Beyond the Next Step: Variable-Length Latent World Models for Long-Horizon Planning
Pith reviewed 2026-06-26 14:20 UTC · model grok-4.3
The pith
VLWMs train latent predictors on variable-length action sequences to avoid recursive rollout errors in long-horizon planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that conditioning latent dynamics directly on variable-length action sequences, rather than on single actions, lets the same model serve planning at different horizons and removes the need for recursive one-step rollout, with curriculum training enabling stable optimization from short to long sequences.
What carries the argument
A latent predictor that accepts action sequences of arbitrary length and outputs the future state after that sequence, trained via progressive horizon expansion.
If this is right
- One network can now evaluate both short and long action plans without separate predictors or repeated rollouts.
- Curriculum lengthening of action horizons stabilizes learning of extended dynamics.
- Planning methods can exploit queries at multiple horizons to improve decision quality.
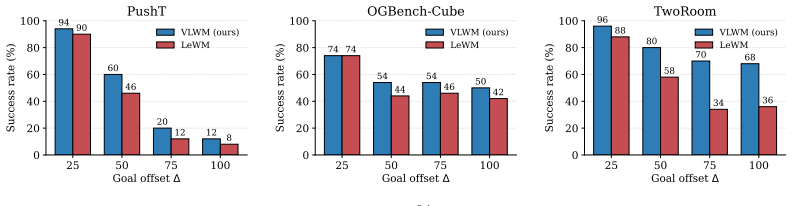
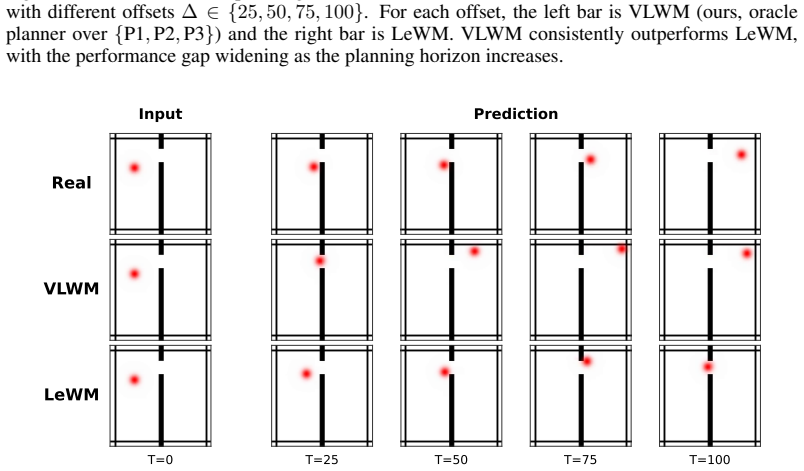
- Gains appear largest on control tasks that demand extended planning horizons.
- Average performance rises 13 percent over the prior LeWM baseline across tested datasets.
Where Pith is reading between the lines
- The variable-length conditioning idea could extend to other sequence prediction domains such as video or language modeling.
- Search algorithms might learn to select the most useful horizon length on the fly during planning.
- Model-based reinforcement learning policies could be trained to output variable-length action chunks rather than single steps.
- Real-world robot experiments would test whether curriculum-trained VLWMs transfer when dynamics contain unmodeled noise.
Load-bearing premise
Training directly on variable-length sequences yields stable long-range predictions without introducing new optimization failures or distribution mismatches that one-step models avoid.
What would settle it
A head-to-head test in which a one-step model with near-zero short-term error is unrolled to the same long horizon as a VLWM and the two are compared on final state accuracy.
Figures

read the original abstract
Recently, world models have emerged as a promising paradigm for building intelligent agents by learning predictive models that estimate future environment states conditioned on observations and actions. In particular, JEPA-style latent world models provide an efficient alternative to pixel space prediction by learning action-conditioned dynamics in compact representation spaces. However, existing latent world models typically rely on one-step prediction and must be recursively rolled out for long-horizon planning, which leads to compounding errors and a mismatch between training objectives and downstream planning tasks. To address this limitation, we propose Variable-length Latent World Models (VLWMs), a framework that learns to predict future latent states conditioned on action sequences of variable lengths. Instead of training only on one-step transitions, VLWMs directly model temporally extended dynamics, allowing the same predictor to evaluate action plans over different horizons. We further introduce a curriculum training strategy that progressively expands the action horizon, stabilizing optimization from short-range dynamics to long-range prediction. At test time, we design planning methods tailored to VLWMs to better exploit their variable-length predictive capabilities. Experiments on long-horizon control tasks show that VLWMs significantly improve latent space world models, achieving 13\% average improvement over the state-of-the-art LeWM across different datasets, with especially large gains on tasks requiring extended planning. These results suggest that VLWM provides a simple yet effective paradigm for improving long-horizon prediction and planning in latent world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Variable-length Latent World Models (VLWMs) that directly predict future latent states conditioned on action sequences of variable lengths rather than one-step transitions. It introduces a curriculum that progressively increases the action horizon during training and designs planning methods at test time that exploit the variable-length predictions. Experiments on long-horizon control tasks report a 13% average improvement over the state-of-the-art LeWM, with larger gains on tasks requiring extended planning.
Significance. If the reported gains can be attributed to the variable-length training objective rather than differences in test-time planning, the approach would offer a direct way to reduce the train-test mismatch that arises when one-step latent predictors are rolled out recursively for long horizons. The curriculum strategy and the ability to evaluate plans at multiple horizons in a single forward pass are potentially useful for latent world models in general.
major comments (1)
- [Abstract] Abstract: the central empirical claim is a 13% average improvement over LeWM 'with planning methods tailored to VLWMs to better exploit their variable-length predictive capabilities.' No ablation is described that holds the planning procedure fixed while varying only the training regime (one-step vs. variable-length). Because the abstract explicitly introduces planner changes at test time, the performance delta cannot yet be attributed to the training procedure itself; this directly affects the soundness of the main claim.
minor comments (2)
- The abstract and any experimental section should report error bars, number of seeds, dataset splits, and exact baseline implementations (including whether LeWM was re-evaluated under the new planner).
- Notation for the variable-length predictor and the curriculum schedule should be defined with explicit equations showing how the loss is computed for sequences of different lengths.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to clarify the source of the reported performance gains. We address the major comment below and commit to revisions that strengthen the attribution of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim is a 13% average improvement over LeWM 'with planning methods tailored to VLWMs to better exploit their variable-length predictive capabilities.' No ablation is described that holds the planning procedure fixed while varying only the training regime (one-step vs. variable-length). Because the abstract explicitly introduces planner changes at test time, the performance delta cannot yet be attributed to the training procedure itself; this directly affects the soundness of the main claim.
Authors: We agree that the current presentation does not fully isolate the contribution of the variable-length training objective from the test-time planning adaptations. The core technical contribution is the variable-length prediction model trained with curriculum, which directly addresses the train-test mismatch of recursive one-step rollouts. The tailored planning methods (e.g., multi-horizon evaluation in a single forward pass) are enabled by this model and form an integral part of the proposed framework. Nevertheless, to strengthen the claim, we will add an ablation in the revised manuscript that applies an identical fixed planning procedure (standard model-predictive control with fixed horizon) to both the baseline one-step LeWM and the VLWM. We will also revise the abstract to state that the 13% gain is achieved by the full VLWM approach (variable-length training plus its associated planning methods) and report the new ablation results to quantify the isolated effect of the training regime. This revision directly addresses the soundness concern. revision: yes
Circularity Check
No circularity; empirical method with external baseline comparison
full rationale
The paper proposes VLWMs as a new training framework (variable-length prediction + curriculum) evaluated via experiments against the external LeWM baseline. No derivation chain, equations, or first-principles results are presented that reduce to inputs by construction. Claims rest on reported performance deltas rather than tautological redefinitions or self-citation load-bearing arguments. The experimental design (including planner tailoring) may raise validity questions but does not constitute circularity under the specified patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muck- ley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self- supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[2]
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representa- tions from video.arXiv preprint arXiv:2404.08471, 2024
Pith/arXiv arXiv 2024
-
[3]
Genie: Gener- ative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Gener- ative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[4]
Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Nicholas Sukiennik, et al. Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
2025
-
[5]
World models.arXiv preprint arXiv:1803.10122, 2(3): 440, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3): 440, 2018
Pith/arXiv arXiv 2018
-
[6]
Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
Pith/arXiv arXiv 1912
-
[7]
TD-MPC2: Scalable, robust world models for continuous control
Nick Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. InICLR, 2024
2024
-
[8]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InNeurIPS, 2026
2026
-
[9]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. LeWorldModel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
Pith/arXiv arXiv 2026
-
[10]
Heejeong Nam, Quentin Le Lidec, Lucas Maes, Yann LeCun, and Randall Balestriero. Causal-jepa: Learning world models through object-level latent interventions.arXiv preprint arXiv:2602.11389, 2026
Pith/arXiv arXiv 2026
-
[11]
Va-red 2: Video adaptive redundancy reduction
Bowen Pan, Rameswar Panda, Camilo Fosco, Chung-Ching Lin, Alex Andonian, Yue Meng, Kate Saenko, Aude Oliva, and Rogerio Feris. Va-red 2: Video adaptive redundancy reduction. arXiv preprint arXiv:2102.07887, 2021
arXiv 2021
-
[12]
Ogbench: Benchmark- ing offline goal-conditioned rl
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmark- ing offline goal-conditioned rl. InICLR, 2025
2025
-
[13]
Springer Science & Business Media, 2004
Reuven Y Rubinstein and Dirk P Kroese.The cross-entropy method: a unified approach to combinatorial optimization, Monte-Carlo simulation and machine learning. Springer Science & Business Media, 2004
2004
-
[14]
Vlad Sobal, Wancong Zhang, Kyunghyun Cho, Randall Balestriero, Tim G. J. Rudner, and Yann LeCun. Stress-testing offline reward-free reinforcement learning: A case for planning with latent dynamics models. In7th Robot Learning Workshop: Towards Robots with Human- Level Abilities, 2025
2025
-
[15]
HunyuanWorld Team, Zhenwei Wang, Yuhao Liu, Junta Wu, Zixiao Gu, Haoyuan Wang, Xuhui Zuo, Tianyu Huang, Wenhuan Li, Sheng Zhang, et al. Hunyuanworld 1.0: Generat- ing immersive, explorable, and interactive 3d worlds from words or pixels.arXiv preprint arXiv:2507.21809, 2025
arXiv 2025
-
[16]
Longcat-video technical report
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report. arXiv preprint arXiv:2510.22200, 2025. 10
arXiv 2025
-
[17]
Learning to generate long-term future via hierarchical prediction
Ruben Villegas, Jimei Yang, Yuliang Zou, Sungryull Sohn, Xunyu Lin, and Honglak Lee. Learning to generate long-term future via hierarchical prediction. InICML, 2017
2017
-
[18]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[19]
Haichao Zhang, Yijiang Li, Shwai He, Tushar Nagarajan, Mingfei Chen, Jianglin Lu, Ang Li, and Yun Fu. ThinkJEPA: Empowering latent world models with large vision-language reasoning model.arXiv preprint arXiv:2603.22281, 2026
Pith/arXiv arXiv 2026
-
[20]
Hierarchical planning with latent world models.arXiv preprint arXiv:2604.03208, 2026
Wancong Zhang, Basile Terver, Artem Zholus, Soham Chitnis, Harsh Sutaria, Mido Assran, Randall Balestriero, Amir Bar, Adrien Bardes, Yann LeCun, et al. Hierarchical planning with latent world models.arXiv preprint arXiv:2604.03208, 2026
Pith/arXiv arXiv 2026
-
[21]
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024. 11 A Environment and Dataset Details We adopt the same three environments and datasets as LeWM [9], so that the planning protocol, data, and evaluation budgets are directly comparable...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.