MedHal-Loc: Are "Explainable-by-Architecture" Medical Hallucination Detectors Faithful Localizers? A Localization Benchmark
Pith reviewed 2026-06-26 14:13 UTC · model grok-4.3
The pith
Detection competence in medical hallucination detectors does not guarantee faithful localization of errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
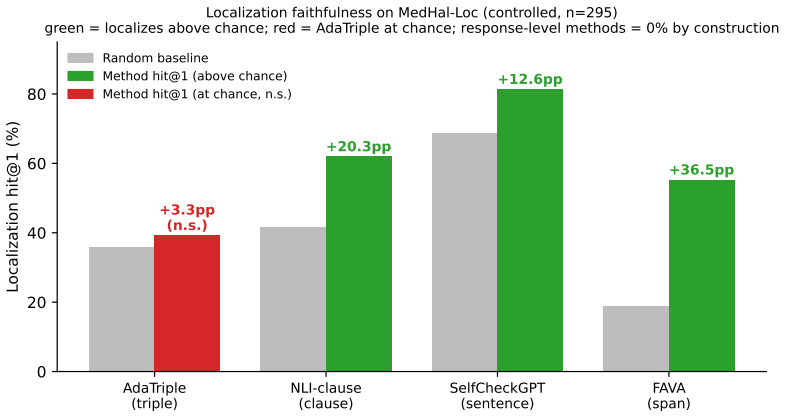
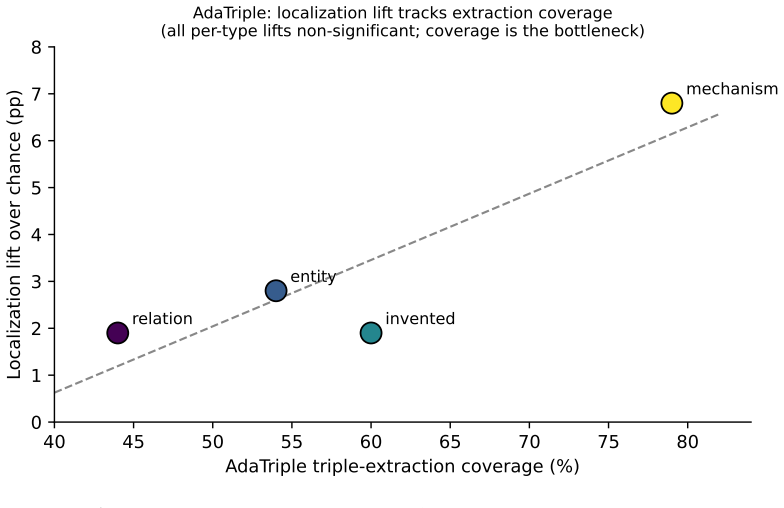
Evaluating four fine-grained paradigms, we find that NLI-per-clause, consistency-per-sentence, and the dedicated span detector FAVA all localize well above chance, whereas an elaborate KG-triple pipeline localizes no better than chance (+3.3pp, n.s.), bottlenecked by ~59% entity-extraction coverage -- despite competitive detection F1 (0.609). Detection competence does not imply faithful localization; architectural explainability must be validated, not presumed.
What carries the argument
The localization faithfulness metric that checks whether a detector's top-ranked error unit overlaps the gold erroneous span in the MedHal-Loc benchmark.
If this is right
- KG-triple pipelines need better entity extraction to achieve localization performance.
- NLI-per-clause and consistency-per-sentence approaches provide usable localization in controlled settings.
- Real-world medical hallucinations often resist span-level localization.
- Architectural claims of explainability require explicit localization testing.
Where Pith is reading between the lines
- The benchmark could be adapted to test localization in non-medical domains where hallucinations also occur.
- Methods might need to handle multi-span or diffuse errors rather than assuming single-span cases.
- Detection F1 alone is insufficient as an evaluation metric for explainable systems.
Load-bearing premise
That the four injected span-level error types and the overlap metric adequately represent what faithful localization means for the diffuse hallucinations found in real medical text.
What would settle it
Finding that most natural medical hallucinations are diffuse conclusion-flips with no identifiable single erroneous span, as the paper's human expert review of 18 cases already indicates.
Figures



read the original abstract
Detecting hallucinations in clinical text is increasingly framed as an explainability problem: systems should not merely flag an unreliable response but point to the offending span. Architectures built around knowledge-graph (KG) triple decomposition are marketed for exactly this auditability, yet their localization ability is typically assumed rather than measured. We introduce MedHal-Loc, a benchmark and metric for localization faithfulness -- whether a detector's top-ranked error unit actually overlaps the erroneous span. The controlled subset comprises 300 PubMedQA-derived statements with single, span-level errors injected across four localizable types (entity substitution, relation error, mechanism misattribution, invention), yielding gold spans by construction; a complementary natural subset documents that real hallucinations are dominated by diffuse conclusion-flips that resist span localization (a human expert accepted 1/18 candidate spans). Evaluating four fine-grained paradigms, we find that NLI-per-clause, consistency-per-sentence, and the dedicated span detector FAVA all localize well above chance, whereas an elaborate KG-triple pipeline localizes no better than chance (+3.3pp, n.s.), bottlenecked by ~59% entity-extraction coverage -- despite competitive detection F1 (0.609). Detection competence does not imply faithful localization; architectural explainability must be validated, not presumed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MedHal-Loc benchmark to test whether hallucination detectors that are explainable-by-architecture can faithfully localize erroneous spans in medical text. On a controlled subset of 300 PubMedQA-derived statements with four types of injected single-span errors (yielding gold spans by construction), NLI-per-clause, consistency-per-sentence, and FAVA localize well above chance while a KG-triple pipeline localizes at chance level (+3.3pp, n.s.) despite competitive detection F1 (0.609), limited by ~59% entity-extraction coverage. A natural subset shows real hallucinations are dominated by diffuse conclusion-flips (human expert accepts only 1/18 candidate spans as localizable). The central claim is that detection competence does not imply faithful localization, so architectural explainability must be validated rather than presumed.
Significance. If the dissociation result holds, the work is significant for medical AI safety: it supplies a concrete benchmark with gold spans and shows that KG-based pipelines, despite strong detection, can fail at localization due to coverage bottlenecks. The controlled-vs-natural contrast and the explicit metric (top-ranked overlap) are strengths that make the empirical point falsifiable and reproducible in principle.
major comments (2)
- [Abstract] Abstract (natural subset paragraph): the finding that real hallucinations are dominated by diffuse conclusion-flips (only 1/18 spans accepted by expert) means the positive localization results and the top-ranked overlap metric apply only to the minority of cases that happen to contain discrete erroneous spans by construction; this limits the force of the claim that architectural explainability must be validated in the practical medical setting the paper targets.
- [Abstract] Abstract (controlled subset results): the dissociation between detection F1 (0.609) and localization (+3.3pp n.s. for the KG pipeline) is load-bearing for the central claim, yet the abstract reports no error bars, exact p-values, or replication details, making it impossible to judge whether the "no better than chance" conclusion is robust.
minor comments (1)
- [Abstract] Abstract: the four injected error types are listed but their precise definitions and injection procedure are not summarized, which would help readers assess how representative they are even of the controlled setting.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below and propose targeted revisions to the abstract and discussion to improve clarity and statistical transparency while preserving the paper's core empirical contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract (natural subset paragraph): the finding that real hallucinations are dominated by diffuse conclusion-flips (only 1/18 spans accepted by expert) means the positive localization results and the top-ranked overlap metric apply only to the minority of cases that happen to contain discrete erroneous spans by construction; this limits the force of the claim that architectural explainability must be validated in the practical medical setting the paper targets.
Authors: We agree that the natural-subset result is important context and already use it to qualify the scope of the localization metric. The controlled subset is deliberately constructed to isolate localization faithfulness under conditions where gold spans exist by design; the natural subset then shows that such conditions are rare in practice. This contrast is central to our argument: even when discrete erroneous spans are present, KG-based detectors fail to localize them reliably, while the prevalence of diffuse hallucinations further underscores why architectural explainability cannot be assumed. We will revise the abstract to explicitly state that the top-ranked overlap results apply to the subset of hallucinations that admit span-level localization and to emphasize the practical implication that most real medical hallucinations may require different evaluation paradigms. revision: partial
-
Referee: [Abstract] Abstract (controlled subset results): the dissociation between detection F1 (0.609) and localization (+3.3pp n.s. for the KG pipeline) is load-bearing for the central claim, yet the abstract reports no error bars, exact p-values, or replication details, making it impossible to judge whether the "no better than chance" conclusion is robust.
Authors: The referee is correct that the abstract omits these details. The full manuscript reports bootstrap confidence intervals and exact p-values for the localization metric (Section 4.3 and Appendix C), but the abstract condenses this to "+3.3pp, n.s." We will expand the abstract to include the 95% CI for the KG localization result and the exact p-value, along with a brief note on the bootstrap procedure, to make the statistical robustness immediately verifiable from the abstract alone. revision: yes
Circularity Check
No significant circularity; empirical benchmark evaluation is self-contained.
full rationale
The paper introduces a new benchmark (MedHal-Loc) with controlled injected span errors and a natural subset, then measures localization faithfulness via direct overlap metrics on the constructed data. No mathematical derivations, equations, fitted parameters, or self-citation chains appear in the provided text; the central dissociation finding (detection F1 does not entail faithful localization) rests on empirical measurements rather than any reduction of outputs to inputs by construction. This is standard independent benchmark work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four injected error types and the top-ranked unit overlap metric measure faithful localization for medical hallucinations
Reference graph
Works this paper leans on
-
[1]
Large language models encode clinical knowledge.Nature, 620:172–180, 2023
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, et al., Large language models encode clinical knowledge, Nature 620 (7972) (2023) 172–180.doi:10.1038/s41586-023-06291-2
-
[2]
H. Nori, N. King, S. M. McKinney, D. Carignan, E. Horvitz, Ca- pabilities of GPT-4 on medical challenge problems, arXiv preprint arXiv:2303.13375 (2023). 16
Pith/arXiv arXiv 2023
-
[3]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, et al., Survey of hallucina- tion in natural language generation, ACM Computing Surveys 55 (12) (2023) 1–38.doi:10.1145/3571730
-
[4]
ACM Transactions on Information Systems43(2), 1–55 (2025) https://doi.org/10.1145/3703155
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, T. Liu, A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions, ACM Transactions on Information Systems 43 (2) (2025) 1–55.doi: 10.1145/3703155
-
[5]
Y. Kim, H. Jeong, S. Chen, S. S. Li, M. Lu, K. Alhamoud, et al., Med- ical hallucination in foundation models and their impact on healthcare, medRxiv (2025).doi:10.1101/2025.02.28.25323115
-
[6]
S. Min, K. Krishna, X. Lyu, M. Lewis, W. Yih, P. W. Koh, M. Iyyer, L. Zettlemoyer, H. Hajishirzi, FActScore: Fine-grained atomic evalua- tion of factual precision in long form text generation, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Pro- cessing, Association for Computational Linguistics, 2023, pp. 12076– 12100.doi:...
- [7]
-
[8]
Pandit, J
S. Pandit, J. Xu, J. Hong, Z. Wang, T. Chen, K. Xu, Y. Ding, Med- Hallu: A comprehensive benchmark for detecting medical hallucinations in large language models, in: Proceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing, Association for Com- putational Linguistics, 2025, pp. 2858–2873
2025
-
[9]
Q. Jin, B. Dhingra, Z. Liu, W. W. Cohen, X. Lu, PubMedQA: A dataset for biomedical research question answering, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, 2019, pp. 2567–2577.d...
-
[10]
P. Manakul, A. Liusie, M. J. F. Gales, SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models, in: Findings of the Association for Computational Linguistics: EMNLP 2023, Association for Computational Linguistics, 2023, pp. 9004–9017. doi:10.18653/v1/2023.findings-emnlp.557. 17
-
[11]
P. He, J. Gao, W. Chen, DeBERTaV3: Improving DeBERTa us- ing ELECTRA-style pre-training with gradient-disentangled embedding sharing, in: The Eleventh International Conference on Learning Repre- sentations (ICLR 2023), 2023
2023
-
[12]
Hughes, A
C. Hughes, A. Sahu, J. Frey, HHEM-2.1-Open: An open-source halluci- nation evaluation model, Vectara, Hugging Face model card,https:// huggingface.co/vectara/hallucination_evaluation_model(2024)
2024
-
[13]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al., Qwen2.5 technical report, arXiv preprint arXiv:2412.15115 (2024)
Pith/arXiv arXiv 2024
-
[14]
Detecting hallucinations in large language models using semantic entropy , volume =
S. Farquhar, J. Kossen, L. Kuhn, Y. Gal, Detecting hallucinations in large language models using semantic entropy, Nature 630 (2024) 625– 630.doi:10.1038/s41586-024-07421-0
-
[15]
B. Yang, et al., Hallucination detection in large language models with metamorphic relations, arXiv preprint arXiv:2502.15844 (2025)
arXiv 2025
-
[16]
H. Sansford, et al., GraphEval: A knowledge-graph based LLM halluci- nation evaluation framework, arXiv preprint arXiv:2407.10793 (2024)
arXiv 2024
-
[17]
González, S
M. González, S. Boldsen, R. Hangelbroek, TripleCheck: Transparent post-hoc verification of biomedical claims in AI-generated answers, in: Proceedings of the 4th Workshop on Bridging Human–Computer Inter- action and Natural Language Processing at ACL 2025, Association for Computational Linguistics, 2025
2025
-
[18]
L. Zhao, et al., Zero-resource hallucination detection for text generation via graph-based contextual knowledge triples modeling, in: Proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI 2025), 2025
2025
-
[19]
S. Chen, et al., A probabilistic framework for LLM hallucination detec- tion via belief tree propagation, in: Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computa- tional Linguistics, 2025, pp. 2891–2912
2025
-
[20]
L. K. Umapathi, A. Pal, M. Sankarasubbu, Med-HALT: Medical do- main hallucination test for large language models, arXiv preprint arXiv:2307.15343 (2023). 18
arXiv 2023
-
[21]
Y. Liu, Q. Yang, J. Tang, Y. Guo, Z. Wang, Y. Liu, Reduc- ing hallucinations of large language models via hierarchical semantic piece, Complex & Intelligent Systems 11 (2025) 231.doi:10.1007/ s40747-025-01764-5
2025
-
[22]
D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, P. Szolovits, What disease does this patient have? A large-scale open domain question answering dataset from medical exams, Applied Sciences 11 (14) (2021) 6421.doi:10.3390/app11146421
-
[23]
Fact or Fiction: Verifying Scientific Claims
D. Wadden, S. Lin, K. Lo, L. L. Wang, M. van Zuylen, A. Cohan, H. Hajishirzi, Fact or fiction: Verifying scientific claims, in: Proceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, 2020, pp. 7534–7550.doi:10.18653/v1/2020.emnlp-main.609
-
[24]
Hendrycks, C
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, J. Steinhardt, Measuring massive multitask language understanding, in: Proceedings of the 9th International Conference on Learning Represen- tations (ICLR 2021), 2021
2021
-
[25]
F. Liu, E. Shareghi, Z. Meng, M. Basaldella, N. Collier, Self-alignment pretraining for biomedical entity representations, in: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, 2021, pp. 4228–4238.doi:10.18653/v1/ 2021.n...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.