FeLoG: Scalable and Efficient Distributed Graph Embedding with Feedback Loop Mechanism
Pith reviewed 2026-06-26 11:06 UTC · model grok-4.3
The pith
FeLoG couples real-time embedding quality feedback to sampling and communication to reduce redundant work in distributed graph embedding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
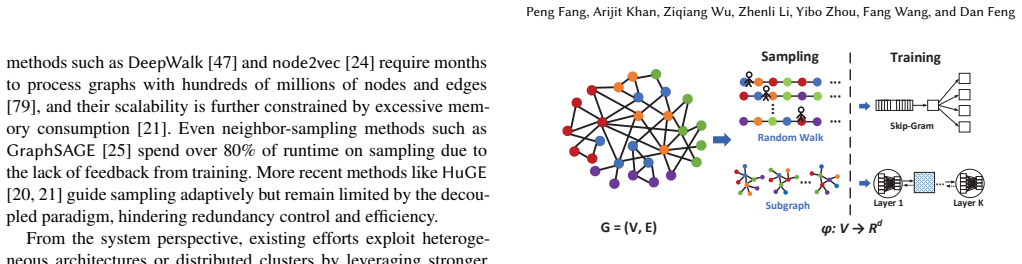
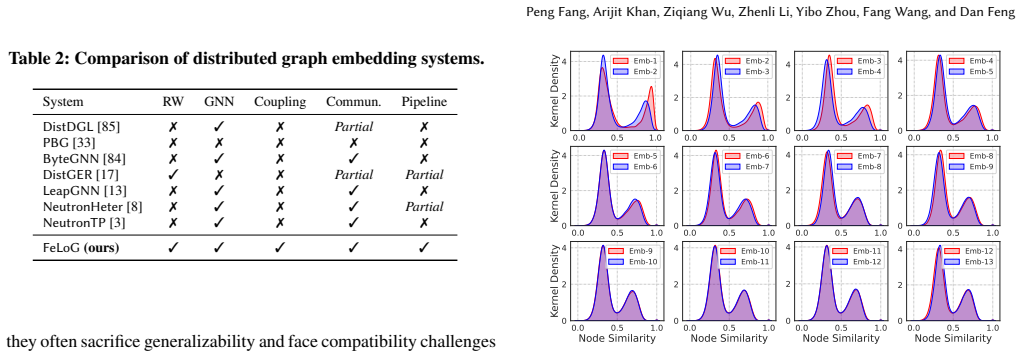
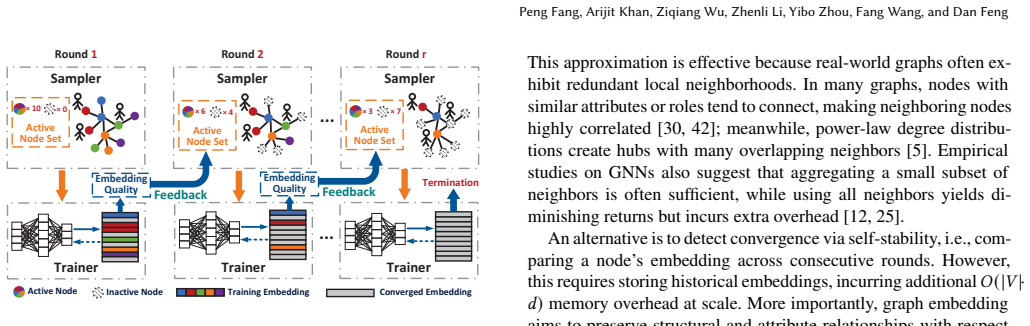
FeLoG introduces feedback-coupled sampling that dynamically prioritizes undertrained nodes according to real-time embedding-quality signals, activity-aware communication that compresses frequent node sequences and selectively synchronizes embeddings, and a round-interleaved pipeline that overlaps next-round sampling with current-round training; together these changes reduce redundant computation, cut communication cost, and raise CPU-GPU utilization on large-scale graphs.
What carries the argument
The feedback loop that links evolving embedding quality to sampling priorities and communication decisions.
If this is right
- Redundant sampling of already well-embedded nodes drops because priorities shift to undertrained regions.
- Intra-machine PCIe traffic and inter-machine synchronization both decrease through sequence compression and selective updates.
- CPU-GPU utilization rises above 80 percent by interleaving sampling of the next round with training of the current round.
- Convergence accelerates on large graphs relative to six prior distributed frameworks.
- Average end-to-end speedup reaches 27.9 times with communication cost falling more than 53 percent.
Where Pith is reading between the lines
- The same feedback principle could be tested on distributed training of graph neural networks beyond simple embedding.
- Energy consumption per embedding task may fall in data-center settings if communication volume shrinks as reported.
- Adaptive feedback loops of this type might generalize to other sampling-heavy distributed workloads such as large language model fine-tuning on graphs.
- Experiments on graphs with different degree distributions would reveal whether the prioritization rule remains effective.
Load-bearing premise
The cost of computing and applying real-time embedding-quality feedback stays small enough that net savings in sampling and communication remain large.
What would settle it
On a billion-edge graph, if the measured time spent calculating and acting on feedback exceeds the measured time saved in sampling and data transfer, the claimed net speedup disappears.
Figures














read the original abstract
Graph embedding maps graph nodes into low-dimensional vectors to support applications such as recommendation, fraud detection, and graph-based retrieval-augmented generation (GraphRAG). As graphs scale to billions of edges, scalable and efficient graph embedding has become increasingly important. Existing frameworks commonly adopt a sampling-training paradigm, in which mini-batches are constructed by sampling nodes and their neighbors. However, sampling is typically decoupled from evolving embedding quality, causing redundant exploration of well-trained regions while under-sampling undertrained nodes. At the system level, such decoupling further leads to excessive communication, serialized execution, and low resource utilization in distributed environments. We present FeLoG, a feedback loop-driven system for scalable distributed graph embedding. (1) FeLoG introduces feedback-coupled sampling and training, dynamically prioritizing undertrained nodes according to real-time embedding-quality feedback, thereby reducing redundant computation and accelerating convergence. (2) It employs activity-aware communication that compresses frequently occurring node sequences to reduce intra-machine PCIe traffic and selectively synchronizes frequently updated embeddings to reduce inter-machine communication. (3) It adopts a round-interleaved pipeline that overlaps next-round sampling with current-round training to improve CPU-GPU utilization. Experiments against six state-of-the-art baselines on large-scale graphs show that FeLoG achieves an average speedup of 27.9x, reduces communication cost by more than 53.1%, and sustains over 80% CPU-GPU utilization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FeLoG, a distributed graph embedding system that couples sampling with real-time embedding-quality feedback to prioritize undertrained nodes, uses activity-aware communication to compress node sequences and selectively synchronize embeddings, and employs a round-interleaved pipeline to overlap sampling and training. It reports an average 27.9× speedup, >53.1% communication reduction, and >80% CPU-GPU utilization versus six baselines on large-scale graphs.
Significance. If the reported gains are reproducible, the work would constitute a practical advance in scalable systems for graph embedding by showing how feedback can reduce redundant sampling and communication in distributed settings. The contribution is primarily empirical and systems-oriented; its value depends directly on the rigor and transparency of the evaluation.
major comments (1)
- [Abstract] Abstract: The central empirical claims (27.9× speedup, 53.1% communication reduction, >80% utilization) are presented without any description of graph sizes (nodes/edges), baseline implementations, hardware configuration, measurement methodology, or statistical significance. These omissions are load-bearing because the net benefit of the feedback-coupled sampling rests entirely on whether its overhead is low enough to produce the stated gains; without the experimental details the claims cannot be assessed.
minor comments (1)
- [Abstract] The abstract paragraph describing the feedback mechanism could be expanded with one sentence on how embedding quality is quantified and how often feedback is computed, to clarify the overhead assumption.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the abstract requires additional context to make the empirical claims assessable and will revise it accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (27.9× speedup, 53.1% communication reduction, >80% utilization) are presented without any description of graph sizes (nodes/edges), baseline implementations, hardware configuration, measurement methodology, or statistical significance. These omissions are load-bearing because the net benefit of the feedback-coupled sampling rests entirely on whether its overhead is low enough to produce the stated gains; without the experimental details the claims cannot be assessed.
Authors: We agree with this assessment. The current abstract is too concise and omits key experimental parameters that are necessary to evaluate the reported gains. In the revised version we will expand the abstract (while remaining within length limits) to include: (1) graph scales (up to 10^9 edges), (2) the six baselines and their implementations, (3) hardware configuration (multi-node CPU-GPU clusters), (4) measurement methodology (wall-clock time, communication volume, utilization averaged over 5 runs), and (5) a note on statistical significance. These additions will allow readers to judge whether the feedback-loop overhead is justified by the observed speedups. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical systems contribution describing a feedback-coupled sampling design, activity-aware communication, and round-interleaved pipeline for distributed graph embedding. All central claims rest on end-to-end experimental measurements (27.9× speedup, 53.1% communication reduction, >80% utilization) against six baselines on large graphs. No equations, fitted parameters, uniqueness theorems, or self-citation chains are present that would reduce any prediction or result to its own inputs by construction. The design choices are evaluated directly via reported performance metrics rather than through definitional equivalence or internal fitting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Our code and datasets
2026. Our code and datasets. https://github.com/RocmFang/FeLoG
2026
-
[2]
Xin Ai, Qiange Wang, Chunyu Cao, Y anfeng Zhang, Chaoyi Chen, Hao Y uan, Y u Gu, and Ge Y u. 2024. NeutronOrch: Rethinking Sample-Based GNN Train- ing under CPU-GPU Heterogeneous Environments. Proceedings of the VLDB Endowment 17, 8 (2024), 1995–2008
2024
-
[3]
Xin Ai, Hao Y uan, Zeyu Ling, Qiange Wang, Y anfeng Zhang, Zhenbo Fu, Chaoyi Chen, Y u Gu, and Ge Y u. 2025. NeutronTP: Load-Balanced Distributed Full- Graph GNN Training with Tensor Parallelism. In 51st International Conference on V ery Large Data Bases. 173–186
2025
-
[4]
Guangji Bai, Ziyang Y u, Zheng Chai, Y ue Cheng, and Liang Zhao. 2025. Staleness-alleviated distributed gnn training via online dynamic-embedding pre- diction. In Proceedings of the 2025 SIAM International Conference on Data Min- ing (SDM). SIAM, 578–587
2025
-
[5]
Albert-László Barabási and Réka Albert. 1999. Emergence of scaling in random networks. Science 286, 5439 (1999), 509–512
1999
-
[6]
Paolo Boldi, Massimo Santini, and Sebastiano Vigna. 2008. A large time-aware web graph. In ACM SIGIR F orum, V ol. 42. ACM New Y ork, NY , USA, 33–38
2008
-
[7]
Hongyun Cai, Vincent W Zheng, and Kevin Chen-Chuan Chang. 2018. A com- prehensive survey of graph embedding: Problems, techniques, and applications. IEEE Transactions on Knowledge and Data Engineering 30, 9 (2018), 1616– 1637
2018
-
[8]
Chunyu Cao, Xin Ai, Qiange Wang, Y anfeng Zhang, Zhenbo Fu, Hao Y uan, Mingyi Cao, Chaoyi Chen, Yingyou Wen, Y u Gu, et al. 2025. NeutronHeter: Op- timizing Distributed Graph Neural Network Training for Heterogeneous Clusters. Proceedings of the ACM on Management of Data 3, 4 (2025), 1–29
2025
-
[9]
Jiahang Cao, Jinyuan Fang, Zaiqiao Meng, and Shangsong Liang. 2024. Knowl- edge graph embedding: A survey from the perspective of representation spaces. Comput. Surveys 56, 6 (2024), 1–42
2024
-
[10]
Deepayan Chakrabarti, Yiping Zhan, and Christos Faloutsos. 2004. R-MA T: A Recursive Model for Graph Mining. In Proceedings of the SIAM International Conference on Data Mining . 442–446
2004
-
[11]
Chee-Y ong Chan and Y annis E Ioannidis. 1998. Bitmap index design and eval- uation. In Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data. 355–366
1998
-
[12]
Jie Chen, Tengfei Ma, and Cao Xiao. 2018. FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling. In International Conference on Learning Representations
2018
-
[13]
Weijian Chen, Shuibing He, Haoyang Qu, and Xuechen Zhang. 2025. LeapGNN: Accelerating Distributed GNN Training Leveraging Feature-Centric Model Mi- gration. In 23rd USENIX Conference on File and Storage Technologies (F AST 25). 255–270
2025
-
[14]
Xu Cheng, Liang Y ao, Feng He, Y ukuo Cen, Y ufei He, Chenhui Zhang, Wenzheng Feng, Hongyun Cai, and Jie Tang. 2025. LPS-GNN: Deploying Graph Neural Networks on Graphs with 100-Billion Edges. arXiv preprint arXiv:2507.14570 (2025)
arXiv 2025
-
[15]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query- focused summarization. arXiv preprint arXiv:2404.16130 (2024)
Pith/arXiv arXiv 2024
-
[16]
R. Fan, K. Chang, C. Hsieh, X. Wang, and C. Lin. 2008. LIBLINEAR: A Library for Large Linear Classification. Journal of Machine Learning Research (2008), 18711874
2008
-
[17]
Peng Fang, Arijit Khan, Siqiang Luo, Fang Wang, Dan Feng, Zhenli Li, Wei Yin, and Y uchao Cao. 2023. Distributed Graph Embedding with Information- Oriented Random Walks. Proceedings of the VLDB Endowment 16, 7 (2023), 1643–1656
2023
-
[18]
Peng Fang, Zhenli Li, Arijit Khan, Siqiang Luo, Fang Wang, Zhan Shi, and Dan Feng. 2025. Information-Oriented Random Walks and Pipeline Optimization for Distributed Graph Embedding. IEEE Transactions on Knowledge and Data Engineering 37, 1 (2025), 408–422
2025
-
[19]
Peng Fang, Siqiang Luo, Fang Wang, Bolong Zheng, Hong Jiang, Dan Feng, Hechang Pan, and Xingyu Wan. 2025. OMeGa: Boosting Large-Scale Graph Embeddings with Heterogeneous Memory Processing. In 2025 IEEE 41st Inter- national Conference on Data Engineering . 3369–3383
2025
-
[20]
Peng Fang, Fang Wang, Zhan Shi, Hong Jiang, Dan Feng, Xianghao Xu, and Wei Yin. 2022. How to Realize Efficient and Scalable Graph Embeddings via an Entropy-driven Mechanism. IEEE Transactions on Big Data (2022)
2022
-
[21]
Peng Fang, Fang Wang, Zhan Shi, Hong Jiang, Dan Feng, and Lei Y ang. 2021. HuGE: An entropy-driven approach to efficient and scalable graph embeddings. In IEEE 37th International Conference on Data Engineering. IEEE, 2045–2050
2021
-
[22]
Tong Geng, Ang Li, Runbin Shi, Chunshu Wu, Tianqi Wang, Y anfei Li, Pouya Haghi, Antonino Tumeo, Shuai Che, Steve Reinhardt, et al. 2020. AWB-GCN: A graph convolutional network accelerator with runtime workload rebalancing. In 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). 922–936
2020
-
[23]
Chenghua Gong, Y ao Cheng, Jianxiang Y u, Can Xu, Caihua Shan, Siqiang Luo, and Xiang Li. 2024. A survey on learning from graphs with heterophily: Recent advances and future directions. arXiv preprint arXiv:2401.09769 (2024)
arXiv 2024
-
[24]
Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . 855–864
2016
-
[25]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive Representa- tion Learning on Large Graphs. In Advances in Neural Information Processing Systems, V ol. 30
2017
-
[26]
Jiafeng Hu, Reynold Cheng, Zhipeng Huang, Yixang Fang, and Siqiang Luo
-
[27]
In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management
On embedding uncertain graphs. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management . 157–166. 15 Peng Fang, Arijit Khan, Ziqiang Wu, Zhenli Li, Yibo Zhou, Fang Wang, and Dan Feng
2017
-
[28]
Weihua Hu, Matthias Fey, Marinka Zitnik, Y uxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing sys- tems 33 (2020), 22118–22133
2020
-
[29]
Shihao Ji, Nadathur Satish, Sheng Li, and Pradeep K Dubey. 2019. Parallelizing word2vec in shared and distributed memory. IEEE Transactions on Parallel and Distributed Systems 30, 9 (2019), 2090–2100
2019
-
[30]
M. M. Keikha, M. Rahgozar, and M. Asadpour. 2018. Community Aware Ran- dom Walk for Network Embedding. Knowledge-Based Systems 148 (2018), 47– 54
2018
-
[31]
Thomas N Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In International Conference on Learning Repre- sentations
2017
-
[32]
Haewoon Kwak, Changhyun Lee, Hosung Park, and Sue Moon. 2010. What is Twitter, a social network or a news media?. In Proceedings of the 19th Interna- tional Conference on World Wide Web. 591–600
2010
-
[33]
Y unjae Lee, Jinha Chung, and Minsoo Rhu. 2022. Smartsage: training large-scale graph neural networks using in-storage processing architectures. In Proceedings of the 49th Annual International Symposium on Computer Architecture . 932– 945
2022
-
[34]
Adam Lerer, Ledell Wu, Jiajun Shen, Timothee Lacroix, Luca Wehrstedt, Abhi- jit Bose, and Alex Peysakhovich. 2019. Pytorch-biggraph: A large scale graph embedding system. In Proceedings of Machine Learning and Systems , V ol. 1. 120–131
2019
-
[35]
Jure Leskovec, Daniel Huttenlocher, and Jon Kleinberg. 2010. Predicting pos- itive and negative links in online social networks. In Proceedings of the 19th International Conference on World Wide Web. 641–650
2010
-
[36]
Y ongkun Li, Zhiyong Wu, Shuai Lin, Hong Xie, Min Lv, Yinlong Xu, and John CS Lui. 2019. Walking with perception: Efficient random walk sampling via common neighbor awareness. In 2019 IEEE 35th International Conference on Data Engineering . IEEE, 962–973
2019
-
[37]
Zhiyuan Li, Xun Jian, Y ue Wang, Yingxia Shao, and Lei Chen. 2024. Daha: Ac- celerating gnn training with data and hardware aware execution planning. Pro- ceedings of the VLDB Endowment 17, 6 (2024), 1364–1376
2024
-
[38]
Ningyi Liao, Dingheng Mo, Siqiang Luo, Xiang Li, and Pengcheng Yin. 2022. SCARA: scalable graph neural networks with feature-oriented optimization. arXiv preprint arXiv:2207.09179 (2022)
arXiv 2022
-
[39]
Dongkyun Lim and John Kim. 2025. TidalMesh: Topology-Driven AllReduce Collective Communication for Mesh Topology. In 2025 IEEE International Sym- posium on High Performance Computer Architecture. IEEE, 1526–1540
2025
-
[40]
Tianfeng Liu, Y angrui Chen, Dan Li, Chuan Wu, Yibo Zhu, Jun He, Y anghua Peng, Hongzheng Chen, Hongzhi Chen, and Chuanxiong Guo. 2023. BGL: GPU- Efficient GNN training by optimizing graph data I/O and preprocessing. In 20th USENIX Symposium on Networked Systems Design and Implementation . 103– 118
2023
-
[41]
Linhao Luo, Zicheng Zhao, Gholamreza Haffari, Dinh Phung, Chen Gong, and Shirui Pan. 2025. GFM-RAG: graph foundation model for retrieval augmented generation. arXiv preprint arXiv:2502.01113 (2025)
arXiv 2025
-
[42]
Siqiang Luo, Zichen Zhu, Xiaokui Xiao, Yin Y ang, Chunbo Li, and Ben Kao
-
[43]
In International Conference on Extending Database Technology
Multi-Task Processing in V ertex-Centric Graph Systems: Evaluations and Insights. In International Conference on Extending Database Technology . 247– 259
-
[44]
Miller McPherson, Lynn Smith-Lovin, and James M Cook. 2001. Birds of a feather: Homophily in social networks. Annual review of sociology 27, 1 (2001), 415–444
2001
-
[45]
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. In International Conference on Learning Representations
2013
-
[46]
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. Advances in Neural Information Processing Systems 26 (2013)
2013
-
[47]
Jeongmin Brian Park, Vikram Sharma Mailthody, Zaid Qureshi, and Wen-mei Hwu. 2024. Accelerating Sampling and Aggregation Operations in GNN Frame- works with GPU Initiated Direct Storage Accesses. Proceedings of the VLDB Endowment 17, 6 (2024), 1227–1240
2024
-
[48]
Y eonhong Park, Sunhong Min, and Jae W Lee. 2022. Ginex: SSD-Enabled Billion-Scale Graph Neural Network Training on a Single Machine via Prov- ably Optimal in-Memory Caching. Proceedings of the VLDB Endowment 15, 11 (2022), 26262639
2022
-
[49]
Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . 701–710
2014
-
[50]
Oleg Platonov, Denis Kuznedelev, Artem Babenko, and Liudmila Prokhorenkova
-
[51]
Advances in Neural Information Processing Systems 36 (2023), 523–548
Characterizing graph datasets for node classification: Homophily- heterophily dichotomy and beyond. Advances in Neural Information Processing Systems 36 (2023), 523–548
2023
-
[52]
Oleg Platonov, Denis Kuznedelev, Michael Diskin, Artem Babenko, and Liud- mila Prokhorenkova. 2023. A Critical Look at the Evaluation of GNNs under Heterophily: Are We Really Making Progress?. In International Conference on Learning Representations
2023
-
[53]
Linshan Qiu, Lu Chen, Hailiang Jie, Xiangyu Ke, Y unjun Gao, Y ang Liu, and Zetao Zhang. 2024. GPU-Accelerated Batch-Dynamic Subgraph Matching. In 2024 IEEE 40th International Conference on Data Engineering (ICDE) . IEEE, 3204–3216
2024
-
[54]
Alexander Renz-Wieland, Rainer Gemulla, Zoi Kaoudi, and V olker Markl. 2022. NuPS: A Parameter Server for Machine Learning with Non-Uniform Parameter Access. In Proceedings of the 2022 International Conference on Management of Data. 481–495
2022
-
[55]
Andrea Rossi, Denilson Barbosa, Donatella Firmani, Antonio Matinata, and Paolo Merialdo. 2021. Knowledge graph embedding for link prediction: A com- parative analysis. ACM Transactions on Knowledge Discovery from Data 15, 2 (2021), 1–49
2021
-
[56]
Guangming Sheng, Junwei Su, Chao Huang, and Chuan Wu. 2024. Mspipe: Efficient temporal gnn training via staleness-aware pipeline. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 2651–2662
2024
-
[57]
Jaeyong Song, Hongsun Jang, Hunseong Lim, Jaewon Jung, Y oungsok Kim, and Jinho Lee. 2024. GraNNDis: Fast distributed graph neural network training framework for multi-server clusters. In Proceedings of the 2024 International Conference on Parallel Architectures and Compilation Techniques. 91–107
2024
-
[58]
Dahai Tang, Jiali Wang, Rong Chen, Lei Wang, Wenyuan Y u, Jingren Zhou, and Kenli Li. 2024. Xgnn: Boosting multi-gpu gnn training via global gnn memory store. Proceedings of the VLDB Endowment 17, 5 (2024), 1105–1118
2024
-
[59]
Lei Tang and Huan Liu. 2009. Scalable learning of collective behavior based on sparse social dimensions. In Proceedings of the 18th ACM Conference on Information and Knowledge Management . 1107–1116
2009
-
[60]
Anton Tsitsulin, Davide Mottin, Panagiotis Karras, and Emmanuel Müller. 2018. V erse: V ersatile graph embeddings from similarity measures. In Proceedings of the 2018 World Wide Web conference. 539–548
2018
-
[61]
Ke Tu, Peng Cui, Xiao Wang, Philip S Y u, and Wenwu Zhu. 2018. Deep re- cursive network embedding with regular equivalence. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Min- ing. 2357–2366
2018
-
[62]
Petar V eliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Y oshua Bengio. 2018. Graph Attention Networks. In International Con- ference on Learning Representations
2018
-
[63]
Roger Waleffe, Jason Mohoney, Theodoros Rekatsinas, and Shivaram V enkatara- man. 2023. MariusGNN: Resource-Efficient Out-of-Core Training of Graph Neu- ral Networks. In Proceedings of the 18th European Conference on Computer Systems (Rome, Italy). 144161
2023
-
[64]
Wolfe, Anastasios Kyrillidis, Nam Sung Kim, and Yingyan Lin
Cheng Wan, Y oujie Li, Cameron R. Wolfe, Anastasios Kyrillidis, Nam Sung Kim, and Yingyan Lin. 2022. PipeGCN: Efficient Full-Graph Training of Graph Con- volutional Networks with Pipelined Feature Communication. In International Conference on Learning Representations
2022
-
[65]
Daixin Wang, Peng Cui, and Wenwu Zhu. 2016. Structural deep network em- bedding. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining . 1225–1234
2016
-
[66]
Hongwei Wang, Jia Wang, Jialin Wang, Miao Zhao, Weinan Zhang, Fuzheng Zhang, Xing Xie, and Minyi Guo. 2018. GraphGAN: Graph Representation Learning With Generative Adversarial Nets. In Proceedings of the AAAI Confer- ence on Artificial Intelligence , V ol. 32
2018
-
[67]
Minjie Wang, Da Zheng, Zihao Y e, Quan Gan, Mufei Li, Xiang Song, Jinjing Zhou, Chao Ma, Lingfan Y u, Y u Gai, et al. 2019. Deep graph library: A graph- centric, highly-performant package for graph neural networks. arXiv preprint arXiv:1909.01315 (2019)
Pith/arXiv arXiv 2019
-
[68]
Qiange Wang, Y anfeng Zhang, Hao Wang, Chaoyi Chen, Xiaodong Zhang, and Ge Y u. 2022. Neutronstar: Distributed GNN Training with Hybrid Dependency Management. In Proceedings of the 2022 International Conference on Manage- ment of Data. 1301–1315
2022
-
[69]
Xiao Wang, Deyu Bo, Chuan Shi, Shaohua Fan, Y anfang Y e, and Philip S Y u
-
[70]
IEEE Transactions on Big Data 9, 2 (2022), 415–436
A survey on heterogeneous graph embedding: methods, techniques, appli- cations and sources. IEEE Transactions on Big Data 9, 2 (2022), 415–436
2022
-
[71]
Xuhong Wang, Ding Lyu, Mengjian Li, Y ang Xia, Qi Y ang, Xinwen Wang, Xin- guang Wang, Ping Cui, Y upu Y ang, Bowen Sun, et al. 2021. Apan: Asynchronous propagation attention network for real-time temporal graph embedding. In Pro- ceedings of the 2021 International Conference on Management of Data . 2628– 2638
2021
-
[72]
Y uke Wang, Boyuan Feng, Zheng Wang, Tong Geng, Kevin Barker, Ang Li, and Y ufei Ding. 2023. MGG: Accelerating graph neural networks with Fine-Grained Intra-Kernel Communication-Computation pipelining on Multi-GPU platforms. In 17th USENIX Symposium on Operating Systems Design and Implementation . 779–795
2023
-
[73]
Y uyue Wang, Xiurui Pan, Y uda An, Jie Zhang, and Glenn Reinman. 2024. BeaconGNN: Large-Scale GNN Acceleration with Out-of-Order Streaming In- Storage Computing. In IEEE International Symposium on High-Performance Computer Architecture. IEEE, 330–344. 16 FeLoG: Scalable and Efficient Distributed Graph Embedding with Feedback Loop Mechanism
2024
-
[74]
Zesong Wang, Peng Fang, Fang Wang, Hong Jiang, Yimin Lu, Zhan Shi, and Dan Feng. 2025. SpiderCache: Semantic-Aware Caching Strategy for DNN Train- ing. In Proceedings of the 54th International Conference on Parallel Processing (ICPP’25). 320330
2025
-
[75]
Brian J Worton. 1989. Kernel methods for estimating the utilization distribution in home-range studies. Ecology 70, 1 (1989), 164–168
1989
-
[76]
Qitian Wu, Wentao Zhao, Zenan Li, David P Wipf, and Junchi Y an. 2022. Node- former: A scalable graph structure learning transformer for node classification. Advances in Neural Information Processing Systems 35 (2022), 27387–27401
2022
-
[77]
Yidi Wu, Kaihao Ma, Zhenkun Cai, Tatiana Jin, Boyang Li, Chenguang Zheng, James Cheng, and Fan Y u. 2021. Seastar: V ertex-centric programming for graph neural networks. In Proceedings of the 16th European Conference on Computer Systems. 359–375
2021
-
[78]
Jaewon Y ang and Jure Leskovec. 2012. Defining and evaluating network com- munities based on ground-truth. In Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics . 1–8
2012
-
[79]
Renchi Y ang, Jieming Shi, Xiaokui Xiao, Yin Y ang, and Sourav S Bhowmick
-
[80]
Prococeding of VLDB Endowment 13, 5 (2020), 670– 683
Homogeneous Network Embedding for Massive Graphs via Reweighted Personalized PageRank. Prococeding of VLDB Endowment 13, 5 (2020), 670– 683
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.