Beyond Entropy: Learning from Token-Level Distributional Deviations for LLM Reasoning
Pith reviewed 2026-06-26 17:35 UTC · model grok-4.3
The pith
The ICT framework uses JS divergence on token logits to select distinctive tokens for selective updates, balancing Shannon and Rényi entropies to stabilize LLM reasoning training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
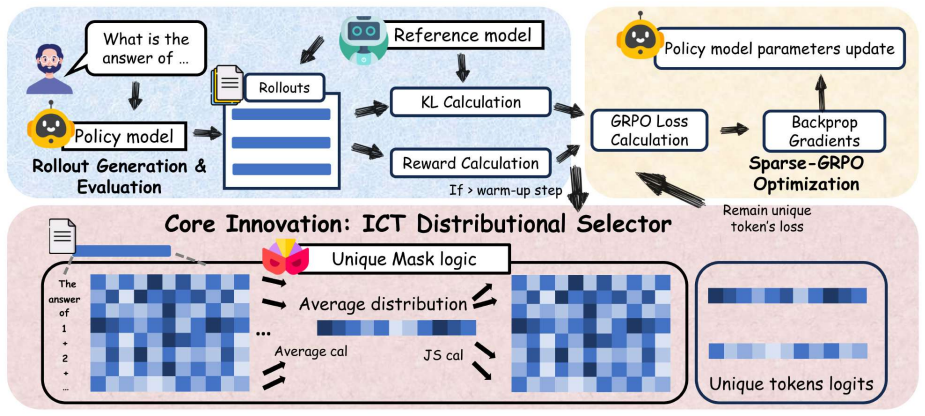
The Independent Combinatorial Tokens framework shifts optimization from scalar uncertainty to distributional properties of token logits. By using Jensen-Shannon divergence to identify tokens with distinctive distributional patterns as critical branching points, selective updates on these tokens reduce overall distribution uncertainty measured by Shannon entropy while controlling probability concentration captured by second-order Rényi entropy. This dual regulation prevents over-concentrated generation from weakening exploration and stabilizes the training landscape.
What carries the argument
The Independent Combinatorial Tokens (ICT) framework, which identifies tokens via Jensen-Shannon divergence between token logits distributions as branching points and performs selective updates on them.
If this is right
- Updating only the top 10% of unique tokens produces an average 4.58% pass@4 gain and up to 14.9% maximum gain over GRPO, 20-Entropy, and STAPO baselines.
- The dual entropy effect prevents both collapse that stops exploration and explosion that produces incoherent chains.
- The approach applies across Qwen2.5 models from 0.5B to 7B parameters on math, commonsense, and Olympiad-level tasks.
- Training stability improves without requiring manual tuning of entropy coefficients.
Where Pith is reading between the lines
- The method could lower training compute by concentrating gradient steps on fewer tokens per batch.
- Similar divergence-based selection might apply to other sequence models where policy concentration causes training issues.
- The identified branching tokens could be inspected to study how LLMs discover alternative reasoning paths.
- Combining ICT with curriculum scheduling of update fractions might further improve results on harder problems.
Load-bearing premise
The assumption that Jensen-Shannon divergence between token logits distributions reliably identifies tokens with distinctive distributional patterns that serve as critical branching points for guiding effective exploration.
What would settle it
An experiment showing no performance difference or worse results when updating the same fraction of tokens chosen at random instead of by JS divergence would falsify the claim that the divergence-based selection drives the stabilization and gains.
Figures



read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced Large Language Model (LLM) reasoning; however, it faces a fundamental optimization instability: uniform token updates precipitate entropy collapse, leading to premature convergence to suboptimal strategies, whereas excessive Shannon Entropy maximization can cause entropy explosion, driving blind exploration toward incoherent reasoning chains. To resolve this dichotomy, we introduce the Independent Combinatorial Tokens (ICT) framework, which shifts the optimization focus from scalar uncertainty to the distributional properties of token logits. By leveraging the Jensen-Shannon (JS) divergence between token logits distributions, ICT identifies tokens with distinctive distributional patterns as critical branching points for guiding effective exploration in LLM reasoning. Our theoretical analysis, grounded in both Shannon and second-order R\'enyi entropy, proves that selectively updating on these tokens regulates policy concentration: it reduces the overall distribution uncertainty measured by Shannon entropy, while controlling probability concentration captured by second-order R\'enyi entropy. This dual effect prevents over-concentrated token generation from weakening exploration and effectively stabilizes the training landscape. Empirical results demonstrate that updating only the top 10% of unique tokens on Qwen2.5 (0.5B/1.5B/7B) models yields an average pass@4 improvement of 4.58%, with a maximum gain of 14.9%, over GRPO, 20-Entropy, and STAPO baselines across seven benchmarks spanning math, commonsense, and Olympiad-level problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RLVR for LLM reasoning suffers from entropy collapse or explosion under uniform token updates. It introduces Independent Combinatorial Tokens (ICT) selected via top-10% Jensen-Shannon divergence on token logit distributions; selective updates on these tokens are asserted to reduce overall Shannon entropy while controlling second-order Rényi entropy, thereby stabilizing training. Empirical results on Qwen2.5 (0.5B/1.5B/7B) report average 4.58% (max 14.9%) pass@4 gains over GRPO, 20-Entropy, and STAPO across seven math/commonsense/Olympiad benchmarks.
Significance. If the claimed entropy-regulation mechanism holds, the work would supply a token-level distributional criterion for balancing exploration/exploitation in verifiable-reward RL that goes beyond scalar entropy penalties. The multi-size, multi-benchmark evaluation provides a reasonable empirical scope for assessing practical impact.
major comments (3)
- [Abstract / Theoretical analysis] Abstract / Theoretical analysis: the statement that the analysis 'proves' selective ICT updates reduce Shannon entropy while controlling Rényi entropy contains no derivation, no entropy identities, and no equations linking JS-divergence selection to the dual effect; the mapping from distributional distinctiveness to the claimed policy-concentration regulation is therefore asserted rather than shown.
- [Abstract / Empirical results] Abstract / Empirical results: the reported pass@4 gains are given without error bars, statistical significance tests, or ablation on the free parameter (top 10% threshold); without these, it is impossible to assess whether the gains are robust or could be explained by update sparsity alone.
- [Abstract] Abstract: the central assumption that high-JS tokens reliably identify 'critical branching points' in reasoning chains is not derived from the Shannon or Rényi definitions; if high-JS tokens instead reflect logit variance unrelated to decision points, the dual-entropy regulation does not follow from the selection rule.
minor comments (1)
- [Abstract] The acronym 'Independent Combinatorial Tokens (ICT)' is introduced without an explicit definition or combinatorial motivation in the abstract.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, noting where the manuscript will be revised for greater clarity, rigor, and completeness.
read point-by-point responses
-
Referee: [Abstract / Theoretical analysis] Abstract / Theoretical analysis: the statement that the analysis 'proves' selective ICT updates reduce Shannon entropy while controlling Rényi entropy contains no derivation, no entropy identities, and no equations linking JS-divergence selection to the dual effect; the mapping from distributional distinctiveness to the claimed policy-concentration regulation is therefore asserted rather than shown.
Authors: We agree the abstract states the claim without the supporting derivation. Section 3 of the manuscript contains the entropy analysis, but it is not summarized with explicit identities or equations in the abstract. In revision we will add a concise outline of the key steps (JS selection o selective update o Shannon reduction with Rényi control) directly into the abstract and introduction so the mapping is shown rather than asserted. revision: yes
-
Referee: [Abstract / Empirical results] Abstract / Empirical results: the reported pass@4 gains are given without error bars, statistical significance tests, or ablation on the free parameter (top 10% threshold); without these, it is impossible to assess whether the gains are robust or could be explained by update sparsity alone.
Authors: This observation is correct. The current results report only mean improvements. We will revise the experimental section and abstract to include (i) error bars from at least three independent runs, (ii) paired statistical significance tests against each baseline, and (iii) an ablation varying the selection threshold (5 %, 10 %, 20 %) to isolate the contribution of JS-based selection from mere sparsity. revision: yes
-
Referee: [Abstract] Abstract: the central assumption that high-JS tokens reliably identify 'critical branching points' in reasoning chains is not derived from the Shannon or Rényi definitions; if high-JS tokens instead reflect logit variance unrelated to decision points, the dual-entropy regulation does not follow from the selection rule.
Authors: We accept that the link to 'critical branching points' is interpretive rather than a direct corollary of the entropy definitions. The entropy-regulation result itself follows from the selective-update rule shown in Section 3; the branching-point interpretation is supported by qualitative trace analysis in Section 4. We will add an explicit discussion paragraph clarifying this distinction and providing additional empirical correlation (e.g., alignment with human-annotated decision points) to strengthen the justification. revision: partial
Circularity Check
No circularity: claims rest on external entropy identities and JS selection without reduction to own inputs
full rationale
The provided abstract and description contain no equations, no self-citations, and no fitted parameters that are later renamed as predictions. The central theoretical claim invokes standard Shannon and Rényi entropy definitions plus JS divergence as an external criterion for token selection; the stated dual regulation effect is presented as following from those identities rather than being tautological with the selection rule itself. No load-bearing step reduces by construction to a definition or prior self-result inside the paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- top 10% threshold =
10%
axioms (2)
- domain assumption JS divergence identifies critical branching points for exploration
- domain assumption Selective token updates produce the stated Shannon/Rényi entropy regulation
invented entities (1)
-
Independent Combinatorial Tokens (ICT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Efficient reinforcement learning with semantic and token entropy for llm reasoning
Hongye Cao, Zhixin Bai, Ziyue Peng, Boyan Wang, Tianpei Yang, Jing Huo, Yuyao Zhang, and Yang Gao. Efficient reinforcement learning with semantic and token entropy for llm reasoning. arXiv preprint arXiv:2512.04359,
-
[2]
Acereason-nemotron: Advancing math and code reasoning through reinforcement learning
Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acereason-nemotron: Advancing math and code reasoning through reinforcement learning. arXiv preprint arXiv:2505.16400 ,
-
[3]
Safe rlhf: Safe reinforcement learning from human feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback. arXiv preprint arXiv:2310.12773 ,
-
[4]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 ,
-
[5]
Rethinking entropy interventions in rlvr: An entropy change perspective
Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, and Jiawei Chen. Rethinking entropy interventions in rlvr: An entropy change perspective. arXiv preprint arXiv:2510.10150,
-
[6]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 ,
Pith/arXiv arXiv 2009
-
[7]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Alek- sander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720 ,
-
[8]
Rethinking entropy regular- ization in large reasoning models
Yuxian Jiang, Yafu Li, Guanxu Chen, Dongrui Liu, Yu Cheng, and Jing Shao. Rethinking entropy regular- ization in large reasoning models. arXiv preprint arXiv:2509.25133 ,
-
[9]
Revisiting entropy in reinforcement learning for large reasoning models
26 Renren Jin, Pengzhi Gao, Yuqi Ren, Zhuowen Han, Tongxuan Zhang, Wuwei Huang, Wei Liu, Jian Luan, and Deyi Xiong. Revisiting entropy in reinforcement learning for large reasoning models. arXiv preprint arXiv:2511.05993,
-
[10]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050 ,
-
[11]
Critical tokens matter: Token-level contrastive estimation enhances llm’s reasoning capability
Zicheng Lin, Tian Liang, Jiahao Xu, Qiuzhi Lin, Xing Wang, Ruilin Luo, Chufan Shi, Siheng Li, Yujiu Yang, and Zhaopeng Tu. Critical tokens matter: Token-level contrastive estimation enhances llm’s reasoning capability. arXiv preprint arXiv:2411.19943 ,
-
[12]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 ,
-
[13]
Keliang Liu, Dingkang Yang, Ziyun Qian, Weijie Yin, Yuchi Wang, Hongsheng Li, Jun Liu, Peng Zhai, Yang Liu, and Lihua Zhang. Reinforcement learning meets large language models: A survey of advancements and applications across the llm lifecycle. arXiv preprint arXiv:2509.16679 ,
-
[14]
Stapo: Stabilizing reinforcement learning for llms by silencing rare spurious tokens
Shiqi Liu, Zeyu He, Guojian Zhan, Letian Tao, Zhilong Zheng, Jiang Wu, Yinuo Wang, Yang Guan, Kehua Sheng, Bo Zhang, et al. Stapo: Stabilizing reinforcement learning for llms by silencing rare spurious tokens. arXiv preprint arXiv:2602.15620 ,
-
[15]
Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms
Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, and Jingren Zhou. Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms. arXiv preprint arXiv:2603.22446 ,
-
[16]
Accessed: 2026-04-23
URL https://huggingface.co/datasets/opencompass/ AIME2025. Accessed: 2026-04-23. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems , 35:277...
2026
-
[17]
Top-h decoding: Adapt- ing the creativity and coherence with bounded entropy in text generation
Erfan Baghaei Potraghloo, Seyedarmin Azizi, Souvik Kundu, and Massoud Pedram. Top-h decoding: Adapt- ing the creativity and coherence with bounded entropy in text generation. arXiv preprint arXiv:2509.02510,
-
[18]
27 Chen Qian, Dongrui Liu, Haochen Wen, Zhen Bai, Yong Liu, and Jing Shao. Demystifying reasoning dynamics with mutual information: Thinking tokens are information peaks in llm reasoning. arXiv preprint arXiv:2506.02867,
-
[19]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022 ,
-
[20]
Enhancing large language model reasoning via selective critical token fine-tuning
Zhiwen Ruan, Yixia Li, He Zhu, Yun Chen, Peng Li, Yang Liu, and Guanhua Chen. Enhancing large language model reasoning via selective critical token fine-tuning. arXiv preprint arXiv:2510.10974 ,
-
[21]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 ,
-
[22]
Ktae: A model-free algorithm to key-tokens advantage estimation in mathematical reasoning
Wei Sun, Wen Yang, Pu Jian, Qianlong Du, Fuwei Cui, Shuo Ren, and Jiajun Zhang. Ktae: A model-free algorithm to key-tokens advantage estimation in mathematical reasoning. arXiv preprint arXiv:2505.16826, 2025a. Yuhao Sun, Yifan Zhang, Quandong Wang, QinZhuo Wu, Wei Liu, and Jian Luan. Spo: Self preference opti- mization with self regularization. In Findin...
arXiv 2025
-
[23]
Tokenskip: Controllable chain-of- thought compression in llms
Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and Wenjie Li. Tokenskip: Controllable chain-of- thought compression in llms. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3351–3363,
2025
-
[24]
Less is more: Improving llm reasoning with minimal test-time intervention
Zhen Yang, Mingyang Zhang, Feng Chen, Ganggui Ding, Liang Hou, Xin Tao, and Ying-Cong Chen. Less is more: Improving llm reasoning with minimal test-time intervention. arXiv preprint arXiv:2510.13940 , 2025a. 28 Zhihe Yang, Xufang Luo, Zilong Wang, Dongqi Han, Zhiyuan He, Dongsheng Li, and Yunjian Xu. Do not let low-probability tokens over-dominate in rl f...
-
[25]
Dapo: An open-source llm reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476 ,
-
[26]
Entropy-based exploration conduction for multi-step reasoning
Jinghan Zhang, Xiting Wang, Fengran Mo, Yeyang Zhou, Wanfu Gao, and Kunpeng Liu. Entropy-based exploration conduction for multi-step reasoning. In Findings of the Association for Computational Lin- guistics: ACL 2025 , pages 3895–3906, 2025a. Xiaoyun Zhang, Xiaojian Yuan, Di Huang, Wang You, Chen Hu, Jingqing Ruan, Kejiang Chen, and Xing Hu. Rediscovering...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.