LEAP: Layer-skipping Efficiency via Adaptive Progression for Vision Transformer Distillation
Pith reviewed 2026-06-26 21:05 UTC · model grok-4.3
The pith
A curriculum that starts small vision transformers on easier intermediate teacher features before complex ones narrows the distillation gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By utilizing the teacher's intermediate feature maps as a sequence of progressively more difficult targets, the LEAP curriculum allows the student to build a foundational representation before tackling higher-level abstractions, significantly accelerating convergence through adaptive difficulty selection across various student model sizes and dataset scales.
What carries the argument
Adaptive progression curriculum that treats successive teacher layers as ordered distillation targets with early-stopping of teacher inference in initial training stages.
If this is right
- LEAP-distilled ViT-S reaches 90.1 percent accuracy on ImageNet-100, a 12.24 point gain over baseline distillation.
- On ImageNet-1K the method yields a 3.84 percent gain and raises instance retrieval by 7.75 percent on the Oxford and Paris datasets.
- Training FLOPs drop 25.1 percent and wall-clock time drops 21 percent on ImageNet-100 because teacher inference can be skipped early.
- The same curriculum works across multiple student model sizes and dataset scales without architecture changes.
Where Pith is reading between the lines
- The same ordered-layer idea might reduce the number of epochs needed in other progressive training regimes such as self-supervised pretraining.
- If intermediate features truly encode increasing abstraction, the method could be tested by measuring layer-wise task difficulty on a separate probe set before distillation begins.
- The early-stopping rule for teacher inference could be generalized to other teacher-student pairs where the teacher is much larger than the student.
Load-bearing premise
The teacher's intermediate feature maps form a natural sequence of increasing difficulty that matches what the student can usefully learn at each stage of training.
What would settle it
Training the same student-teacher pair with fixed final-layer targets from the first epoch and measuring whether convergence speed and final accuracy remain unchanged.
Figures

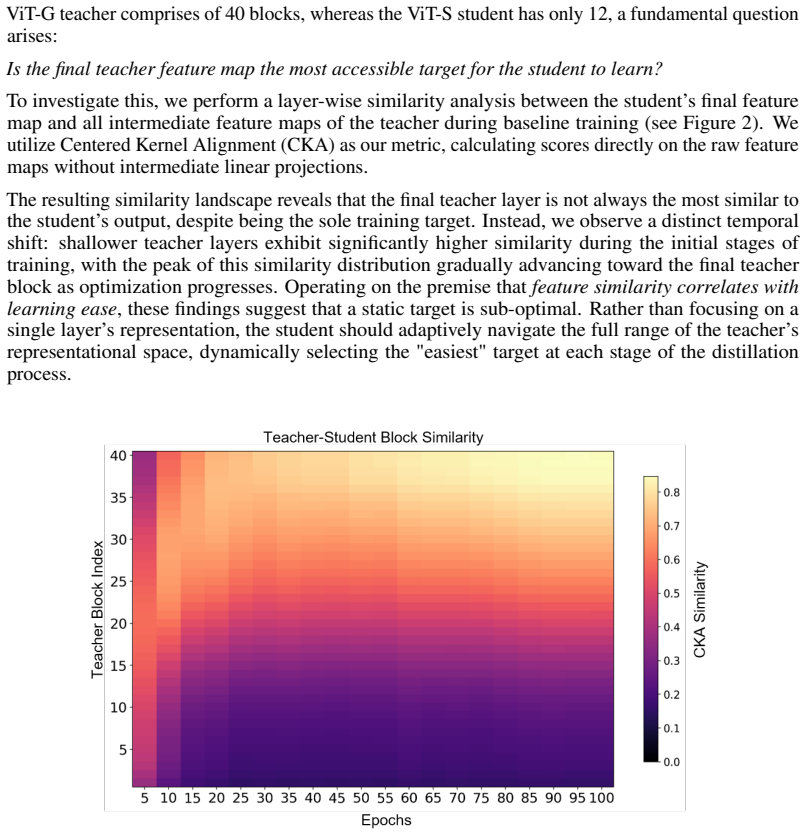
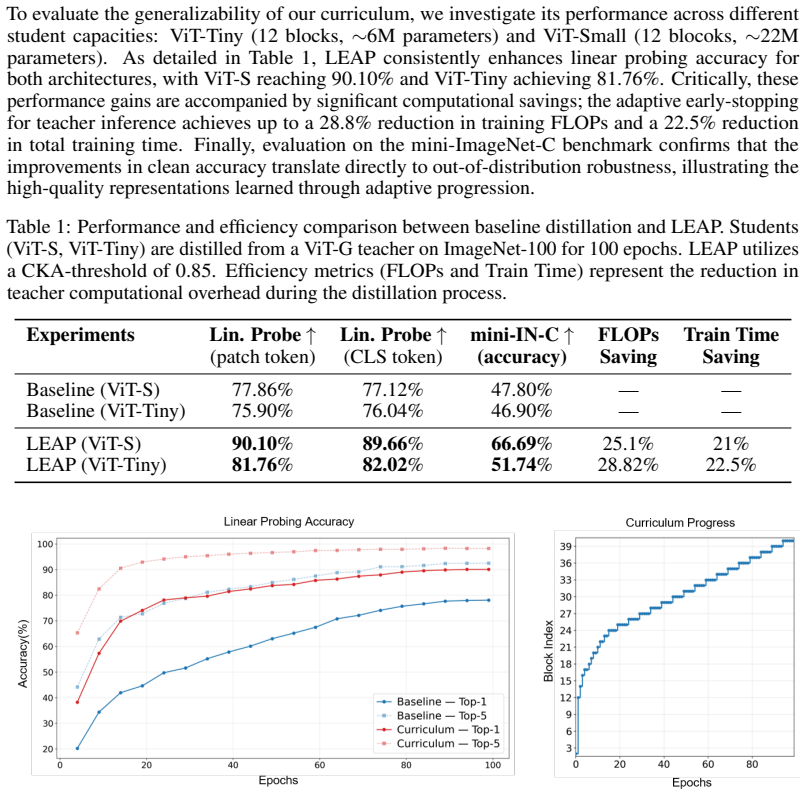



read the original abstract
Vision Foundation Models (VFMs) with Vision Transformer (ViT) backbones, such as DINOv2, have become essential for downstream tasks like object recognition and semantic segmentation. The immense computational requirements of backbones often necessitate distillation into smaller architectures for edge deployment. Feature-based knowledge distillation (KD) often suffers from the teacher-student gap; the student struggles to imitate teacher's complex feature map due to its limited capacity. To mitigate this bottleneck, we propose LEAP: Layer-skipping Efficiency via Adaptive Progression, a training curriculum for ViT feature-based knowledge distillation. By utilizing the teacher's intermediate feature maps as a sequence of progressively more difficult targets, our curriculum allows the student to build a foundational representation before tackling higher-level abstractions. Our results demonstrate that this paradigm significantly accelerates convergence through adaptive difficulty selection across various student model sizes and dataset scales. With our curriculum, the LEAP-distilled ViT-S achieves 90.1% accuracy on ImageNet-100, a +12.24% improvement compared with baseline. On ImageNet-1K, LEAP achieves +3.84% and +7.75% improvement for the instance retrieval task on the Oxford and Paris datasets, respectively. Furthermore, the curriculum enables 25.1% savings in training FLOPs and 21% savings in training time on ImageNet-100 by implementing early-stopping for teacher inference during the initial stages of training. Code is available at https://github.com/KevinZ0217/LEAP
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LEAP, a curriculum-learning approach to feature-based knowledge distillation for Vision Transformers. It treats the teacher's intermediate feature maps as an ordered sequence of progressively harder targets, combined with adaptive difficulty selection and early-stopping of teacher inference in early training stages. Reported results include +12.24% top-1 accuracy on ImageNet-100 for a ViT-S student (reaching 90.1%), +3.84% on ImageNet-1K classification, +7.75% on Paris retrieval, and 25.1% training FLOPs / 21% time savings on ImageNet-100. Code is released at the cited GitHub repository.
Significance. If the empirical gains hold under the reported protocol, the curriculum offers a lightweight, training-time-only modification that improves both accuracy and efficiency in ViT distillation without changing the loss or architecture. The explicit release of code is a positive factor for reproducibility and follow-up work on curriculum-based KD.
minor comments (3)
- [§3] §3 (Method): the precise rule or threshold used for 'adaptive difficulty selection' and layer skipping is described at a high level; adding the exact decision criterion or pseudocode would improve clarity even though code is available.
- [Table 2] Table 2 / §4.2: the baseline distillation method and hyper-parameters (temperature, loss weights, optimizer schedule) should be stated explicitly so that the +12.24% delta can be directly compared.
- [Figure 3] Figure 3: axis labels and legend entries are too small for print; increasing font size would aid readability of the convergence curves.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of LEAP and for recommending minor revision. The referee summary correctly reflects the method's curriculum design, reported gains, and efficiency benefits. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical curriculum for ViT feature distillation that orders teacher layer outputs as progressively harder targets, with results consisting of measured accuracy gains (+12.24% on ImageNet-100), retrieval improvements, and FLOPs savings from early-stopping. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the provided text. The method is presented as a practical training schedule whose effectiveness is demonstrated experimentally and is externally falsifiable via the linked code repository. This is the standard non-circular case for an applied CV methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th International Conference on Machine Learning, 2009
2009
-
[2]
Cross-layer distillation with semantic calibration
Defang Chen, Jian-Ping Mei, Yuan Zhang, Can Wang, Yan Feng, and Chun Chen. Cross-layer distillation with semantic calibration. InProceedings of the AAAI Conference on Artificial Intelligence, 2021
2021
-
[3]
On the efficacy of knowledge distillation
Jang Hyun Cho and Bharath Hariharan. On the efficacy of knowledge distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
2019
-
[4]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[5]
Maybank, and Dacheng Tao
Jianping Gou, Baosheng Yu, Stephen J. Maybank, and Dacheng Tao. Knowledge distillation: A survey.International Journal of Computer Vision, 2021
2021
-
[6]
Reducing the teacher- student gap via spherical knowledge distillation
Jia Guo, Minghao Chen, Yao Hu, Chen Zhu, Xiaofei He, and Deng Cai. Reducing the teacher- student gap via spherical knowledge distillation. InarXiv preprint arXiv:2010.07485, 2020
-
[7]
Benchmarking neural network robustness to common corruptions and perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. InInternational Conference on Learning Representations, 2019
2019
-
[8]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
Knowledge distillation via route constrained optimization
Xiao Jin, Baoyun Peng, Yichao Wu, Yu Liu, Jiaheng Liu, Ding Liang, Junjie Yan, and Xiaolin Hu. Knowledge distillation via route constrained optimization. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
2019
-
[10]
Curriculum temperature for knowledge distillation.arXiv preprint arXiv:2211.16231, 2022
Zheng Li, Xiang Li, Lingfeng Yang, Borui Zhao, Renjie Song, Lei Luo, Jun Li, and Jian Yang. Curriculum temperature for knowledge distillation.arXiv preprint arXiv:2211.16231, 2022
-
[11]
Lightlytrain, 2025
Lightly Team. Lightlytrain, 2025. URL https://github.com/lightly-ai/ lightly-train
2025
-
[12]
Ditch the denoiser: Emergence of noise robustness in self-supervised learning from data curriculum
Wenquan Lu, Jiaqi Zhang, Hugues Van Assel, and Randall Balestriero. Ditch the denoiser: Emergence of noise robustness in self-supervised learning from data curriculum. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=Pa5pKAeAO7
2025
-
[13]
Improved knowledge distillation via teacher assistant
Seyed Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, Nir Levine, Akihiro Matsukawa, and Hassan Ghasemzadeh. Improved knowledge distillation via teacher assistant. InProceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[14]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Laba...
2023
-
[15]
Relational knowledge distillation
Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho. Relational knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019
2019
-
[16]
Revisiting Oxford and Paris: Large-scale image retrieval benchmarking
Filip Radenovi´c, Ahmet Iscen, Giorgos Tolias, Yannis Avrithis, and Ondˇrej Chum. Revisiting Oxford and Paris: Large-scale image retrieval benchmarking. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[17]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. 2021. 10
2021
-
[18]
Do vision transformers see like convolutional neural networks?arXiv:2108.08810, 2021
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks?arXiv:2108.08810, 2021
-
[19]
FitNets: Hints for Thin Deep Nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets.arXiv preprint arXiv:1412.6550, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[20]
ImageNet Large Scale Visual Recognition Challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge.arXiv preprint arXiv:1409.0575, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[21]
Logit standardization in knowledge distillation.arXiv preprint arXiv:2403.01427, 2024
Shangquan Sun, Wenqi Ren, Jingzhi Li, Rui Wang, and Xiaochun Cao. Logit standardization in knowledge distillation.arXiv preprint arXiv:2403.01427, 2024
-
[22]
Patient knowledge distillation for BERT model compression
Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. Patient knowledge distillation for BERT model compression. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019
2019
-
[23]
Distillation dynamics: Towards understanding feature- based distillation in vision transformers
Huiyuan Tian, Bonan Xu, and Shijian Li. Distillation dynamics: Towards understanding feature- based distillation in vision transformers. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[24]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Douze Matthijs, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, 2021
2021
-
[25]
Matching networks for one shot learning
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. Matching networks for one shot learning. InAdvances in Neural Information Processing Systems, 2016
2016
-
[26]
Progressive blockwise knowledge distillation for neural network acceleration
Hui Wang, Hanbin Zhao, Xi Li, and Xu Tan. Progressive blockwise knowledge distillation for neural network acceleration. InProceedings of the 27th International Joint Conference on Artificial Intelligence, 2018
2018
-
[27]
Delving deep into semantic relation distillation
Zhaoyi Yan, Kangjun Liu, and Qixiang Ye. Delving deep into semantic relation distillation. arXiv preprint arXiv:2503.21269, 2025
-
[28]
Chuanguang Yang, Xinqiang Yu, Zhulin An, and Yongjun Xu. Categories of response-based, feature-based, and relation-based knowledge distillation.arXiv preprint arXiv:2306.10687, 2023
-
[29]
ViTKD: Feature-based knowledge distillation for vision transformers
Zhendong Yang, Zhe Li, Ailing Zeng, Zexian Li, Chun Yuan, and Yu Li. ViTKD: Feature-based knowledge distillation for vision transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop, 2022
2022
-
[30]
Large Batch Training of Convolutional Networks
Yang You, Igor Gitman, and Boris Ginsburg. Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Jiaqi Zhang, Juntuo Wang, Zhixin Sun, John Zou, and Randall Balestriero. FastDINOv2: Frequency based curriculum learning improves robustness and training speed.arXiv preprint arXiv:2507.03779, 2025
-
[32]
Scene parsing through ADE20K dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ADE20K dataset. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[33]
Semantic understanding of scenes through the ADE20K dataset.International Journal of Computer Vision, 127(3):302–321, 2019
Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ADE20K dataset.International Journal of Computer Vision, 127(3):302–321, 2019
2019
-
[34]
iBOT: Image BERT pre-training with online tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. iBOT: Image BERT pre-training with online tokenizer. InInternational Conference on Learning Representations, 2022
2022
-
[35]
Student customized knowledge distillation
Yizhen Zhu and Yi Wang. Student customized knowledge distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021. 11 A Technical appendices and supplementary material A.1 Linear Probing with Standard Deviation In this section, we investigate whether LEAP can perform consistently. ViT-G teacher is used to distill Vi...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.