CoRaCommit: A VS Code Extension for Commit Message Generation with Exemplar Retrieval
Pith reviewed 2026-06-26 16:54 UTC · model grok-4.3
The pith
CoRaCommit retrieves similar past commits as context to improve LLM-generated commit messages in VS Code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
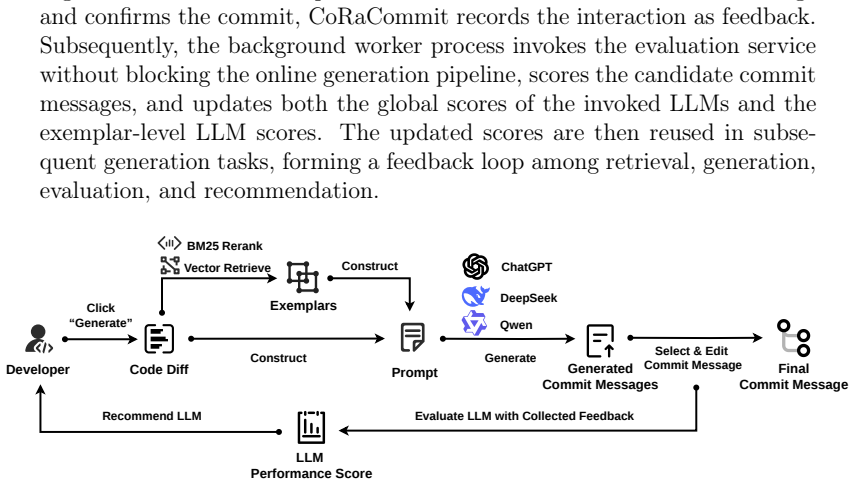
CoRaCommit is a VS Code extension that augments commit message generation by retrieving similar commit exemplars to serve as prompt context for large language models, invoking multiple LLMs in parallel to produce and compare candidate messages, and dynamically recommending an LLM based on collected user feedback, with experiments on the ApacheCM dataset showing superior performance on standard automatic metrics.
What carries the argument
Retrieval of similar commit exemplars to augment LLM prompts, combined with parallel multi-LLM generation and feedback-driven model recommendation.
If this is right
- Adding retrieved commit exemplars to prompts produces higher automatic metric scores than using the diff alone.
- Running multiple LLMs in parallel and selecting among their outputs improves the final message quality.
- Incorporating user feedback allows the system to recommend more suitable LLMs over repeated use.
- The retrieval-augmented approach addresses the limitation of existing extensions that ignore similar historical examples.
Where Pith is reading between the lines
- The same retrieval step could be tested on related tasks such as generating pull-request descriptions or code-review comments.
- Developers working in other IDEs might see comparable gains if the retrieval mechanism were ported beyond VS Code.
- Over time, the growing set of user-accepted messages could serve as additional high-quality exemplars for future retrievals.
Load-bearing premise
Higher scores on automatic metrics such as BLEU correspond to commit messages that developers actually find more useful or accurate.
What would settle it
A controlled developer study that asks participants to rate the accuracy, clarity, and helpfulness of messages generated by CoRaCommit versus baseline extensions on the same code changes.
Figures






read the original abstract
Commit messages are essential textual artifacts that describe the intent behind code changes, and play a critical role in version control, code review, and historical tracking. However, in practice, commit messages are primarily authored manually, which is time-consuming and often results in inconsistent quality and non-uniform expression. Existing VS Code extensions for commit message generation typically directly invoke large language models based on the code diff, without leveraging similar commit exemplars as references, and rarely support user feedback-driven LLM recommendation. To address these limitations, this paper presents CoRaCommit, a VS Code extension that enhances commit message generation by retrieving similar commit exemplars as prompt context, invoking multiple LLMs in parallel for candidate commit message comparison, and dynamically recommending LLMs based on user feedback. Experimental results on 945 commits from the ApacheCM dataset show that CoRaCommit outperforms existing VS Code extensions across BLEU, CIDEr, METEOR, and ROUGE-L metrics, demonstrating the effectiveness of retrieval-augmented context for commit message generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CoRaCommit, a VS Code extension for commit message generation. It retrieves similar commit exemplars to provide context in LLM prompts, invokes multiple LLMs in parallel for candidate comparison, and dynamically recommends LLMs based on user feedback. The central claim is that on 945 commits from the ApacheCM dataset, CoRaCommit outperforms existing VS Code extensions on BLEU, CIDEr, METEOR, and ROUGE-L metrics, demonstrating the effectiveness of retrieval-augmented context.
Significance. If the results hold with proper validation, the work could contribute a practical IDE tool for improving commit message quality in software development. The deployment as a VS Code extension and the use of exemplar retrieval are strengths for applicability. However, the significance is reduced because the evaluation relies solely on automatic metrics without evidence that improvements correspond to messages developers find more useful or accurate.
major comments (2)
- [Evaluation] Evaluation section: The abstract claims outperformance on BLEU, CIDEr, METEOR, and ROUGE-L over 945 ApacheCM commits but supplies no information on baseline implementations, statistical tests, dataset splits, or human validation. This makes the central empirical result impossible to verify and is load-bearing for the claim of effectiveness.
- [Evaluation] Evaluation section: The paper provides no human evaluation, developer preference study, or correlation analysis between the automatic metric scores and actual usefulness or accuracy of the generated commit messages. This proxy assumption is load-bearing for a tool paper whose value proposition is improved commit messages inside an IDE.
minor comments (1)
- [Abstract] The abstract could more explicitly name the existing VS Code extensions used as baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the evaluation aspects of our work. We address the two major comments point-by-point below, agreeing where revisions are needed to improve verifiability while providing the strongest honest defense of the manuscript's current contributions and scope.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The abstract claims outperformance on BLEU, CIDEr, METEOR, and ROUGE-L over 945 ApacheCM commits but supplies no information on baseline implementations, statistical tests, dataset splits, or human validation. This makes the central empirical result impossible to verify and is load-bearing for the claim of effectiveness.
Authors: We agree that the Evaluation section requires expansion for full verifiability. In the revised manuscript we will add: explicit descriptions of how the compared VS Code extensions were implemented or replicated for the experiments; details on any statistical significance tests (such as paired tests with p-values) applied to the metric scores; and clarification on the selection process and any splits for the 945 ApacheCM commits. The current manuscript already specifies the dataset and metrics used, but these additions will address the gaps. Human validation is absent from the original experiments, so we will add an explicit limitations subsection noting this and situating the work within prior commit message papers that also rely primarily on automatic metrics. revision: yes
-
Referee: [Evaluation] Evaluation section: The paper provides no human evaluation, developer preference study, or correlation analysis between the automatic metric scores and actual usefulness or accuracy of the generated commit messages. This proxy assumption is load-bearing for a tool paper whose value proposition is improved commit messages inside an IDE.
Authors: We recognize that linking metric gains to developer-perceived improvements would provide stronger support for the IDE tool's value. The manuscript's evaluation follows standard practice in commit message generation research by using automatic metrics (BLEU, CIDEr, METEOR, ROUGE-L) as proxies. In revision we will expand the discussion to explicitly address the proxy assumption, cite literature on metric-human judgment correlations in related generation tasks, and note the absence of human studies as a limitation. A full developer preference study is outside the scope of the current experiments, but we will strengthen the text to clarify that the reported gains demonstrate the technical benefit of exemplar retrieval. revision: partial
Circularity Check
No circularity; empirical metric comparison is self-contained
full rationale
The paper describes a VS Code extension and reports direct experimental results comparing outputs against BLEU/CIDEr/METEOR/ROUGE-L on the ApacheCM dataset. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. The evaluation is a straightforward empirical benchmark against existing tools; the central claim does not reduce to its inputs by construction. The assumption that automatic metrics proxy developer usefulness is a validity concern, not a circularity issue per the analysis rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y. Tian, J. Lawall, D. Lo, What makes a good commit message?, in: Proceedings of the 26th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), IEEE, 2019, pp. 1–12. 1
2019
-
[2]
Xiong, L
B. Xiong, L. Zhang, Z. Ren, C. Wang, P. Liang, Coracmg: Contextual retrieval-augmented framework for commit message generation, Infor- mation and Software Technology 196 (2026) 108169. 1, 2.1, 2.2, 5
2026
-
[3]
Xiong, L
B. Xiong, L. Zhang, C. Wang, P. Liang, Contextual code retrieval for commit message generation: A preliminary study, in: Proceedings of the 19th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), IEEE, 2025, pp. 358–364. 1
2025
-
[4]
Jiang, C
S. Jiang, C. McMillan, Automatically generating commit messages from diffs using neural machine translation, in: Proceedings of the 39th Inter- national Conference on Software Engineering (ICSE), IEEE, 2017, pp. 109–119. 2.1
2017
-
[5]
Q. Liu, Z. Liu, H. Zhu, et al., Generating commit messages from diffs using pointer-generator network, in: Proceedings of the 16th Interna- tional Conference on Mining Software Repositories (MSR), IEEE, 2019, pp. 25–35. 2.1 15
2019
-
[6]
S. Liu, C. Gao, S. Chen, L. Y. Nie, Y. Liu, Atom: Commit message gen- eration based on abstract syntax tree and hybrid ranking, IEEE Trans- actions on Software Engineering 48 (5) (2022) 1800–1817. 2.1
2022
-
[7]
Kuang, N
H. Kuang, N. Zhang, H. Gao, X. Zhou, W. K. G. Assuncao, X. Ma, D. Shao, G. Rong, H. Zhang, Brevity is the soul of wit: Condensing code changes to improve commit message generation, in: Proceedings of the 16th International Conference on Internetware (Internetware), ACM, 2025, pp. 389–401. 2.1
2025
-
[8]
P.Xue, L.Wu, Z.Yu, Z.Jin, Z.Yang, X.Li, Z.Yang, Y.Tan, Automated commit message generation with large language models: An empirical study and beyond, IEEE Transactions on Software Engineering 50 (12) (2024) 3208–3224. 2.1
2024
-
[9]
Lewis, E
P. Lewis, E. Perez, A. Piktus, et al., Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Proceedings of the 34th Annual Con- ference on Neural Information Processing Systems (NeurIPS), Curran Associates, Inc., 2020, pp. 9459–9474. 2.1
2020
-
[10]
Z. Feng, D. Guo, D. Tang, Y. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, T. Jiang, et al., Codebert: A pre-trained model for programming and natural languages, arXiv preprint arXiv:2002.08155 (2020). 4.2
Pith/arXiv arXiv 2002
-
[11]
URLhttps://www.conventionalcommits.org5
Conventional commits, accessed: 2026-05-01 (2023). URLhttps://www.conventionalcommits.org5
2026
-
[12]
Papineni, S
K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, Bleu: a method for auto- matic evaluation of machine translation, in: Proceedings of the 40th An- nual Meeting of the Association for Computational Linguistics (ACL), ACL, 2002, pp. 311–318. 5
2002
-
[13]
Vedantam, C
R. Vedantam, C. L. Zitnick, D. Parikh, Cider: Consensus-based image description evaluation, in: Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2015, pp. 4566–4575. 5
2015
-
[14]
Banerjee, A
S. Banerjee, A. Lavie, Meteor: An automatic metric for mt evaluation with improved correlation with human judgments, in: Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization (MTSumm), ACL, 2005, pp. 65–72. 5 16
2005
-
[15]
Lin, Rouge: A package for automatic evaluation of summaries, in: Proceedings of the Text Summarization Branches Out: Proceedings of the ACL Workshop, ACL, 2004, pp
C.-Y. Lin, Rouge: A package for automatic evaluation of summaries, in: Proceedings of the Text Summarization Branches Out: Proceedings of the ACL Workshop, ACL, 2004, pp. 74–81. 5
2004
-
[16]
Zhang, J
L. Zhang, J. Zhao, C. Wang, P. Liang, Using large language models for commit message generation: A preliminary study, in: Proceedings of the 31st IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), IEEE, 2024, pp. 126–130. 5 17
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.