Fail-RAG : A Retrieval Augmented Generation Informed Framework for Robot Failure Identification
Pith reviewed 2026-06-26 20:24 UTC · model grok-4.3
The pith
Fail-RAG retrieves similar past failures from a database to raise robot failure detection accuracy 25 points above direct vision-language model use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
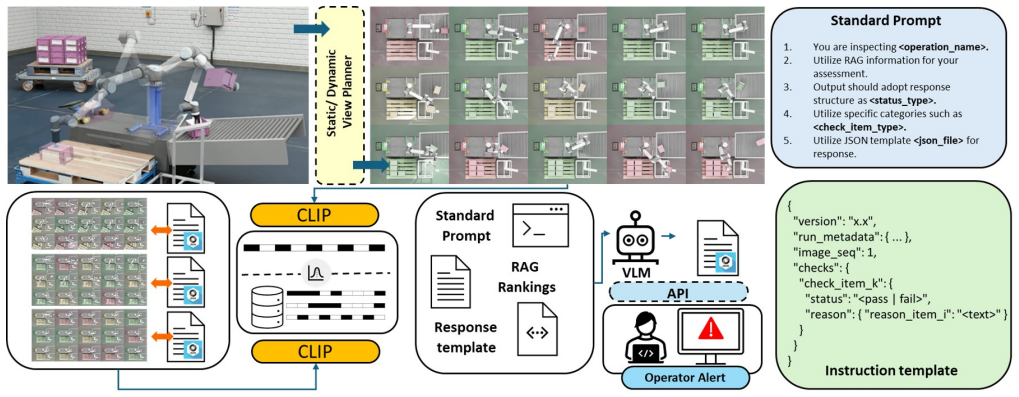
Fail-RAG embeds failure images and context, queries a failure database by similarity, and applies vision-language models with an instruction template to analyze the current event, yielding higher detection accuracy than direct use of the models across multiple robot operations.
What carries the argument
The retrieval step of Fail-RAG, which computes embedding similarity to surface relevant entries from a pre-populated failure database before vision-language models generate analysis.
If this is right
- Removes dependence on hand-crafted rules that cannot cover changing warehouse conditions.
- Produces both detection and detailed failure descriptions through the templated model step.
- Applies to fixed robot arms and mobile manipulators in both simulation and physical trials.
- Delivers measurable gains on five distinct types of warehouse material-handling tasks.
Where Pith is reading between the lines
- The same retrieval structure could be extended to let the database grow automatically with newly observed failures.
- Retrieved cases might also supply candidate recovery actions rather than only detection labels.
- Comparable retrieval-augmented pipelines could address error detection in robot navigation or grasping outside warehouse settings.
Load-bearing premise
Embedding similarity to a fixed set of stored failures will still locate useful information when the robot encounters a previously unseen failure mode.
What would settle it
Measure whether detection accuracy falls back to the level of plain vision-language models when the test failures are selected to have low embedding similarity with every entry in the database.
Figures




read the original abstract
Industry automation is witnessing an evolution in robotics driven by both technological breakthroughs and societal changes: progress towards generalist robots, embodied and physical artificial intelligence (AI), and increasing labor shortage in manufacturing.An intelligent autonomous robot needs to not only act according to planned motions but also react to any unexpected events. In this study, we focus on such unexpected events in warehouses where robots are used for material handling. Specifically, we refer to any unexpected events as failures and develop methods to detect robot operations related failures. Rule-based detection methods may break since the form of failures could change due to the dynamic nature of both environments and tasks. We propose 'Fail-RAG', a Retrieval Augmented Generation (RAG)-based failure detection framework where failure images and context information are embedded and queried against a failure database by calculating their similarities. Vision-Language Models (VLMs) are further used to analyze failures and provide details by following our instruction template. We evaluated the performance of Fail-RAG by conducting both simulation and physical experiments using fixed robot arms and a mobile manipulator for multiple tasks that are common in warehouse automation. Fail-RAG achieved 25 percentage point higher failure detection accuracy on average across five types of robot operations compared to using off-the-shelf VLMs, indicating its effectiveness for real-world failure detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Fail-RAG, a retrieval-augmented generation framework for robot failure identification in warehouse material-handling tasks. Failure images and contextual information are embedded and matched via similarity search against a pre-populated failure database; retrieved cases are then supplied to a vision-language model (VLM) that follows a fixed instruction template to classify and describe the failure. The authors report results from both simulation and physical experiments using fixed robot arms and a mobile manipulator across five operation types, claiming an average 25-percentage-point accuracy improvement over off-the-shelf VLMs.
Significance. If the reported accuracy gains can be shown to arise from genuine generalization rather than database overlap, the Fail-RAG approach would supply a practical, database-driven alternative to brittle rule-based monitors for dynamic robotic environments. The explicit use of both simulated and physical testbeds is a constructive element that strengthens the empirical grounding.
major comments (2)
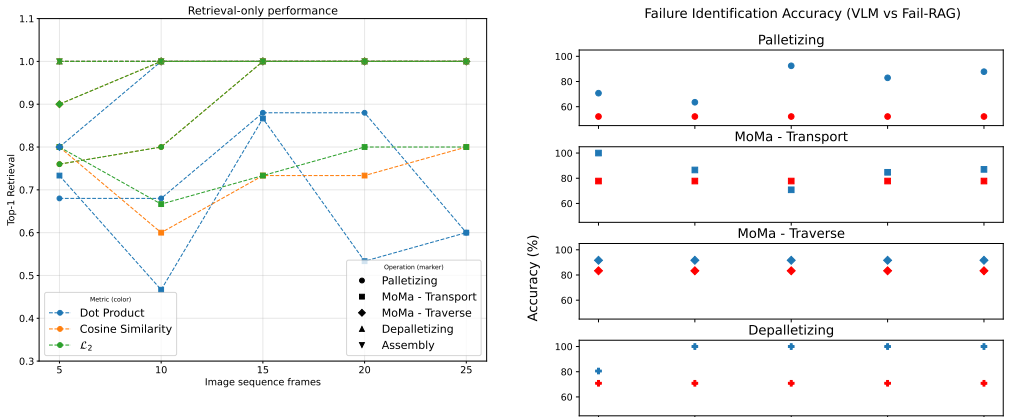
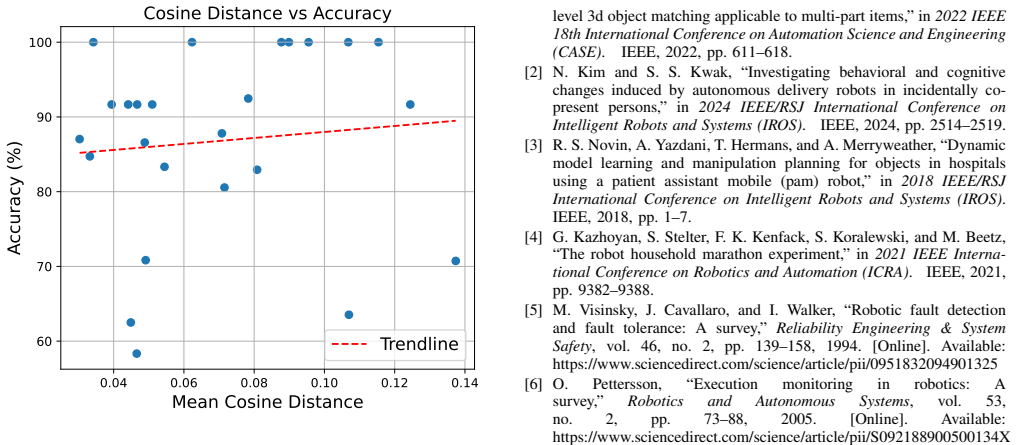
- [Experiments] Experiments section: the central claim of a 25-percentage-point accuracy lift is presented without dataset sizes, number of trials per operation type, failure definitions, or any statistical significance tests. This information is required to evaluate whether the improvement reflects robustness to novel failure modes or merely better prompting when test cases closely match database entries.
- [Method] Method and motivation sections: the paper motivates the work by noting that 'the form of failures could change due to the dynamic nature of both environments and tasks,' yet provides no explicit protocol (e.g., held-out failure modes, distribution-shift metrics, or ablation on database coverage) to test retrieval performance on previously unseen failures. Without such a test the 25 pp gain cannot be attributed to the claimed generalization property.
minor comments (2)
- [Method] The abstract and method description should state the embedding model, similarity metric, and any retrieval threshold or top-k value used; these details are currently omitted.
- [Figures/Tables] Figure captions and table legends would benefit from explicit indication of which bars or rows correspond to Fail-RAG versus baseline VLMs and whether results are averaged over multiple runs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The feedback identifies key areas where additional detail and analysis will strengthen the manuscript. We address each major comment below and commit to revisions that directly incorporate the requested information.
read point-by-point responses
-
Referee: Experiments section: the central claim of a 25-percentage-point accuracy lift is presented without dataset sizes, number of trials per operation type, failure definitions, or any statistical significance tests. This information is required to evaluate whether the improvement reflects robustness to novel failure modes or merely better prompting when test cases closely match database entries.
Authors: We agree that these experimental details are essential. The submitted manuscript omitted them. In the revised version we will expand the Experiments section to report the sizes of the simulation and physical datasets, the exact number of trials conducted for each of the five operation types, explicit definitions of all failure modes considered, and the results of statistical significance tests (e.g., McNemar’s test) comparing Fail-RAG against the baseline VLMs. These additions will allow readers to assess whether the reported gains reflect genuine robustness. revision: yes
-
Referee: Method and motivation sections: the paper motivates the work by noting that 'the form of failures could change due to the dynamic nature of both environments and tasks,' yet provides no explicit protocol (e.g., held-out failure modes, distribution-shift metrics, or ablation on database coverage) to test retrieval performance on previously unseen failures. Without such a test the 25 pp gain cannot be attributed to the claimed generalization property.
Authors: We acknowledge that no dedicated held-out failure protocol or distribution-shift metrics were presented. While the physical experiments introduce real-world variability absent from the simulation database, this was not formalized as an explicit test of unseen failures. In the revision we will add a description of database composition and an ablation study that varies database coverage, thereby providing quantitative evidence on retrieval performance for novel failure cases. revision: yes
Circularity Check
No circularity: empirical evaluation of a retrieval framework with no derivations or self-referential fits.
full rationale
The paper describes a RAG-based failure detection system (embedding similarity lookup into a pre-populated database followed by VLM analysis) and reports an experimental accuracy gain of 25 percentage points. No equations, parameter fits, uniqueness theorems, or derivation steps are present in the provided text. The accuracy figure is presented strictly as an outcome of simulation and physical experiments across five operation types, not as a quantity derived from the method itself. This matches the default expectation of a non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embedding similarity between failure images and context reliably identifies relevant past cases.
- domain assumption VLMs can produce accurate failure descriptions when given retrieved examples and an instruction template.
Reference graph
Works this paper leans on
-
[1]
Param- eterized b-rep-based surface correspondence estimation for category- level 3d object matching applicable to multi-part items,
T. Yano, D. Hagihara, N. Kimura, N. Chihara, and K. Ito, “Param- eterized b-rep-based surface correspondence estimation for category- level 3d object matching applicable to multi-part items,” in2022 IEEE 18th International Conference on Automation Science and Engineering (CASE). IEEE, 2022, pp. 611–618
2022
-
[2]
Investigating behavioral and cognitive changes induced by autonomous delivery robots in incidentally co- present persons,
N. Kim and S. S. Kwak, “Investigating behavioral and cognitive changes induced by autonomous delivery robots in incidentally co- present persons,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 2514–2519
2024
-
[3]
Dynamic model learning and manipulation planning for objects in hospitals using a patient assistant mobile (pam) robot,
R. S. Novin, A. Yazdani, T. Hermans, and A. Merryweather, “Dynamic model learning and manipulation planning for objects in hospitals using a patient assistant mobile (pam) robot,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1–7
2018
-
[4]
The robot household marathon experiment,
G. Kazhoyan, S. Stelter, F. K. Kenfack, S. Koralewski, and M. Beetz, “The robot household marathon experiment,” in2021 IEEE Interna- tional Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 9382–9388
2021
-
[5]
Robotic fault detection and fault tolerance: A survey,
M. Visinsky, J. Cavallaro, and I. Walker, “Robotic fault detection and fault tolerance: A survey,”Reliability Engineering & System Safety, vol. 46, no. 2, pp. 139–158, 1994. [Online]. Available: https://www.sciencedirect.com/science/article/pii/0951832094901325
-
[6]
Execution monitoring in robotics: A survey,
O. Pettersson, “Execution monitoring in robotics: A survey,”Robotics and Autonomous Systems, vol. 53, no. 2, pp. 73–88, 2005. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S092188900500134X
2005
-
[7]
A survey of fault detection, isolation, and reconfiguration methods,
I. Hwang, S. Kim, Y . Kim, and C. E. Seah, “A survey of fault detection, isolation, and reconfiguration methods,”IEEE Transactions on Control Systems Technology, vol. 18, no. 3, pp. 636–653, 2010
2010
-
[8]
C. Grislain, H. Rahimi, O. Sigaud, and M. Chetouani, “I-FailSense: Towards General Robotic Failure Detection with Vision-Language Models,” Sep. 2025, arXiv:2509.16072 [cs]. [Online]. Available: http://arxiv.org/abs/2509.16072
- [9]
-
[10]
Robust Task Planning via Failure Detection Using Scene Graph From Multi-View Images,
H. Chong, J. Lee, and H. Ahn, “Robust Task Planning via Failure Detection Using Scene Graph From Multi-View Images,”IEEE Robotics and Automation Letters, vol. 11, no. 2, pp. 1986–1993, Feb. 2026. [Online]. Available: https://ieeexplore.ieee.org/document/11302797/
-
[11]
Recover: A neuro-symbolic framework for failure detection and recovery,
C. Cornelio and M. Diab, “Recover: A neuro-symbolic framework for failure detection and recovery,” 2024. [Online]. Available: https://arxiv.org/abs/2404.00756
-
[12]
AHA: A Vision- Language-Model for Detecting and Reasoning Over Failures in Robotic Manipulation,
J. Duan, W. Pumacay, N. Kumar, Y . R. Wang, S. Tian, W. Yuan, R. Krishna, D. Fox, A. Mandlekar, and Y . Guo, “AHA: A Vision- Language-Model for Detecting and Reasoning Over Failures in Robotic Manipulation,” Oct. 2024, arXiv:2410.00371 [cs]. [Online]. Available: http://arxiv.org/abs/2410.00371
-
[13]
FailSafe: Reasoning and Recovery from Failures in Vision-Language-Action Models
Z. Lin, J. Duan, H. Fang, D. Fox, R. Krishna, C. Tan, and B. Wen, “FailSafe: Reasoning and Recovery from Failures in Vision-Language-Action Models,” Oct. 2025, arXiv:2510.01642 [cs]. [Online]. Available: http://arxiv.org/abs/2510.01642
work page internal anchor Pith review arXiv 2025
-
[14]
Diagnose, Correct, and Learn from Manipulation Failures via Visual Symbols,
X. Zeng, X. Zhou, Y . Li, J. Shi, T. Li, L. Chen, L. Ren, and Y .-L. Li, “Diagnose, Correct, and Learn from Manipulation Failures via Visual Symbols,” Dec. 2025, arXiv:2512.02787 [cs]. [Online]. Available: http://arxiv.org/abs/2512.02787
-
[15]
Safe: Multitask failure detection for vision-language-action models
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti, “SAFE: Multitask Failure Detection for Vision-Language- Action Models,” Oct. 2025, arXiv:2506.09937 [cs]. [Online]. Available: http://arxiv.org/abs/2506.09937
-
[16]
Multimodal Anomaly Detection with a Mixture-of-Experts,
C. Willibald, D. Sliwowski, and D. Lee, “Multimodal Anomaly Detection with a Mixture-of-Experts,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Hangzhou, China: IEEE, Oct. 2025, pp. 20 020–20 027. [Online]. Available: https://ieeexplore.ieee.org/document/11245878/
-
[17]
Addressing Failures in Robotics using Vision-Based Language Models (VLMs) and Behavior Trees (BT),
F. Ahmad, J. Styrud, and V . Krueger, “Addressing Failures in Robotics using Vision-Based Language Models (VLMs) and Behavior Trees (BT),” Nov. 2024, arXiv:2411.01568 [cs]. [Online]. Available: http://arxiv.org/abs/2411.01568
-
[18]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021. [Online]. Available: https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Evarag: Evaluating advanced rag tech- niques with indexing and distance metrics,
H. Elkiran and J. Rasheed, “Evarag: Evaluating advanced rag tech- niques with indexing and distance metrics,”IEEE Access, vol. 13, pp. 215 724–215 747, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.