A scalar per patch from pre-trained ViTs enables fast moving navigation in the real world
Pith reviewed 2026-06-26 14:17 UTC · model grok-4.3
The pith
Bottlenecking pre-trained ViTs to one scalar per patch yields features for real-world robot navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reducing pre-trained ViT encoders to a single scalar per image patch through principled bottlenecking, after heterogeneous distillation, produces navigation policies that succeed on static point-goal tasks in a real building while generating features that can be interpreted as affordances.
What carries the argument
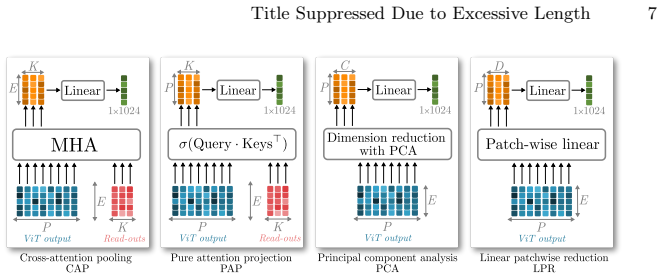
The scalar-per-patch bottleneck applied to pre-trained ViT encoders after multi-teacher distillation.
If this is right
- Policies trained on the reduced scalar features complete long-distance navigation episodes in real buildings.
- Distillation from multiple heterogeneous teachers equips encoders with complementary visual skills.
- Finetuning shows that policies pre-trained on privileged information outperform those trained on RGB alone.
- The bottleneck step causes features linked to affordances to appear without explicit supervision.
Where Pith is reading between the lines
- The same per-patch scalar reduction could be tested on other robotics tasks that rely on pre-trained vision backbones.
- Measuring how the scalar features correlate with specific actions across varied buildings would test the affordance interpretation.
- The approach suggests that explicit spatial structure in the bottleneck matters more than raw feature dimensionality for policy learning.
Load-bearing premise
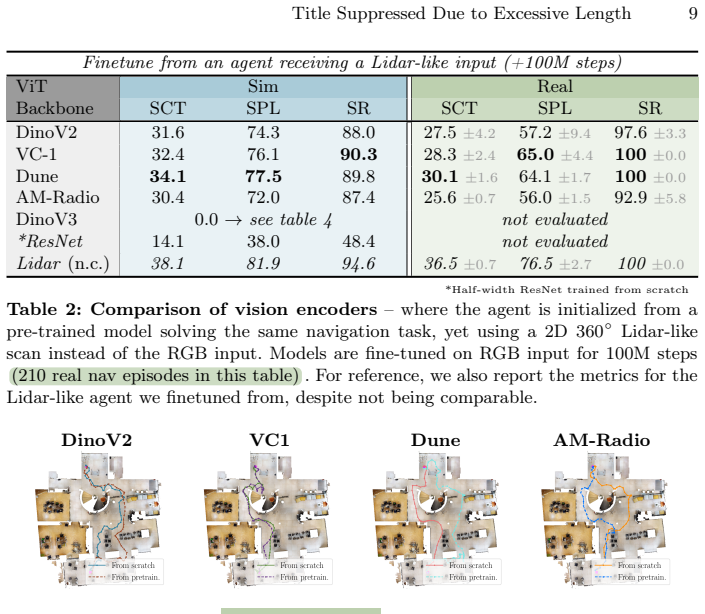
Results from 966 episodes inside one building will generalize to broader real-world navigation conditions.
What would settle it
Navigation success rate drops sharply when the same scalar-per-patch policies are deployed in a second building with different layout or lighting while full-resolution encoders maintain performance.
Figures










read the original abstract
Trained policies for real-world robotics rely on computer vision components, typically in the form of pre-trained visual encoders. These encoders are an essential component and it has been shown that their power does not emerge from training on robotics downstream losses alone. Pre-training with auxiliary losses in the form of computer-vision pre-text tasks is a defining factor and heavily conditions agent performance in robotics tasks. In this unprecedented large-scale study, we ran 966 navigation episodes of static point goal navigation in a real-world building for 24km and asked which components really matter for the computer vision aspects of robotics: we evaluate state-of-the art visual encoders in realistic conditions. We explore the usefulness of heterogeneous multi-teacher distillation leading to encoders with multiple different and complementary skills. We investigate how much information from these encoders is necessary for robotics by bottlenecking them in a principled and spatially useful way and we show that this leads to the emergence of interpretable features linked to affordances. We also argue that training policies on RGB data alone does not lead to an optimal usage of visual features and show this by finetuning policies pre-trained on privileged information. All in all, we paint a more complete picture of what aspects of computer vision are relevant for real-world navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a large-scale real-world evaluation of 966 static point-goal navigation episodes (24 km total) inside a single building. It compares state-of-the-art pre-trained visual encoders, heterogeneous multi-teacher distillation, and a principled spatial bottlenecking procedure; the central claim is that the bottlenecking step produces interpretable features linked to affordances. Additional claims are that RGB-only policy training is suboptimal (demonstrated via privileged-information fine-tuning) and that the study clarifies which computer-vision components matter for real-world navigation.
Significance. If the emergence of affordance-linked features from spatial bottlenecking generalizes, the result would supply concrete guidance for encoder design in robotics. The scale of the real-world data collection is a clear strength; the work also supplies an empirical comparison of distillation strategies that is rarely performed at this volume outside simulation.
major comments (2)
- [Abstract and experimental evaluation] Abstract and § on experimental results: the central claim that bottlenecking yields 'interpretable features linked to affordances' is supported only by experiments inside one building; no cross-building or cross-environment transfer results are reported for either feature interpretability or navigation performance, which is load-bearing for the generalization implied by the title and abstract.
- [Abstract] Abstract: quantitative support for all reported outcomes (success rates, ablation deltas, feature-interpretability metrics) is absent; the manuscript therefore provides no error bars, confidence intervals, or statistical tests that would allow a reader to assess whether the observed effects exceed environment-specific noise.
minor comments (2)
- The description of the spatial bottlenecking procedure would benefit from an explicit equation or diagram showing how the per-patch scalar is computed and how it is inserted into the ViT forward pass.
- The manuscript should clarify the precise definition of 'heterogeneous multi-teacher distillation' (number of teachers, loss weighting, and which layers are distilled) so that the ablation can be reproduced.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the scale of the real-world evaluation. We address each major comment below, clarifying the scope of our claims and committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] Abstract and § on experimental results: the central claim that bottlenecking yields 'interpretable features linked to affordances' is supported only by experiments inside one building; no cross-building or cross-environment transfer results are reported for either feature interpretability or navigation performance, which is load-bearing for the generalization implied by the title and abstract.
Authors: The study is explicitly conducted within a single building, as stated in the abstract and experimental section. The title's reference to 'the real world' contrasts with simulation rather than claiming multi-environment generalization. Feature interpretability is evidenced through visualizations and affordance correlations observed in this environment. We will revise the abstract and discussion sections to explicitly delimit the single-building scope and remove any phrasing that could imply broader transfer. revision: partial
-
Referee: [Abstract] Abstract: quantitative support for all reported outcomes (success rates, ablation deltas, feature-interpretability metrics) is absent; the manuscript therefore provides no error bars, confidence intervals, or statistical tests that would allow a reader to assess whether the observed effects exceed environment-specific noise.
Authors: The current manuscript reports aggregate outcomes from 966 episodes but omits error bars and statistical tests. We will add these elements, including confidence intervals and significance tests for success rates and ablation deltas, in the revised version to quantify variability. revision: yes
Circularity Check
No circularity; empirical results from real-world episodes stand independently.
full rationale
The paper reports outcomes from 966 navigation episodes across 24km in one building, evaluating pre-trained ViT encoders, multi-teacher distillation, spatial bottlenecking for affordance-linked features, and policy finetuning. No equations, derivations, or self-referential definitions appear; claims rest on experimental measurements rather than any reduction of outputs to fitted inputs or self-citations by construction. The single-building scope raises generalization questions but does not create circularity in the reported chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: International Symposium on Experimental Robotics (2023)
Ai, B., Wu, Z., Hsu, D.: Invariance is key to generalization: Examining the role of representation in sim-to-real transfer for visual navigation. In: International Symposium on Experimental Robotics (2023)
2023
-
[2]
In: Neural Information Processing Systems (2022)
Alayrac,J.B.,Donahue,J.,Luc,P.,Miech,A.,Barr,I.,Hasson,Y.,Lenc,K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. In: Neural Information Processing Systems (2022)
2022
-
[3]
arXiv preprint (2018)
Anderson, P., Chang, A.X., Chaplot, D.S., Dosovitskiy, A., Gupta, S., Koltun, V., Kosecka, J., Malik, J., Mottaghi, R., Savva, M., Zamir, A.R.: On evaluation of embodied navigation agents. arXiv preprint (2018)
2018
-
[4]
In: Conference on Computer Vision and Pattern Recognition (2016)
Arandjelović, R., Gronat, P., Torii, A., Pajdla, T., Sivic, J.: NetVLAD: CNN architecture for weakly supervised place recognition. In: Conference on Computer Vision and Pattern Recognition (2016)
2016
-
[5]
In: European Conference on Computer Vision (2024)
Baradel, F., Armando, M., Galaaoui, S., Brégier, R., Weinzaepfel, P., Rogez, G., Lucas, T.: Multi-hmr: Multi-person whole-body human mesh recovery in a single shot. In: European Conference on Computer Vision (2024)
2024
-
[6]
In: European Conference on Computer Vision (2020)
Beeching, E., Dibangoye, J., Simonin, O., Wolf, C.: Learning to reason on uncertain topological maps. In: European Conference on Computer Vision (2020)
2020
-
[7]
In: European Con- ference on Machine Learning (2020)
Beeching, E., Dibangoye, J., Simonin, O., Wolf, C.: Egomap: Projective mapping and structured egocentric memory for deep RL. In: European Con- ference on Machine Learning (2020)
2020
-
[8]
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Shi, L.X., Tanner, J., Vuong, Q., Walling, A., Wang, H., Zhilinsky, U.:π0: A vision- language-action flow model for general robot control. In: arxi...
Pith/arXiv arXiv 2024
-
[9]
In: International Conference on Learning Repre- sentation (2024)
Bono, G., Antsfeld, L., Chidlovskii, B., Weinzaepfel, P., Wolf, C.: End- to-End (Instance)-Image Goal Navigation through Correspondence as an Emergent Phenomenon,. In: International Conference on Learning Repre- sentation (2024)
2024
-
[10]
In: International Conference on Learning Representation (2024)
Bono, G., Antsfeld, L., Sadek, A., Monaci, G., Wolf, C.: Learning with a Mole: Transferable latent spatial representations for navigation without reconstruction. In: International Conference on Learning Representation (2024)
2024
-
[11]
In: Con- ference on Computer Vision and Pattern Recognition (2024)
Bono, G., Poirier, H., Antsfeld, L., Monaci, G., Chidlovskii, B., Wolf, C.: Learning to navigate efficiently and precisely in real environments. In: Con- ference on Computer Vision and Pattern Recognition (2024)
2024
-
[12]
IEEE Trans- actions on Intelligent Vehicles (2017) 16 Janny et al
Bresson, G., Alsayed, Z., Yu, L., Glaser, S.: Simultaneous localization and mapping: A survey of current trends in autonomous driving. IEEE Trans- actions on Intelligent Vehicles (2017) 16 Janny et al
2017
-
[13]
In: Association for the Advancement of Artificial Intelligence (1998)
Burgard, W., Cremers, A.B., Fox, D., Hähnel, D., Lakemeyer, G., Schulz, D., Steiner, W., Thrun, S.: The interactive museum tour-guide robot. In: Association for the Advancement of Artificial Intelligence (1998)
1998
-
[14]
In: European Conference on Computer Vision (2020)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: European Conference on Computer Vision (2020)
2020
-
[15]
In: International Conference on Computer Vision (2021)
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: International Conference on Computer Vision (2021)
2021
-
[16]
In: Neural Information Processing Systems (2020)
Chaplot, D.S., Gandhi, D., Gupta, A., Salakhutdinov, R.: Object goal nav- igation using goal-oriented semantic exploration. In: Neural Information Processing Systems (2020)
2020
-
[17]
In: International Conference on Learning Representation (2020)
Chaplot, D.S., Gandhi, D., Gupta, S., Gupta, A., Salakhutdinov, R.: Learn- ing to explore using active neural slam. In: International Conference on Learning Representation (2020)
2020
-
[18]
In: Conference on Computer Vision and Pattern Recognition (2020)
Chaplot, D.S., Salakhutdinov, R., Gupta, A., Gupta, S.: Neural topological slam for visual navigation. In: Conference on Computer Vision and Pattern Recognition (2020)
2020
-
[19]
CoRR (2021)
Chattopadhyay, P., Hoffman, J., Mottaghi, R., Kembhavi, A.: Robustnav: Towards benchmarking robustness in embodied navigation. CoRR (2021)
2021
-
[20]
In: Conference on Computer Vision and Pattern Recognition (2022)
Chen, S., Guhur, P.L., Tapaswi, M., Schmid, C., Laptev, I.: Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Naviga- tion. In: Conference on Computer Vision and Pattern Recognition (2022)
2022
-
[21]
In: Conference on Em- pirical Methods in Natural Language Processing (2014)
Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using RNN encoder–decoder for statistical machine translation. In: Conference on Em- pirical Methods in Natural Language Processing (2014)
2014
-
[22]
In: Neural Information Processing Systems (2023)
Dai, W., Li, J., Li, D., Tiong, A.M.H., Zhao, J., Wang, W., Li, B., Fung, P., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. In: Neural Information Processing Systems (2023)
2023
-
[23]
In: Neural Information Processing Systems (2019)
Ding, Y., Florensa, C., Abbeel, P., Phielipp, M.: Goal-conditioned imitation learning. In: Neural Information Processing Systems (2019)
2019
-
[24]
In: International Conference on Learning Representation (2021)
Du, H., Yu, X., Zheng, L.: Vtnet: Visual transformer network for object goal navigation. In: International Conference on Learning Representation (2021)
2021
-
[25]
In: International Conference on Learning Representation (2024)
Fang, A., Jose, A.M., Jain, A., Schmidt, L., Toshev, A.T., Shankar, V.: Data filtering networks. In: International Conference on Learning Representation (2024)
2024
-
[26]
In: Conference on Computer Vision and Pattern Recognition (2019)
Fang,K.,Toshev,A.,Fei-Fei,L.,Savarese,S.:Scenememorytransformerfor embodied agents in long-horizon tasks. In: Conference on Computer Vision and Pattern Recognition (2019)
2019
-
[27]
IEEE Robotics & Automation Magazine (1997)
Fox, D., Burgard, W., Thrun, S.: The dynamic window approach to collision avoidance. IEEE Robotics & Automation Magazine (1997)
1997
-
[28]
In: International Conference on Robotics and Automation (2024) Title Suppressed Due to Excessive Length 17
Garg, S., Rana, K., Hosseinzadeh, M., Mares, L., Sünderhauf, N., Dayoub, F., Reid, I.: Robohop: Segment-based topological map representation for open-world visual navigation. In: International Conference on Robotics and Automation (2024) Title Suppressed Due to Excessive Length 17
2024
-
[29]
Hariharan,B.,Arbeláez,P.,Girshick,R.,Malik,J.:Hypercolumnsforobject segmentation and fine-grained localization (2015)
2015
-
[30]
In: Conference on Computer Vision and Pattern Recognition (2022)
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoen- coders are scalable vision learners. In: Conference on Computer Vision and Pattern Recognition (2022)
2022
-
[31]
In: Conference on Computer Vision and Pattern Recognition (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recog- nition. In: Conference on Computer Vision and Pattern Recognition (2016)
2016
-
[32]
In: Conference on Computer Vision and Pattern Recognition (2025)
Heinrich,G.,Ranzinger,M.,Hongxu,Yin,Lu,Y.,Kautz,J.,Tao,A.,Catan- zaro, B., Molchanov, P.: Radiov2.5: Improved baselines for agglomerative vision foundation models. In: Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[33]
In: Conference on Computer Vision and Pattern Recognition (2018)
Henriques, J.F., Vedaldi, A.: Mapnet: An allocentric spatial memory for mapping environments. In: Conference on Computer Vision and Pattern Recognition (2018)
2018
-
[34]
Huang, Z., Li, J., Wen, H., Li, T., Yang, X., Qi, L., Peng, B., Huang, X., Yang, M.H., Cheng, G.: Rethinking cross-generator image forgery detection through dinov3. In: arxiv:2511.22471 (2025)
arXiv 2025
-
[35]
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M.Y., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A.Z., Shi, L.X., Smith, L., Springenberg, J.T., Stachow...
Pith/arXiv arXiv 2025
-
[36]
In: International Conference on Learning Representation (2017)
Jaderberg, M., Mnih, V., Czarnecki, W.M., Schaul, T., Leibo, J.Z., Silver, D., Kavukcuoglu, K.: Reinforcement learning with unsupervised auxiliary tasks. In: International Conference on Learning Representation (2017)
2017
-
[37]
In: International Conference on Machine Learning (2021)
Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., Carreira, J.: Perceiver: General perception with iterative attention. In: International Conference on Machine Learning (2021)
2021
-
[39]
In: Conference on Computer Vision and Pattern Recognition (2025)
Janny, S., Poirier, H., Antsfeld, L., Bono, G., Monaci, G., Chidlovskii, B., Giuliari, F., Bue, A.D., Wolf, C.: Reasoning in visual navigation of end- to-end trained agents: a dynamical systems approach. In: Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[40]
In: Neural Information Processing Sys- tems (2026)
Karypidis, E., Kakogeorgiou, I., Gidaris, S., Komodakis, N.: Dino-foresight: Looking into the future with dino. In: Neural Information Processing Sys- tems (2026)
2026
-
[41]
open-source vision-language-action model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., Vuong, Q., Kollar, T., Burch- fiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., Finn, C.: Openvla: An 18 Janny et al. open-source vision-language-action model. In: Conference on Robot Learn- ing (2024)
2024
-
[42]
In: International Conference on Computer Vision (2023)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollar, P., Girshick, R.: Segment anything. In: International Conference on Computer Vision (2023)
2023
-
[43]
In: International Conference on Computer Vision (2023)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything. In: International Conference on Computer Vision (2023)
2023
-
[44]
Konolige,K.:Agradientmethodforrealtimerobotcontrol.In:International Conference on Intelligent Robots and Systems (2000)
2000
-
[45]
Journal of Field Robotics (2019)
Labbé, M., Michaud, F.: RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. Journal of Field Robotics (2019)
2019
-
[46]
In: European Conference on Computer Vision (2024)
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3D with MASt3R. In: European Conference on Computer Vision (2024)
2024
-
[47]
In: Conference on Computer Vision and Pattern Recognition (2017)
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Conference on Computer Vision and Pattern Recognition (2017)
2017
-
[48]
Liu, C., Chen, Y., Shi, H., Lu, J., Jian, B., Pan, J., Cai, L., Wang, J., Yu, J., Gao, Z., Zhang, X., Bai, L., Zhang, Y., Li, J., Bercea, C.I., Ouyang, C., Chen, C., Xiong, Z., Wiestler, B., Wachinger, C., Duncan, J.S., Rueckert, D., Bai, W., Arcucci, R.: Does dinov3 set a new medical vision standard? benchmarking 2d and 3d classification, segmentation, a...
arXiv 2026
-
[49]
In: Conference on Computer Vision and Pattern Recognition (2025)
Liu, X., Li, J., Jiang, Y., Sujay, N., Yang, Z., Zhang, J., Abanes, J., Zhang, J., Feng, C.: Citywalker: Learning embodied urban navigation from web- scale videos. In: Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[50]
In: Neural Information Processing Systems (2020)
Locatello, F., Weissenborn, D., Unterthiner, T., Mahendran, A., Heigold, G., Uszkoreit, J., Dosovitskiy, A., Kipf, T.: Object-centric learning with slot attention. In: Neural Information Processing Systems (2020)
2020
-
[51]
In: International Conference on Intelligent Robots and Systems (2020)
Macenski, S., Martín, F., White, R., Clavero, J.G.: The marathon 2: A navigation system. In: International Conference on Intelligent Robots and Systems (2020)
2020
-
[52]
Majumdar, A., Yadav, K., Arnaud, S., Ma, Y.J., Chen, C., Silwal, S., Jain, A., Berges, V.P., Abbeel, P., Malik, J., Batra, D., Lin, Y., Maksymets, O., Rajeswaran, A., Meier, F.: Where are we in the search for an artificial visual cortex for embodied intelligence? In: Neural Information Processing Systems (2023)
2023
-
[53]
In: International Conference on Robotics and Automation (2010)
Marder-Eppstein, E., Berger, E., Foote, T., Gerkey, B., Konolige, K.: The office marathon: Robust navigation in an indoor office environment. In: International Conference on Robotics and Automation (2010)
2010
-
[54]
In: International Conference on Computer Vision (2023) Title Suppressed Due to Excessive Length 19
Marza, P., Matignon, L., Simonin, O., Wolf, C.: Multi-Object Navigation with dynamically learned neural implicit representations. In: International Conference on Computer Vision (2023) Title Suppressed Due to Excessive Length 19
2023
-
[55]
In: International Conference on Learning Representation (2017)
Mirowski, P., Pascanu, R., Viola, F., Soyer, H., Ballard, A., Banino, A., De- nil, M., Goroshin, R., Sifre, L., Kavukcuoglu, K., Kumaran, D., Hadsell, R.: Learning to navigate in complex environments. In: International Conference on Learning Representation (2017)
2017
-
[56]
In: International Confer- ence on 3D Vision (3DV) (2024)
Monaci, G., Antsfeld, L., Chidlovskii, B., Wolf, C.: Zero-bev: Zero-shot pro- jection of any first-person modality to bev maps. In: International Confer- ence on 3D Vision (3DV) (2024)
2024
-
[57]
Monaci, G., Weinzaepfel, P., Wolf, C.: What does really matter in image goal navigation? In: International Conference on 3D Vision (2026)
2026
-
[58]
Transaction on Machine Learning Research (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Bal- las, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[59]
In: International Conference on Learning Represen- tation (2018)
Parisotto, E., Salakhutdinov, R.: Neural map: Structured memory for deep reinforcement learning. In: International Conference on Learning Represen- tation (2018)
2018
-
[60]
In: Conference on Computer Vision and Pattern Recognition (2025)
Qian, S., Mo, K., Blukis, V., Fouhey, D.F., Fox, D., Goyal, A.: 3d-mvp: 3d multiview pretraining for manipulation. In: Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[62]
In: International Conference on Machine Learning (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (2021)
2021
-
[63]
In: Neural Information Processing Systems (2021)
Ramakrishnan, S.K., Gokaslan, A., Wijmans, E., Maksymets, O., Clegg, A., Turner, J.M., Undersander, E., Galuba, W., Westbury, A., Chang, A.X., Savva, M., Zhao, Y., Batra, D.: Habitat-matterport 3D dataset (HM3D): 1000 large-scale 3d environments for embodied AI. In: Neural Information Processing Systems (2021)
2021
-
[64]
Transaction on Machine Learning Research (2022)
Reed, S., Zolna, K., Parisotto, E., Colmenarejo, S.G., Novikov, A., Barth- Maron, G., Gimenez, M., Sulsky, Y., Kay, J., Springenberg, J.T., Eccles, T., Bruce, J., Razavi, A., Edwards, A., Heess, N., Chen, Y., Hadsell, R., Vinyals, O., Bordbar, M., de Freitas, N.: A Generalist Agent. Transaction on Machine Learning Research (2022)
2022
-
[65]
In: Neural Information Processing Systems (2016)
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: Neural Information Processing Systems (2016)
2016
-
[66]
In: European Control Conference (ECC) (2015) 20 Janny et al
Rösmann, C., Hoffmann, F., Bertram, T.: Timed-elastic-bands for time- optimal point-to-point nonlinear model predictive control. In: European Control Conference (ECC) (2015) 20 Janny et al
2015
-
[67]
In: Conference on Computer Vision and Pattern Recognition (2025)
Sariyildiz, M.B., Weinzaepfel, P., Lucas, T., de Jorge, P., Larlus, D., Kalan- tidis, Y.: Dune: Distilling a universal encoder from heterogeneous 2d and 3d teachers. In: Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[68]
In: International Conference on Com- puter Vision (2019)
Savva, M., Kadian, A., Maksymets, O., Zhao, Y., Wijmans, E., Jain, B., Straub, J., Liu, J., Koltun, V., Malik, J., Parikh, D., Batra, D.: Habitat: A platform for embodied ai research. In: International Conference on Com- puter Vision (2019)
2019
-
[69]
In: Conference on Robot Learning
Sax, A., Zhang, J.O., Emi, B., Zamir, A., Savarese, S., Guibas, L., Malik, J.: Learning to navigate using mid-level visual priors. In: Conference on Robot Learning. PMLR (2020)
2020
-
[70]
arXiv preprint (2017)
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint (2017)
2017
-
[71]
Proceedings of the National Academy of Sciences (1996)
Sethian, J.A.: A fast marching level set method for monotonically advancing fronts. Proceedings of the National Academy of Sciences (1996)
1996
-
[72]
In: Robotics, Science and System (2022)
Shah, D., Levine, S.: ViKiNG: Vision-based kilometer-scale navigation with geographic hints. In: Robotics, Science and System (2022)
2022
-
[73]
In: Conference on Robot Learning (2023)
Shah, D., Sridhar, A., Dashora, N., Stachowicz, K., Black, K., Hirose, N., Levine, S.: ViNT: A foundation model for visual navigation. In: Conference on Robot Learning (2023)
2023
-
[74]
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zoui- tine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., Alibert, S., Cord, M., Wolf, T., Cadene, R.: Smolvla: A vision-language-action model for affordable and efficient robotics. In: arxiv:2506.01844 (2025)
Pith/arXiv arXiv 2025
-
[75]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haz- iza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: Dinov3. In: arxiv:2508...
Pith/arXiv arXiv 2025
-
[76]
In: Neural Information Process- ing Systems (2024)
Sun, X., Chen, P., Fan, J., Chen, J., Li, T., Tan, M.: Fgprompt: fine-grained goal prompting for image-goal navigation. In: Neural Information Process- ing Systems (2024)
2024
-
[77]
In: Robotics, Science and System (2024)
Team, O.M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., Luo, J., Tan, Y.L., Chen, L.Y., Sanketi, P., Vuong, Q., Xiao, T., Sadigh, D., Finn, C., Levine, S.: Octo: An open- source generalist robot policy. In: Robotics, Science and System (2024)
2024
-
[78]
Thrun, S., Burgard, W., Fox, D.: Probabilistic robotics (2005)
2005
-
[79]
In: Conference on Computer Vision and Pattern Recognition (2024)
Uppal,S.,Agarwal,A.,Xiong,H.,Shaw,K.,Pathak,D.:Spin:Simultaneous perception interaction and navigation. In: Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[80]
In: Conference on Computer Vision and Pattern Recognition (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[81]
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: DUSt3R: Geo- metric3Dvisionmadeeasy.In:ConferenceonComputerVisionandPattern Recognition (2024) Title Suppressed Due to Excessive Length 21
2024
-
[82]
In: International Conference on Robotics and Automation (2024)
Wang, Y., Zhang, M., Li, Z., Driggs-Campbell, K.R., Wu, J., Fei-Fei, L., Li, Y.: D$^3$fields: Dynamic 3d descriptor fields for zero-shot generaliz- able robotic manipulation. In: International Conference on Robotics and Automation (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.