Interactive Pareto navigation for deep multi-task learning
Pith reviewed 2026-06-26 21:06 UTC · model grok-4.3
The pith
Preference Pareto Exploration uses predictor-corrector steps to let users interactively navigate the Pareto manifold in multi-task deep learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
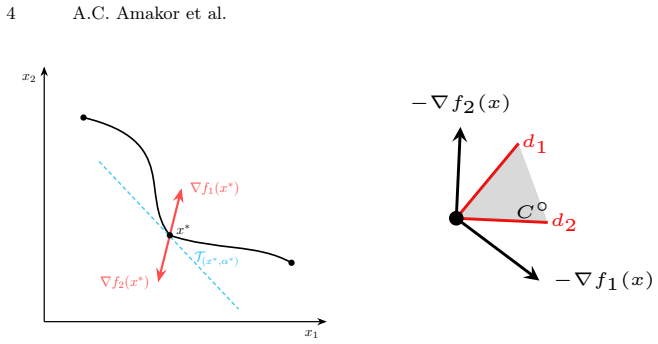
Preference Pareto Exploration (PPE) enforces the decision maker's preferences while accounting for the geometry of the Pareto set in an interactive exploration process based on a predictor-corrector method that performs predictor steps tangential to the manifold of Pareto-optimal solutions, with the corrector step producing a new trade-off. The tangent space is characterized without explicit Hessians by employing a Krylov subspace method relying on matrix-vector products from automatic differentiation.
What carries the argument
The predictor-corrector method operating on the manifold of Pareto-optimal solutions, with Krylov subspace approximation of the tangent space.
If this is right
- Decision makers can explore trade-offs interactively without repeated full optimizations.
- The method remains efficient in deep learning settings by using only first-order information.
- New solutions respect both user preferences and the shape of the Pareto front.
- Applicable to problems with many objectives where manual weighting becomes impractical.
Where Pith is reading between the lines
- This navigation could be combined with existing multi-task learning algorithms to dynamically adjust during training.
- Similar tangential exploration might apply to other constrained optimization problems in machine learning.
- Testing on larger models would show if the Krylov approximation remains stable as dimensionality grows.
Load-bearing premise
The Pareto set forms a smooth manifold and user preferences can be translated into tangential directions that the corrector can follow while staying on it.
What would settle it
Apply PPE to a deep multi-task problem with known Pareto front and verify whether the output solutions after preference updates are non-dominated or if they require many more function evaluations than claimed.
Figures

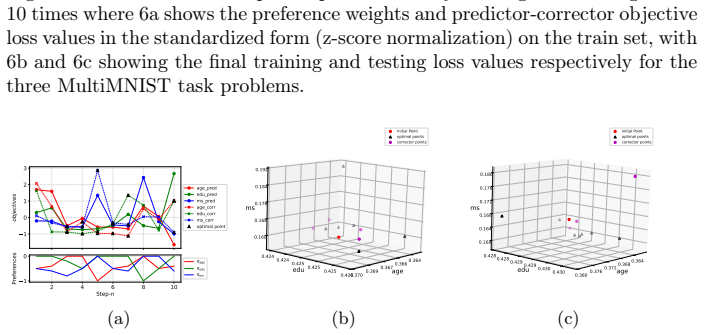
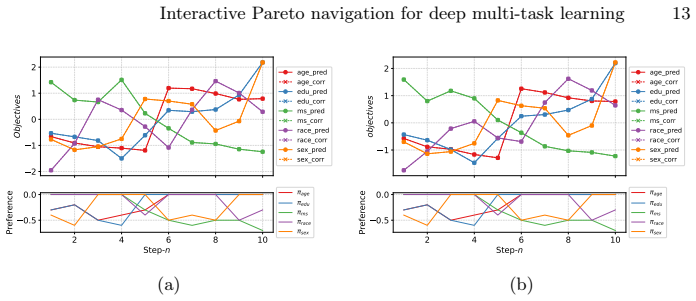
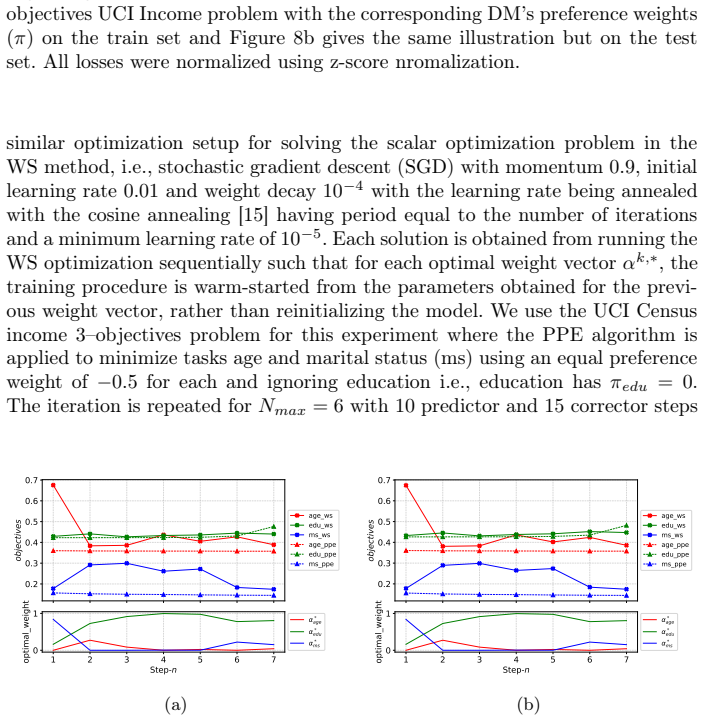
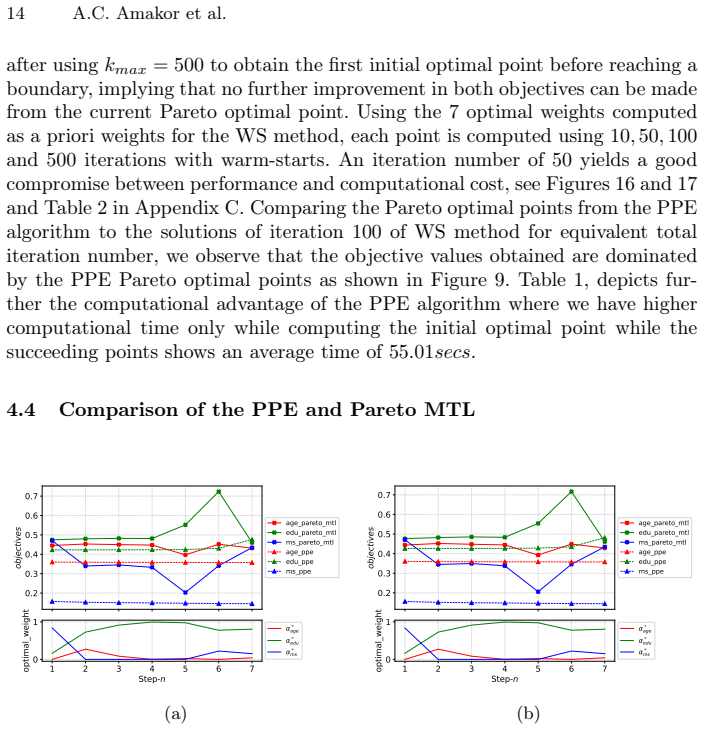
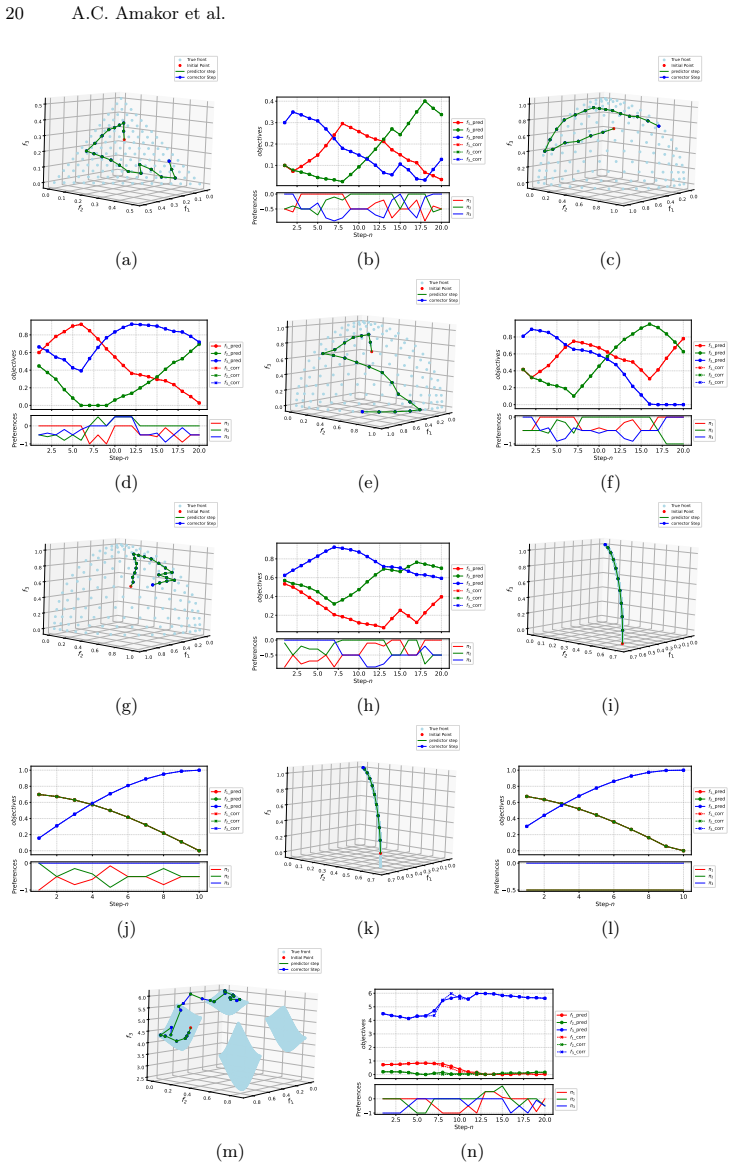
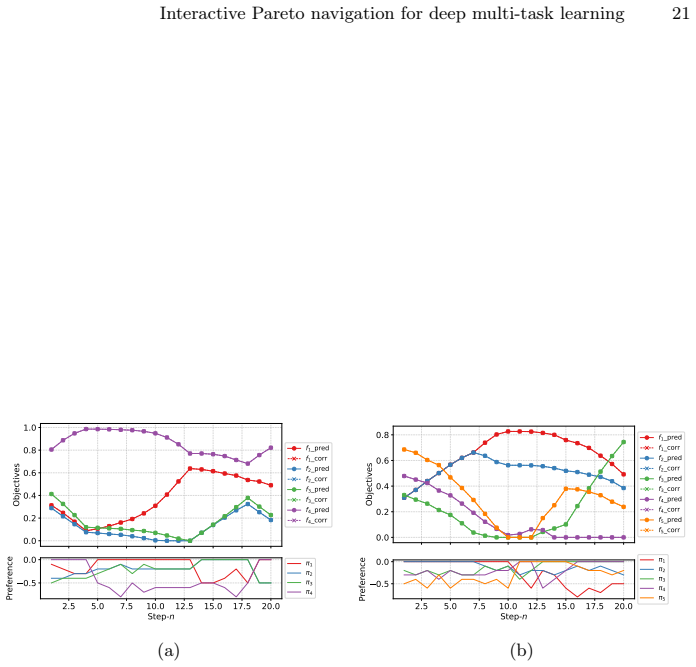
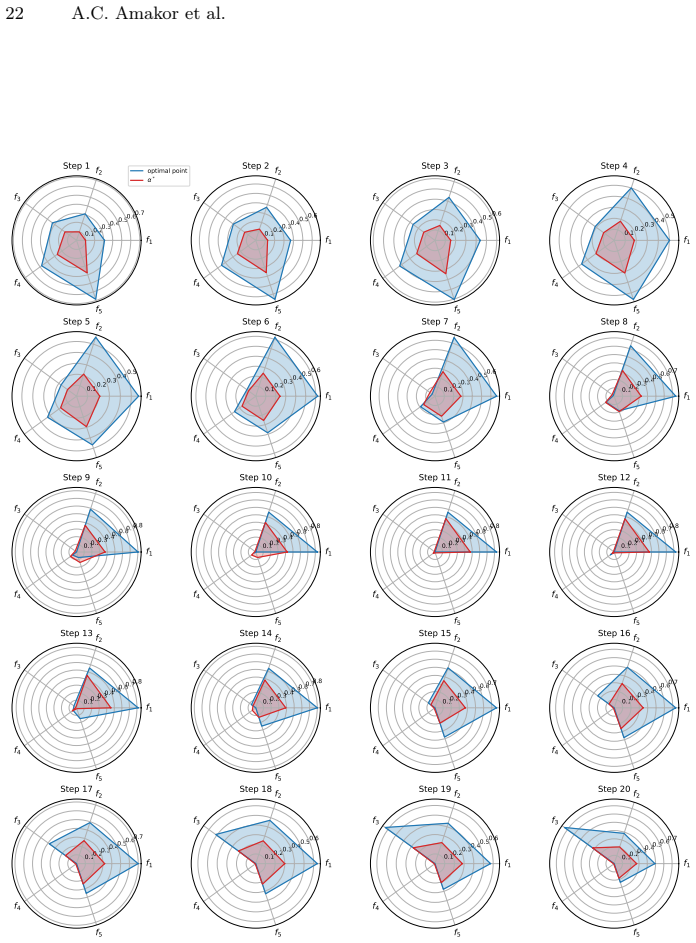
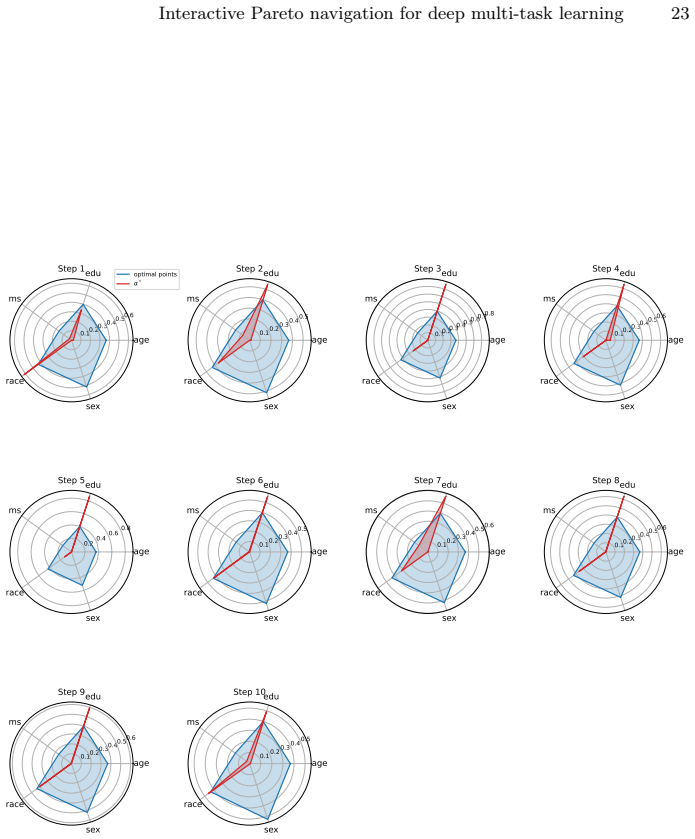
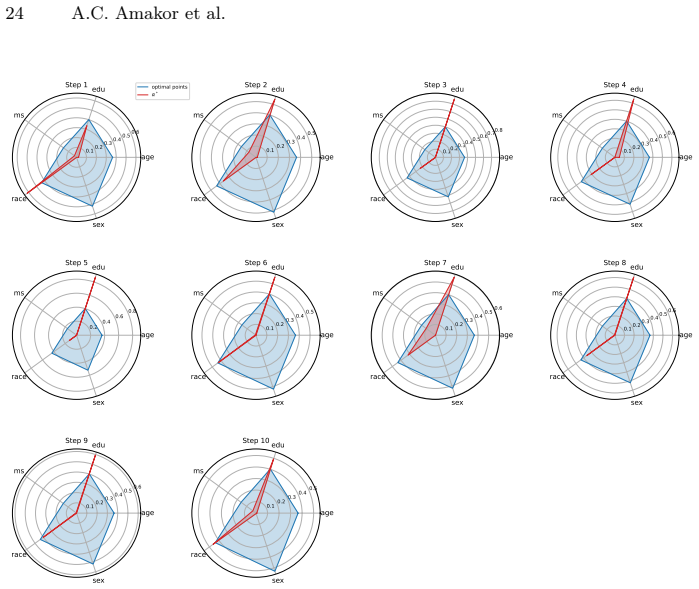
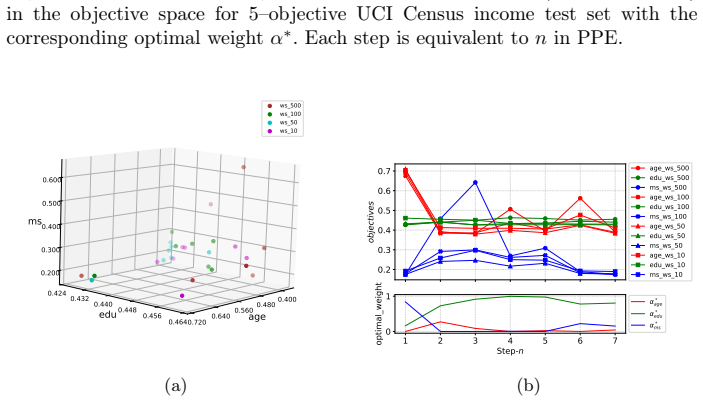
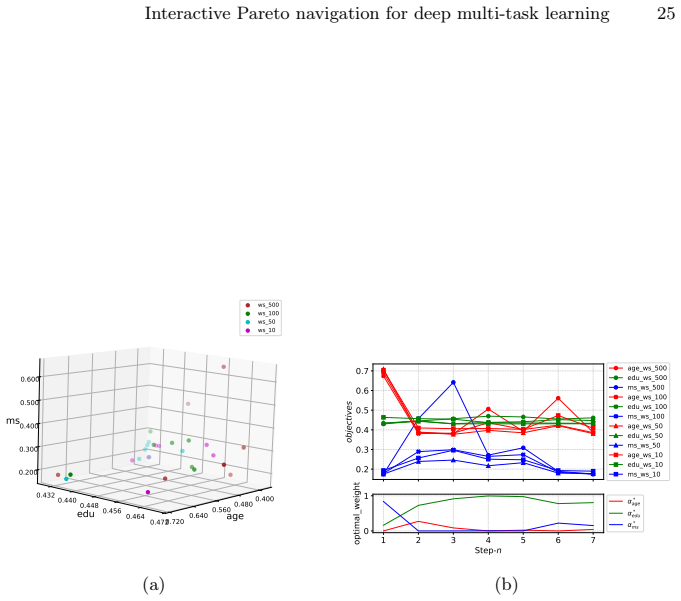
read the original abstract
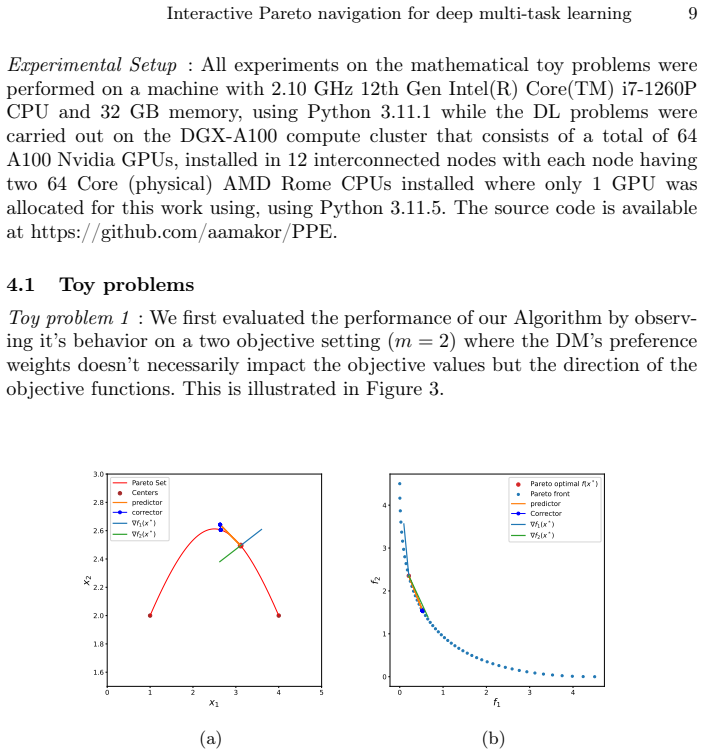
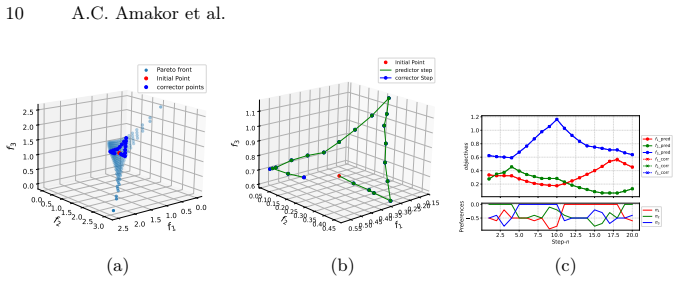
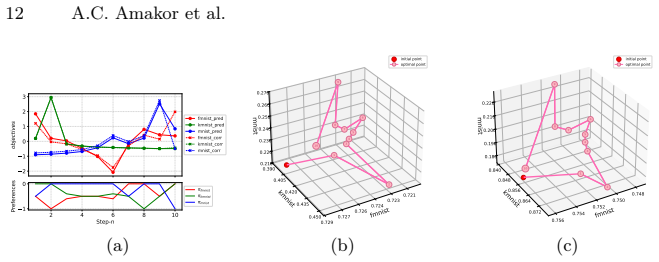
In multi-task learning, handling an increasing number of objectives can quickly become challenging, both in terms of the computational resources and the decision maker's capacity to choose appropriate trade-offs. A widely used approach is thus to aggregate the individual losses in a single loss function by a weighted sum. This often fails to capture either the decision maker's preferences as a result of the shape of the Pareto front, or requires multiple adjustments and computations which becomes prohibitively expensive in deep learning applications. To address these issues, we introduce a novel framework, Preference Pareto Exploration (PPE), which enforces the decision maker's preferences while accounting for the geometry of the Pareto set in an interactive exploration process. PPE is based on a predictor-corrector method that performs predictor steps tangential to the manifold of Pareto-optimal solutions, following the decision maker's preference. The subsequent corrector step results in a new trade-off reflecting this preference. To avoid explicit Hessian computations when characterizing the tangent space of the manifold, we employ a Krylov subspace method that relies solely on matrix-vector products. These products can be efficiently obtained via automatic differentiation, ensuring both efficiency and robustness throughout the optimization process. The method's functionality and performance are demonstrated using both toy problems and examples from deep learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Preference Pareto Exploration (PPE), an interactive predictor-corrector framework for navigating the Pareto set in multi-task learning. Predictor steps follow user preferences along the tangent space of the Pareto manifold (approximated via Krylov subspace iterations on matrix-vector products obtained by automatic differentiation, avoiding explicit Hessians), while corrector steps recover a new Pareto-optimal point reflecting the preference. The approach is motivated as more efficient than repeated weighted-sum optimizations for high-dimensional deep MTL and is illustrated on toy problems plus deep learning examples.
Significance. If the geometric assumptions hold and the method produces valid Pareto points under user-specified preferences, PPE could reduce computational cost for preference elicitation in deep multi-task settings by exploiting local manifold structure rather than global re-optimization. The use of AD-compatible Krylov methods for tangent approximation is a practical strength that avoids second-order derivatives.
major comments (2)
- [§3.2 and §4] §3.2 (Predictor step) and §4 (Manifold characterization): the construction assumes the Pareto set forms a smooth manifold whose tangent space is reliably spanned by Krylov iterations on first-order information. In non-convex deep MTL the Pareto set is typically a discrete collection of points or lower-dimensional strata with singularities; no argument or empirical check is supplied showing that a user preference vector maps to a feasible tangent whose corrector step lands on another valid Pareto point.
- [§5] §5 (Experiments): the reported toy and deep-learning examples do not include diagnostics (e.g., distance to the true Pareto set after correction, or failure rate when the manifold assumption is violated) that would test whether the predictor-corrector remains on the Pareto front under the non-convex losses typical of deep MTL.
minor comments (2)
- [Abstract and §1] The abstract and introduction repeatedly refer to 'the manifold of Pareto-optimal solutions' without a precise local definition or reference to the conditions under which such a manifold exists for non-convex vector-valued losses.
- [§3] Notation for the preference vector and the tangent-space projection is introduced without an explicit equation linking them to the Krylov solve; a single displayed equation would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting important assumptions in our PPE framework and the need for stronger experimental validation. We address each major comment below, clarifying the local nature of our method and committing to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2 and §4] §3.2 (Predictor step) and §4 (Manifold characterization): the construction assumes the Pareto set forms a smooth manifold whose tangent space is reliably spanned by Krylov iterations on first-order information. In non-convex deep MTL the Pareto set is typically a discrete collection of points or lower-dimensional strata with singularities; no argument or empirical check is supplied showing that a user preference vector maps to a feasible tangent whose corrector step lands on another valid Pareto point.
Authors: We agree that the Pareto set in non-convex deep MTL is generally not a globally smooth manifold and can exhibit singularities or discrete structure. PPE is formulated as a local predictor-corrector procedure that assumes local smoothness in a neighborhood of the current Pareto point, allowing the tangent space to be approximated via the Krylov method on first-order information from automatic differentiation. The corrector then solves a local constrained problem to recover a nearby Pareto point. We will revise §4 to explicitly articulate this local manifold assumption, invoke the implicit function theorem for local existence of the tangent space under standard regularity conditions on the objectives, and discuss step-size restrictions on the preference vector to ensure the corrector lands on a valid point. We will also add a short paragraph noting that global guarantees are not claimed. revision: partial
-
Referee: [§5] §5 (Experiments): the reported toy and deep-learning examples do not include diagnostics (e.g., distance to the true Pareto set after correction, or failure rate when the manifold assumption is violated) that would test whether the predictor-corrector remains on the Pareto front under the non-convex losses typical of deep MTL.
Authors: The current experiments demonstrate qualitative behavior on toy problems and deep MTL tasks but indeed lack quantitative diagnostics for the manifold assumption. In the revision we will extend §5 to report: (i) estimated Euclidean distance of each corrected point to the Pareto front (approximated by running multiple weighted-sum scalarizations from perturbed starting points), and (ii) the empirical success/failure rate of the corrector step across a range of preference directions, including cases where the step size violates the local-smoothness regime. These metrics will be added for both the toy and deep-learning examples. revision: yes
Circularity Check
No significant circularity detected
full rationale
The PPE framework is presented as an explicit algorithmic construction: a predictor-corrector scheme whose tangent directions are obtained from Krylov iterations on matrix-vector products supplied by automatic differentiation. No equation or claim reduces a derived quantity to a fitted parameter, a self-referential definition, or a load-bearing self-citation. The smoothness assumption on the Pareto set is introduced as a modeling premise required for the geometry to be well-defined, not as a result obtained from the method itself. All cited numerical primitives (AD, Krylov) are standard external techniques whose correctness is independent of the present paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Machine Learning with Applications19, 100625 (2025)
Amakor, A.C., Sonntag, K., Peitz, S.: A multiobjective continuation method to compute the regularization path of deep neural networks. Machine Learning with Applications19, 100625 (2025). https://doi.org/10.1016/j.mlwa.2025.100625
-
[2]
UCI Machine Learning Repository
Becker, B., Kohavi, R.: Adult (1996). https://doi.org/10.24432/C5XW20
-
[3]
Blank, J., Deb, K.: Pymoo: Multi-objective optimization in python. IEEE Access 8, 89497–89509 (2020). https://doi.org/10.1109/ACCESS.2020.2990567
-
[4]
Deep Learning for Classical Japanese Literature
Clanuwat, T., Bober-Irizar, M., Kitamoto, A., Lamb, A., Yamamoto, K., Ha, D.: Deep learning for classical japanese literature. arXiv preprint arXiv:1812.017181 (2018). https://doi.org/10.48550/ARXIV.1812.01718 16 A.C. Amakor et al
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1812.01718 2018
-
[5]
In: Proceedings of the 8th annual conference on Ge- netic and evolutionary computation
Deb, K., Sundar, J.: Reference point based multi-objective optimization using evolutionary algorithms. In: Proceedings of the 8th annual conference on Ge- netic and evolutionary computation. p. 635–642. GECCO06, ACM (Jul 2006). https://doi.org/10.1145/1143997.1144112
-
[6]
Deng, L.: The mnist database of handwritten digit images for machine learn- ing research [dataset]. IEEE Signal Processing Magazine29, 141–142 (2012). https://doi.org/\url {https://doi.org/10.1109/MSP.2012.2211477}
-
[7]
Désidéri, J.A.: Multiple-gradient descent algorithm (MGDA) for multiobjective optimization. Comptes Rendus. Mathématique350(5–6), 313–318 (Mar 2012). https://doi.org/10.1016/j.crma.2012.03.014
-
[8]
OR spectrum32, 211–227 (2010)
Eskelinen, P., Miettinen, K., Klamroth, K., Hakanen, J.: Pareto navigator for in- teractive nonlinear multiobjective optimization. OR spectrum32, 211–227 (2010)
2010
-
[9]
Filatovas, E., Kurasova, O., Redondo, J.L., Fernández, J.: A reference point-based evolutionaryalgorithmforapproximatingregionsofinterestinmultiobjectiveprob- lems. TOP28(2), 402–423 (Nov 2019). https://doi.org/10.1007/s11750-019-00535- z
-
[10]
Mathematical methods of operations research51(3), 479–494 (2000)
Fliege, J., Svaiter, B.F.: Steepest descent methods for multicriteria optimization. Mathematical methods of operations research51(3), 479–494 (2000)
2000
-
[11]
Neurocomputing228, 241–255 (Mar 2017)
Gong, D., Sun, F., Sun, J., Sun, X.: Set-based many-objective optimiza- tion guided by a preferred region. Neurocomputing228, 241–255 (Mar 2017). https://doi.org/10.1016/j.neucom.2016.09.081
-
[12]
Birkhäuser Basel, 1 edn
Hillermeier, C.: Nonlinear Multiobjective Optimization. Birkhäuser Basel, 1 edn. (2001)
2001
-
[13]
In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R
Lin, X., Zhen, H.L., Li, Z., Zhang, Q.F., Kwong, S.: Pareto multi-task learning. In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 32. Curran Associates, Inc. (2019)
2019
-
[14]
In: 2011 Seventh Interna- tional Conference on Natural Computation
Liu, G., Wu, G., Zheng, T., Ling, Q.: Integrating preference based weighted sum into evolutionary multi-objective optimization. In: 2011 Seventh Interna- tional Conference on Natural Computation. p. 1251–1255. IEEE (Jul 2011). https://doi.org/10.1109/icnc.2011.6022362
-
[15]
SGDR: Stochastic Gradient Descent with Warm Restarts
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. arXiv:1608.03983v55(2017). https://doi.org/10.48550/ARXIV.1608.03983
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1608.03983 2017
-
[16]
Omega37(2), 450–462 (Apr 2009)
Luque, M., Miettinen, K., Eskelinen, P., Ruiz, F.: Incorporating preference in- formation in interactive reference point methods for multiobjective optimization. Omega37(2), 450–462 (Apr 2009). https://doi.org/10.1016/j.omega.2007.06.001
-
[17]
In: International Conference on Machine Learning
Ma, P., Du, T., Matusik, W.: Efficient continuous pareto exploration in multi-task learning. In: International Conference on Machine Learning. pp. 6522–6531. PMLR (2020)
2020
-
[18]
Mahbub, M.S., Wagner, M., Crema, L.: Multi-objective Optimisation with Multi- ple Preferred Regions, p. 241–253. Springer International Publishing (Dec 2016). https://doi.org/10.1007/978-3-319-51691-2_21
-
[19]
Engineering Optimization50(3), 516–536 (Jun 2017)
Martín, A., Schütze, O.: Pareto tracer: a predictor–corrector method for multi- objective optimization problems. Engineering Optimization50(3), 516–536 (Jun 2017). https://doi.org/10.1080/0305215x.2017.1327579
-
[20]
Springer Nature, 1998/2012.doi: 10.1007/978-1-4615-5563-6
Miettinen, K.: Nonlinear Multiobjective Optimization. Springer New York, NY, 1 edn. (1998). https://doi.org/10.1007/978-1-4615-5563-6
-
[21]
Miettinen, K.: Introduction to Multiobjective Optimization: Noninteractive Ap- proaches, p. 1–26. Springer Berlin Heidelberg (2008). https://doi.org/10.1007/978- 3-540-88908-3_1 Interactive Pareto navigation for deep multi-task learning 17
-
[22]
European Journal of Operational Research206(2), 426–434 (2010)
Miettinen, K., Eskelinen, P., Ruiz, F., Luque, M.: Nautilus method: An interac- tive technique in multiobjective optimization based on the nadir point. European Journal of Operational Research206(2), 426–434 (2010)
2010
-
[23]
Miettinen,K.,Mäkelä,M.M.:Interactivemultiobjectiveoptimizationsystemwww- nimbusontheinternet.Computers&OperationsResearch27(7-8),709–723(2000)
2000
-
[24]
Machine Learning with Applications21, 100700 (Sep 2025)
Peitz, S., Hotegni, S.S.: Multi-objective deep learning: Taxonomy and survey of the state of the art. Machine Learning with Applications21, 100700 (Sep 2025). https://doi.org/10.1016/j.mlwa.2025.100700
-
[25]
European Journal of Operational Research284(1), 53–66 (2020)
Raimundo, M.M., Ferreira, P.A., Von Zuben, F.J.: An extension of the non-inferior set estimation algorithm for many objectives. European Journal of Operational Research284(1), 53–66 (2020). https://doi.org/10.1016/j.ejor.2019.11.017
-
[26]
Reinaldo Meneghini, I., Gadelha Guimarães, F., Gaspar-Cunha, A., Weiss Cohen, M.: Incorporation of Region of Interest in a Decomposition-Based Multi-objective Evolutionary Algorithm, p. 35–50. Springer International Publishing (Nov 2020). https://doi.org/10.1007/978-3-030-57422-2_3
-
[27]
Journal of Multi-Criteria Deci- sion Analysis5(2), 145–159 (Jun 1996)
Roy, B., Mousseau, V.: A theoretical framework for analysing the no- tion of relative importance of criteria. Journal of Multi-Criteria Deci- sion Analysis5(2), 145–159 (Jun 1996). https://doi.org/10.1002/(sici)1099- 1360(199606)5:2<145::aid-mcda99>3.0.co;2-5
-
[28]
Engineering Optimization52(5), 832–855 (May 2019)
Schütze, O., Cuate, O., Martín, A., Peitz, S., Dellnitz, M.: Pareto ex- plorer: a global/local exploration tool for many-objective optimiza- tion problems. Engineering Optimization52(5), 832–855 (May 2019). https://doi.org/10.1080/0305215x.2019.1617286
-
[29]
In: Ad- vances in Neural Information Processing Systems 31
Sener, O., Koltun, V.: Multi-task learning as multi-objective optimization. In: Ad- vances in Neural Information Processing Systems 31. pp. 525––536. Curran Asso- ciates, Inc. (2018)
2018
-
[30]
Ad- vances in neural information processing systems31, 12 (2018)
Sener, O., Koltun, V.: Multi-task learning as multi-objective optimization. Ad- vances in neural information processing systems31, 12 (2018)
2018
-
[31]
Applied Soft Computing165, 112106 (Nov 2024)
Vargas, D.E., Lemonge, A.C., Barbosa, H.J., Bernardino, H.S.: An interactive reference-point-based method for incorporating user preferences in multi-objective structural optimization problems. Applied Soft Computing165, 112106 (Nov 2024). https://doi.org/10.1016/j.asoc.2024.112106
-
[32]
Complex & amp; Intelligent Systems3(4), 233–245 (Aug 2017)
Wang, H., Olhofer, M., Jin, Y.: A mini-review on preference modeling and articulation in multi-objective optimization: current status and chal- lenges. Complex & amp; Intelligent Systems3(4), 233–245 (Aug 2017). https://doi.org/10.1007/s40747-017-0053-9
-
[33]
IEEE Transactions on Evolutionary Computation22(1), 3–18 (Feb 2018)
Wang, R., Zhou, Z., Ishibuchi, H., Liao, T., Zhang, T.: Localized weighted sum method for many-objective optimization. IEEE Transactions on Evolutionary Computation22(1), 3–18 (Feb 2018). https://doi.org/10.1109/tevc.2016.2611642
-
[34]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Xiao, H., Rasul, K., Vollgraf, R.: Fashion-mnist: a novel im- age dataset for benchmarking machine learning algorithms (2017). https://doi.org/10.48550/ARXIV.1708.07747
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1708.07747 2017
-
[35]
IEEE Access6, 41256–41279 (2018)
Xin, B., Chen, L., Chen, J., Ishibuchi, H., Hirota, K., Liu, B.: Interactive multiob- jective optimization: A review of the state-of-the-art. IEEE Access6, 41256–41279 (2018). https://doi.org/10.1109/access.2018.2856832
-
[36]
IEEE Access7, 117699–117715 (2019)
Xiong, M., Xiong, W., Liu, C.: A hybrid many-objective evolutionary algorithm with region preference for decision makers. IEEE Access7, 117699–117715 (2019). https://doi.org/10.1109/access.2019.2931742
-
[37]
National Sci- ence Review5(1), 30–43 (09 2017)
Zhang, Y., Yang, Q.: An overview of multi-task learning. National Sci- ence Review5(1), 30–43 (09 2017). https://doi.org/10.1093/nsr/nwx105, https://doi.org/10.1093/nsr/nwx105 18 A.C. Amakor et al. A Proof A.1 Computation ofd i In the PPE method, we compute the directions di = arg min d∈Rn ⟨d,∇f i(x)⟩+ 1 2 ∥d∥2, s.t.⟨d,∇f j(x)⟩ ≤0,forj∈ I, (7) for alli∈ I...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.