Exploring Multi-Modal Large Language Models and Two-Stage Fine-Tuning for Fashion Image Retrieval
Pith reviewed 2026-06-26 17:58 UTC · model grok-4.3
The pith
LLaVA generates attribute-aware triplets and two-stage fine-tuning strengthens contrastive learning for composed fashion image retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that integrating LLaVA to produce attribute-aware triplets, together with a two-stage fine-tuning schedule on contrastive objectives and prompt concatenation from pretrained CLIP models, yields measurable gains in compositional reasoning and fine-grained retrieval accuracy on fashion benchmarks.
What carries the argument
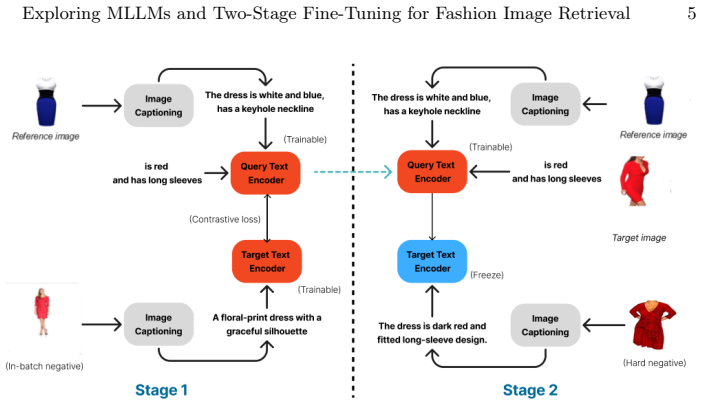
LLaVA-generated attribute-aware triplets fed into two-stage fine-tuning of contrastive learning on concatenated CLIP prompts
If this is right
- Composed queries involving subtle attribute shifts become easier to satisfy without extra manual annotations.
- Negative sampling becomes more effective by scaling from static representations rather than on-the-fly mining.
- Compositional reasoning improves because the generated triplets explicitly link reference images to modified descriptions.
- The same pipeline can be applied to other retrieval domains that share the problem of scarce fine-grained labels.
Where Pith is reading between the lines
- The method may reduce the need for domain experts to label every possible attribute combination in new datasets.
- If LLaVA output quality varies across clothing categories, performance gains could be uneven and require category-specific checks.
- Combining this data-generation step with larger-scale contrastive backbones might further lift retrieval without changing the fine-tuning schedule.
Load-bearing premise
The triplets produced by LLaVA are accurate and varied enough to help training rather than introduce errors or reduce diversity.
What would settle it
Run the same retrieval model on a standard fashion benchmark with and without the LLaVA triplets; if recall or ranking metrics show no improvement or a drop, the claim does not hold.
Figures



read the original abstract
Composed image retrieval retrieves a target image using a composed query of a reference image and a modified text description. In the fashion domain, this task requires understanding subtle attribute variations such as color, pattern, and texture. However, existing approaches face limitations due to scarce annotated data and simplistic negative sampling. We propose a novel framework that integrates a multi-modal large language model (LLaVA) to generate attribute-aware triplets and introduces a two-stage fine-tuning strategy to enhance contrastive learning. We leverage pretrained vision-language models, such as CLIP-ViT/B32, to generate and concatenate sentence-level prompts with the relative caption and to scale the number of negatives using static representations. Experimental results demonstrate enhanced compositional reasoning and improved fine-grained retrieval behavior, underscoring the feasibility and potential of the proposed framework for fashion retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for composed image retrieval in the fashion domain that uses the multi-modal LLM LLaVA to generate attribute-aware triplets (reference image + relative caption + target) and applies a two-stage fine-tuning strategy on top of pretrained vision-language models such as CLIP-ViT/B32. The method concatenates sentence-level prompts, scales negatives via static representations, and claims to improve compositional reasoning and fine-grained retrieval over existing approaches limited by scarce annotations and simplistic negative sampling.
Significance. If the central claim holds after proper validation, the work would demonstrate a practical way to leverage MLLMs for data augmentation in a data-scarce domain, potentially improving contrastive learning for attribute-sensitive tasks. However, the absence of any reported quality controls on the generated triplets means the significance cannot yet be assessed; the contribution reduces to an untested pipeline description.
major comments (2)
- [Method (triplet generation)] Method section on triplet generation: the claim that LLaVA produces 'attribute-aware triplets' that enhance contrastive learning is load-bearing, yet the manuscript reports no human validation, hallucination rate, inter-annotator agreement, or comparison against human-annotated triplets. Without these, it is impossible to determine whether observed gains (if any) arise from the two-stage fine-tuning or from label noise/diversity issues in the synthetic data.
- [Experiments] Experiments section: the abstract asserts 'enhanced compositional reasoning and improved fine-grained retrieval behavior' but supplies no quantitative results, baselines (e.g., standard CLIP fine-tuning, other negative-sampling strategies), metrics (Recall@K, compositional accuracy), error analysis, or ablation on the two-stage schedule. This prevents verification that the framework outperforms prior art rather than merely describing it.
minor comments (2)
- [Method] Notation for the two-stage fine-tuning procedure is introduced without a clear algorithmic listing or pseudocode, making the distinction between stages difficult to follow.
- [Abstract / Method] The abstract mentions 'static representations' for negative scaling but does not define how these are computed or stored; a short clarifying sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for validation of generated triplets and more rigorous experimental reporting. We address each major comment below and commit to a major revision that incorporates the requested elements.
read point-by-point responses
-
Referee: [Method (triplet generation)] Method section on triplet generation: the claim that LLaVA produces 'attribute-aware triplets' that enhance contrastive learning is load-bearing, yet the manuscript reports no human validation, hallucination rate, inter-annotator agreement, or comparison against human-annotated triplets. Without these, it is impossible to determine whether observed gains (if any) arise from the two-stage fine-tuning or from label noise/diversity issues in the synthetic data.
Authors: We agree that the absence of quality controls on the LLaVA-generated triplets is a significant gap. The current manuscript does not report human validation, hallucination rates, or comparisons to human annotations. In the revised version we will add these evaluations, including inter-annotator agreement and a direct comparison of synthetic versus human triplets, to substantiate that the gains stem from improved data quality rather than noise. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts 'enhanced compositional reasoning and improved fine-grained retrieval behavior' but supplies no quantitative results, baselines (e.g., standard CLIP fine-tuning, other negative-sampling strategies), metrics (Recall@K, compositional accuracy), error analysis, or ablation on the two-stage schedule. This prevents verification that the framework outperforms prior art rather than merely describing it.
Authors: We acknowledge that the experiments section currently lacks the detailed quantitative results, baselines, metrics, error analysis, and ablations needed for verification. Although the abstract summarizes the outcomes, the full experimental evidence is insufficiently presented. We will expand the experiments section in the revision to include Recall@K, compositional accuracy metrics, comparisons against standard CLIP fine-tuning and alternative negative-sampling strategies, error analysis, and an ablation study on the two-stage schedule. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical framework proposal using LLaVA for triplet generation and two-stage fine-tuning on top of pretrained models like CLIP, with experimental results claimed. No equations, parameter fits, derivations, or load-bearing self-citations appear in the provided abstract or description. The central claims rest on experimental outcomes rather than any mathematical reduction to inputs by construction, making the derivation chain self-contained against external benchmarks with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, Y., Xu, X., Liu, Y., Khan, S., Khan, F., Zuo, W., Goh, R.S.M., Feng, C.M.: Sentence-level prompts benefit composed image retrieval (2023),https://arxiv. org/abs/2310.05473
-
[2]
arXiv preprint (2023)
Bai, Y., Xu, X., Liu, Y., Khan, S., Khan, F., Zuo, W., Goh, R.S.M., Feng, C.M.: Sentence-level prompts benefit composed image retrieval. arXiv preprint (2023)
2023
- [3]
-
[4]
Baldrati, A., Bertini, M., Uricchio, T., Del Bimbo, A.: Conditioned and composed imageretrievalcombiningandpartiallyfine-tuningclip-basedfeatures.In:Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 4959–4968 (Jun 2022) 10 Nguyen Cao Hoang et al
2022
-
[5]
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations (2020),https://arxiv.org/abs/2002. 05709
2020
- [6]
- [7]
-
[8]
In: Multimedia Content Analysis, Management, and Retrieval 2006
Hare, J.S., Lewis, P.H., Enser, P.G., Sandom, C.J.: Mind the gap: Another look at the problem of the semantic gap in image retrieval. In: Multimedia Content Analysis, Management, and Retrieval 2006. vol. 6073, pp. 75–86. SPIE (2006)
2006
-
[9]
International Journal of Computer Applications73(15) (2013)
Karmokar, P.R., Parekh, R.: Recognition of semantic content in image and video. International Journal of Computer Applications73(15) (2013)
2013
-
[10]
Multimedia Tools and Applications80, 17169–17181 (2021)
Liu, A.A., Zhang, T., Song, D., Li, W., Zhou, M.: Frsfn: A semantic fusion network for practical fashion retrieval. Multimedia Tools and Applications80, 17169–17181 (2021)
2021
-
[11]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Liu, Z., Rodriguez-Opazo, C., Teney, D., Gould, S.: Image retrieval on real- life images with pre-trained vision-and-language models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 2125–2134 (Oct 2021)
2021
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Pal, A., Wadhwa, S., Jaiswal, A., Zhang, X., Wu, Y., Chada, R., Natarajan, P., Christensen, H.I.: Fashionntm: Multi-turn fashion image retrieval via cascaded memory. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11323–11334 (October 2023)
2023
- [14]
-
[15]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.00020, arXiv preprint arXiv:2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
International Journal of Intelligent Systems32(2), 134–152 (2017) https://doi.org/10.1002/int
Ren, X., Zheng, X., Zhou, H., Liu, W., Dong, X.: Contrastive hashing with vi- sion transformer for image retrieval. International Journal of Intelligent Systems 37(12), 12192–12211 (2022).https://doi.org/https://doi.org/10.1002/int. 23082,https://onlinelibrary.wiley.com/doi/abs/10.1002/int.23082
work page doi:10.1002/int 2022
-
[17]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR)
Saito, K., Sohn, K., Zhang, X., Li, C.L., Lee, C.Y., Saenko, K., Pfister, T.: Pic2word: Mapping pictures to words for zero-shot composed image retrieval. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR). pp. 19305–19314 (Jun 2023)
2023
-
[18]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2025 (2025)
Shi, J., Yin, X., Chen, Y., Zhang, Y., Zhang, Z., Xie, Y., Qu, Y.: Multi-schema proximity network for composed image retrieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2025 (2025)
2025
-
[19]
Tang, Y., Yu, J., Gai, K., Zhuang, J., Xiong, G., Hu, Y., Wu, Q.: Context-i2w: Mapping images to context-dependent words for accurate zero-shot composed im- age retrieval. Proceedings of the AAAI Conference on Artificial Intelligence38(6), 5180–5188 (Mar 2024).https://doi.org/10.1609/aaai.v38i6.28324,https:// ojs.aaai.org/index.php/AAAI/article/view/28324...
-
[20]
Valle, D., Ziviani, N., Veloso, A.: Effective fashion retrieval based on semantic com- positional networks. In: 2018 International Joint Conference on Neural Networks (IJCNN). pp. 1–8 (2018).https://doi.org/10.1109/IJCNN.2018.8489494
-
[21]
Ventura, L., Yang, A., Schmid, C., Varol, G.: Covr-2: Automatic data construction for composed video retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 11409–11421 (Dec 2024).https://doi.org/10.1109/tpami. 2024.3463799,http://dx.doi.org/10.1109/TPAMI.2024.3463799
- [22]
-
[23]
Wu, Z., Xiong, Y., Yu, S., Lin, D.: Unsupervised feature learning via non- parametric instance-level discrimination (2018),https://arxiv.org/abs/1805. 01978
2018
-
[24]
Xu, Y., Bin, Y., Wei, J., Yang, Y., Wang, G., Shen, H.T.: Multi-modal transformer with global-local alignment for composed query image retrieval. Trans. Multi.25(1), 8346–8357 (Jan 2023).https://doi.org/10.1109/TMM.2023. 3235495,https://doi.org/10.1109/TMM.2023.3235495
- [25]
- [26]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.