AgentCAT: Simulating Computerized Adaptive Testing via Multi-Agent Large Language Models
Pith reviewed 2026-06-26 12:27 UTC · model grok-4.3
The pith
A multi-agent LLM system called AgentCAT simulates the full dynamic loop of computerized adaptive testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
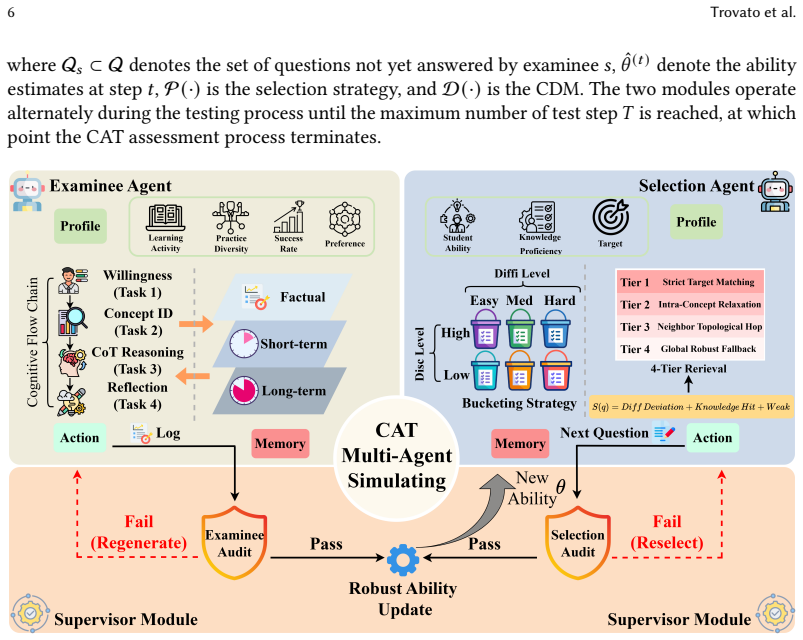
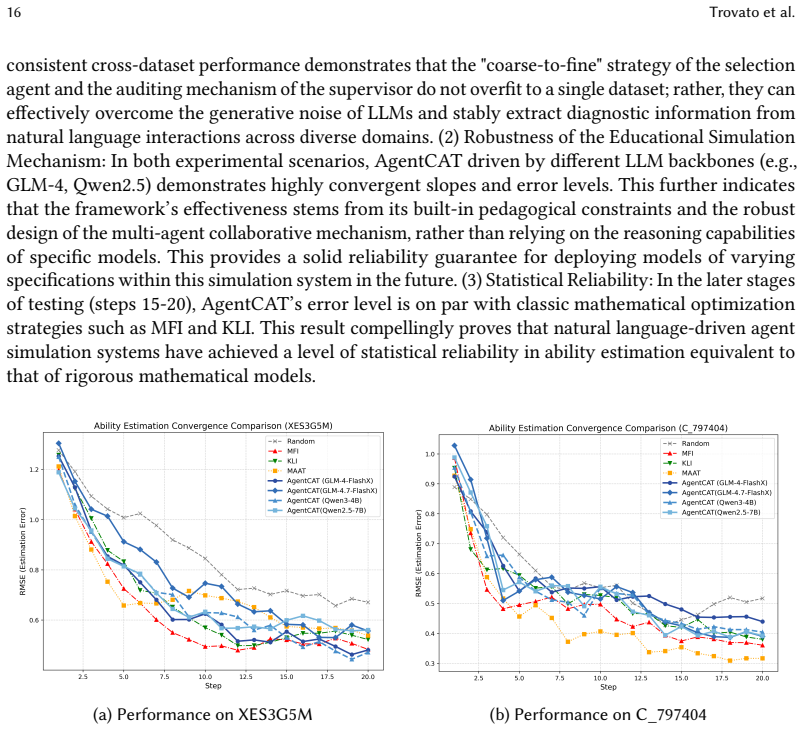
AgentCAT consists of an examinee agent that retrieves memory and applies chain-of-thought reasoning to generate responses, a selection agent that performs coarse-to-fine bucketing and knowledge-graph exploration to balance local difficulty with global coverage, and a supervisor that applies dual auditing and robust updates. On two real-world datasets the system produces converging ability estimates, micro-level interaction sequences that remain instructionally coherent, and stable performance under data sparsity.
What carries the argument
The three-agent loop (examinee, selection, supervisor) that enacts the complete CAT interaction cycle using only cognitive profiles and a knowledge graph.
If this is right
- Ability estimates produced by the simulation converge to stable values at the macro level.
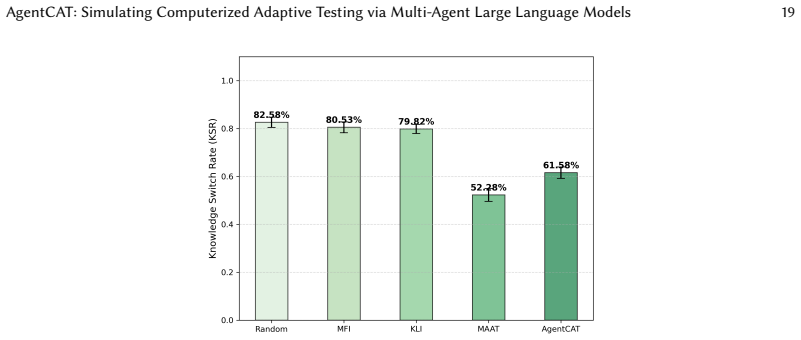
- Item sequences generated by the selection agent maintain both difficulty adaptation and instructional coherence.
- The framework continues to function when training data are sparse.
- The overall interaction process can be audited for validity without access to real examinee logs.
Where Pith is reading between the lines
- The same agent architecture could be used to generate large volumes of synthetic response traces for pre-training or stress-testing new CAT algorithms.
- If the agents prove faithful, the framework offers a low-cost way to compare alternative selection policies before any live deployment with students.
- Extending the supervisor module to track bias metrics could allow early detection of fairness problems in proposed CAT rules.
Load-bearing premise
Large language model agents will produce response patterns and selection decisions that match those of real humans when supplied only with cognitive profiles and knowledge graphs.
What would settle it
Run AgentCAT on a dataset that also contains recorded human responses to the same items; large systematic differences between the simulated and human ability trajectories or item sequences would falsify the claim.
Figures






read the original abstract
Computerized Adaptive Testing (CAT), as a key technology for personalized education, aims to accurately assess examinee proficiency by retrieving exercises dynamically matching current ability estimates. However, existing CAT research is constrained by limitations of static offline data and isolated component optimization. Restricted by partial labels in offline logs, researchers degrade the dynamic assessment process into static sequence prediction. Current research focuses on isolated perspectives, e.g., selection or diagnosis, neglecting the overall CAT interaction process. To address this, we propose AgentCAT, a Large Language Model-based multi-agent simulation system, to construct a high-fidelity benchmarking environment for dynamic testing. This framework comprises three modules: (1) The examinee agent with memory retrieval and Chain-of-Thought reasoning simulates responses based on cognitive profiles; (2) The selection agent uses coarse-to-fine bucketing and knowledge graph exploration to balance local difficulty and global coverage; (3) The supervisor uses dual-auditing and robust update to ensure convergence and validity. To validate the framework, we evaluated on two real-world datasets across three dimensions: macro-level ability convergence, micro-level interaction logic, and data sparsity resilience. Results show AgentCAT achieves effective ability estimation, and its selection strategy balances difficulty adaptation and instructional coherence, aligning with human pedagogical intuition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AgentCAT, a multi-agent LLM framework to simulate the full dynamic process of Computerized Adaptive Testing (CAT) beyond static offline data limitations. It consists of an examinee agent (memory retrieval + CoT for response simulation from cognitive profiles), a selection agent (coarse-to-fine bucketing + KG exploration for item choice balancing local difficulty and global coverage), and a supervisor (dual-auditing and robust updates for convergence). The system is evaluated on two real-world datasets across three dimensions—macro-level ability convergence, micro-level interaction logic, and data sparsity resilience—with claims of effective ability estimation and selection strategy alignment with human pedagogical intuition.
Significance. If the simulation is shown to faithfully reproduce human response patterns and pedagogical decisions without LLM artifacts, this could provide a valuable high-fidelity benchmarking environment for CAT research, enabling dynamic testing of algorithms and addressing the field's reliance on partial offline logs and isolated component optimization.
major comments (2)
- [Abstract] Abstract: The claims of 'effective ability estimation' and a selection strategy that 'balances difficulty adaptation and instructional coherence, aligning with human pedagogical intuition' are presented without any quantitative metrics, error bars, baseline comparisons, or description of measurement procedures for ability convergence or interaction logic, so the data-to-claim link cannot be verified.
- [Evaluation] Evaluation section: No held-out human response baseline, inter-rater agreement with actual examinee logs, or teacher selection comparisons is described; without this, macro-level convergence could be an artifact of LLM priors rather than recovered human dynamics, directly undermining the central claim of high-fidelity simulation.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help improve the manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'effective ability estimation' and a selection strategy that 'balances difficulty adaptation and instructional coherence, aligning with human pedagogical intuition' are presented without any quantitative metrics, error bars, baseline comparisons, or description of measurement procedures for ability convergence or interaction logic, so the data-to-claim link cannot be verified.
Authors: We concur that the abstract should provide more concrete support for its claims. Accordingly, we will revise the abstract to include quantitative metrics from the evaluation, such as specific convergence measures, error statistics, and references to baseline comparisons and procedures used. This revision will be made to enhance verifiability. revision: yes
-
Referee: [Evaluation] Evaluation section: No held-out human response baseline, inter-rater agreement with actual examinee logs, or teacher selection comparisons is described; without this, macro-level convergence could be an artifact of LLM priors rather than recovered human dynamics, directly undermining the central claim of high-fidelity simulation.
Authors: The manuscript evaluates AgentCAT on two real-world datasets across the specified dimensions, demonstrating the framework's performance. We recognize the absence of held-out human baselines and inter-rater agreements as noted. This is because the available data consists of partial offline logs, limiting direct human comparisons. We will add a section discussing this limitation and the steps taken in the multi-agent design (e.g., memory retrieval and supervisor auditing) to reduce reliance on LLM priors alone. We believe this addresses the concern without new experiments, though we agree additional validation would strengthen the high-fidelity claim. revision: partial
Circularity Check
No significant circularity; derivation is empirical framework proposal without self-referential reductions
full rationale
The paper introduces AgentCAT as a multi-agent LLM simulation for CAT with examinee, selection, and supervisor modules, evaluated empirically on two real-world datasets for ability convergence, interaction logic, and sparsity resilience. No equations, derivations, or parameter-fitting steps are described that reduce outputs to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no predictions are presented as fitted inputs renamed. The framework claims rest on described agent behaviors and dataset results rather than circular definitions or self-referential chains, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jasper Meynard Arana, Kristine Ann M Carandang, Ethan Robert Casin, Christian Alis, Daniel Stanley Tan, Erika Fille Legara, and Christopher Monterola. 2025. Foundations of PEERS: Assessing LLM role performance in educational simulations. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. 908–918
2025
-
[2]
Haoyang Bi, Qi Liu, Han Wu, Weidong He, Zhenya Huang, Yu Yin, Haiping Ma, Yu Su, Shijin Wang, and Enhong Chen
-
[3]
Model-agnostic adaptive testing for intelligent education systems via meta-learned gradient embeddings.ACM Transactions on Intelligent Systems and Technology15, 5 (2024), 1–26
2024
-
[4]
Haoyang Bi, Haiping Ma, Zhenya Huang, Yu Yin, Qi Liu, Enhong Chen, Yu Su, and Shijin Wang. 2020. Quality meets diversity: A model-agnostic framework for computerized adaptive testing. In2020 IEEE International Conference on Data Mining (ICDM). IEEE, 42–51
2020
-
[5]
Lianyu Cai, Mgambi Msambwa Msafiri, and Daniel Kangwa. 2025. Exploring the impact of integrating AI tools in higher education using the Zone of Proximal Development.Education and Information Technologies30, 6 (2025), 7191–7264
2025
-
[6]
Xiaoming Cao, Shiting Xu, Xinyue Chen, Yujie Song, Qiurui Luo, and Tao He. 2026. Leveraging Generative AI Agent to Promote Teaching Reflection in a K–12 AI Course: Effects on Teachers’ Reflection Self-Efficacy, Instructional Design, and Reflective Thinking.IEEE Transactions on Learning Technologies19 (2026), 127–140. doi:10.1109/TLT.2026.3668051
-
[7]
Hua-Hua Chang and Zhiliang Ying. 1996. A global information approach to computerized adaptive testing.Applied Psychological Measurement20, 3 (1996), 213–229
1996
-
[8]
REPLUG: Retrieval-augmented black- box language models, in: Duh, K., Gomez, H., Bethard, S
Zhendong Chu, Shen Wang, Jian Xie, Tinghui Zhu, Yibo Yan, Jingheng Ye, Aoxiao Zhong, Xuming Hu, Jing Liang, Philip S. Yu, and Qingsong Wen. 2025. LLM Agents for Education: Advances and Applications. InFindings of the Association for Computational Linguistics: EMNLP 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.)...
-
[9]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2025. The faiss library.IEEE Transactions on Big Data(2025)
2025
-
[10]
Qian Fu, Yaning Zhao, Zixi Jia, and Yafeng Zheng. 2025. Large Language Models (LLMs) in Programming Learning: The Current Research State and Agenda.IEEE Transactions on Learning Technologies18 (2025), 942–961. doi:10.1109/ TLT.2025.3622043
arXiv 2025
-
[11]
Weibo Gao, Qi Liu, Linan Yue, Fangzhou Yao, Rui Lv, Zheng Zhang, Hao Wang, and Zhenya Huang. 2025. Agent4edu: Generating learner response data by generative agents for intelligent education systems. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23923–23932
2025
-
[12]
Aritra Ghosh and Andrew Lan. 2021. BOBCAT: Bilevel Optimization-Based Computerized Adaptive Testing. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, 2410–2417
2021
-
[13]
Yuxiang Guo, Yan Zhuang, Qi Liu, Zhenya Huang, Xianquan Wang, Liyang He, Jiatong Li, Rui Li, and Shijin Wang
-
[14]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
From Diagnosis to Generalization: A Cognitive Approach to Data Selection for Educational LLMs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 21522–21530
-
[15]
Zhanxin Hao, Jie Cao, Ruimiao Li, Jifan Yu, Zhiyuan Liu, and Yu Zhang. 2026. Mapping student-AI interaction dynamics in multi-agent learning environments: Supporting personalized learning and reducing performance gaps.Comput. Educ.241 (2026), 105472. doi:10.1016/J.COMPEDU.2025.105472
-
[16]
Bihao Hu, Jiayi Zhu, Yiying Pei, and Xiaoqing Gu. 2025. Exploring the potential of LLM to enhance teaching plans through teaching simulation.npj Science of Learning10, 1 (2025), 7
2025
-
[17]
Chao Huang, Huance Xu, Yong Xu, Peng Dai, Lianghao Xia, Mengyin Lu, Liefeng Bo, Hao Xing, Xiaoping Lai, and Yanfang Ye. 2021. Knowledge-aware coupled graph neural network for social recommendation. InProceedings of the AAAI conference on artificial intelligence, Vol. 35. 4115–4122
2021
-
[18]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 7969–7992
2023
-
[19]
Daehwan Kim, Kwangrok Ryoo, Hansang Cho, and Seungryong Kim. 2025. SplitNet: Learnable clean-noisy label splitting for learning with noisy labels.International Journal of Computer Vision133, 2 (2025), 549–566
2025
-
[20]
Qi Lang, Shengjing Tian, Mo Wang, and Jianan Wang. 2024. Exploring the Answering Capability of Large Language Models in Addressing Complex Knowledge in Entrepreneurship Education.IEEE Transactions on Learning Technologies 17 (2024), 2053–2062. , Vol. 1, No. 1, Article . Publication date: June 2026. 24 Trovato et al
2024
-
[21]
Yuanhao Liu, Yiya You, Shuo Liu, Hong Qian, Ying Qian, and Aimin Zhou. 2025. A fast-adaptive cognitive diagnosis framework for computerized adaptive testing systems. InProceedings of the 34th International Joint Conference on Artificial Intelligence. Montreal, Canada
2025
-
[22]
Zitao Liu, Qiongqiong Liu, Teng Guo, Jiahao Chen, Shuyan Huang, Xiangyu Zhao, Jiliang Tang, Weiqi Luo, and Jian Weng. 2023. Xes3g5m: A knowledge tracing benchmark dataset with auxiliary information.Advances in Neural Information Processing Systems36 (2023), 32958–32970
2023
-
[23]
Zirui Liu, Yan Zhuang, Qi Liu, Jiatong Li, Yuren Zhang, Zhenya Huang, Jinze Wu, and Shijin Wang. 2024. Computerized adaptive testing via collaborative ranking.Advances in Neural Information Processing Systems37 (2024), 95488–95514
2024
-
[24]
2012.Applications of item response theory to practical testing problems
Frederic M Lord. 2012.Applications of item response theory to practical testing problems. Routledge
2012
-
[25]
Haiping Ma, Changqian Wang, Hengshu Zhu, Shangshang Yang, Xiaoming Zhang, and Xingyi Zhang. 2024. Enhancing cognitive diagnosis using un-interacted exercises: A collaboration-aware mixed sampling approach. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 8877–8885
2024
-
[26]
Haiping Ma, Aoqing Xia, Changqian Wang, Hai Wang, and Xingyi Zhang. 2025. Diffusion-Inspired Cold Start with Sufficient Prior in Computerized Adaptive Testing. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 997–1007
2025
-
[27]
Haiping Ma, Weiyuan Zhou, Xiaoshan Yu, Changqian Wang, Shangshang Yang, Limiao Zhang, and Xingyi Zhang
-
[28]
InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
Reconciling efficiency and effectiveness of exercise retreival: An uncertainty reduction hashing approach for computerized adaptive testing. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1044–1054
-
[29]
Zhiyuan Ma, Jiayu Liu, Xianzhen Luo, Zhenya Huang, Qingfu Zhu, and Wanxiang Che. 2025. Advancing tool- augmented large language models via meta-verification and reflection learning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 2078–2089
2025
-
[30]
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. 2025. A comprehensive overview of large language models.ACM Transactions on Intelligent Systems and Technology16, 5 (2025), 1–72
2025
-
[31]
Cong-Duy T Nguyen, Xiaobao Wu, Thong Thanh Nguyen, Shuai Zhao, Khoi M Le, Nguyen Viet Anh, Feng Yichao, and Luu Anh Tuan. 2025. Enhancing multimodal entity linking with jaccard distance-based conditional contrastive learning and contextual visual augmentation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association f...
2025
-
[32]
Manh Hung Nguyen, Victor-Alexandru Padurean, Alkis Gotovos, Sebastian Tschiatschek, and Adish Singla. 2025. Synthesizing High-Quality Programming Tasks with LLM-Based Expert and Student Agents. InArtificial Intelligence in Education - 26th International Conference, AIED 2025, Palermo, Italy, July 22-26, 2025, Proceedings, Part I. Springer, 77–91. doi:10.1...
-
[33]
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, et al. 2025. Scaling large language model-based multi-agent collaboration. InInternational Conference on Learning Representations, Vol. 2025. 41488–41505
2025
-
[34]
Kantwon Rogers, Michael Davis, Mallesh Maharana, Pete Etheredge, and Sonia Chernova. 2025. Playing Dumb to Get Smart: Creating and Evaluating an LLM-based Teachable Agent within University Computer Science Classes. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–22
2025
-
[35]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems36 (2023), 8634–8652
2023
-
[36]
Ignacio Villagrán, Rocío Hernández, Gregory Schuit, Andrés Neyem, Javiera Fuentes-Cimma, Constanza Miranda, Isabel Hilliger, Valentina Durán, Gabriel Escalona, and Julián Varas. 2024. Implementing Artificial Intelligence in Physiotherapy Education: A Case Study on the Use of Large Language Models (LLM) to Enhance Feedback.IEEE Transactions on Learning Tec...
-
[37]
Changqian Wang, Shangshang Yang, Siyu Song, Ziwen Wang, Haiping Ma, Xingyi Zhang, and Bo Jin. 2025. Explicit and Implicit Examinee-Question Relation Exploiting for Efficient Computerized Adaptive Testing. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12685–12693
2025
-
[38]
Hangyu Wang, Ting Long, Liang Yin, Weinan Zhang, Wei Xia, Qichen Hong, Dingyin Xia, Ruiming Tang, and Yong Yu. 2023. GMOCAT: A Graph-Enhanced Multi-Objective Method for Computerized Adaptive Testing. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2279–2289
2023
-
[39]
Tianyou Wang and Walter P Vispoel. 1998. Properties of ability estimation methods in computerized adaptive testing. Journal of Educational Measurement35, 2 (1998), 109–135
1998
-
[40]
Tianfu Wang, Yi Zhan, Jianxun Lian, Zhengyu Hu, Nicholas Jing Yuan, Qi Zhang, Xing Xie, and Hui Xiong. 2025. Llm- powered multi-agent framework for goal-oriented learning in intelligent tutoring system. InCompanion Proceedings of the ACM on Web Conference 2025. 510–519. , Vol. 1, No. 1, Article . Publication date: June 2026. AgentCAT: Simulating Computeri...
2025
-
[41]
Rob Wass and Clinton Golding. 2014. Sharpening a tool for teaching: the zone of proximal development.Teaching in Higher Education19, 6 (2014), 671–684
2014
-
[42]
Xiaolong Wei, Bo Lu, Xingyu Zhang, Zhejun Zhao, Dongdong Shen, Long Xia, and Dawei Yin. 2025. Igniting creative writing in small language models: Llm-as-a-judge versus multi-agent refined rewards. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 17171–17197
2025
-
[43]
Linjin Xi, Yi Zhang, and Qiyun Wang. 2025. Investigating the effects of an LLM-based Socratic conversational agent on students’ academic performance and reflective thinking in higher education.Computers & Education(2025), 105494
2025
-
[44]
Linjin Xi, Yi Zhang, and Qiyun Wang. 2026. Investigating the effects of an LLM-based Socratic conversational agent on students’ academic performance and reflective thinking in higher education.Comput. Educ.241 (2026), 105494. doi:10.1016/J.COMPEDU.2025.105494
-
[45]
Juan Yang, Minjuan Wang, Xu Du, and Rina Na. 2025. A Comprehensive Survey on Large-Language-Model-Based Agents for Education.IEEE Transactions on Learning Technologies18 (2025), 898–913. doi:10.1109/TLT.2025.3617909
-
[46]
Fangzhou Yao, Qi Liu, Min Hou, Shiwei Tong, Zhenya Huang, Enhong Chen, Jing Sha, and Shijin Wang. 2023. Exploiting non-interactive exercises in cognitive diagnosis.Interaction100, 200 (2023), 300
2023
-
[47]
Fangzhou Yao, Qi Liu, Linan Yue, Weibo Gao, Jiatong Li, Xin Li, and Yuanjing He. 2024. Adard: An adaptive response denoising framework for robust learner modeling. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3886–3895
2024
-
[48]
Danial Yazdani, Mohammad Nabi Omidvar, Donya Yazdani, Jürgen Branke, Trung Thanh Nguyen, Amir H Gandomi, Yaochu Jin, and Xin Yao. 2023. Robust optimization over time: a critical review.IEEE Transactions on Evolutionary Computation(2023)
2023
-
[49]
Huizi Yu, Jiayan Zhou, Lingyao Li, Shan Chen, Jack Gallifant, Anye Shi, Jie Sun, Xiang Li, Jingxian He, Wenyue Hua, et al. 2025. Simulated patient systems powered by large language model-based AI agents offer potential for transforming medical education.Communications Medicine(2025)
2025
-
[50]
Jifan Yu, Mengying Lu, Qingyang Zhong, Zijun Yao, Shangqing Tu, Zhengshan Liao, Xiaoya Li, Manli Li, Lei Hou, Hai-Tao Zheng, et al. 2023. Moocradar: A fine-grained and multi-aspect knowledge repository for improving cognitive student modeling in moocs. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information ...
2023
-
[51]
Xiaoshan Yu, Shangshang Yang, Ziwen Wang, Siyu Song, Haiping Ma, Zhiguang Cao, and Xingyi Zhang. 2025. LIGHT: Enhancing Learning Path Recommendation via Knowledge Topology-Aware Sequence Optimization. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 306–315
2025
-
[52]
Ziyao Zhang, Chong Wang, Yanlin Wang, Ensheng Shi, Yuchi Ma, Wanjun Zhong, Jiachi Chen, Mingzhi Mao, and Zibin Zheng. 2025. Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 481–503
2025
-
[53]
Zheyuan Zhang, Daniel Zhang-Li, Jifan Yu, Linlu Gong, Jinchang Zhou, Zhanxin Hao, Jianxiao Jiang, Jie Cao, Huiqin Liu, Zhiyuan Liu, et al. 2025. Simulating classroom education with llm-empowered agents. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies ...
2025
-
[54]
Lanqin Zheng, Zhe Shi, and Lei Gao. 2026. A generative artificial intelligence-enhanced multiagent approach to empowering collaborative problem solving across different learning domains.Comput. Educ.241 (2026), 105489. doi:10.1016/J.COMPEDU.2025.105489
-
[55]
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Daisy Zhe Wang, Zhenhailong Wang, Cheng Qian, Robert Tang, Heng Ji, et al. 2025. Multiagentbench: Evaluating the collaboration and competition of llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8580–8622
2025
-
[56]
Yan Zhuang, Qi Liu, Haoyang Bi, Zhenya Huang, Weizhe Huang, Jiatong Li, Junhao Yu, Zirui Liu, Zirui Hu, Yuting Hong, et al. 2026. Survey of Computerized Adaptive Testing: a Machine Learning Perspective.IEEE Transactions on Pattern Analysis and Machine Intelligence(2026)
2026
-
[57]
Yan Zhuang, Qi Liu, Zhenya Huang, Zhi Li, Shuanghong Shen, and Haiping Ma. 2022. Fully adaptive framework: Neural computerized adaptive testing for online education. InProceedings of the AAAI conference on artificial intelligence, Vol. 36. 4734–4742. , Vol. 1, No. 1, Article . Publication date: June 2026
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.