Execution-State Capsules: Graph-Bound Execution-State Checkpoint and Restore for Low-Latency, Small-Batch, On-Device Physical-AI Serving
Pith reviewed 2026-06-26 17:37 UTC · model grok-4.3
The pith
Execution-state capsules checkpoint and restore the full LLM execution state at graph-bound boundaries for sub-millisecond reuse in low-latency on-device serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
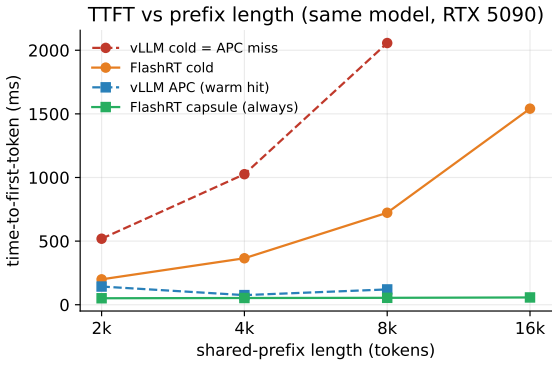
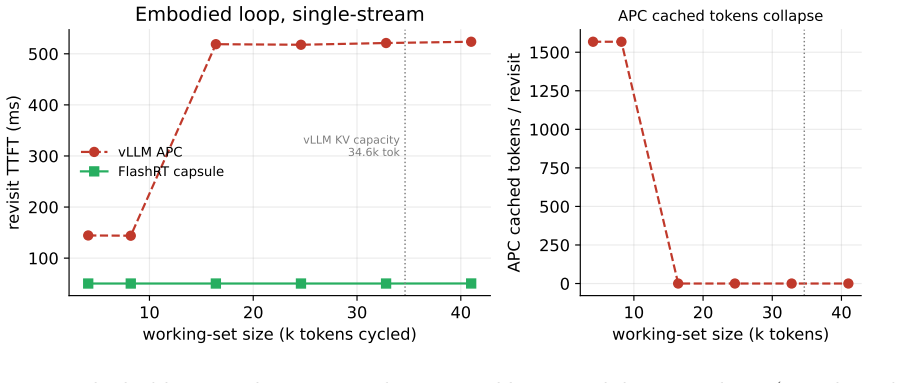
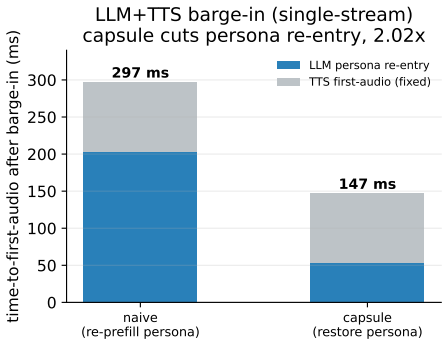
FlashRT's execution-state capsules snapshot, restore, fork, or roll back the entire execution boundary, including KV, recurrent state, convolution state, MTP state, and metadata. On an RTX 5090 the restore is byte-exact at the stored-state level and token-identical under greedy decode; GPU-resident snapshot and restore complete in sub-milliseconds. TTFT speedup over cold prefill grows from 3.9x at 2k tokens to 27x at 16k tokens. A KV-only ablation diverges, showing recurrent state is load-bearing. The same properties hold on Jetson AGX Thor and DGX Spark.
What carries the argument
execution-state capsules: graph-bound checkpoint and restore for the complete restorable state at a committed boundary, implemented by running captured graph plans over contiguous static buffers with no block-table indirection.
If this is right
- Capsule restore is byte-exact at the stored-state level and token-identical under greedy decode.
- GPU-resident snapshot and restore complete in sub-milliseconds.
- TTFT speedup over cold prefill grows from 3.9x at 2k tokens to 27x at 16k tokens.
- A KV-only ablation diverges, confirming that recurrent state must be included.
- The same correctness and structural properties hold on Jetson AGX Thor and DGX Spark.
Where Pith is reading between the lines
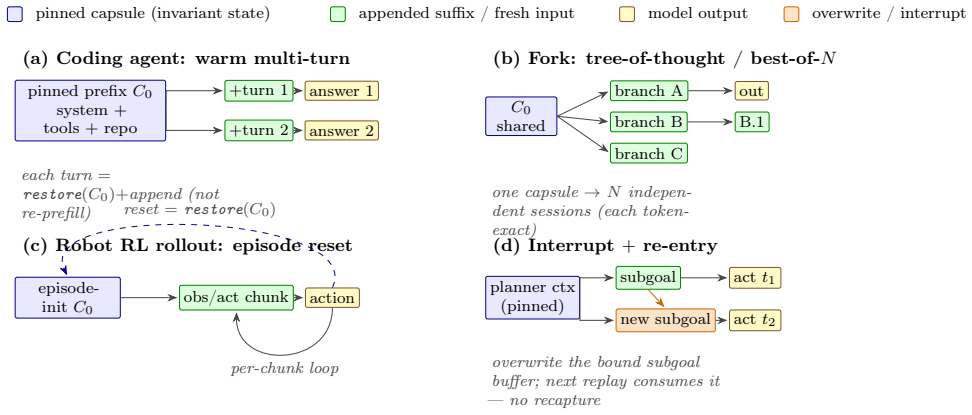
- Capsules could support repeated branching inside robotic control loops without recomputing prior execution prefixes.
- The closed-buffer assumption may restrict direct use with models that rely on dynamic memory allocation during inference.
- Hybrid schedulers could route latency-critical interactive paths through capsules while routing bulk throughput through conventional KV caches.
Load-bearing premise
The live execution state forms a closed set of named buffers that can be managed via captured graph plans over contiguous static buffers with no block-table indirection.
What would settle it
A restore operation that produces a different token sequence than re-execution from the same starting point under identical greedy decoding, or a measured GPU-resident restore latency exceeding the reported sub-millisecond range on the tested hardware.
Figures




read the original abstract
Mainstream LLM serving systems reuse prefix work mainly through paged or radix key-value (KV) caches. This is highly effective for high-throughput, high-concurrency serving, but it manages only one positional fragment of execution state: the KV cache. We study the opposite regime: low-latency, small-batch, on-device physical-AI serving, where interactive LLM agents, speech systems, and robot policies repeatedly branch, reset, interrupt, and re-enter under tight responsiveness budgets. We introduce execution-state capsules, a graph-bound checkpoint and restore mechanism for the complete restorable state at a committed boundary. FlashRT is a white-box, backend-facing kernel runtime whose evaluated NVIDIA CUDA backend runs captured graph plans over contiguous static buffers with no block-table indirection. Because the live state is a closed set of named buffers, a capsule can snapshot, restore, fork, or roll back the whole execution boundary, including KV, recurrent state, convolution state, MTP state, and metadata. This moves reuse from token-addressed KV fragments to graph-bound execution-state boundaries. On an RTX 5090, capsule restore is byte-exact at the stored-state level and token-identical under greedy decode. A KV-only ablation diverges, showing that recurrent state is load-bearing. GPU-resident snapshot and restore are sub-millisecond, and TTFT speedup over cold prefill grows from 3.9x at 2k tokens to 27x at 16k tokens. On Jetson AGX Thor and DGX Spark, the same correctness and structural properties hold. Capsules are not a replacement for high-throughput KV-cache serving; they define a complementary latency-first serving point for explicit execution-state reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces execution-state capsules, a graph-bound checkpoint/restore mechanism for the complete restorable execution state (KV, recurrent, convolution, MTP, metadata) at committed boundaries in low-latency small-batch on-device LLM serving. FlashRT is presented as a white-box runtime whose NVIDIA CUDA backend uses captured graph plans over contiguous static buffers with no block-table indirection, enabling byte-exact snapshot/restore, token-identical greedy outputs, sub-millisecond GPU-resident operations, and TTFT speedups of 3.9x (2k tokens) to 27x (16k tokens) over cold prefill. A KV-only ablation is reported to diverge, and the same properties are claimed to hold on Jetson AGX Thor and DGX Spark hardware.
Significance. If the central mechanism and empirical claims hold, the work defines a latency-first complementary point to paged KV-cache serving for interactive physical-AI workloads that require frequent branching, reset, and re-entry. The multi-hardware evaluation and the KV-only ablation that isolates recurrent state as load-bearing are concrete strengths; the absence of fitted parameters or self-referential derivations is appropriate for an empirical runtime contribution.
major comments (2)
- [Abstract] Abstract: the central claim that 'the live state is a closed set of named buffers' enabling complete byte-exact snapshot/restore rests on the unverified assertion that all components (KV, recurrent, convolution, MTP, metadata) are captured by static graph plans with no dynamic allocation or indirection; without an explicit enumeration of these buffers or the capture procedure, the completeness guarantee and the interpretation of the KV-only ablation cannot be assessed.
- [Abstract] Abstract: concrete performance numbers (sub-millisecond restore, 3.9x–27x TTFT speedup) and correctness properties (byte-exact at stored-state level, token-identical under greedy decode) are reported without methods details, number of trials, error bars, or raw data, which is load-bearing for the empirical support of the speedup claims across hardware platforms.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and positive assessment of the work's significance for latency-first on-device serving. We respond to each major comment below, committing to revisions that add the requested details for verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the live state is a closed set of named buffers' enabling complete byte-exact snapshot/restore rests on the unverified assertion that all components (KV, recurrent, convolution, MTP, metadata) are captured by static graph plans with no dynamic allocation or indirection; without an explicit enumeration of these buffers or the capture procedure, the completeness guarantee and the interpretation of the KV-only ablation cannot be assessed.
Authors: We agree that the abstract's brevity leaves the buffer set and capture procedure implicit. In revision we will add a dedicated Methods subsection 'Buffer Enumeration and Graph Capture Procedure' that explicitly enumerates every restorable named buffer (per-layer KV tensors, recurrent/SSM hidden states, convolution buffers, MTP states, and metadata) together with the exact sequence of CUDA graph captures that enforce contiguous static allocation and eliminate dynamic allocation or block-table indirection. This addition will directly substantiate the closed-set claim and clarify why the KV-only ablation diverges. revision: yes
-
Referee: [Abstract] Abstract: concrete performance numbers (sub-millisecond restore, 3.9x–27x TTFT speedup) and correctness properties (byte-exact at stored-state level, token-identical under greedy decode) are reported without methods details, number of trials, error bars, or raw data, which is load-bearing for the empirical support of the speedup claims across hardware platforms.
Authors: We acknowledge that the reported numbers and correctness properties require fuller methodological support. The revised manuscript will expand the Experiments section with: (i) the precise measurement protocol (CUDA event timing with full synchronization barriers), (ii) the number of independent trials per configuration (minimum 50) together with standard-deviation error bars, (iii) per-platform configuration details for RTX 5090, Jetson AGX Thor, and DGX Spark, and (iv) a statement that raw timing and output logs will be released in a public repository. These changes will strengthen the empirical grounding of the speedup and correctness claims. revision: yes
Circularity Check
No circularity; empirical system evaluation with no derivations or self-referential reductions
full rationale
The paper introduces a runtime mechanism (execution-state capsules via FlashRT) for checkpoint/restore of LLM execution state and evaluates it empirically on NVIDIA hardware with reported TTFT speedups, byte-exact restores, and KV-only ablations. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text. The central premise (state as closed set of named static buffers with captured graphs) is a design assumption enabling the mechanism, not a reduction to prior results or self-definition. Claims rest on direct measurement rather than any load-bearing derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GPU execution state at committed boundaries can be represented as a closed set of named buffers managed via captured static graph plans
invented entities (1)
-
execution-state capsule
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Embodied.cpp: A Portable Inference Runtime of Embodied AI Models on Heterogeneous Robots
Embodied.cpp introduces a portable C++ inference runtime with modular layers for deploying VLA and WAM models on heterogeneous robots, reporting 100% and 91% task success on two models plus memory reduction on a WAM b...
Reference graph
Works this paper leans on
-
[1]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774, 2024
Pith/arXiv arXiv 2024
-
[2]
CRIU: Checkpoint/restore in userspace
CRIU Project. CRIU: Checkpoint/restore in userspace. GitHub repository, https://github.com/ checkpoint-restore/criu, 2024
2024
-
[3]
Prompt cache: Modular attention reuse for low-latency inference
In Gim, Guojun Chen, Seung seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference. InProceedings of Machine Learning and Systems (MLSys), 2024.https://arxiv.org/abs/2311.04934
arXiv 2024
-
[4]
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[5]
Fu, Christopher Ré, and Azalia Mirhoseini
Jordan Juravsky, Bradley Brown, Ryan Ehrlich, Daniel Y. Fu, Christopher Ré, and Azalia Mirhoseini. Hydragen: High-throughput LLM inference with shared prefixes.arXiv preprint arXiv:2402.05099, 2024
arXiv 2024
-
[6]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023.https://arxiv.org/abs/2309.06180
Pith/arXiv arXiv 2023
-
[7]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[8]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[9]
CUDA C++ programming guide: CUDA graphs
NVIDIA. CUDA C++ programming guide: CUDA graphs. https://docs.nvidia.com/cuda/ cuda-c-programming-guide/, 2024
2024
-
[10]
Physical Intelligence, Kevin Black, et al.π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[11]
vAttention: Dynamic memory management for serving LLMs without PagedAttention
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, and Ashish Panwar. vAttention: Dynamic memory management for serving LLMs without PagedAttention. InProceedings of the 30th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2025.https://arxiv.org/abs/2405.04437
arXiv 2025
-
[12]
FlashRT: A white-box kernel-level inference runtime
Liang Su. FlashRT: A white-box kernel-level inference runtime. https://github.com/ flashrt-project/FlashRT, 2026
2026
-
[13]
Gated delta networks: Improving Mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving Mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
Pith/arXiv arXiv 2024
-
[14]
Stateful large language model serving with Pensieve
Lingfan Yu, Jinkun Lin, and Jinyang Li. Stateful large language model serving with Pensieve. In Proceedings of the Twentieth European Conference on Computer Systems (EuroSys), 2025.https: //arxiv.org/abs/2312.05516
arXiv 2025
-
[15]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024.https://arxiv.org/abs/2312.07104. 26
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.