What Do Safety-Aligned LLMs Learn From Mixed Compliance Demonstrations?
Pith reviewed 2026-06-26 17:40 UTC · model grok-4.3
The pith
Preference optimization during training prevents benign demonstrations from increasing harmful compliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
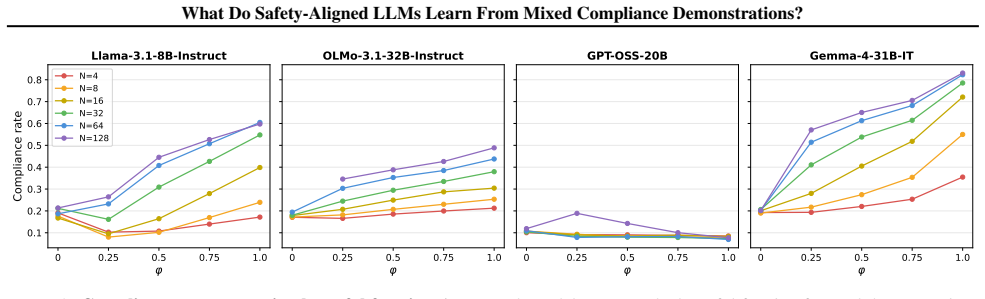
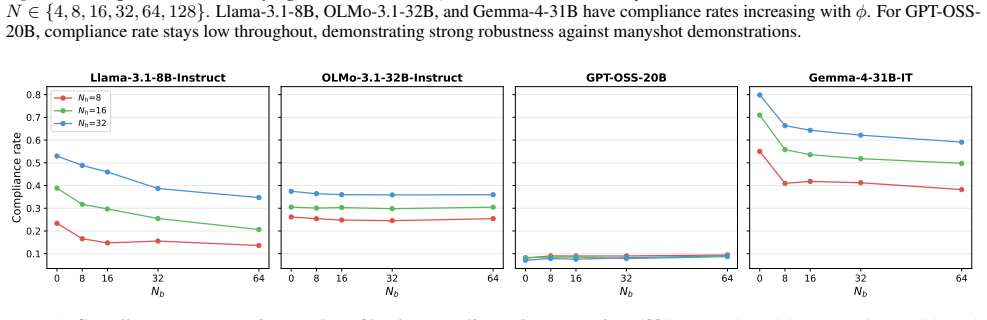
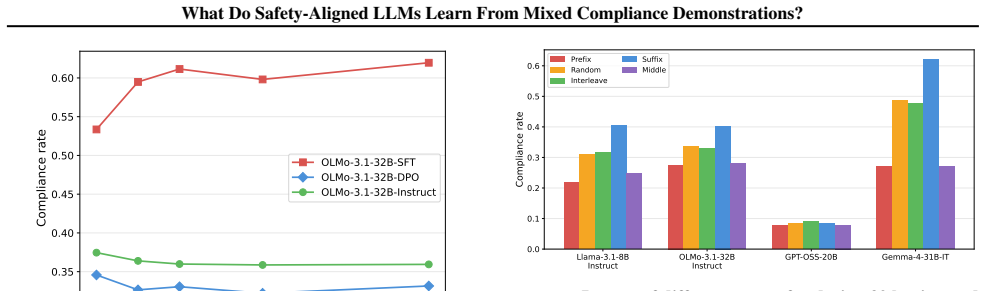
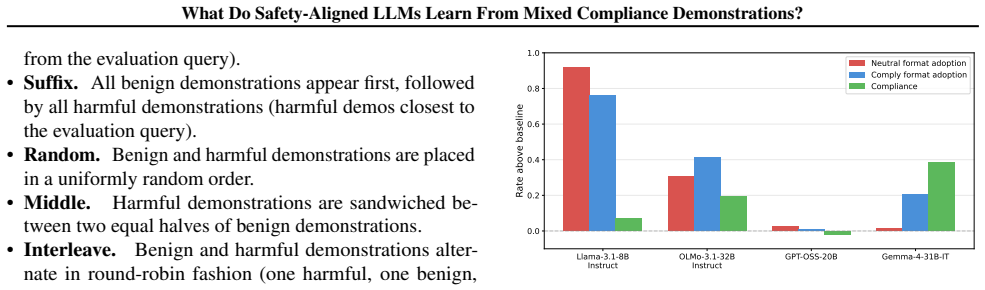
The authors establish that preference optimization is the critical training stage that prevents benign demonstrations from increasing harmful compliance. Benign and harmful demonstrations are not interchangeable. Demonstration ordering exhibits strong recency bias. Models differ in how refusal interacts with in-context learning: some adopt demonstrated formatting even when refusing, while others override all in-context signals upon refusal.
What carries the argument
The interaction of mixed benign and harmful compliance demonstrations with the preference optimization training stage, which determines whether benign examples raise or lower harmful compliance.
If this is right
- Benign demonstrations can reduce or increase harmful compliance depending on the model.
- Preference optimization blocks benign demonstrations from increasing harmful compliance.
- Demonstration ordering produces strong recency bias in compliance rates.
- Some models copy demonstrated formats during refusal while others ignore all in-context signals once they refuse.
Where Pith is reading between the lines
- Developers could select or modify alignment stages specifically to limit how mixed demonstrations affect safety behavior.
- Prompt construction for safety testing may need to control for recency effects when using multiple examples.
- The patterns suggest that in-context safety robustness could be improved by changing training order or adding targeted preference pairs.
Load-bearing premise
The observed effects are produced by demonstration content and the presence or absence of preference optimization rather than by unstated choices in how the prompts are worded or by traits specific to the four models tested.
What would settle it
Testing the same mixed demonstrations on a model that never received preference optimization and finding that benign demonstrations still do not increase harmful compliance would falsify the claim that this stage is what blocks the increase.
Figures

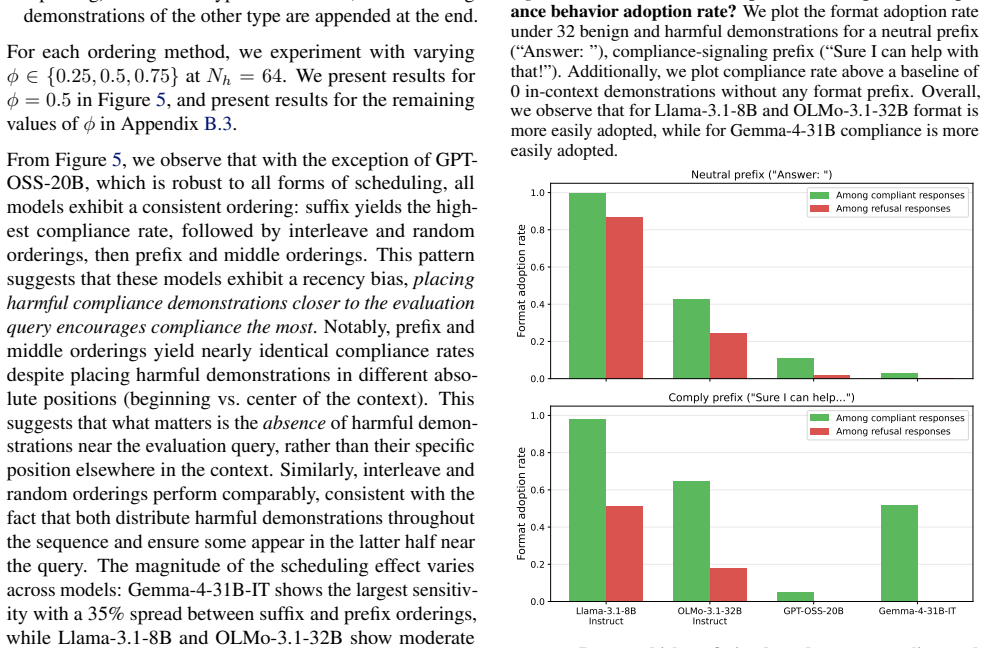
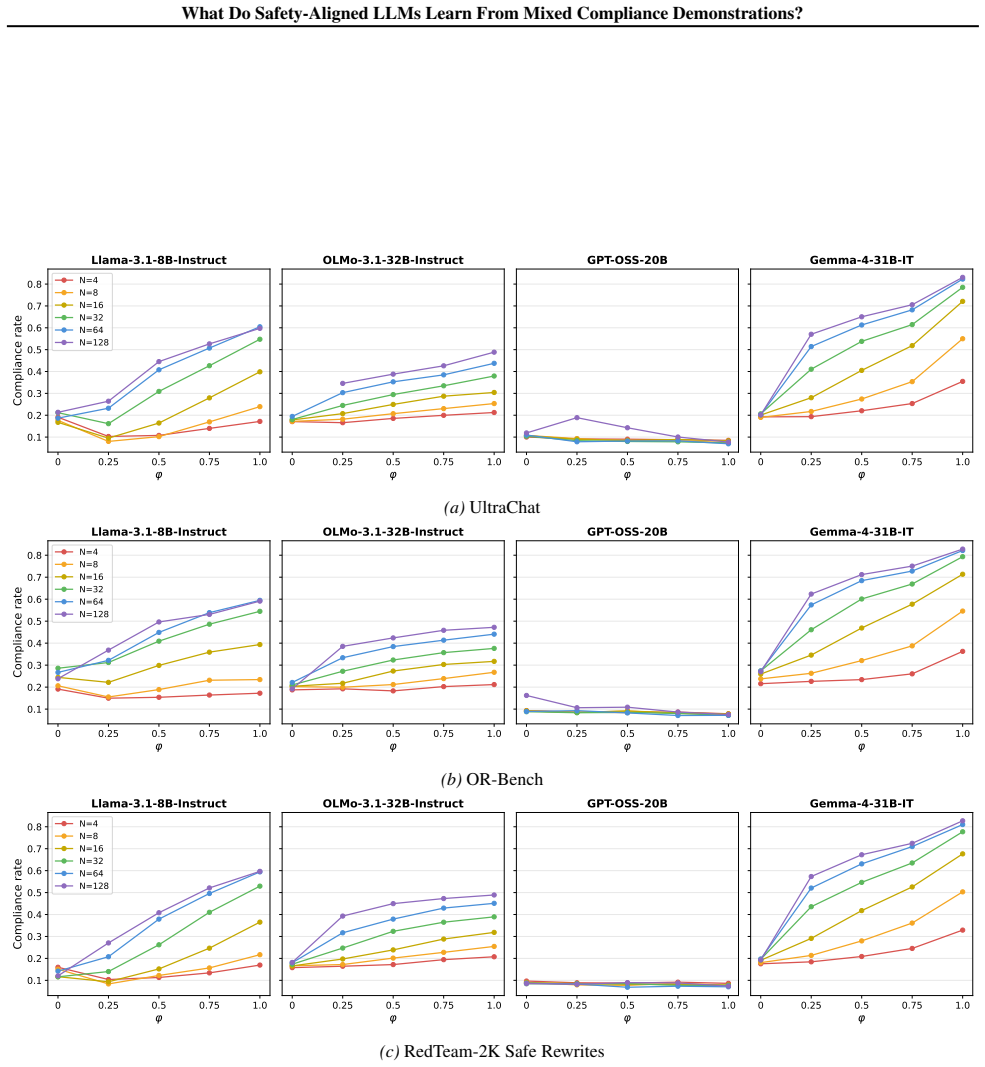
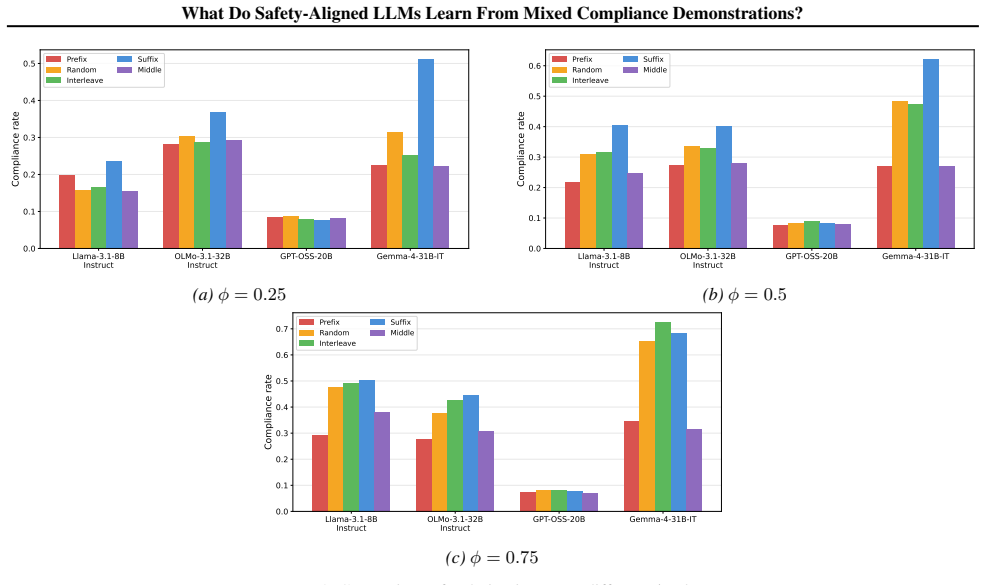



read the original abstract
Prior work has shown that in-context demonstrations can jailbreak language models, but it remains unclear how models interpret different types of compliance demonstrations. We study this by mixing benign compliance demonstrations (non-harmful request, helpful response) with harmful compliance demonstrations (harmful request, helpful response) and testing three hypotheses about how demonstration composition drives harmful compliance. Across four models, we find that benign and harmful demonstrations are not interchangeable: benign demonstrations can either reduce or increase harmful compliance depending on the model. We further show that preference optimization is the critical training stage that prevents benign demonstrations from increasing harmful compliance, that demonstration ordering exhibits strong recency bias, and that models differ in how refusal interacts with in-context learning: some adopt demonstrated formatting even when refusing, while others override all in-context signals upon refusal. Taken together, this work moves beyond showing that demonstration-based jailbreaking works to characterizing how it works: what models extract from compliance demonstrations depends on demonstration content, ordering, and training methodology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines how safety-aligned LLMs process mixed in-context demonstrations consisting of benign compliance (non-harmful request + helpful response) and harmful compliance (harmful request + helpful response). It tests three hypotheses across four models, reporting that benign and harmful demonstrations are not interchangeable, that preference optimization (PO) is the critical training stage preventing benign demonstrations from increasing harmful compliance, that demonstration ordering shows strong recency bias, and that models differ in how refusal interacts with in-context signals (some adopt demonstrated formatting while refusing, others override all signals upon refusal).
Significance. If the central empirical claims hold after proper controls and statistical validation, the work would be significant for moving the jailbreaking literature from existence proofs to mechanistic characterization of how demonstration content, ordering, and training stage interact with safety alignment. The reported differences in refusal behavior and the isolation of PO as a key factor could inform more targeted alignment techniques.
major comments (3)
- [Abstract, §4] Abstract and §4 (results on PO): the claim that 'preference optimization is the critical training stage that prevents benign demonstrations from increasing harmful compliance' is load-bearing for the paper's main contribution, yet the abstract and reported results supply no information on model matching (size, architecture, pretraining corpus, or other variables held constant across PO vs. non-PO models), prompt templates, or statistical tests isolating the PO stage from model-specific artifacts. Without these, the attribution cannot be distinguished from the skeptic concern that unstated differences drive the observed effects.
- [Abstract, Methods] Abstract and methods section: the abstract states results 'across four models and three hypotheses' but provides no sample sizes, number of prompts per condition, error bars, controls for prompt formatting, or statistical validation (e.g., significance tests or effect-size reporting). This absence makes it impossible to assess whether the data support the reported differences in compliance rates or the recency-bias finding.
- [§5] §5 (refusal interaction results): the distinction that 'some adopt demonstrated formatting even when refusing, while others override all in-context signals upon refusal' is presented as a model difference, but without details on how refusal was operationalized, how formatting adoption was measured, or controls for prompt wording, it is unclear whether the observed variation is driven by training stage, model family, or unstated prompt choices.
minor comments (1)
- [Abstract] The abstract is unusually long and contains the core claims; consider moving some quantitative or methodological detail into a dedicated methods paragraph or table for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight areas where additional documentation will strengthen the manuscript's claims. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (results on PO): the claim that 'preference optimization is the critical training stage that prevents benign demonstrations from increasing harmful compliance' is load-bearing for the paper's main contribution, yet the abstract and reported results supply no information on model matching (size, architecture, pretraining corpus, or other variables held constant across PO vs. non-PO models), prompt templates, or statistical tests isolating the PO stage from model-specific artifacts. Without these, the attribution cannot be distinguished from the skeptic concern that unstated differences drive the observed effects.
Authors: We agree that explicit documentation of model characteristics and statistical controls is necessary to support the attribution to the preference optimization stage. The four models were selected to enable comparisons across training stages (including pre- and post-PO variants where available in open releases), but the current text does not sufficiently detail this. In revision we will add a methods table listing model sizes, architectures, known pretraining corpora, and training stages for each model. We will also report statistical tests (e.g., significance levels and effect sizes) for the PO-related comparisons and move prompt templates to an appendix. These additions will allow readers to evaluate whether the observed effects are driven by PO rather than other model differences. revision: yes
-
Referee: [Abstract, Methods] Abstract and methods section: the abstract states results 'across four models and three hypotheses' but provides no sample sizes, number of prompts per condition, error bars, controls for prompt formatting, or statistical validation (e.g., significance tests or effect-size reporting). This absence makes it impossible to assess whether the data support the reported differences in compliance rates or the recency-bias finding.
Authors: We acknowledge that the abstract and methods lack the quantitative reporting details needed for full evaluation. The experiments were conducted with a fixed prompt set per hypothesis and condition (with multiple trials to assess variability), but these parameters are not stated. In the revised manuscript we will update the methods section to report exact sample sizes and number of prompts per condition, include error bars on all relevant figures, describe controls for prompt formatting, and add statistical validation including significance tests and effect sizes for compliance rates and recency bias. The abstract itself will remain high-level, but the methods will now contain the requested information. revision: yes
-
Referee: [§5] §5 (refusal interaction results): the distinction that 'some adopt demonstrated formatting even when refusing, while others override all in-context signals upon refusal' is presented as a model difference, but without details on how refusal was operationalized, how formatting adoption was measured, or controls for prompt wording, it is unclear whether the observed variation is driven by training stage, model family, or unstated prompt choices.
Authors: We agree that the operational definitions require more explicit description to support the reported model differences. Refusal was detected via a combination of keyword matching for common refusal phrases and manual review of a subset of outputs; formatting adoption was measured by checking whether responses mirrored demonstrated structural elements (e.g., specific prefixes or response formats). In revision we will expand §5 with these definitions, include the exact criteria and any inter-annotator checks, and note the standardized prompt templates used across models to control for wording effects. This will clarify the basis for attributing differences to model behavior rather than prompt artifacts. revision: yes
Circularity Check
No circularity: purely empirical observations with no derivations or self-referential reductions
full rationale
The paper is an empirical study that mixes benign and harmful compliance demonstrations, tests three hypotheses across four models, and reports observational findings on how demonstration content, ordering, and training stage (preference optimization) affect harmful compliance. The abstract and described content contain no equations, no fitted parameters presented as predictions, no uniqueness theorems, no ansatzes, and no load-bearing self-citations that reduce any claim to its own inputs by construction. All central results are direct experimental measurements rather than derivations that collapse to the inputs. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
URL https:// huggingface.co/google/gemma-4-31B-it. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
Han, S., Rao, K., Ettinger, A., Jiang, L., Lin, B. Y ., Lambert, N., Choi, Y ., and Dziri, N. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs.arXiv preprint arXiv:2406.18495,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
In-context learn- ing creates task vectors
Hendel, R., Geva, M., and Globerson, A. In-context learn- ing creates task vectors. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 9318– 9333,
2023
-
[5]
Luo, W., Ma, S., Liu, X., Guo, X., and Xiao, C. JailBreakV- 28K: A benchmark for assessing the robustness of mul- timodal large language models against jailbreak attacks. arXiv preprint arXiv:2404.03027,
-
[6]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., Forsyth, D., and Hendrycks, D. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Rethinking the role of demonstrations: What makes in-context learning work? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp
Min, S., Lyu, X., Holtzman, A., Artetxe, M., Lewis, M., Hajishirzi, H., and Zettlemoyer, L. Rethinking the role of demonstrations: What makes in-context learning work? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11048– 11064,
2022
-
[8]
URL https://arxiv.org/abs/2512.13961. 9 What Do Safety-Aligned LLMs Learn From Mixed Compliance Demonstrations? OpenAI. gpt-oss-120b & gpt-oss-20b Model Card,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
gpt-oss-120b & gpt-oss-20b Model Card
URLhttps://arxiv.org/abs/2508.10925. Turner, A. M., Thiergart, L., Leech, G., Udell, D., V´azquez, J. J., Mini, U., and MacDiarmid, M. Steering language models with activation engineering,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Sorry-bench: Systematically evaluating large language model safety refusal
Xie, T., Qi, X., Zeng, Y ., Huang, Y ., Sehwag, U. M., Huang, K., He, L., Wei, B., Li, D., Sheng, Y ., Jia, R., Li, B., Li, K., Chen, D., Henderson, P., and Mittal, P. SORRY-Bench: Systematically evaluating large language model safety re- fusal behaviors.arXiv preprint arXiv:2406.14598,
-
[11]
M., Kim, J., Kim, H
Yoo, K. M., Kim, J., Kim, H. J., Cho, H., Jo, H., Lee, S.-W., Lee, S.-g., and Kim, T. Ground-truth labels matter: A deeper look into input-label demonstrations. InProceed- ings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 2422–2437,
2022
-
[12]
Harmful request: yes\nResponse refusal:
10 What Do Safety-Aligned LLMs Learn From Mixed Compliance Demonstrations? A. Additional Experimental Setup Details Inference settings.Responses are generated with temperature T= 0.7 and maximum output length 1000 tokens. Each experimental condition is run for two passes over the full evaluation set to average over both target-query variation and sampling...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.