T-MOR: Learning Motion-Aware Skeleton Representations for Human Action Recognition
Pith reviewed 2026-06-26 14:42 UTC · model grok-4.3
The pith
Skeleton sequences alone achieve strong action recognition after aligning with video and text during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
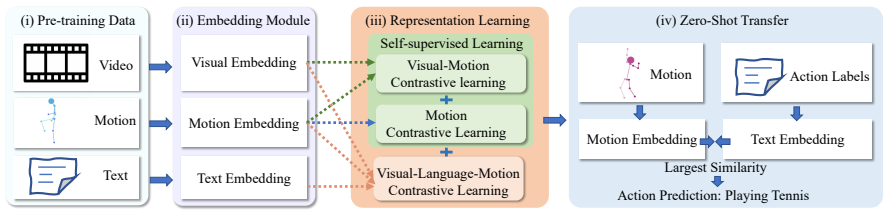
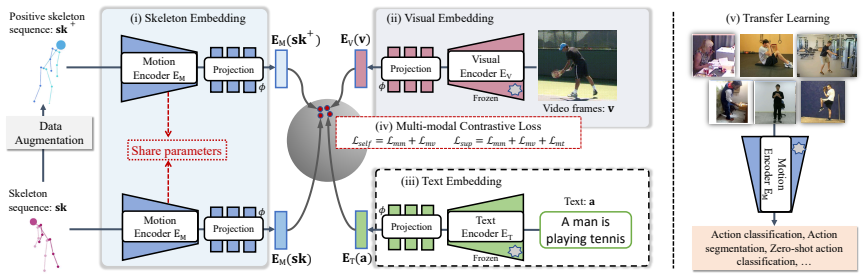
T-MOR learns transferable action representations from skeleton sequences with the aid of video and language supervision during training. It adopts a multi-modal contrastive learning scheme that aligns skeleton motion with visual and textual representations, while performing inference using only lightweight skeleton inputs. Pre-training is supported by the PoseCap-1M dataset containing over one million synchronized video, skeleton, and text triplets. This produces improved performance on action classification and frame-wise temporal detection across multiple benchmarks and demonstrates strong generalization in few-shot and zero-shot settings.
What carries the argument
multi-modal contrastive learning scheme that aligns skeleton motion with visual and textual representations
If this is right
- Skeleton-only inference achieves competitive results on action classification and frame-wise temporal detection tasks.
- Representations generalize across datasets in both few-shot and zero-shot regimes.
- Large-scale pre-training on synchronized video-skeleton-text triplets improves motion-centric action understanding.
- The framework supports human-centric benchmarks where motion structure matters more than appearance.
Where Pith is reading between the lines
- Motion patterns can be effectively decoupled from visual appearance for transferable recognition if the alignment holds.
- The method suggests deployment in settings where only pose data is available or affordable at test time.
- Scaling the pre-training triplets further could strengthen generalization to additional temporal understanding tasks.
- The same alignment principle might apply to other embodied modalities beyond skeletons.
Load-bearing premise
The multi-modal contrastive alignment learned from video and text supervision during training will produce skeleton representations that remain effective when video and text are removed at inference time.
What would settle it
An ablation experiment on the same datasets showing that removing the multi-modal contrastive alignment causes performance to drop to the level of standard skeleton baselines without video or text pre-training.
Figures

read the original abstract
Vision-language models such as CLIP have recently achieved strong performance on a wide range of visual understanding tasks. However, most existing models rely primarily on appearance-level supervision from images or videos, and do not explicitly model human motion, which is essential for fine-grained and human-centric action recognition task as actions are defined by temporally structured and physically grounded body movements. To address this problem, we propose Transferable skeleton MOtion Representation (T-MOR), a motion-aware framework that learns transferable action representations from skeleton sequences with the aid of video and language supervision during training. T-MOR adopts a multi-modal contrastive learning scheme that aligns skeleton motion with visual and textual representations, while performing inference using only lightweight skeleton inputs. To support large-scale pre-training, we construct PoseCap-1M, a new dataset that contains over one million synchronized video, skeleton, and text triplets covering diverse human activities. We evaluate T-MOR on a range of human-centric action recognition benchmarks, including action classification and frame-wise temporal detection. Experimental results show that T-MOR consistently improves performance across multiple datasets, such as Toyota Smarthome, Penn Action, UAV-Human, TSU, and Charades. In addition, T-MOR demonstrates strong generalization ability in few-shot and zero-shot settings, highlighting the effectiveness of motion-centric and embodied representations for transferable action understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes T-MOR, a framework for learning motion-aware skeleton representations for human action recognition. It employs multi-modal contrastive learning to align skeleton sequences with video and text embeddings from vision-language models during training, enabling inference with only skeleton inputs. The authors introduce PoseCap-1M, a dataset of over one million synchronized video-skeleton-text triplets, and evaluate on action classification and frame-wise temporal detection tasks across benchmarks including Toyota Smarthome, Penn Action, UAV-Human, TSU, and Charades, claiming consistent improvements and strong few-shot/zero-shot generalization.
Significance. If the transfer from multi-modal training to effective skeleton-only inference holds and is supported by rigorous ablations, the work could meaningfully advance efficient, motion-centric action recognition by leveraging large-scale pre-training without requiring video or text at test time. The construction and release of PoseCap-1M would be a concrete community contribution for skeleton-based pre-training research.
major comments (2)
- [Abstract] Abstract (paragraph describing the inference setup): The central claim requires that contrastive alignment of skeleton sequences to video and text embeddings during training produces a skeleton encoder whose outputs remain discriminative when video and text are removed at inference. However, the abstract supplies no quantitative evidence such as an ablation removing the video/text contrastive terms, a comparison against a skeleton-only baseline, or analysis of surviving motion features. This assumption is load-bearing for the reported gains and generalization results.
- [Abstract] Abstract (experimental results paragraph): Performance improvements are described only qualitatively ('consistently improves performance across multiple datasets') with no reference to specific tables, numerical deltas, or error bars. Without these, the magnitude, statistical significance, and robustness of the claimed gains on Toyota Smarthome, Penn Action, UAV-Human, TSU, and Charades cannot be assessed.
minor comments (1)
- [Abstract] Abstract: 'task as actions' appears to be a grammatical error and should read 'tasks, as actions'.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address each point below and will revise the abstract accordingly to provide more quantitative support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing the inference setup): The central claim requires that contrastive alignment of skeleton sequences to video and text embeddings during training produces a skeleton encoder whose outputs remain discriminative when video and text are removed at inference. However, the abstract supplies no quantitative evidence such as an ablation removing the video/text contrastive terms, a comparison against a skeleton-only baseline, or analysis of surviving motion features. This assumption is load-bearing for the reported gains and generalization results.
Authors: The abstract is space-constrained and provides a high-level overview of the approach. Detailed ablations, including comparisons against skeleton-only baselines and the effect of removing video/text contrastive terms, along with analysis of the learned motion features, are presented in the experiments section of the full manuscript. To strengthen the abstract, we will revise it to briefly reference these quantitative results and point to the relevant tables and sections. revision: yes
-
Referee: [Abstract] Abstract (experimental results paragraph): Performance improvements are described only qualitatively ('consistently improves performance across multiple datasets') with no reference to specific tables, numerical deltas, or error bars. Without these, the magnitude, statistical significance, and robustness of the claimed gains on Toyota Smarthome, Penn Action, UAV-Human, TSU, and Charades cannot be assessed.
Authors: We agree that the abstract would be more informative with specific numerical evidence. In the revised version, we will update the results paragraph to include representative numerical deltas from the main experiments (with references to the corresponding tables) while maintaining the abstract's brevity. revision: yes
Circularity Check
No significant circularity in claimed derivation
full rationale
The paper describes a standard multi-modal contrastive pretraining setup on a newly constructed dataset (PoseCap-1M) followed by empirical evaluation of the resulting skeleton encoder on held-out benchmarks. No equations, fitted parameters, or predictions are shown that reduce by construction to the training inputs; the central claim is an empirical performance gain rather than a self-referential derivation. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz that would force the result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quo vadis, action recognition? a new model and the kinetics dataset,
Joao Carreira and Andrew Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” inCVPR, 2017
2017
-
[2]
Videomae v2: Scaling video masked autoencoders with dual masking,
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, and Yu Qiao, “Videomae v2: Scaling video masked autoencoders with dual masking,” inCVPR, 2023
2023
-
[3]
Crcl: Causal representation consistency learning for anomaly detection in surveillance videos,
Yang Liu, Hongjin Wang, Zepu Wang, Xiaoguang Zhu, Jing Liu, Peng Sun, Rui Tang, Jianwei Du, Victor Leung, and Liang Song, “Crcl: Causal representation consistency learning for anomaly detection in surveillance videos,”IEEE TIP, 2025
2025
-
[4]
Anomaly detec- tion and generation with diffusion models: A survey,
Yang Liu, Jing Liu, Chengfang Li, Rui Xi, Wenchao Li, Liang Cao, Jin Wang, Laurence T Yang, Junsong Yuan, and Wei Zhou, “Anomaly detec- tion and generation with diffusion models: A survey,”arXiv:2506.09368, 2025
arXiv 2025
-
[5]
Privacy- preserving video anomaly detection: A survey,
Yang Liu, Siao Liu, Xiaoguang Zhu, Jielin Li, Hao Yang, Liangyu Teng, Juncen Guo, Yan Wang, Dingkang Yang, and Jing Liu, “Privacy- preserving video anomaly detection: A survey,”IEEE TNNLS, 2025
2025
-
[6]
Stnmamba: Mamba-based spatial-temporal normality learning for video anomaly detection,
Zhangxun Li, Mengyang Zhao, Xuan Yang, Yang Liu, Jiamu Sheng, Xinhua Zeng, Tian Wang, Kewei Wu, and Yu-Gang Jiang, “Stnmamba: Mamba-based spatial-temporal normality learning for video anomaly detection,”IEEE TMM, 2026
2026
-
[7]
Spatial temporal graph convolu- tional networks for skeleton-based action recognition,
S. Yan, Yuanjun Xiong, and D. Lin, “Spatial temporal graph convolu- tional networks for skeleton-based action recognition,”AAAI, 2018
2018
-
[8]
Unik: A unified framework for real-world skeleton-based action recognition,
Di Yang, Yaohui Wang, Antitza Dantcheva, Lorenzo Garattoni, Gian- piero Francesca, and Francois Bremond, “Unik: A unified framework for real-world skeleton-based action recognition,” inBMVC, 2021
2021
-
[9]
Motionbert: A unified perspective on learning human motion representations,
Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang, “Motionbert: A unified perspective on learning human motion representations,” inICCV, 2023
2023
-
[10]
thesis, Universit ´e C ˆote d’Azur, 2024
Di Yang,Learning effective video representations for action recognition, Ph.D. thesis, Universit ´e C ˆote d’Azur, 2024
2024
-
[11]
Internvid: A large-scale video-text dataset for multimodal understanding and generation,
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinyuan Chen, Yaohui Wang, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao, “Internvid: A large-scale video-text dataset for multimodal understanding and generation,” inICLR, 2024
2024
-
[12]
X-CLIP:: End-to-end multi-grained contrastive learning for video-text retrieval,
Yiwei Ma, Guohai Xu, Xiaoshuai Sun, Ming Yan, Ji Zhang, and Rongrong Ji, “X-CLIP:: End-to-end multi-grained contrastive learning for video-text retrieval,” inACMMM, 2022
2022
-
[13]
Quo Vadis, Video Un- derstanding with Vision-Language Foundation Models?,
Mahmoud Ali, Di Yang, Arkaprava Sinha, Dominick Reilly, Srijan Das, Gianpiero Francesca, and Francois Bremond, “Quo Vadis, Video Un- derstanding with Vision-Language Foundation Models?,” inNeurIPSW, 2024
2024
-
[14]
Are visual-language models effective in action recognition? a comparative study,
Mahmoud Ali, Di Yang, and Franc ¸ois Br ´emond, “Are visual-language models effective in action recognition? a comparative study,” inECCVW, 2024
2024
-
[15]
Toyota smarthome untrimmed: Real-world untrimmed videos for activity detection,
Rui Dai, Srijan Das, Saurav Sharma, Luca Minciullo, Lorenzo Garattoni, Francois Bremond, and Gianpiero Francesca, “Toyota smarthome untrimmed: Real-world untrimmed videos for activity detection,”IEEE TPAMI, 2022
2022
-
[16]
Momentum contrast for unsupervised visual representation learning,
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick, “Momentum contrast for unsupervised visual representation learning,” inCVPR, 2020
2020
-
[17]
3d human action representation learning via cross-view consistency pursuit,
Linguo Li, Minsi Wang, Bingbing Ni, Hang Wang, Jiancheng Yang, and Wenjun Zhang, “3d human action representation learning via cross-view consistency pursuit,” inCVPR, 2021
2021
-
[18]
Contrastive learning from extremely augmented skeleton sequences for self-supervised action recognition,
Guo Tianyu, Liu Hong, Chen Zhan, Liu Mengyuan, Wang Tao, and Ding Runwei, “Contrastive learning from extremely augmented skeleton sequences for self-supervised action recognition,” inAAAI, 2022
2022
-
[19]
Masked motion predictors are strong 3d action representation learners,
Yunyao Mao, Jiajun Deng, Wengang Zhou, Yao Fang, Wanli Ouyang, and Houqiang Li, “Masked motion predictors are strong 3d action representation learners,” inICCV, 2023
2023
-
[20]
An image is worth 16x16 words: Transformers for image recognition at scale,
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inICLR, 2021
2021
-
[21]
Learning transferable visual models from natural language supervision,
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever, “Learning transferable visual models from natural language supervision,” inICML, 2021
2021
-
[22]
A density-based algorithm for discovering clusters in large spatial databases with noise,
Martin Ester, Hans-Peter Kriegel, J ¨org Sander, and Xiaowei Xu, “A density-based algorithm for discovering clusters in large spatial databases with noise,” inKDD, 1996
1996
-
[23]
Unsupervised feature learning via non-parametric instance discrimination,
Z. Wu, Y . Xiong, S. X. Yu, and D. Lin, “Unsupervised feature learning via non-parametric instance discrimination,” inCVPR, 2018
2018
-
[24]
Internvideo: General video foundation models via generative and dis- criminative learning,
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, and Yu Qiao, “Internvideo: General video foundation models via generative and dis- criminative learning,”arXiv:2212.03191, 2022
Pith/arXiv arXiv 2022
-
[25]
Vlm: Task-agnostic video-language model pre-training for video un- derstanding,
Hu Xu, Gargi Ghosh, Po-Yao Huang, Prahal Arora, Masoumeh Amin- zadeh, Christoph Feichtenhofer, Florian Metze, and Luke Zettlemoyer, “Vlm: Task-agnostic video-language model pre-training for video un- derstanding,”arXiv preprint arXiv:2105.09996, 2021
arXiv 2021
-
[26]
Ntu rgb+d: A large scale dataset for 3D human activity analysis,
Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang, “Ntu rgb+d: A large scale dataset for 3D human activity analysis,”CVPR, 2016
2016
-
[27]
Ntu rgb+d 120: A large-scale benchmark for 3D human activity understanding,
J. Liu, A. Shahroudy, M. Perez, G. Wang, L. Y . Duan, and A. C. Kot, “Ntu rgb+d 120: A large-scale benchmark for 3D human activity understanding,”IEEE TPAMI, 2020
2020
-
[28]
Via: View-invariant skeleton action representation learning via motion retargeting,
Di Yang, Yaohui Wang, Antitza Dantcheva, Lorenzo Garattoni, Gian- piero Francesca, and Francois Bremond, “Via: View-invariant skeleton action representation learning via motion retargeting,”IJCV, 2024
2024
-
[29]
Framewise phoneme classifi- cation with bidirectional lstm and other neural network architectures,
Alex Graves and J ¨urgen Schmidhuber, “Framewise phoneme classifi- cation with bidirectional lstm and other neural network architectures,” IJCNN, 2005
2005
-
[30]
Temporal gaussian mixture layer for videos,
AJ Piergiovanni and Michael S. Ryoo, “Temporal gaussian mixture layer for videos,” inICML, 2019
2019
-
[31]
Motionclip: Exposing human motion generation to clip space,
Guy Tevet, Brian Gordon, Amir Hertz, Amit H Bermano, and Daniel Cohen-Or, “Motionclip: Exposing human motion generation to clip space,” inECCV, 2022
2022
-
[32]
Video-llava: Learning united visual representation by align- ment before projection,
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan, “Video-llava: Learning united visual representation by align- ment before projection,”arXiv preprint arXiv:2311.10122, 2023
Pith/arXiv arXiv 2023
-
[33]
Llava- onevision: Easy visual task transfer,
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li, “Llava- onevision: Easy visual task transfer,”arXiv preprint arXiv:2408.03326, 2024
Pith/arXiv arXiv 2024
-
[34]
Llavi- dal: Benchmarking large language vision models for daily activities of living,
Rajatsubhra Chakraborty, Arkaprava Sinha, Dominick Reilly, Man- ish Kumar Govind, Pu Wang, Francois Bremond, and Srijan Das, “Llavi- dal: Benchmarking large language vision models for daily activities of living,” inCVPR, 2025
2025
-
[35]
Video-chatgpt: Towards detailed video understanding via large vision and language models,
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan, “Video-chatgpt: Towards detailed video understanding via large vision and language models,” inACL, 2024
2024
-
[36]
Graph distillation for action detection with privileged modalities,
Zelun Luo, Jun-Ting Hsieh, Lu Jiang, Juan Carlos Niebles, and Li Fei- Fei, “Graph distillation for action detection with privileged modalities,” inECCV, 2018
2018
-
[37]
Learning an augmented rgb representation with cross-modal knowledge distillation for action detection,
Rui Dai, Srijan Das, and Franc ¸ois Bremond, “Learning an augmented rgb representation with cross-modal knowledge distillation for action detection,” inICCV, 2021
2021
-
[38]
Online human action detection using joint classification-regression recurrent neural networks,
Yanghao Li, Cuiling Lan, Junliang Xing, Wenjun Zeng, Chunfeng Yuan, and Jiaying Liu, “Online human action detection using joint classification-regression recurrent neural networks,” inECCV, 2016
2016
-
[39]
Pku-mmd: A large scale benchmark for continuous multi-modal human action understanding,
Liu Chunhui, Hu Yueyu, Li Yanghao, Song Sijie, and Liu Jiaying, “Pku-mmd: A large scale benchmark for continuous multi-modal human action understanding,”arXiv:1703.07475, 2017
Pith/arXiv arXiv 2017
-
[40]
Skeleton boxes: Solving skeleton based action detection with a single deep convolutional neural network,
Bo Li, Huahui Chen, Yucheng Chen, Yuchao Dai, and Mingyi He, “Skeleton boxes: Solving skeleton based action detection with a single deep convolutional neural network,” inICMEW, 2017
2017
-
[41]
Joint distance maps based action recognition with convolutional neural net- works,
Chuankun Li, Yonghong Hou, Pichao Wang, and Wanqing Li, “Joint distance maps based action recognition with convolutional neural net- works,” inICMEW, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.