Provably Sub-Linear Two-Timescale NeuroEvolution with Online Plasticity
Pith reviewed 2026-06-26 14:45 UTC · model grok-4.3
The pith
NEOL decouples neuroevolution into outer architecture search and inner online weight adaptation to prove sublinear regret.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
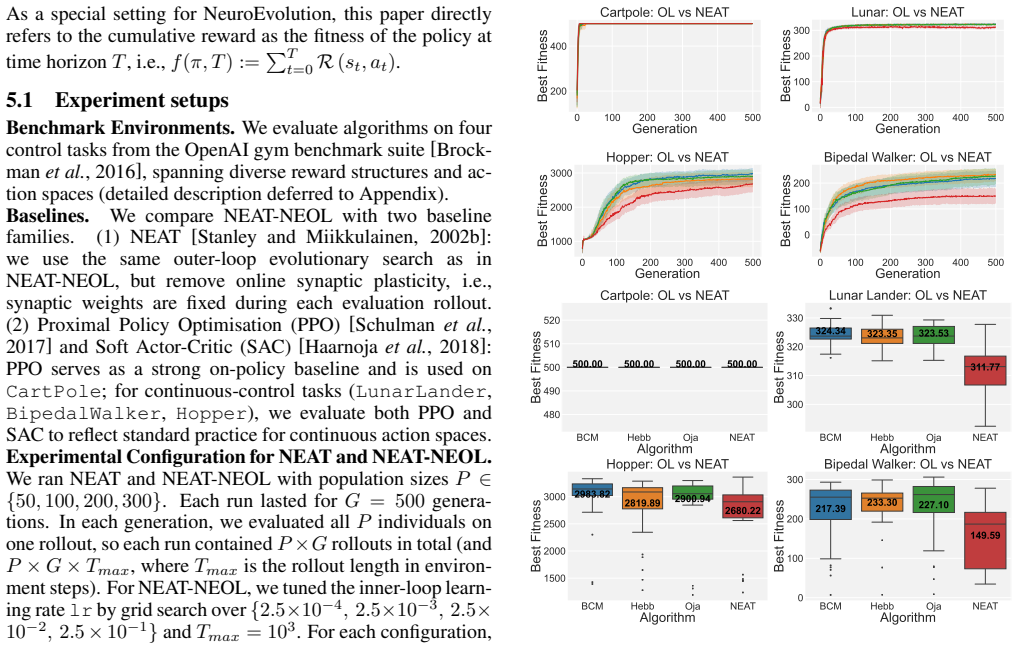
The NEOL framework decouples neuroevolution into an outer loop for architecture search and an inner loop for online weight adaptation via reward-modulated plasticity; under mild conditions the resulting two-timescale process is proved to achieve sublinear regret, and a NEAT-based implementation empirically outperforms pure NEAT while matching strong RL baselines on standard control tasks.
What carries the argument
Two-timescale decoupling of an outer architecture-search loop from an inner online weight-adaptation loop that uses reward-modulated plasticity.
If this is right
- NEOL attains sublinear regret where standard offline neuroevolution lacks such guarantees.
- A NEAT-based NEOL version reaches higher final fitness than pure NEAT under fixed interaction budgets.
- NEOL shows lower performance variance than pure NEAT across repeated runs.
- NEOL matches or exceeds several reinforcement-learning baselines on the tested control problems.
- Wilcoxon rank-sum tests and ablation studies support the observed gains from online plasticity.
Where Pith is reading between the lines
- The regret analysis may extend to other evolutionary algorithms if they can be similarly split into slow architecture search and fast weight plasticity.
- The separation of timescales could be tested in non-stationary control environments where online adaptation is especially valuable.
- Practical implementations could use the derived regret rate to set the relative frequencies of the outer and inner loops.
Load-bearing premise
The outer architecture-search loop and the inner online weight-adaptation loop can be treated as cleanly decoupled so that their interaction does not invalidate the regret bound.
What would settle it
A counter-example in which the cumulative regret of NEOL grows linearly or faster, under the same mild conditions used in the proof, would falsify the central claim.
Figures






read the original abstract
NeuroEvolution of Augmenting Topologies (NEAT) is a widely used neuroevolution algorithm for learning neural network architectures and weights for control tasks. However, standard offline optimisation searches for connection strengths directly, which can scale poorly in high-dimensional weight spaces and more difficult continuous control problems. Hybrid methods that combine neuroevolution with online learning can address this challenge, but their theoretical properties remain underexplored. This paper gives the first regret analysis for a general NeuroEvolutionary Online Learning (NEOL) framework, which decouples learning into two timescales: an outer loop for architecture search and an inner loop for online weight adaptation via rewardmodulated plasticity. Under mild conditions, we prove that NEOL achieves sublinear regret. Empirically, under fixed interaction budgets on four standard control benchmarks, a NEAT-based NEOL implementation achieves higher final fitness and lower variance than pure NEAT, and is competitive with strong reinforcement learning (RL) baselines on several tasks. The results are supported byWilcoxon rank-sum tests and ablation studies. Overall, the findings show that online plasticity can improve the sample efficiency and robustness of two-timescale neuroevolution. Code is available at https://github.com/boobaa2001/NeuroEvolution Online Learning NEOL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the NEOL framework, which decouples neuroevolution into an outer loop for architecture search (e.g., via NEAT) and an inner loop for online weight adaptation using reward-modulated plasticity. It provides the first regret analysis for this two-timescale setup, proving sublinear regret under mild conditions (stationarity of the effective MDP, bounded plasticity rates, Lipschitz continuity of the value function) via two-timescale stochastic approximation arguments. Empirically, a NEAT-based NEOL implementation outperforms pure NEAT on four control benchmarks under fixed budgets, with lower variance and competitiveness against RL baselines, supported by Wilcoxon tests and ablations. Code is provided.
Significance. If the regret bound holds, this supplies the first theoretical guarantee for hybrid neuroevolution-online plasticity methods, potentially explaining improved sample efficiency and robustness over pure offline search. The explicit conditions on timescale interaction and the use of standard stochastic approximation tools make the result falsifiable and extensible. Open code strengthens reproducibility.
minor comments (3)
- [Abstract] Abstract: 'rewardmodulated' is missing a hyphen; should read 'reward-modulated'.
- [Abstract] Abstract: 'byWilcoxon' is missing a space; should read 'by Wilcoxon'.
- [Abstract] Abstract: the GitHub link contains embedded spaces ('NeuroEvolution Online Learning NEOL'); provide a correctly formatted URL.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the NEOL framework, the regret analysis, and the empirical results. We appreciate the recommendation for minor revision and the recognition of the work's novelty in providing the first theoretical guarantees for this two-timescale hybrid approach.
Circularity Check
No significant circularity; derivation uses standard external arguments
full rationale
The paper's central claim is a sublinear regret bound for the NEOL two-timescale framework, derived via standard two-timescale stochastic approximation under stated conditions on stationarity, bounded rates, and Lipschitz continuity. No equations, fitted parameters, or predictions are presented that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the abstract and summary indicate the proof relies on established mathematical tools rather than internal redefinitions or ansatzes. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Online interactive neuro- evolution.Neural Processing Letters, 11(1):29–38,
[Agoginoet al., 2000 ] Adrian Agogino, Kenneth Stanley, and Risto Miikkulainen. Online interactive neuro- evolution.Neural Processing Letters, 11(1):29–38,
2000
-
[2]
Angeline, Gregory M
[Angelineet al., 1994 ] Peter J. Angeline, Gregory M. Saun- ders, and Jordan B. Pollack. An evolutionary algorithm that constructs recurrent neural networks.IEEE Transac- tions on Neural Networks, 5(1):54–65,
1994
-
[3]
Bauschke and Patrick L
[Bauschke and Combettes, 2017] Heinz H. Bauschke and Patrick L. Combettes.Correction to: Convex analysis and monotone operator theory in Hilbert spaces, pages C1– C4. Springer International Publishing, Cham,
2017
-
[4]
Dynamic programming
[Bellman, 1966] Richard Bellman. Dynamic programming. Science, 153(3731):34–37,
1966
-
[5]
Bienenstock, Leon N
[Bienenstocket al., 1982 ] Elie L. Bienenstock, Leon N. Cooper, and Paul W. Munro. Theory for the development of neuron selectivity: orientation specificity and binocu- lar interaction in visual cortex.Journal of Neuroscience, 2(1):32–48,
1982
-
[6]
[Brockmanet al., 2016 ] Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. OpenAI gym.arXiv preprint arXiv:1606.01540,
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Spike timing–dependent plasticity: a hebbian learning rule.Annual Review of Neuroscience, 31:25–46,
[Caporale and Dan, 2008] Natalia Caporale and Yang Dan. Spike timing–dependent plasticity: a hebbian learning rule.Annual Review of Neuroscience, 31:25–46,
2008
-
[8]
Neuroevolution is a competitive alternative to reinforcement learning for skill discovery
[Chalumeauet al., 2023 ] Felix Chalumeau, Raphael Boige, Bryan Lim, Valentin Mac´e, Maxime Allard, Arthur Flajo- let, Antoine Cully, and Thomas Pierrot. Neuroevolution is a competitive alternative to reinforcement learning for skill discovery. InICLR,
2023
-
[9]
Co-Reyes, Yingjie Miao, Daiyi Peng, Esteban Real, Quoc V
[Co-Reyeset al., 2021 ] John D. Co-Reyes, Yingjie Miao, Daiyi Peng, Esteban Real, Quoc V . Le, Sergey Levine, Honglak Lee, and Aleksandra Faust. Evolving reinforce- ment learning algorithms. InICLR,
2021
-
[10]
First steps towards a runtime analysis of neuroevolution
[Fischeret al., 2023 ] Paul Fischer, Emil Lundt Larsen, and Carsten Witt. First steps towards a runtime analysis of neuroevolution. InFOGA, pages 61–72,
2023
-
[11]
[Florian, 2007] R˘azvan V . Florian. Reinforcement learning through modulation of spike-timing–dependent synaptic plasticity.Neural Computation, 19(6):1468–1502,
2007
-
[12]
A decision-theoretic generalization of on-line learning and an application to boosting.Journal of com- puter and system sciences, 55(1):119–139,
[Freund and Schapire, 1997] Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of com- puter and system sciences, 55(1):119–139,
1997
-
[13]
Neuromodulated spike-timing-dependent plasticity and theory of three-factor learning rules.Fron- tiers in Neural Circuits, 9:85,
[Fr´emaux and Gerstner, 2016] Nicolas Fr ´emaux and Wul- fram Gerstner. Neuromodulated spike-timing-dependent plasticity and theory of three-factor learning rules.Fron- tiers in Neural Circuits, 9:85,
2016
-
[14]
Eligibil- ity traces and plasticity on behavioral time scales: exper- imental support of neohebbian three-factor learning rules
[Gerstneret al., 2018 ] Wulfram Gerstner, Marco Lehmann, Vasiliki Liakoni, Dane Corneil, and Johanni Brea. Eligibil- ity traces and plasticity on behavioral time scales: exper- imental support of neohebbian three-factor learning rules. Frontiers in Neural Circuits, 12:53,
2018
-
[15]
Soft actor-critic algorithms and applications.arXiv preprint,
[Haarnojaet al., 2018 ] Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, and Sergey Levine. Soft actor-critic algorithms and applications.arXiv preprint,
2018
-
[16]
A neu- roevolution approach to general atari game playing.IEEE Transactions on Computational Intelligence and AI in Games, 6(4):355–366,
[Hausknechtet al., 2014 ] Matthew Hausknecht, Joel Lehman, Risto Miikkulainen, and Peter Stone. A neu- roevolution approach to general atari game playing.IEEE Transactions on Computational Intelligence and AI in Games, 6(4):355–366,
2014
-
[17]
Hebb.The organization of behav- ior: a neuropsychological theory
[Hebb, 1949] Donald O. Hebb.The organization of behav- ior: a neuropsychological theory. John Wiley & Sons, New York,
1949
-
[18]
Probability inequali- ties for sums of bounded random variables.Journal of the American statistical association, 58(301):13–30,
[Hoeffding, 1963] Wassily Hoeffding. Probability inequali- ties for sums of bounded random variables.Journal of the American statistical association, 58(301):13–30,
1963
-
[19]
Holland.Adaptation in natural and artificial systems: an introductory analysis with ap- plications to biology, control, and artificial intelligence
[Holland, 1992] John H. Holland.Adaptation in natural and artificial systems: an introductory analysis with ap- plications to biology, control, and artificial intelligence. Complex Adaptive Systems. MIT Press, Cambridge, MA,
1992
-
[20]
Evolution-guided policy gradient in reinforcement learning.NeurIPS, 31,
[Khadka and Tumer, 2018] Shauharda Khadka and Kagan Tumer. Evolution-guided policy gradient in reinforcement learning.NeurIPS, 31,
2018
-
[21]
[Khanet al., 2010 ] Maryam Mahsal Khan, Gul Muhammad Khan, and Julian F. Miller. Evolution of neural net- works using cartesian genetic programming. In17th IEEE Congress on Evolutionary Computation, pages 1–8. IEEE,
2010
-
[22]
Evolving neural networks for strategic decision-making problems.Neural Networks, 22(3):326– 337,
[Kohl and Miikkulainen, 2009] Nate Kohl and Risto Mi- ikkulainen. Evolving neural networks for strategic decision-making problems.Neural Networks, 22(3):326– 337,
2009
-
[23]
Biological underpinnings for lifelong learning machines.Nature Machine Intelligence, 4(3):196–210,
[Kudithipudiet al., 2022 ] Dhireesha Kudithipudi, Mario Aguilar-Simon, et al. Biological underpinnings for lifelong learning machines.Nature Machine Intelligence, 4(3):196–210,
2022
-
[24]
Runtime analysis of population-based evo- lutionary neural architecture search for a binary classifica- tion problem
[Lvet al., 2024 ] Zeqiong Lv, Chao Bian, Chao Qian, and Yanan Sun. Runtime analysis of population-based evo- lutionary neural architecture search for a binary classifica- tion problem. InGECCO, GECCO ’24, pages 358–366, New York, NY , USA,
2024
-
[25]
[Lvet al., 2025 ] Zeqiong Lv, Chao Qian, Yun Liu, Jiahao Fan, and Yanan Sun
Association for Computing Machinery. [Lvet al., 2025 ] Zeqiong Lv, Chao Qian, Yun Liu, Jiahao Fan, and Yanan Sun. Runtime analysis of evolution- ary NAS for multiclass classification. InICML, volume 267 ofProceedings of Machine Learning Research, pages 41648–41666. PMLR, 13–19 Jul
2025
-
[26]
Martin, Paul D
[Martinet al., 2000 ] Stephen J. Martin, Paul D. Grimwood, and Richard G. M. Morris. Synaptic plasticity and mem- ory: an evaluation of the hypothesis.Annual Review of Neuroscience, 23(1):649–711,
2000
-
[27]
Stanley, and Jeff Clune
[Miconiet al., 2018 ] Thomas Miconi, Kenneth O. Stanley, and Jeff Clune. Differentiable plasticity: training plastic neural networks with backpropagation. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th Interna- tional Conference on Machine Learning, volume 80, pages 3559–3568. PMLR,
2018
-
[28]
Evolving deep neural networks
[Miikkulainenet al., 2024 ] Risto Miikkulainen, Jason Liang, et al. Evolving deep neural networks. InArtificial Intelligence in the Age of Neural Networks and Brain Computing, pages 269–287. Elsevier,
2024
-
[29]
Neuroevolution insights into biological neural computation.Science, 387(6735):eadp7478,
[Miikkulainen, 2025] Risto Miikkulainen. Neuroevolution insights into biological neural computation.Science, 387(6735):eadp7478,
2025
-
[30]
Meta-learning through hebbian plasticity in random net- works
[Najarro and Risi, 2020] Elias Najarro and Sebastian Risi. Meta-learning through hebbian plasticity in random net- works. InNeurIPS,
2020
-
[31]
A simplified neuron model as a prin- cipal component analyzer.Journal of Mathematical Biol- ogy, 15(3):267–273,
[Oja, 1982] Erkki Oja. A simplified neuron model as a prin- cipal component analyzer.Journal of Mathematical Biol- ogy, 15(3):267–273,
1982
-
[32]
Online Learning: A Modern Introduction Using Convex Optimization
[Orabona, 2019] Francesco Orabona. A modern introduc- tion to online learning.arXiv preprint arXiv:1912.13213,
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[33]
Neat for large-scale reinforcement learning through evolutionary feature learning and policy gradient search
[Penget al., 2018 ] Yiming Peng, Gang Chen, Harith Singh, and Mengjie Zhang. Neat for large-scale reinforcement learning through evolutionary feature learning and policy gradient search. InGECCO, pages 490–497, New York, NY , USA,
2018
-
[34]
[Schmidhuber, 1987] J¨urgen Schmidhuber
ACM. [Schmidhuber, 1987] J¨urgen Schmidhuber. Evolutionary principles in self-referential learning: on learning how to learn. Diploma thesis, Technische Universit ¨at M ¨unchen, Institut f¨ur Informatik, Munich, Germany,
1987
-
[35]
Proximal policy optimization algorithms.arXiv preprint,
[Schulmanet al., 2017 ] John Schulman, Filip Wolski, Pra- fulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint,
2017
-
[36]
Online learn- ing and online convex optimization.Foundations and Trends in Machine Learning, 4(2):107–194,
[Shalev-Shwartz, 2011] Shai Shalev-Shwartz. Online learn- ing and online convex optimization.Foundations and Trends in Machine Learning, 4(2):107–194,
2011
-
[37]
Stan- ley, and Risto Miikkulainen
[Soltoggioet al., 2008 ] Andrea Soltoggio, Kenneth O. Stan- ley, and Risto Miikkulainen. Evolutionary advantages of neuromodulated plasticity in dynamic, reward-based sce- narios. InALIFE,
2008
-
[38]
Stan- ley, and Sebastian Risi
[Soltoggioet al., 2018 ] Andrea Soltoggio, Kenneth O. Stan- ley, and Sebastian Risi. Born to learn: the inspiration, progress, and future of evolved plastic artificial neural net- works.Neural Networks, 108:48–67,
2018
-
[39]
Stanley, Bobby D
[Stanleyet al., 2003 ] Kenneth O. Stanley, Bobby D. Bryant, and Risto Miikkulainen. Evolving adaptive neural net- works with and without adaptive synapses. InCEC,
2003
-
[40]
Stanley, David B
[Stanleyet al., 2009 ] Kenneth O. Stanley, David B. D’Ambrosio, and Jason Gauci. A hypercube-based encoding for evolving large-scale neural networks. Artificial Life, 15(2):185–212,
2009
-
[41]
Stanley, Jeff Clune, Joel Lehman, and Risto Miikkulainen
[Stanleyet al., 2019 ] Kenneth O. Stanley, Jeff Clune, Joel Lehman, and Risto Miikkulainen. Designing neural net- works through neuroevolution.Nature Machine Intelli- gence, 1(1):24–35,
2019
-
[42]
Sutton and Andrew G
[Sutton and Barto, 1998] Richard S. Sutton and Andrew G. Barto.Reinforcement learning: an introduction. MIT Press, Cambridge, MA,
1998
-
[43]
Duszkiewicz, and Richard G
[Takeuchiet al., 2014 ] Tatsuya Takeuchi, Adrian J. Duszkiewicz, and Richard G. M. Morris. The synaptic plasticity and memory hypothesis: encoding, storage and persistence.Philosophical Transactions of the Royal Society B: Biological Sciences, 369(1633):20130288,
2014
-
[44]
Stanley, Risto Miikkulainen, and Nate Kohl
[Whitesonet al., 2005 ] Shimon Whiteson, Peter Stone, Ken- neth O. Stanley, Risto Miikkulainen, and Nate Kohl. Au- tomatic feature selection in neuroevolution. InGECCO, pages 1225–1232,
2005
-
[45]
Sample-efficient quality- diversity by cooperative coevolution
[Xueet al., 2024 ] Ke Xue, Ren-Jian Wang, Pengyi Li, Dong Li, Jianye Hao, and Chao Qian. Sample-efficient quality- diversity by cooperative coevolution. InICLR,
2024
-
[46]
Evolving artificial neural networks
[Yao, 1999] Xin Yao. Evolving artificial neural networks. Proceedings of the IEEE, 87(9):1423–1447,
1999
-
[47]
Discovering effective policies for land-use planning with neuroevolution.Environmental Data Science, 4:e30,
[Younget al., 2025 ] Daniel Young, Olivier Francon, et al. Discovering effective policies for land-use planning with neuroevolution.Environmental Data Science, 4:e30,
2025
-
[48]
Zarantonello
[Zarantonello, 1971] Eduardo H. Zarantonello. Projections on convex sets in hilbert space and spectral theory: Part i. projections on convex sets: Part ii. spectral theory. In Eduardo H. Zarantonello, editor,Contributions to Nonlin- ear Functional Analysis, pages 237–424. Academic Press,
1971
-
[49]
Online convex pro- gramming and generalized infinitesimal gradient ascent
[Zinkevich, 2003] Martin Zinkevich. Online convex pro- gramming and generalized infinitesimal gradient ascent. In ICML,
2003
-
[50]
ii 2 Preliminaries and Notation ii 3 NeuroEvolutionary Online Learning ii 3.1 Decoupling Updates for Weight and Topology
7 Appendix Contents 1 Introduction i 1.1 Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ii 2 Preliminaries and Notation ii 3 NeuroEvolutionary Online Learning ii 3.1 Decoupling Updates for Weight and Topology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ii 3.2...
1963
-
[51]
Choosingη=D/(U √ T)yields TX t=1 L(h) t w(h) t −min w∈Wh TX t=1 L(h) t (w)≤DU √ T
Moreover, if∥u (h) t ∥2 ≤Ufor allt(implied by A2–4), then TX t=1 L(h) t w(h) t −min w∈Wh TX t=1 L(h) t (w)≤ D2 2η + ηU 2T 2 . Choosingη=D/(U √ T)yields TX t=1 L(h) t w(h) t −min w∈Wh TX t=1 L(h) t (w)≤DU √ T . Our proof follows a standard regret bound for projected (sub)gradient methods in online convex optimisation [Zinkevich, 2003], but instead, we cons...
2003
-
[52]
Choosingη=D/(U √ T)yields D2 2η + ηU 2T 2 = D2 2 · U √ T D + 1 2 · D U √ T ·U 2T=DU √ T
If additionally∥u t∥2 ≤Ufor allt(Assumptions 2-4 imply the local plasticity update is bounded by some constantUw.r.t T), thenPT t=1 ∥ut∥2 2 ≤U 2T, giving TX t=1 L(h) t w(h) t −min w∈Wh TX t=1 L(h) t (w)≤ D2 2η + ηU 2T 2 . Choosingη=D/(U √ T)yields D2 2η + ηU 2T 2 = D2 2 · U √ T D + 1 2 · D U √ T ·U 2T=DU √ T . This completes the proof. Lemma 2.Let{F t}t≥1...
1997
-
[53]
(1)CartPole-v1within Gymnasium [Brockmanet al., 2016 ]
C.3 Four control tasks from OpenAI gym benchmark suite We evaluate on four standard environments from the OpenAI gym benchmark suite [Brockmanet al., 2016 ], spanning diverse reward structures and action spaces. (1)CartPole-v1within Gymnasium [Brockmanet al., 2016 ]. Here, the statesis a 4-dimensional vector s= [x,˙x, θ, ˙θ], wherexand˙xare respectively t...
2016
-
[54]
fracture
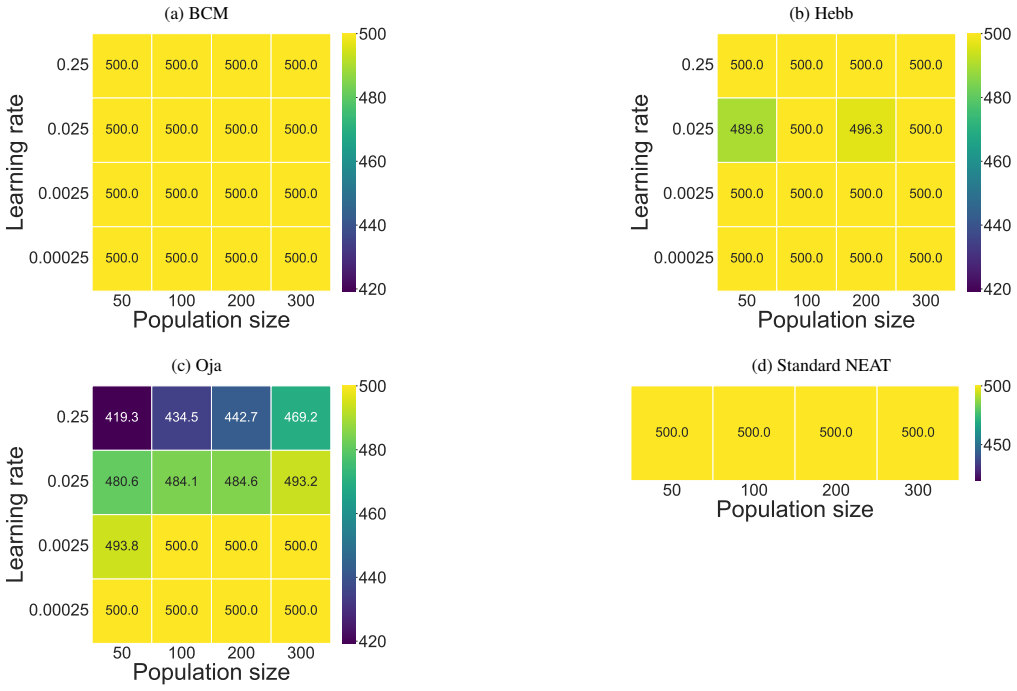
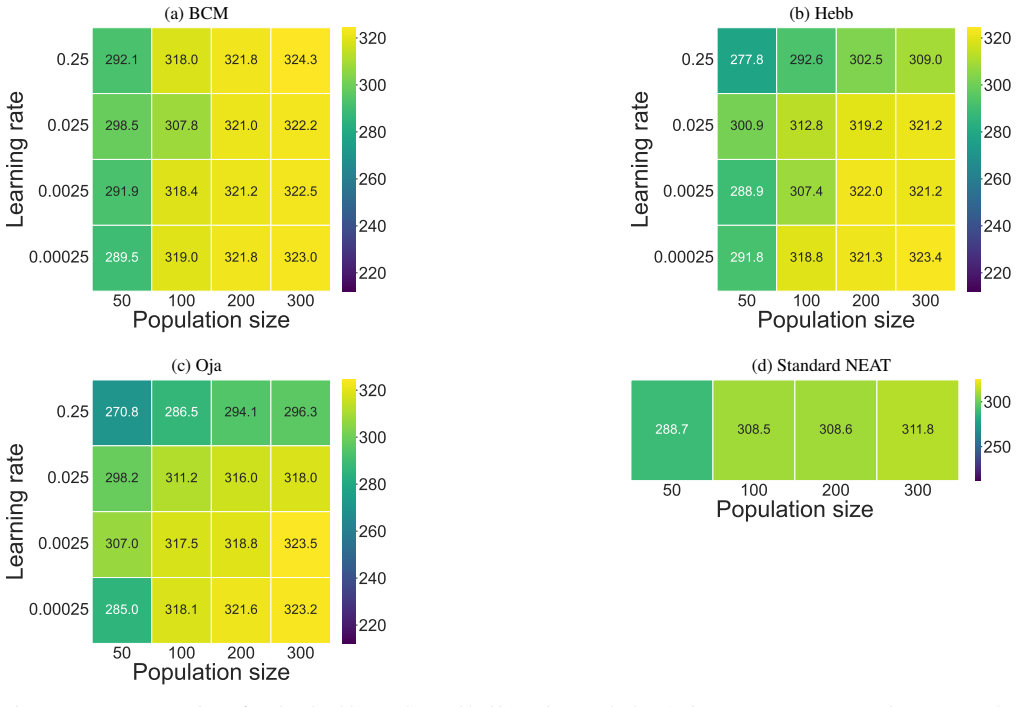
Very small learning rates underfit and very large rates overfit or destabilise, producing a characteristic ridge across the middle rows. Hebb benefits from the same scaling trends but remains below BCM and Oja over most of the grid, particularly at small populations or extreme rates. Standard NEAT also scales with population but plateaus several hundred p...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.