From Sparse X-rays to 3D CT: Training-Free Reconstruction with Diffusion Priors
Pith reviewed 2026-06-26 15:33 UTC · model grok-4.3
The pith
A frozen 3D diffusion prior serves as a universal solver for volumetric medical inverse problems via task-specific sampling guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TF-PRDiT converts a frozen 3D Diffusion Transformer prior into a versatile inverse-problem solver by enforcing measurement consistency through a task-specific forward operator during posterior sampling, without any weight updates; the method combines predictor-corrector sampling with likelihood-based guidance on the denoised estimate and demonstrates this on X-ray-to-CT with consistent gains from one to twelve views plus direct transfer to other volumetric tasks.
What carries the argument
Frozen voxel-level 3D Diffusion Transformer prior with task-specific likelihood guidance applied to the denoised prediction during predictor-corrector sampling.
If this is right
- The same model produces improving reconstructions as the number of input X-rays increases from one to twelve.
- Replacing the forward operator with a new measurement model immediately enables 3D super-resolution, infilling, or deblurring.
- No task-specific training or fine-tuning is required when the inverse problem or number of measurements changes.
- A single prior can be reused across diverse conditional settings while preserving the underlying 3D anatomical distribution.
Where Pith is reading between the lines
- Hospitals could maintain one large prior model and swap only the projector code for different scanner geometries or modalities.
- The method may reduce the data and compute barrier for deploying 3D reconstruction in low-resource settings where labeled paired data are scarce.
- If the prior encodes population-level anatomy, performance on rare pathologies would depend on how well those cases align with the pretraining distribution.
Load-bearing premise
The pretrained diffusion model already contains enough general anatomical knowledge that guidance during sampling can enforce data consistency without needing to adapt the model weights.
What would settle it
If adding more X-ray views beyond six on LIDC-IDRI data yields no further improvement or produces visible anatomical distortions, the claim that one prior scales universally would be falsified.
Figures




read the original abstract
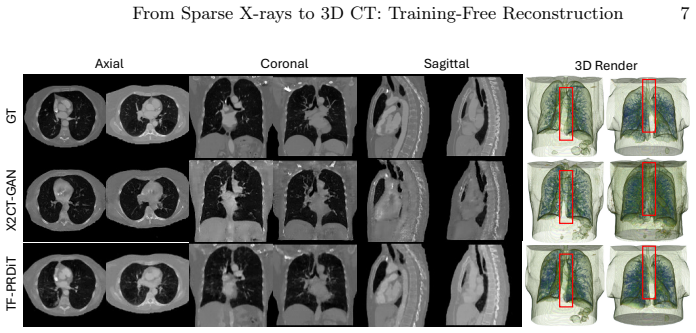
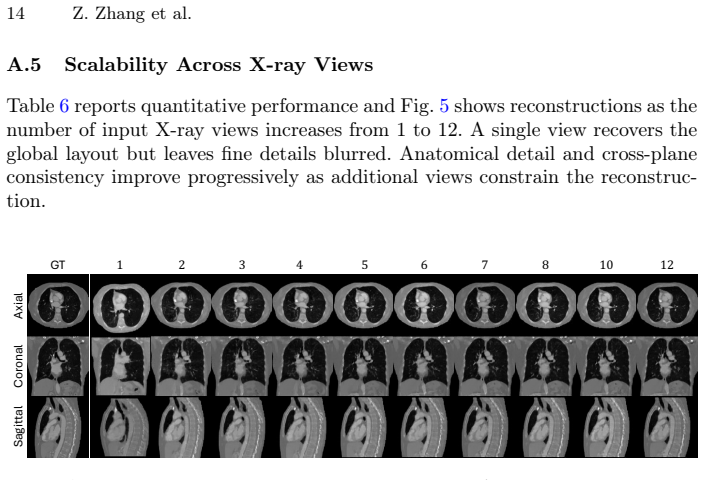
Solving 3D medical inverse problems typically requires training dedicated supervised models for each specific task and measurement setting. To break this dependency, we present TF-PRDiT: a training-free conditional sampling framework that converts a frozen voxel-level 3D Diffusion Transformer prior into a versatile inverse medical problem solver. Building on the posterior-sampling view of diffusion inverse solvers, TF-PRDiT enforces measurement consistency during sampling via a task-specific forward operator rather than updating model weights, enabling a single pretrained prior to be reused across diverse conditional settings. Our method combines a predictor-corrector sampler with likelihood-based guidance on the denoised prediction, providing stable data-fidelity correction while preserving the underlying 3D anatomical prior. We highlight our framework's capability on the challenging task of X-ray-to-CT reconstruction by integrating a differentiable DRR projector to allow gradients to propagate directly from projection space back to voxels without any retraining. Experiments on LIDC-IDRI demonstrate that TF-PRDiT achieves strong reconstruction quality and uniquely scales to an arbitrary number of input X-rays (1-12) under a unified model, with performance improving consistently as additional views are provided. Beyond X-ray-to-CT, we show that simply swapping the forward operator extends the same frozen model to 3D super-resolution, volumetric infilling, and deblurring without any task-specific retraining, demonstrating that a single 3D diffusion prior can serve as a universal solver for volumetric medical inverse problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TF-PRDiT, a training-free posterior sampling framework that repurposes a single frozen 3D Diffusion Transformer (DiT) prior as a solver for volumetric medical inverse problems. By swapping only the differentiable forward operator (e.g., a DRR projector for X-ray-to-CT) and applying likelihood guidance on the denoised estimate within a predictor-corrector sampler, the method enforces measurement consistency without any weight updates or task-specific retraining. Experiments on LIDC-IDRI are claimed to show strong X-ray-to-CT reconstruction quality that improves consistently with 1–12 views, plus generalization to super-resolution, infilling, and deblurring via operator swap.
Significance. If validated, the result would demonstrate that a single pretrained 3D anatomical diffusion prior can function as a universal solver across inverse problems, eliminating the need for per-task supervised retraining in data-scarce medical imaging settings. The training-free reuse of an external frozen prior and the explicit use of a differentiable forward operator are notable strengths that align with the central claim.
major comments (3)
- [Experiments] Experiments section (referenced in abstract): the claim of 'strong reconstruction quality and consistent improvement with more views' is unsupported by any quantitative tables, PSNR/SSIM values, error bars, or baseline comparisons against supervised or other diffusion-based methods; without these, the scaling behavior and superiority cannot be assessed.
- [Method] §3 (likelihood guidance implementation): the description of 'likelihood-based guidance on the denoised prediction' lacks the precise form of the guidance term, the choice of guidance scale schedule, and any analysis of how the frozen prior is prevented from being overridden by the data term; this is load-bearing for the 'preserving the underlying 3D anatomical prior' claim.
- [Experiments] Abstract and §4: the generalization claim ('simply swapping the forward operator extends the same frozen model to 3D super-resolution, volumetric infilling, and deblurring') is stated without any quantitative results or even qualitative figures for those tasks, leaving the 'universal solver' thesis unverified beyond the X-ray-to-CT case.
minor comments (2)
- [Method] Notation for the predictor-corrector sampler and the exact form of the forward operator (DRR) should be introduced with equations rather than prose only.
- [Experiments] The LIDC-IDRI data split, number of test cases, and view-angle sampling protocol are not specified, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation of our training-free framework. We address each major point below and commit to revisions that strengthen the quantitative support, methodological precision, and verification of generalization claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section (referenced in abstract): the claim of 'strong reconstruction quality and consistent improvement with more views' is unsupported by any quantitative tables, PSNR/SSIM values, error bars, or baseline comparisons against supervised or other diffusion-based methods; without these, the scaling behavior and superiority cannot be assessed.
Authors: We acknowledge that the current version presents the X-ray-to-CT results primarily through qualitative figures and visual comparisons. To rigorously support the claims of reconstruction quality and consistent improvement from 1–12 views, we will add a quantitative table in the revised Experiments section reporting PSNR and SSIM (with standard deviations across multiple test cases), plus direct comparisons against relevant supervised reconstruction baselines and other diffusion-based methods. This will enable clear assessment of scaling behavior. revision: yes
-
Referee: [Method] §3 (likelihood guidance implementation): the description of 'likelihood-based guidance on the denoised prediction' lacks the precise form of the guidance term, the choice of guidance scale schedule, and any analysis of how the frozen prior is prevented from being overridden by the data term; this is load-bearing for the 'preserving the underlying 3D anatomical prior' claim.
Authors: We agree that §3 requires additional technical detail to make the guidance mechanism fully reproducible and to substantiate the prior-preservation claim. In the revision we will insert the exact mathematical expression for the likelihood guidance term applied to the denoised prediction, specify the guidance-scale schedule employed during sampling, and include a short analysis (via ablation or gradient-norm discussion) showing how the data term is balanced against the frozen DiT prior so that anatomical structure is not overridden. revision: yes
-
Referee: [Experiments] Abstract and §4: the generalization claim ('simply swapping the forward operator extends the same frozen model to 3D super-resolution, volumetric infilling, and deblurring') is stated without any quantitative results or even qualitative figures for those tasks, leaving the 'universal solver' thesis unverified beyond the X-ray-to-CT case.
Authors: The manuscript currently illustrates the operator-swap principle conceptually and states that the same frozen prior applies to the additional tasks, but does not yet supply dedicated quantitative metrics or figures for super-resolution, infilling, and deblurring. To verify the universal-solver thesis we will add a short subsection (or appendix) containing both qualitative examples and quantitative PSNR/SSIM results for at least two of these tasks, obtained by simply exchanging the forward operator while keeping all other components fixed. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a training-free posterior sampling framework that reuses a single frozen pretrained 3D Diffusion Transformer prior across tasks by swapping only the forward operator and applying likelihood guidance. The central construction relies on an external pretrained model and a differentiable measurement operator; no parameters are fitted to the target measurements, no predictions are defined in terms of fitted quantities by construction, and no load-bearing self-citations or uniqueness theorems from the same authors are invoked to justify the method. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The frozen voxel-level 3D Diffusion Transformer prior encodes the distribution of realistic anatomical structures needed for multiple inverse tasks.
Reference graph
Works this paper leans on
-
[1]
Medical Physics38(2), 915–931 (2011)
Armato III, S.G., McLennan, G., Bidaut, L., McNitt-Gray, M.F., Meyer, C.R., Reeves, A.P., Zhao, B., Aberle, D.R., Henschke, C.I., Hoffman, E.A., et al.: The lungimagedatabaseconsortium(lidc)andimagedatabaseresourceinitiative(idri): a completed reference database of lung nodules on ct scans. Medical Physics38(2), 915–931 (2011)
2011
-
[2]
arXiv preprint arXiv:2209.14687 (2022)
Chung, H., Kim, J., Mccann, M.T., Klasky, M.L., Ye, J.C.: Diffusion posterior sam- pling for general noisy inverse problems. arXiv preprint arXiv:2209.14687 (2022)
Pith/arXiv arXiv 2022
-
[3]
In: Workshop on Clinical Image-Based Procedures
Gopalakrishnan, V., Golland, P.: Fast auto-differentiable digitally reconstructed radiographs for solving inverse problems in intraoperative imaging. In: Workshop on Clinical Image-Based Procedures. pp. 1–11. Springer (2022)
2022
-
[4]
In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Jeong, Y.S., Yoo, H.B., Chun, I.Y.: Dx2ct: Diffusion model for 3d ct reconstruction from bi or mono-planar 2d x-ray (s). In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2025)
2025
-
[5]
IEEE transactions on image processing 26(9), 4509–4522 (2017)
Jin, K.H., McCann, M.T., Froustey, E., Unser, M.: Deep convolutional neural network for inverse problems in imaging. IEEE transactions on image processing 26(9), 4509–4522 (2017)
2017
-
[6]
Advances in neural information processing systems35, 23593–23606 (2022)
Kawar, B., Elad, M., Ermon, S., Song, J.: Denoising diffusion restoration models. Advances in neural information processing systems35, 23593–23606 (2022)
2022
-
[7]
In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Kyung, D., Jo, K., Choo, J., Lee, J., Choi, E.: Perspective projection-based 3d ct reconstruction from biplanar x-rays. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
2023
-
[8]
In: European Conference on Computer Vision
Liu,X.,Qiao,Z.,Liu,R.,Li,H.,Zhang,J.,Zhen,X.,Qian,Z.,Zhang,B.:Diffux2ct: Diffusion learning to reconstruct ct images from biplanar x-rays. In: European Conference on Computer Vision. pp. 458–476. Springer (2024)
2024
-
[9]
In: Proceedings of the XVI’th Interna- tional Conference on the use of Computers in Radiotherapy (ICCR), Amsterdam, Netherlands
Sharp, G.C., Li, R., Wolfgang, J., Chen, G., Peroni, M., Spadea, M.F., Mori, S., Zhang, J., Shackleford, J., Kandasamy, N.: Plastimatch: an open source software suite for radiotherapy image processing. In: Proceedings of the XVI’th Interna- tional Conference on the use of Computers in Radiotherapy (ICCR), Amsterdam, Netherlands. vol. 3 (2010)
2010
-
[10]
arXiv preprint arXiv:2111.08005 (2021)
Song, Y., Shen, L., Xing, L., Ermon, S.: Solving inverse problems in medical imag- ing with score-based generative models. arXiv preprint arXiv:2111.08005 (2021)
arXiv 2021
-
[11]
arXiv preprint arXiv:2212.00490 (2022)
Wang, Y., Yu, J., Zhang, J.: Zero-shot image restoration using denoising diffusion null-space model. arXiv preprint arXiv:2212.00490 (2022)
arXiv 2022
-
[12]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ying, X., Guo, H., Ma, K., Wu, J., Weng, Z., Zheng, Y.: X2ct-gan: reconstructing ct from biplanar x-rays with generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10619– 10628 (2019)
2019
-
[14]
Yu, J., Wang, Y., Zhao, C., Ghanem, B., Zhang, J.: Freedom: Training-free energy- guidedconditionaldiffusionmodel.In:ProceedingsoftheIEEE/CVFInternational Conference on Computer Vision. pp. 23174–23184 (2023)
2023
-
[15]
In: Medical Image Computing and Computer-Assisted Intervention – MICCAI 2022
Zha, R., Zhang, Y., Li, H.: NAF: Neural attenuation fields for sparse-view CBCT reconstruction. In: Medical Image Computing and Computer-Assisted Intervention – MICCAI 2022. pp. 442–452. Springer (2022) 10 Z. Zhang et al
2022
-
[16]
arXiv preprint arXiv:2310.17167 (2023)
Zhang, Z., Ehinger, K.A., Drummond, T.: Improving denoising diffusion models via simultaneous estimation of image and noise. arXiv preprint arXiv:2310.17167 (2023)
arXiv 2023
-
[17]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, Z., Ehinger, K.A., Drummond, T.: TCAM-Diff: Triplane-aware cross- attention medical diffusion model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 22732–22740 (2025)
2025
-
[18]
Zhang, Z., Hiller, M., Ehinger, K.A., Drummond, T.: Pixel-level residual diffusion transformer: Scalable 3d CT volume generation. In: The Fourteenth International Conference on Learning Representations (2026) From Sparse X-rays to 3D CT: Training-Free Reconstruction 11 A Appendix The appendix is organized to separate implementation detail from empirical e...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.