CRAX: Fast Safe Reinforcement Learning Benchmarking
Pith reviewed 2026-06-26 18:20 UTC · model grok-4.3
The pith
CRAX delivers up to 100x faster safe RL benchmarking using vectorized MJX environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
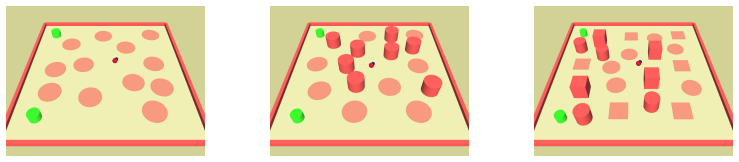
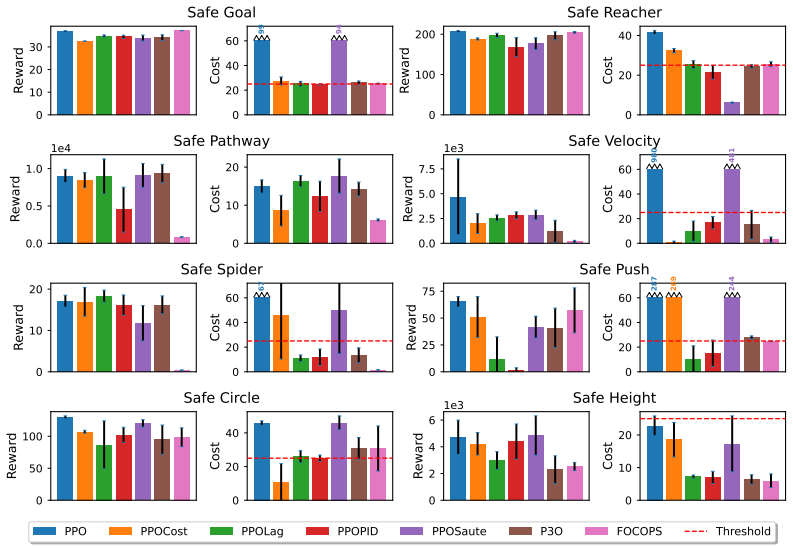
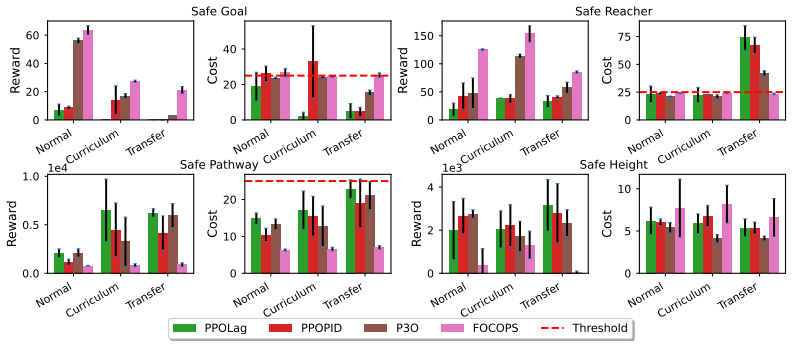
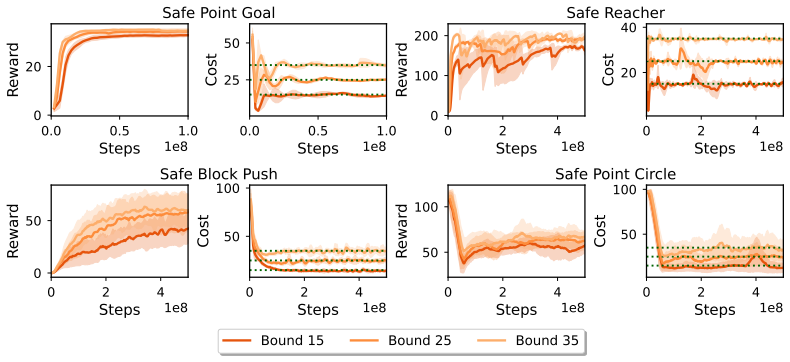
CRAX provides six environment suites and three agent-specific tasks each at three difficulty levels, all running on MJX. It reports up to 100x speedups compared to CPU-based safety benchmarks while preserving realistic 3D dynamics. Testing six popular safe RL methods reveals performance-safety trade-offs with no universal winner, and shows that curriculum learning across difficulty levels plus safety transfer can improve performance over direct training in harder settings.
What carries the argument
The CRAX benchmark suite, which applies vectorized operations on the MuJoCo XLA engine to accelerate constrained RL training and evaluation.
If this is right
- Large-scale experimentation with safe RL methods becomes feasible in realistic 3D physics settings.
- Rapid prototyping and comparison of constrained RL algorithms can occur without prohibitive compute costs.
- Observed trade-offs between performance and safety can inform method selection for specific tasks.
- Curriculum learning and safety transfer become practical strategies for scaling to harder difficulty levels.
Where Pith is reading between the lines
- The same vectorization approach could accelerate other physics-based RL benchmarks beyond safety.
- Extensive hyperparameter tuning for safe RL methods that was previously impractical may now be routine.
- Faster iteration could shorten the gap between simulated safety research and real-world robotics deployment.
Load-bearing premise
The MuJoCo XLA environments provide equivalent fidelity and safety constraint modeling to the slower CPU-based benchmarks they are compared against.
What would settle it
Running the same trained policies on both CRAX environments and the original CPU benchmarks and verifying that safety violation rates and task rewards match within a small margin.
Figures








read the original abstract
Safety is a core concern for deploying reinforcement learning (RL) agents in real-world domains such as robotics and autonomous driving. While benchmarks have been central to progress in RL, existing safety benchmarks with high-fidelity 3D physics remain computationally slow, limiting large-scale experimentation and rapid prototyping. To address this gap, we propose CRAX (Constrained RL Accelerated with JAX). Built on top of the MuJoCo XLA (MJX) physics engine with realistic 3D dynamics, CRAX leverages vectorized operations and hardware acceleration, yielding up to ~100x speedups over comparable CPU-based safety benchmarks. The benchmark features six environment suites and three agent-specific tasks, each spanning three difficulty levels. Evaluating six popular safe RL methods shows that no single approach dominates across all tasks, and reveals the trade-offs between performance and safety. We find that curriculum learning across difficulty levels and safety transfer can improve performance over direct training in harder settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CRAX, a benchmark suite for constrained/safe RL built on MuJoCo XLA (MJX) that uses vectorization and hardware acceleration to achieve up to ~100x speedups over existing CPU-based safety benchmarks. It includes six environment suites with three agent-specific tasks at three difficulty levels each, evaluates six popular safe RL algorithms, reports that no single method dominates across tasks, and claims that curriculum learning and safety transfer improve performance in harder settings.
Significance. If the MJX environments are shown to be dynamically equivalent to the CPU baselines, CRAX would meaningfully lower the computational barrier to large-scale safe RL experimentation and prototyping. The empirical finding that method rankings are task-dependent and the suggestion of curriculum/safety-transfer benefits would be useful for guiding future algorithm design in a domain where real-world deployment requires both performance and constraint satisfaction.
major comments (2)
- [Environments / Experiments] Environments and Experiments sections: the ~100x speedup claim and the conclusion that 'no single approach dominates' both rest on the assumption that the MJX-based environments preserve identical dynamics, contact modeling, constraint definitions, termination logic, and reward structure as the original CPU MuJoCo safety suites. No side-by-side validation (identical state-transition distributions, constraint-violation statistics, or reward curves) is reported, so the speedups and cross-method rankings cannot be directly interpreted as general results.
- [Experiments] Experiments section: the abstract and available description provide no details on measurement methodology (wall-clock timing procedure, hardware configuration, number of independent seeds, error bars, or statistical tests), making the quantitative speedup and performance-safety trade-off claims unverifiable from the presented evidence.
minor comments (1)
- [Abstract] Clarify in the abstract and introduction whether the reported speedups are measured on identical hardware or include GPU/TPU acceleration versus CPU baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the validation and reporting of our results.
read point-by-point responses
-
Referee: [Environments / Experiments] Environments and Experiments sections: the ~100x speedup claim and the conclusion that 'no single approach dominates' both rest on the assumption that the MJX-based environments preserve identical dynamics, contact modeling, constraint definitions, termination logic, and reward structure as the original CPU MuJoCo safety suites. No side-by-side validation (identical state-transition distributions, constraint-violation statistics, or reward curves) is reported, so the speedups and cross-method rankings cannot be directly interpreted as general results.
Authors: We agree that explicit side-by-side validation was not included in the submitted manuscript. Although MJX is intended to replicate MuJoCo's physics, we will add a dedicated validation subsection (with matching state-transition histograms, constraint-violation rates, and reward curves on representative tasks) to confirm dynamical equivalence. This will allow readers to interpret the reported speedups and algorithm rankings with greater confidence. revision: yes
-
Referee: [Experiments] Experiments section: the abstract and available description provide no details on measurement methodology (wall-clock timing procedure, hardware configuration, number of independent seeds, error bars, or statistical tests), making the quantitative speedup and performance-safety trade-off claims unverifiable from the presented evidence.
Authors: We acknowledge the lack of methodological detail. In the revised manuscript we will expand the Experiments section to specify: (i) the exact wall-clock timing procedure, (ii) hardware configuration (CPU/GPU models and memory), (iii) number of independent random seeds, (iv) how error bars are computed, and (v) any statistical tests applied. These additions will make the speedup and trade-off claims fully reproducible and verifiable. revision: yes
Circularity Check
No circularity: benchmark proposal with empirical evaluation only
full rationale
The paper proposes CRAX as a vectorized MJX-based safety RL benchmark and reports empirical speedups plus method comparisons. It contains no derivation chain, no first-principles predictions, no fitted parameters renamed as outputs, and no self-citation load-bearing steps that reduce the central claims to inputs by construction. The ~100x speedup and method-ranking results rest on direct timing measurements and environment runs rather than any self-referential mathematical reduction. Environment equivalence to CPU baselines is an external validity question, not a circularity issue within the paper's own logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Eitan Altman.Constrained Markov Decision Processes. Routledge, 1st edition, 1999. doi: 10.1201/9781315140223
-
[2]
Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling
Marc G. Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents.J. Artif. Intell. Res., 47:253–279, 2013
2013
-
[3]
Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling
Marc G. Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents (extended abstract). InIJCAI, pages 4148–4152. AAAI Press, 2015
2015
-
[4]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InICML, pages 41–48, 2009
2009
-
[5]
VMAS: A vectorized multi-agent simulator for collective robot learning
Matteo Bettini, Ryan Kortvelesy, Jan Blumenkamp, and Amanda Prorok. VMAS: A vectorized multi-agent simulator for collective robot learning. InDARS, pages 42–56, 2022
2022
-
[6]
Smit, Nathan Grinsztajn, Raphaël Boige, Cemlyn N
Clément Bonnet, Daniel Luo, Donal Byrne, Shikha Surana, Sasha Abramowitz, Paul Duckworth, Vincent Coyette, Laurence Illing Midgley, Elshadai Tegegn, Tristan Kalloniatis, Omayma Mahjoub, Matthew Macfarlane, Andries P. Smit, Nathan Grinsztajn, Raphaël Boige, Cemlyn N. Waters, Mohamed A. Mimouni, Ulrich A. Mbou Sob, Ruan de Kock, Siddarth Singh, Daniel Furel...
2024
-
[7]
Accelerating goal-conditioned reinforcement learning algorithms and research
Michal Bortkiewicz, Wladyslaw Palucki, Vivek Myers, Tadeusz Dziarmaga, Tomasz Arczewski, Lukasz Kucinski, and Benjamin Eysenbach. Accelerating goal-conditioned reinforcement learning algorithms and research. InICLR, 2025
2025
-
[8]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. OpenAI Gym. arXiv preprint arXiv:1606.01540, 2016
Pith/arXiv arXiv 2016
-
[9]
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo Perez-Vicente, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan K. Terry. Minigrid & Miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. In NeurIPS, 2023
2023
-
[10]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, pages 248–255, 2009
2009
-
[11]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InCoRL, pages 1–16, 2017
2017
-
[12]
Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem
C. Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax - A differentiable physics engine for large scale rigid body simulation. In NeurIPS Datasets and Benchmarks, 2021
2021
-
[13]
A comprehensive survey on safe reinforcement learning
Javier García and Fernando Fernández. A comprehensive survey on safe reinforcement learning. J. Mach. Learn. Res., 16:1437–1480, 2015
2015
-
[14]
Bullet-Safety-Gym: A framework for constrained reinforcement learning
Sven Gronauer. Bullet-Safety-Gym: A framework for constrained reinforcement learning. Technical report, mediaTUM, 2022
2022
-
[15]
A clean slate for offline reinforcement learning
Matthew Thomas Jackson, Uljad Berdica, Jarek Luca Liesen, Shimon Whiteson, and Jakob Nico- laus Foerster. A clean slate for offline reinforcement learning. InNeurIPS, 2025
2025
-
[16]
Safety gymnasium: A unified safe reinforcement learning benchmark
Jiaming Ji, Borong Zhang, Jiayi Zhou, Xuehai Pan, Weidong Huang, Ruiyang Sun, Yiran Geng, Yifan Zhong, Josef Dai, and Yaodong Yang. Safety gymnasium: A unified safe reinforcement learning benchmark. InNeurIPS, 2023
2023
-
[17]
A modern perspective on safe automated driving for different traffic dynamics using constrained reinforcement learning
Danial Kamran, Thiago D Simão, Qisong Yang, Canmanie T Ponnambalam, Johannes Fischer, Matthijs TJ Spaan, and Martin Lauer. A modern perspective on safe automated driving for different traffic dynamics using constrained reinforcement learning. InITSC, pages 4017–4023, 2022. 10
2022
-
[18]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks. InNIPS, pages 1106–1114, 2012
2012
-
[19]
gymnax: A JAX-based reinforcement learning environment library, 2022
Robert Tjarko Lange. gymnax: A JAX-based reinforcement learning environment library, 2022. URLhttp://github.com/RobertTLange/gymnax
2022
-
[20]
AI safety gridworlds.arXiv preprint arXiv:1711.09883, 2017
Jan Leike, Miljan Martic, Victoria Krakovna, Pedro A Ortega, Tom Everitt, Andrew Lefrancq, Laurent Orseau, and Shane Legg. AI safety gridworlds.arXiv preprint arXiv:1711.09883, 2017
Pith/arXiv arXiv 2017
-
[21]
MetaDrive: Composing diverse driving scenarios for generalizable reinforcement learning
Quanyi Li, Zhenghao Peng, Lan Feng, Qihang Zhang, Zhenghai Xue, and Bolei Zhou. MetaDrive: Composing diverse driving scenarios for generalizable reinforcement learning. IEEE Trans. Pattern Anal. Mach. Intell., 45(3):3461–3475, 2022
2022
-
[22]
Matthews, Michael Beukman, Benjamin Ellis, Mikayel Samvelyan, Matthew Thomas Jackson, Samuel Coward, and Jakob Nicolaus Foerster
Michael T. Matthews, Michael Beukman, Benjamin Ellis, Mikayel Samvelyan, Matthew Thomas Jackson, Samuel Coward, and Jakob Nicolaus Foerster. Craftax: A lightning-fast benchmark for open-ended reinforcement learning. InICML, 2024
2024
-
[23]
Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M. G...
Pith/arXiv arXiv 2025
-
[24]
Rusu, Joel Veness, Marc G
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin A. Riedmiller, Andreas Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcemen...
2015
-
[25]
Sharada P. Mohanty, Jyotish Poonganam, Adrien Gaidon, Andrey Kolobov, Blake Wulfe, Di- pam Chakraborty, Grazvydas Semetulskis, João Schapke, Jonas Kubilius, Jurgis Pasukonis, Linas Klimas, Matthew J. Hausknecht, Patrick MacAlpine, Quang Nhat Tran, Thomas Tumiel, Xiaocheng Tang, Xinwei Chen, Christopher Hesse, Jacob Hilton, William Hebgen Guss, Sahika Genc...
2020
-
[26]
MuJoCo XLA (MJX) - MuJoCo documentation
MuJoCo XLA Authors. MuJoCo XLA (MJX) - MuJoCo documentation. https://mujoco. readthedocs.io/en/stable/mjx.html, 2023. [Accessed 28-01-2026]
2023
-
[27]
Curriculum learning for reinforcement learning domains: A framework and survey.J
Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E Taylor, and Peter Stone. Curriculum learning for reinforcement learning domains: A framework and survey.J. Mach. Learn. Res., 21(181):1–50, 2020
2020
-
[28]
XLand-MiniGrid: Scalable meta-reinforcement learning environments in JAX
Alexander Nikulin, Vladislav Kurenkov, Ilya Zisman, Artem Agarkov, Viacheslav Sinii, and Sergey Kolesnikov. XLand-MiniGrid: Scalable meta-reinforcement learning environments in JAX. InNeurIPS, 2024. 11
2024
-
[29]
John Wiley & Sons, Inc., 1 edition, 1994
Martin L Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, Inc., 1 edition, 1994
1994
-
[30]
Asha Ramanujam, Adam Elyoumi, Hao Chen, Sai Madhukiran Kompalli, Akshdeep Singh Ahluwalia, Shraman Pal, Dimitri J. Papageorgiou, and Can Li. SafeOR-Gym: A benchmark suite for safe reinforcement learning algorithms on practical operations research problems. arXiv preprint arXiv:2506.02255, 2025
arXiv 2025
-
[31]
Benchmarking safe exploration in deep rein- forcement learning
Alex Ray, Joshua Achiam, and Dario Amodei. Benchmarking safe exploration in deep rein- forcement learning. arXiv preprint arXiv:1910.01708, 2019
Pith/arXiv arXiv 1910
-
[32]
Julien Roy, Roger Girgis, Joshua Romoff, Pierre-Luc Bacon, and Christopher J. Pal. Direct behavior specification via constrained reinforcement learning. InICML, pages 18828–18843, 2022
2022
-
[33]
Lange, Shimon Whiteson, Bruno Lacerda, Nick Hawes, Tim Rocktäschel, Chris Lu, and Jakob N
Alexander Rutherford, Benjamin Ellis, Matteo Gallici, Jonathan Cook, Andrei Lupu, Garðar Ingvarsson, Timon Willi, Ravi Hammond, Akbir Khan, Christian Schröder de Witt, Alexandra Souly, Saptarashmi Bandyopadhyay, Mikayel Samvelyan, Minqi Jiang, Robert T. Lange, Shimon Whiteson, Bruno Lacerda, Nick Hawes, Tim Rocktäschel, Chris Lu, and Jakob N. Foerster. Ja...
2024
-
[34]
Proximal policy optimization algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[35]
Cowen-Rivers, Taher Jafferjee, Ziyan Wang, David Henry Mguni, Jun Wang, and Haitham Ammar
Aivar Sootla, Alexander I. Cowen-Rivers, Taher Jafferjee, Ziyan Wang, David Henry Mguni, Jun Wang, and Haitham Ammar. Saute RL: almost surely safe reinforcement learning using state augmentation. InICML, pages 20423–20443, 2022
2022
-
[36]
Responsive safety in reinforcement learning by PID Lagrangian methods
Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforcement learning by PID Lagrangian methods. InICML, pages 9133–9143, 2020
2020
-
[37]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement learning - an introduction, 2nd Edition. MIT Press, 2018
2018
-
[38]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, Timothy P. Lillicrap, and Martin A. Riedmiller. DeepMind control suite. arXiv preprint arXiv:1801.00690, 2018
Pith/arXiv arXiv 2018
-
[39]
Taylor and Peter Stone
Matthew E. Taylor and Peter Stone. Transfer learning for reinforcement learning domains: A survey.J. Mach. Learn. Res., 10:1633–1685, 2009
2009
-
[40]
MuJoCo: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. MuJoCo: A physics engine for model-based control. InIROS, pages 5026–5033, 2012
2012
-
[41]
HASARD: A benchmark for vision- based safe reinforcement learning in embodied agents
Tristan Tomilin, Meng Fang, and Mykola Pechenizkiy. HASARD: A benchmark for vision- based safe reinforcement learning in embodied agents. InICLR, 2025
2025
-
[42]
A survey of constraint formulations in safe reinforcement learning
Akifumi Wachi, Xun Shen, and Yanan Sui. A survey of constraint formulations in safe reinforcement learning. InIJCAI, pages 8262–8271, 2024
2024
-
[43]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InCoRL, volume 100 ofProceedings of Machine Learning Research, pages 1094–
-
[44]
Hall, Siqi Zhou, Lukas Brunke, Melissa Greeff, Jacopo Panerati, and Angela P
Zhaocong Yuan, Adam W. Hall, Siqi Zhou, Lukas Brunke, Melissa Greeff, Jacopo Panerati, and Angela P. Schoellig. Safe-control-gym: A unified benchmark suite for safe learning-based control and reinforcement learning in robotics.IEEE Robotics Autom. Lett., 7(4):11142–11149, 2022
2022
-
[45]
Kevin Zakka, Baruch Tabanpour, Qiayuan Liao, Mustafa Haiderbhai, Samuel Holt, Jing Yuan Luo, Arthur Allshire, Erik Frey, Koushil Sreenath, Lueder A Kahrs, et al. MuJoCo playground. arXiv preprint arXiv:2502.08844, 2025. 12
arXiv 2025
-
[46]
Penalized proximal policy optimization for safe reinforcement learning
Linrui Zhang, Li Shen, Long Yang, Shixiang Chen, Bo Yuan, Xueqian Wang, and Dacheng Tao. Penalized proximal policy optimization for safe reinforcement learning. arXiv preprint arXiv:2205.11814, 2022
arXiv 2022
-
[47]
First order constrained optimization in policy space
Yiming Zhang, Quan Vuong, and Keith Ross. First order constrained optimization in policy space. InNeurIPS, pages 15338–15349, 2020
2020
-
[48]
Robust transfer of safety-constrained rein- forcement learning agents
Markel Zubia, Thiago D Simão, and Nils Jansen. Robust transfer of safety-constrained rein- forcement learning agents. InICLR, 2025. 13 A Environment Descriptions A.1 Overview Task Compatible Agents Constraint Type Cost Mechanism Levels Goal Point, Ant, Humanoid, Spider Spatial avoidance Contact / Proximity 3 Button Point, Ant, Humanoid, Spider Spatial + S...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.