note the matching procedure and baseline protocol. revision: yes
-
Referee: [Abstract] Abstract: The method description states that nested dropout yields 'prefix-valid codes that capture compact transition structure first,' but provides no formulation, loss term, or verification (e.g., no equation or procedure showing that essential transition cues are forced into early tokens while later tokens add only non-redundant detail). Without this, it remains possible that the reported gains arise from training dynamics rather than an improved interface, as noted in the stress-test concern.
Authors: Nested dropout is applied by randomly sampling a prefix length at each training step and zeroing all subsequent latent dimensions, using only the standard reconstruction objective with no new loss term. This is the standard formulation (referenced in the paper) that forces essential transition cues into early tokens. Verification is provided by the stress-test results (Section 4.3), where FlexLAM outperforms fixed-capacity models trained under identical dynamics, indicating the gains stem from the variable-length interface rather than dynamics alone. We will add a short parenthetical reference to the prefix-masking procedure in the abstract if length permits. revision: partial
Circularity Check
No circularity: empirical method with no derivations or load-bearing self-citations
full rationale
The paper's abstract and description present FlexLAM as a method using nested dropout on standard architectures to produce variable-length codes, with central claims resting entirely on empirical performance comparisons against fixed-capacity baselines at matched token budgets. No equations, mathematical derivations, fitted parameters renamed as predictions, or self-citation chains are described or invoked to justify the interface quality. The results are externally falsifiable via the reported experiments under scarce-label and stress-test conditions, satisfying the criteria for independent content rather than reduction by construction. This matches the reader's assessment of no equations or derivations that reduce to fitted quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Matryoshka Representation Learning , url =
Kusupati, Aditya and Bhatt, Gantavya and Rege, Aniket and Wallingford, Matthew and Sinha, Aditya and Ramanujan, Vivek and Howard-Snyder, William and Chen, Kaifeng and Kakade, Sham and Jain, Prateek and Farhadi, Ali , booktitle =. Matryoshka Representation Learning , url =
-
[2]
Proceedings of Robotics: Science and Systems , YEAR =
Chuan Wen AND Xingyu Lin AND John Ian Reyes So AND Kai Chen AND Qi Dou AND Yang Gao AND Pieter Abbeel , TITLE =. Proceedings of Robotics: Science and Systems , YEAR =
-
[3]
Bharadhwaj, Homanga and Mottaghi, Roozbeh and Gupta, Abhinav and Tulsiani, Shubham , year=. Track2Act: Predicting Point Tracks from Internet Videos Enables Generalizable Robot Manipulation , ISBN=. doi:10.1007/978-3-031-73116-7_18 , booktitle=
-
[4]
2025 , eprint=
AMPLIFY: Actionless Motion Priors for Robot Learning from Videos , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
Emergence of Human to Robot Transfer in Vision-Language-Action Models , author=. 2025 , eprint=
2025
-
[7]
Learning Universal Policies via Text-Guided Video Generation , url =
Du, Yilun and Yang, Sherry and Dai, Bo and Dai, Hanjun and Nachum, Ofir and Tenenbaum, Josh and Schuurmans, Dale and Abbeel, Pieter , booktitle =. Learning Universal Policies via Text-Guided Video Generation , url =
-
[8]
The Twelfth International Conference on Learning Representations , year=
Zero-Shot Robotic Manipulation with Pre-Trained Image-Editing Diffusion Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
2025 , eprint=
Large Video Planner Enables Generalizable Robot Control , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
Latent Diffusion Planning for Imitation Learning , author=. 2025 , eprint=
2025
-
[11]
The Fourteenth International Conference on Learning Representations , year=
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[12]
The Thirteenth International Conference on Learning Representations , year=
Latent Action Pretraining from Videos , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
9th Annual Conference on Robot Learning , year=
UniSkill: Imitating Human Videos via Cross-Embodiment Skill Representations , author=. 9th Annual Conference on Robot Learning , year=
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Chen, Yi and Ge, Yuying and Tang, Weiliang and Li, Yizhuo and Ge, Yixiao and Ding, Mingyu and Shan, Ying and Liu, Xihui , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[15]
Proceedings of Robotics: Science and Systems , YEAR =
Qingwen Bu AND Yanting Yang AND Jisong Cai AND Shenyuan Gao AND Guanghui Ren AND Maoqing Yao AND Ping Luo AND Hongyang Li , TITLE =. Proceedings of Robotics: Science and Systems , YEAR =
-
[16]
DynaMo: In-Domain Dynamics Pretraining for Visuo-Motor Control , url =
Cui, Zichen Jeff and Pan, Hengkai and Iyer, Aadhithya and Haldar, Siddhant and Pinto, Lerrel , booktitle =. DynaMo: In-Domain Dynamics Pretraining for Visuo-Motor Control , url =. doi:10.52202/079017-1069 , editor =
-
[17]
The Fourteenth International Conference on Learning Representations , year=
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[18]
2025 , eprint=
iFlyBot-VLA Technical Report , author=. 2025 , eprint=
2025
-
[19]
Proceedings of the 36th International Conference on Machine Learning , pages =
Imitating Latent Policies from Observation , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[20]
International Conference on Learning Representations , year=
Learning what you can do before doing anything , author=. International Conference on Learning Representations , year=
-
[21]
Learning to Act without Actions , url =
Schmidt, Dominik and Jiang, Minqi , booktitle =. Learning to Act without Actions , url =
-
[22]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
What Do Latent Action Models Actually Learn? , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[23]
Forty-second International Conference on Machine Learning , year=
Latent Action Learning Requires Supervision in the Presence of Distractors , author=. Forty-second International Conference on Machine Learning , year=
-
[24]
2025 , eprint=
CLAM: Continuous Latent Action Models for Robot Learning from Unlabeled Demonstrations , author=. 2025 , eprint=
2025
-
[25]
2014 , eprint=
Learning Ordered Representations with Nested Dropout , author=. 2014 , eprint=
2014
-
[26]
Stochastic Bottleneck: Rateless Auto-Encoder for Flexible Dimensionality Reduction , url=
Koike-Akino, Toshiaki and Wang, Ye , year=. Stochastic Bottleneck: Rateless Auto-Encoder for Flexible Dimensionality Reduction , url=. doi:10.1109/isit44484.2020.9174523 , booktitle=
-
[27]
2025 , eprint=
LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks , author=. 2025 , eprint=
2025
-
[28]
Kevin Black and Noah Brown and James Darpinian and Karan Dhabalia and Danny Driess and Adnan Esmail and Michael Robert Equi and Chelsea Finn and Niccolo Fusai and Manuel Y. Galliker and Dibya Ghosh and Lachy Groom and Karol Hausman and brian ichter and Szymon Jakubczak and Tim Jones and Liyiming Ke and Devin LeBlanc and Sergey Levine and Adrian Li-Bell an...
2025
-
[29]
Moo Jin Kim and Karl Pertsch and Siddharth Karamcheti and Ted Xiao and Ashwin Balakrishna and Suraj Nair and Rafael Rafailov and Ethan P Foster and Pannag R Sanketi and Quan Vuong and Thomas Kollar and Benjamin Burchfiel and Russ Tedrake and Dorsa Sadigh and Sergey Levine and Percy Liang and Chelsea Finn , booktitle=. Open. 2024 , url=
2024
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Peebles, William and Xie, Saining , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[31]
2025 , eprint=
Rethinking the shape convention of an MLP , author=. 2025 , eprint=
2025
-
[32]
Proceedings of the 41st International Conference on Machine Learning , pages =
Genie: Generative Interactive Environments , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Menapace, Willi and Lathuiliere, Stephane and Tulyakov, Sergey and Siarohin, Aliaksandr and Ricci, Elisa , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2021 , pages =
2021
-
[34]
NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
A Universal World Model Learned from Large Scale and Diverse Videos , author=. NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
2023
-
[35]
2025 , editor =
Gao, Shenyuan and Zhou, Siyuan and Du, Yilun and Zhang, Jun and Gan, Chuang , booktitle =. 2025 , editor =
2025
-
[36]
Tokenization Workshop , year=
One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression , author=. Tokenization Workshop , year=
-
[37]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Bachmann, Roman and Allardice, Jesse and Mizrahi, David and Fini, Enrico and Kar, O. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[38]
Deep learning and the information bottleneck principle
Tishby, Naftali and Zaslavsky, Noga , year=. Deep learning and the information bottleneck principle , url=. doi:10.1109/itw.2015.7133169 , booktitle=
-
[39]
Rissanen, J. , year=. Modeling by shortest data description , volume=. Automatica , publisher=. doi:10.1016/0005-1098(78)90005-5 , number=
-
[40]
2024 , eprint=
Mastering Diverse Domains through World Models , author=. 2024 , eprint=
2024
-
[41]
2026 , eprint=
Learning Latent Action World Models In The Wild , author=. 2026 , eprint=
2026
-
[42]
The Twelfth International Conference on Learning Representations , year=
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation , author=. The Twelfth International Conference on Learning Representations , year=
-
[43]
2024 , eprint=
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation , author=. 2024 , eprint=
2024
-
[44]
2025 , eprint=
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots , author=. 2025 , eprint=
2025
-
[45]
2024 , eprint=
IGOR: Image-GOal Representations are the Atomic Control Units for Foundation Models in Embodied AI , author=. 2024 , eprint=
2024
-
[46]
2018 , eprint=
DeepMind Control Suite , author=. 2018 , eprint=
2018
-
[47]
The Eleventh International Conference on Learning Representations , year=
Become a Proficient Player with Limited Data through Watching Pure Videos , author=. The Eleventh International Conference on Learning Representations , year=
-
[48]
Ego4D: Around the World in 3,000 Hours of Egocentric Video , booktitle =
Grauman, Kristen and Westbury, Andrew and Byrne, Eugene and Chavis, Zachary and Furnari, Antonino and Girdhar, Rohit and Hamburger, Jackson and Jiang, Hao and Liu, Miao and Liu, Xingyu and Martin, Miguel and Nagarajan, Tushar and Radosavovic, Ilija and Ramakrishnan, Santhosh Kumar and Ryan, Fiona and Sharma, Jayant and Wray, Michael and Xu, Mengmeng and X...
2022
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Liu, Kun and Liu, Qi and Liu, Xinchen and Li, Jie and Zhang, Yongdong and Luo, Jiebo and He, Xiaodong and Liu, Wu , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[50]
2024 , eprint=
VidGen-1M: A Large-Scale Dataset for Text-to-video Generation , author=. 2024 , eprint=
2024
-
[51]
The Thirteenth International Conference on Learning Representations , year=
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[52]
Finite Scalar Quantization:
Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen , booktitle=. Finite Scalar Quantization:. 2024 , url=
2024
-
[53]
2026 , eprint=
Co-Evolving Latent Action World Models , author=. 2026 , eprint=
2026
-
[54]
2022 , eprint=
Classifier-Free Diffusion Guidance , author=. 2022 , eprint=
2022
-
[55]
, title =
Brooks, Tim and Holynski, Aleksander and Efros, Alexei A. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[56]
Proceedings of the 41st International Conference on Machine Learning , pages =
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[57]
O’Neill, Abby and Rehman, Abdul and Maddukuri, Abhiram and Gupta, Abhishek and Padalkar, Abhishek and Lee, Abraham and Pooley, Acorn and Gupta, Agrim and Mandlekar, Ajay and Jain, Ajinkya and Tung, Albert and Bewley, Alex and Herzog, Alex and Irpan, Alex and Khazatsky, Alexander and Rai, Anant and Gupta, Anchit and Wang, Andrew and Singh, Anikait and Garg...
-
[58]
Alexander Khazatsky AND Karl Pertsch AND Suraj Nair AND Ashwin Balakrishna AND Sudeep Dasari AND Siddharth Karamcheti AND Soroush Nasiriany AND Mohan Kumar Srirama AND Lawrence Yunliang Chen AND Kirsty Ellis AND Peter David Fagan AND Joey Hejna AND Masha Itkina AND Marion Lepert AND Yecheng Jason Ma AND Patrick Tree Miller AND Jimmy Wu AND Suneel Belkhale...
-
[59]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month =
Goyal, Raghav and Ebrahimi Kahou, Samira and Michalski, Vincent and Materzynska, Joanna and Westphal, Susanne and Kim, Heuna and Haenel, Valentin and Fruend, Ingo and Yianilos, Peter and Mueller-Freitag, Moritz and Hoppe, Florian and Thurau, Christian and Bax, Ingo and Memisevic, Roland , title =. Proceedings of the IEEE International Conference on Comput...
-
[60]
Proceedings of Robotics: Science and Systems , YEAR =
Kevin Black AND Noah Brown AND Danny Driess AND Adnan Esmail AND Michael Robert Equi AND Chelsea Finn AND Niccolo Fusai AND Lachy Groom AND Karol Hausman AND Brian Ichter AND Szymon Jakubczak AND Tim Jones AND Liyiming Ke AND Sergey Levine AND Adrian Li-Bell AND Mohith Mothukuri AND Suraj Nair AND Karl Pertsch AND Lucy Xiaoyang Shi AND Laura Smith AND Jam...
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wang, Limin and Huang, Bingkun and Zhao, Zhiyu and Tong, Zhan and He, Yinan and Wang, Yi and Wang, Yali and Qiao, Yu , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[62]
Neural Rate Control for Learned Video Compression , url =
zhang, yiwei and Lu, Guo and Chen, Yunuo and Wang, Shen and Shi, Yibo and Wang, Jing and Song, Li , booktitle =. Neural Rate Control for Learned Video Compression , url =
-
[63]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =
Fathima, Noor and Petersen, Jens and Sauti\`ere, Guillaume and Wiggers, Auke and Pourreza, Reza , title =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =. 2023 , pages =
2023
-
[64]
2025 , eprint=
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems , author=. 2025 , eprint=
2025
-
[65]
2021 , eprint=
The Distracting Control Suite -- A Challenging Benchmark for Reinforcement Learning from Pixels , author=. 2021 , eprint=
2021
-
[66]
Scalable rate control for MPEG-4 video , volume=
Hung-Ju Lee and Tihao Chiang and Ya-Qin Zhang , year=. Scalable rate control for MPEG-4 video , volume=. IEEE Transactions on Circuits and Systems for Video Technology , publisher=. doi:10.1109/76.867926 , number=
-
[67]
2016 , eprint=
DeepMind Lab , author=. 2016 , eprint=
2016
-
[68]
The Eleventh International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. The Eleventh International Conference on Learning Representations , year=
-
[69]
2026 , eprint=
OAT: Ordered Action Tokenization , author=. 2026 , eprint=
2026
-
[70]
2026 , url=
Junhong Shen and Kushal Tirumala and Michihiro Yasunaga and Ishan Misra and Luke Zettlemoyer and LILI YU and Chunting Zhou , booktitle=. 2026 , url=
2026
-
[71]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[72]
and Shechtman, Eli and Wang, Oliver , title =
Zhang, Richard and Isola, Phillip and Efros, Alexei A. and Shechtman, Eli and Wang, Oliver , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[73]
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation , url=
Wang, Zhouxia and Yuan, Ziyang and Wang, Xintao and Li, Yaowei and Chen, Tianshui and Xia, Menghan and Luo, Ping and Shan, Ying , year=. MotionCtrl: A Unified and Flexible Motion Controller for Video Generation , url=. doi:10.1145/3641519.3657518 , booktitle=
-
[74]
2023 , eprint=
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory , author=. 2023 , eprint=
2023
-
[75]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Burgert, Ryan and Xu, Yuancheng and Xian, Wenqi and Pilarski, Oliver and Clausen, Pascal and He, Mingming and Ma, Li and Deng, Yitong and Li, Lingxiao and Mousavi, Mohsen and Ryoo, Michael and Debevec, Paul and Yu, Ning , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.