Factual Retrieval in LLMs Is a Redundant, Distributed and Non-Contiguous Process
Pith reviewed 2026-06-26 14:30 UTC · model grok-4.3
The pith
Large language models retrieve facts via multiple redundant non-contiguous layer paths rather than localized steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
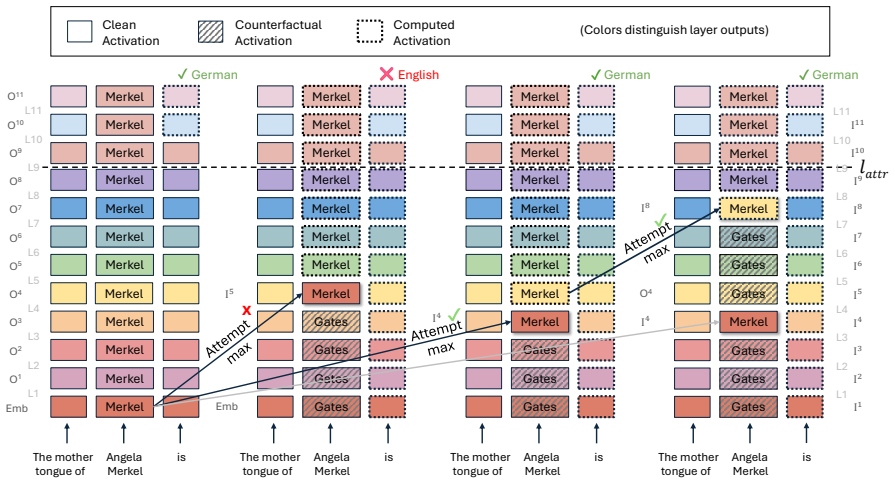
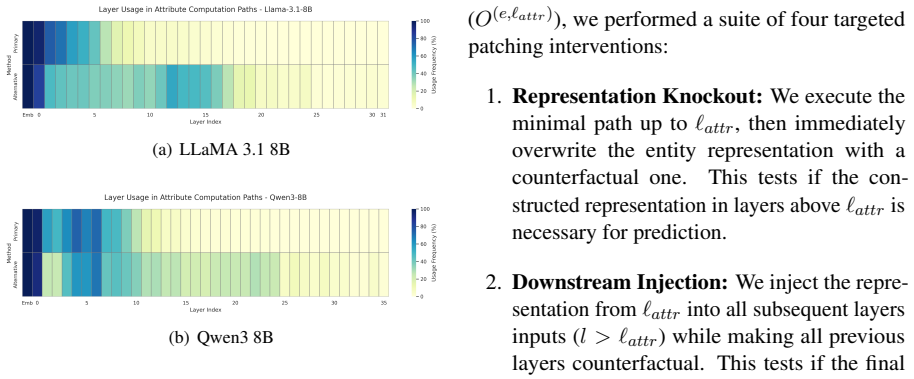
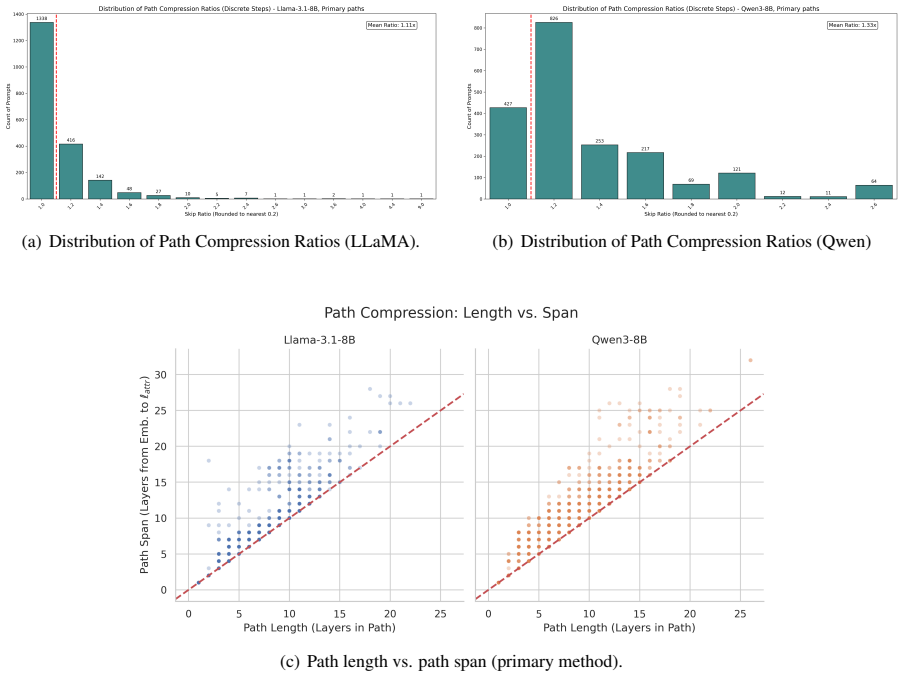
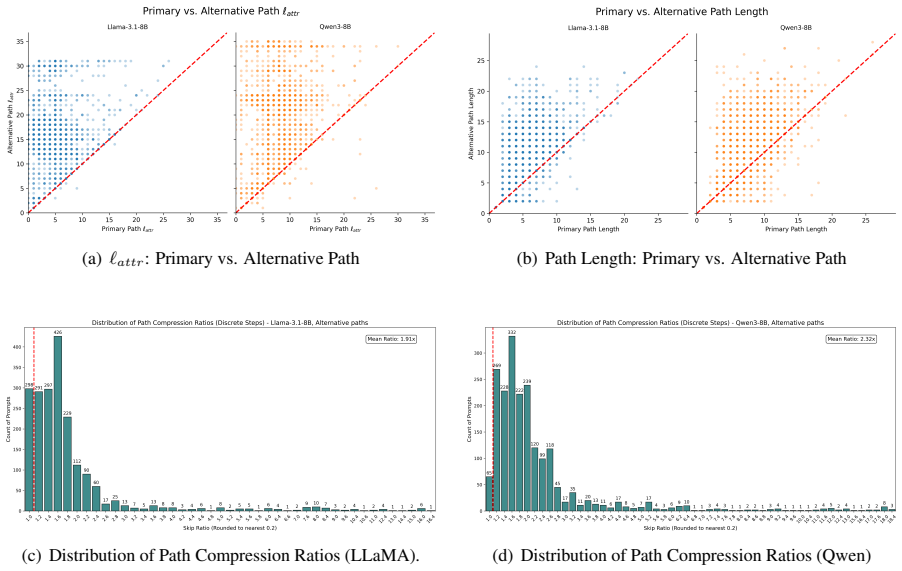
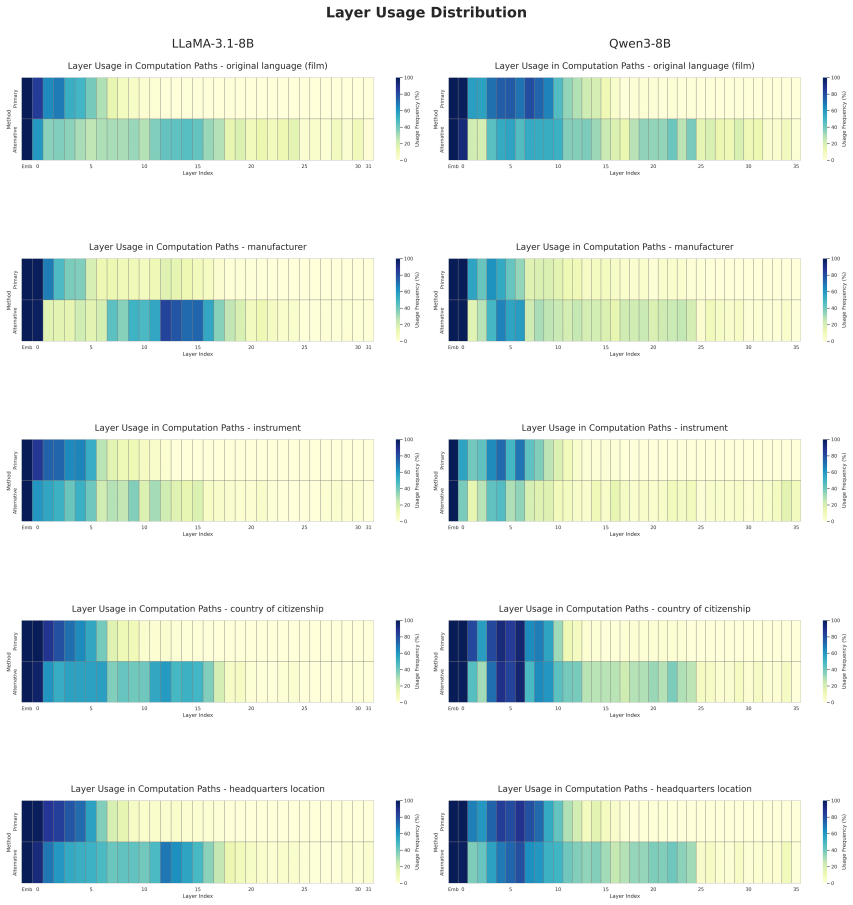
The central claim is that attribute-computation paths are non-contiguous, frequently skipping layers, and that models maintain multiple functionally-equivalent paths for the same entity and fact, which demonstrates a high degree of redundancy in how attributes are computed from entity representations.
What carries the argument
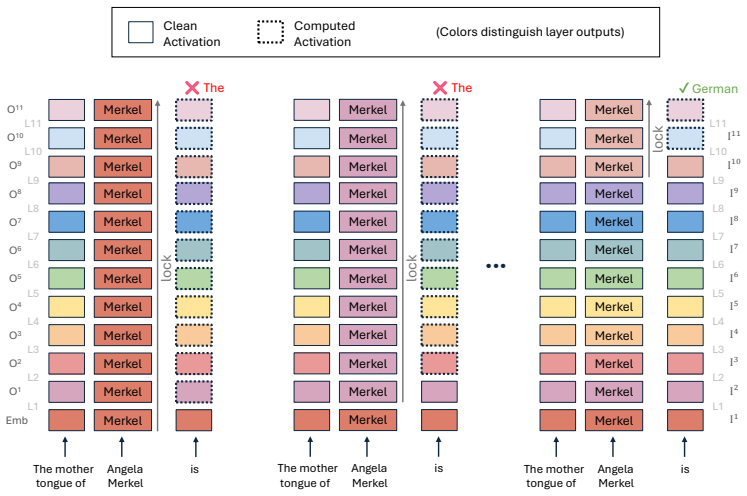
The attribute-computation path, a sequence of computational steps over the entity representation required to elicit a target attribute, located by an iterative patching protocol that finds minimal causally relevant layer subsets.
If this is right
- Knowledge computation occurs in a highly distributed manner across many layers.
- The existence of multiple paths can account for the observed mismatch between localization studies and editing results.
- Knowledge storage and retrieval mechanisms in current LLMs remain incompletely characterized.
- Redundancy may confer robustness to the model but complicates efforts to isolate or modify specific facts.
Where Pith is reading between the lines
- Targeted editing techniques may need to address several alternative paths simultaneously to achieve reliable changes.
- The same redundancy pattern could be tested in models of different sizes or training regimes to check generality.
- Factual recall may function more like an ensemble computation than a single dedicated route.
- Similar distributed mechanisms might appear in other transformer-based tasks beyond fact retrieval.
Load-bearing premise
The iterative patching protocol isolates the true minimal and causally relevant layers without creating artifacts or overlooking interactions between layers.
What would settle it
A demonstration that a single contiguous block of layers suffices to restore correct attribute retrieval for many facts while non-contiguous or alternative patches do not, or that each fact possesses only one unique computation path.
Figures










read the original abstract
Large language models (LLMs) store and recall factual knowledge, yet the precise mechanism of how entity representations are transformed to enable specific attribute retrieval remains underexplored. In this work, we investigate this mechanism through the lens of an "attribute-computation path"-a sequence of computational steps over the entity representation required to elicit a target attribute. We then propose an iterative patching protocol to identify a minimal subset of layers necessary for this computation. Applying our method to LLaMA 3.1 8B and Qwen3 8B, we find that these paths are non-contiguous, often skipping layers, and that models possess multiple, functionally-equivalent paths for the same entity and fact, highlighting a high degree of redundancy in attribute computation. This implies that knowledge computation is highly distributed, potentially explaining the localization-editing mismatch and suggesting that knowledge storage and retrieval in LLMs is far from being well understood.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines attribute-computation paths as sequences of layers transforming entity representations to retrieve target attributes. It introduces an iterative patching protocol to find minimal layer subsets and applies it to LLaMA 3.1 8B and Qwen3 8B, reporting that the paths are non-contiguous (often skipping layers), that multiple functionally equivalent paths exist for the same fact, and that this redundancy implies highly distributed knowledge computation, potentially explaining the localization-editing mismatch.
Significance. If the patching protocol is shown to be robust, the results would strengthen the case that factual knowledge in LLMs is stored and retrieved in a distributed, redundant manner rather than in localized circuits, offering a mechanistic explanation for why localized editing techniques frequently fail to produce consistent or generalizable changes.
major comments (2)
- [Methods (iterative patching protocol)] The iterative patching protocol (described in the methods) assumes sequential removal of layers identifies a minimal causally relevant set without order dependence or unaccounted inter-layer interactions in the residual stream. No ablation is reported that re-runs the search in randomized orders or measures whether patching layer i changes the necessity of layer j, which directly undermines the claims of non-contiguity and multiple equivalent paths.
- [Results] The results section reports the existence of non-contiguous paths and redundancy but provides no quantitative details on the size of the minimal sets, the fraction of facts exhibiting multiple paths, statistical tests for the skipping pattern, or controls confirming that patched outputs match the original model on the target attribute while differing on controls.
minor comments (1)
- [Abstract] The abstract states that paths 'often skip layers' but does not define the criterion used to declare a layer skipped versus merely non-minimal.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. Below, we provide point-by-point responses to the major comments and outline the revisions we will make to address the concerns raised.
read point-by-point responses
-
Referee: [Methods (iterative patching protocol)] The iterative patching protocol (described in the methods) assumes sequential removal of layers identifies a minimal causally relevant set without order dependence or unaccounted inter-layer interactions in the residual stream. No ablation is reported that re-runs the search in randomized orders or measures whether patching layer i changes the necessity of layer j, which directly undermines the claims of non-contiguity and multiple equivalent paths.
Authors: We acknowledge that our iterative patching protocol is a greedy procedure and may exhibit order dependence, which was not fully ablated in the original submission. In the revised manuscript, we will include additional experiments re-running the search with multiple randomized orders of layer removal and report the overlap and stability of the resulting minimal sets. We will also analyze inter-layer interactions by sequentially patching layers and observing changes in the necessity of subsequent layers. These analyses will directly support or qualify our claims regarding non-contiguity and path redundancy. revision: yes
-
Referee: [Results] The results section reports the existence of non-contiguous paths and redundancy but provides no quantitative details on the size of the minimal sets, the fraction of facts exhibiting multiple paths, statistical tests for the skipping pattern, or controls confirming that patched outputs match the original model on the target attribute while differing on controls.
Authors: We agree that the results would benefit from more quantitative reporting. The revised version will include: (1) statistics on the sizes of the minimal layer sets (means, medians, distributions across facts); (2) the fraction of facts for which multiple distinct minimal paths were identified; (3) statistical tests (e.g., permutation tests) assessing whether the observed layer-skipping patterns are significant; and (4) control experiments demonstrating that the patched model outputs match the original on the target attribute while remaining unchanged on control attributes. These additions will be presented in new tables and figures. revision: yes
Circularity Check
No significant circularity; claims rest on direct experimental observations
full rationale
The paper presents an iterative patching protocol as a method to identify minimal layer subsets for attribute computation and reports empirical findings (non-contiguous paths, redundancy) as measured outcomes on LLaMA 3.1 8B and Qwen3 8B. No equations, fitted parameters, or self-citations are used to derive the central claims; the results are observational outputs of the protocol rather than quantities defined in terms of themselves or reduced by construction. The derivation chain is self-contained against the experimental benchmarks described.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The iterative patching protocol accurately identifies minimal subsets of layers required for attribute computation without unintended side effects on model behavior.
Reference graph
Works this paper leans on
-
[1]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, and 8 others. 2025. https://transformer-circuits.pub/2025/attribution...
2025
-
[2]
Bilal Chughtai, Alan Cooney, and Neel Nanda. 2024. Summing up the facts: Additive mechanisms behind factual recall in llms. arXiv preprint arXiv:2402.07321
arXiv 2024
-
[3]
Roi Cohen, Mor Geva, Jonathan Berant, and Amir Globerson. 2023. Crawling the internal knowledge-base of language models. arXiv preprint arXiv:2301.12810
arXiv 2023
-
[4]
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2021. Knowledge neurons in pretrained transformers. arXiv preprint arXiv:2104.08696
arXiv 2021
-
[5]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The llama 3 herd of models. arXiv e-prints, pages arXiv--2407
2024
-
[6]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, and 6 others. 2021. A mathematical framework for transformer circuits. Transformer C...
2021
-
[7]
Brodley, Arjun Guha, Jonathan Bell, Byron C Wallace, and David Bau
Jaden Fried Fiotto-Kaufman, Alexander Russell Loftus, Eric Todd, Jannik Brinkmann, Koyena Pal, Dmitrii Troitskii, Michael Ripa, Adam Belfki, Can Rager, Caden Juang, Aaron Mueller, Samuel Marks, Arnab Sen Sharma, Francesca Lucchetti, Nikhil Prakash, Carla E. Brodley, Arjun Guha, Jonathan Bell, Byron C Wallace, and David Bau. 2025. https://openreview.net/fo...
2025
-
[8]
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. 2023. Dissecting recall of factual associations in auto-regressive language models. arXiv preprint arXiv:2304.14767
arXiv 2023
-
[9]
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. 2022. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. In Proceedings of the 2022 conference on empirical methods in natural language processing, pages 30--45
2022
-
[10]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484--5495
2021
-
[11]
Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva. 2024. Patchscopes: A unifying framework for inspecting hidden representations of language models. arXiv preprint arXiv:2401.06102
arXiv 2024
-
[12]
Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. 2023. Localizing model behavior with path patching. arXiv preprint arXiv:2304.05969
Pith/arXiv arXiv 2023
-
[13]
Daniela Gottesman and Mor Geva. 2024. Estimating knowledge in large language models without generating a single token. arXiv preprint arXiv:2406.12673
arXiv 2024
-
[14]
Wes Gurnee and Max Tegmark. 2023. Language models represent space and time. arXiv preprint arXiv:2310.02207
arXiv 2023
-
[15]
Peter Hase, Mohit Bansal, Been Kim, and Asma Ghandeharioun. 2023. Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models. Advances in Neural Information Processing Systems, 36:17643--17668
2023
-
[16]
Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. 2023. Linearity of relation decoding in transformer language models. arXiv preprint arXiv:2308.09124
arXiv 2023
-
[17]
Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. 2020. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8:423--438
2020
-
[18]
Shahar Katz, Yonatan Belinkov, Mor Geva, and Lior Wolf. 2024. Backward lens: Projecting language model gradients into the vocabulary space. arXiv preprint arXiv:2402.12865
arXiv 2024
-
[19]
Thomas McGrath, Matthew Rahtz, Janos Kramar, Vladimir Mikulik, and Shane Legg. 2023. The hydra effect: Emergent self-repair in language model computations. arXiv preprint arXiv:2307.15771
arXiv 2023
-
[20]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. Advances in neural information processing systems, 35:17359--17372
2022
-
[21]
Neel Nanda, Senthooran Rajamanoharan, János Kramár, and Rohin Shah. 2023. https://www.alignmentforum.org/posts/iGuwZTHWb6DFY3sKB/fact-finding-attempting-to-reverse-engineer-factual-recall Fact finding: Attempting to reverse-engineer factual recall on the neuron level . AI Alignment Forum
2023
-
[22]
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. 2020. https://doi.org/10.23915/distill.00024.001 Zoom in: An introduction to circuits . Distill. Https://distill.pub/2020/circuits/zoom-in
-
[23]
Fabio Petroni, Tim Rockt \"a schel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. 2019. Language models as knowledge bases? arXiv preprint arXiv:1909.01066
Pith/arXiv arXiv 2019
-
[24]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. Investigating gender bias in language models using causal mediation analysis. Advances in neural information processing systems, 33:12388--12401
2020
-
[25]
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. 2022. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. arXiv preprint arXiv:2211.00593
Pith/arXiv arXiv 2022
-
[26]
Zijian Wang and Chang Xu. 2025. Functional abstraction of knowledge recall in large language models. arXiv preprint arXiv:2504.14496
arXiv 2025
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[28]
Yunzhi Yao, Ningyu Zhang, Zekun Xi, Mengru Wang, Ziwen Xu, Shumin Deng, and Huajun Chen. 2024. Knowledge circuits in pretrained transformers. Advances in Neural Information Processing Systems, 37:118571--118602
2024
-
[29]
Zeping Yu and Sophia Ananiadou. 2024. Neuron-level knowledge attribution in large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3267--3280
2024
-
[30]
Zeping Yu, Yonatan Belinkov, and Sophia Ananiadou. 2025. Back attention: Understanding and enhancing multi-hop reasoning in large language models. arXiv preprint arXiv:2502.10835
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.