Geometry-Aware Online Scheduling for LLM Serving: From Theoretical Bound to System Practice
Pith reviewed 2026-06-26 11:15 UTC · model grok-4.3
The pith
Scheduling LLM requests by smallest KV-cache volume growth improves the worst-case competitive ratio from 48 to 3.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that modeling KV-cache expansion as a two-dimensional spatio-temporal geometric volume makes the Smallest Volume First ordering optimal in the sense that its worst-case competitive ratio is at most 3 in the high-concurrency regime, a sharpening of the previous best bound of 48; the proof is supplied by a novel volume-certificate technique, and the result extends to a complete taxonomy of the algorithm family under varying traffic and information assumptions.
What carries the argument
The Smallest Volume First (SVF) algorithm, which at each decision point selects the pending request whose projected KV-cache memory volume is smallest.
If this is right
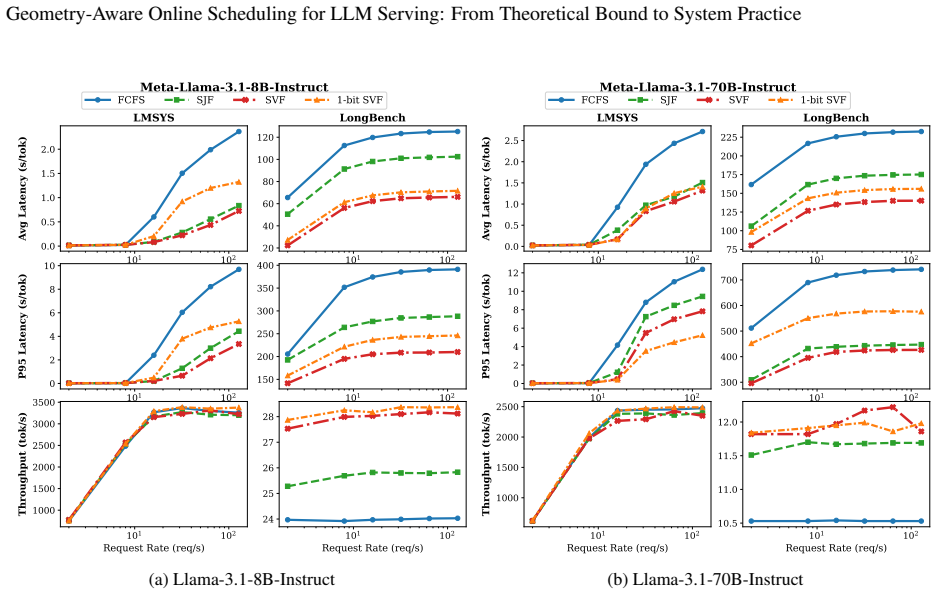
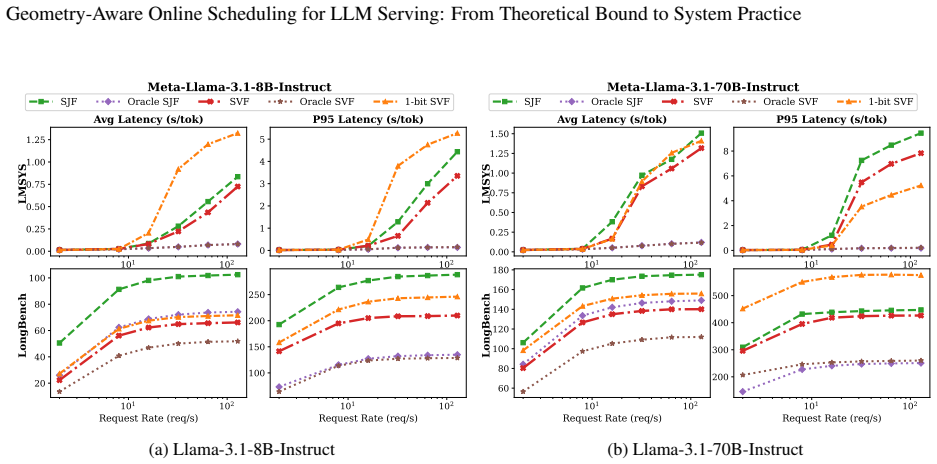
- SVF produces lower average and tail latency than time-centric baselines on Llama-3.1 models.
- The one-bit SVF variant matches the performance of full SVF while requiring only a single bit of per-request information.
- The algorithm integrates directly as a plug-and-play scheduler inside vLLM without altering the rest of the engine.
- A complete theoretical taxonomy classifies the competitive ratios of SVF and its variants across different traffic scenarios and degrees of information availability.
Where Pith is reading between the lines
- If the volume metric remains predictive under request mixing, the same scheduler could be applied without modification to serving multiple model sizes or architectures on one GPU.
- A direct measurement of realized competitive ratio on production traces would indicate whether the bound of 3 is tight or can be tightened further by refined volume estimators.
- Extending the geometric model to account for cache eviction or quantization effects would test whether the same proof technique continues to deliver constant-factor guarantees.
Load-bearing premise
That the memory footprint of an LLM request grows in a way that is accurately summarized by a single scalar volume metric derived from a two-dimensional geometric model.
What would settle it
A high-concurrency request trace for which the total latency or makespan produced by SVF is more than three times larger than the latency of the optimal offline schedule computed from the same trace.
Figures

read the original abstract
The explosive demand for interactive Large Language Model serving has highlighted the management of the Key-Value cache's dynamic memory footprint as a critical area for performance optimization in inference engines. Modern inference systems overwhelmingly rely on time-centric scheduling heuristics, such as Shortest Job First. However, their theoretical optimality is rooted in traditional schedule modeling, failing to capture the highly dynamic, 2D spatio-temporal geometric growth specific to LLM inference mechanisms. To resolve this, we propose the geometry-aware online scheduling by introducing the Smallest Volume First (SVF) algorithm and its highly efficient variant, 1-bit SVF. Theoretically, we provide a rigorous mathematical foundation for our approach. Via a novel volume-certificate proof, we sharpen SVF's worst-case competitive ratio from the prior best of 48 towards \textbf{3} in the high-concurrency regime of LLM serving. Building upon this core breakthrough, we complete a comprehensive theoretical taxonomy analyzing our algorithms across different traffic scenarios and information availability. Practically, we seamlessly integrate our approach as a plug-and-play layer in vLLM. Extensive evaluations on Llama-3.1 models demonstrate comprehensive performance gains: SVF delivers strong reductions in both average and tail latency, while 1-bit SVF, with merely a single bit information, achieves competitive throughput and latency. This work establishes a theoretically sound and empirically proven approach for resolving memory-constrained scheduling in modern LLM deployments. To facilitate future research, our code is available at https://github.com/Aurora-Kl/Geometry-Aware-Online-Scheduling.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Smallest Volume First (SVF) and 1-bit SVF as geometry-aware online schedulers for LLM inference, motivated by a 2D spatio-temporal geometric model of KV-cache growth. It claims a novel volume-certificate proof that tightens the worst-case competitive ratio to 3 (from prior 48) in high-concurrency regimes, supplies a theoretical taxonomy across traffic and information settings, and reports latency/throughput gains when plugged into vLLM on Llama-3.1 models.
Significance. If the geometric model is faithful and the proof is correct, the work would supply the first non-trivial competitive-ratio improvement for memory-constrained LLM scheduling and a practical drop-in replacement for time-centric heuristics such as SJF. The open-source integration and code release would further strengthen its impact.
major comments (2)
- [Abstract] Abstract and introduction: the central claim of a volume-certificate proof sharpening the competitive ratio to 3 is asserted without any model equations, derivation steps, or statement of the 2D geometric growth assumptions; this prevents verification of whether the ratio is independent of input parameters or reduces by construction.
- [Abstract] No quantitative experimental numbers, tables, or figures are referenced in the abstract or summary; the claimed reductions in average and tail latency therefore cannot be assessed for effect size or statistical significance.
minor comments (1)
- The abstract states that code is available at a GitHub link; confirm that the repository contains the exact experimental configurations and the proof scripts used to obtain the ratio-3 bound.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will make targeted revisions to the abstract and introduction to improve verifiability while preserving the manuscript's focus.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the central claim of a volume-certificate proof sharpening the competitive ratio to 3 is asserted without any model equations, derivation steps, or statement of the 2D geometric growth assumptions; this prevents verification of whether the ratio is independent of input parameters or reduces by construction.
Authors: The full manuscript presents the 2D spatio-temporal geometric model of KV-cache growth in Section 3 and the volume-certificate proof in Section 4, establishing that the competitive ratio of 3 holds in the high-concurrency regime and is independent of specific input parameters under the model's assumptions (rather than reducing by construction). To address the concern about accessibility in the abstract and introduction, we will revise both sections to include a concise statement of the key geometric assumptions and a high-level outline of the proof technique. revision: yes
-
Referee: [Abstract] No quantitative experimental numbers, tables, or figures are referenced in the abstract or summary; the claimed reductions in average and tail latency therefore cannot be assessed for effect size or statistical significance.
Authors: We agree that referencing specific quantitative results would allow better assessment of effect sizes. In the revised version, we will update the abstract to include key experimental outcomes from the vLLM integration on Llama-3.1 models (e.g., observed reductions in average and tail latency) and explicitly reference the relevant tables and figures that report the full statistical details. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claim is a novel volume-certificate proof deriving an improved worst-case competitive ratio of 3 for the SVF algorithm under an explicit 2D spatio-temporal KV-cache model. No equations, fitted parameters, or self-citations are shown that would reduce this ratio to a quantity defined by the input data or prior results by construction. The modeling assumption is stated upfront as the reason time-centric bounds fail, and the proof technique is presented as independent mathematical content. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The dynamic memory footprint of LLM KV cache exhibits highly dynamic 2D spatio-temporal geometric growth.
Reference graph
Works this paper leans on
-
[1]
Llm inference serving: Survey of recent advances and opportunities
Baolin Li, Yankai Jiang, Vijay Gadepally, and Devesh Tiwari. Llm inference serving: Survey of recent advances and opportunities. In2024 IEEE High Performance Extreme Computing Conference (HPEC), pages 1–8. IEEE, 2024
2024
-
[2]
Taming the titans: A survey of efficient llm inference serving
Ranran Zhen, Juntao Li, Yixin Ji, Zhenlin Yang, Tong Liu, Qingrong Xia, Xinyu Duan, Zhefeng Wang, Baoxing Huai, and Min Zhang. Taming the titans: A survey of efficient llm inference serving. InProceedings of the 18th International Natural Language Generation Conference, pages 522–541, 2025
2025
-
[3]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[4]
When search engine services meet large language models: visions and challenges.IEEE Transactions on Services Computing, 17(6):4558–4577, 2024
Haoyi Xiong, Jiang Bian, Yuchen Li, Xuhong Li, Mengnan Du, Shuaiqiang Wang, Dawei Yin, and Sumi Helal. When search engine services meet large language models: visions and challenges.IEEE Transactions on Services Computing, 17(6):4558–4577, 2024
2024
-
[5]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[6]
Ai-assisted code authoring at scale: Fine-tuning, deploying, and mixed methods evaluation.Proceedings of the ACM on Software Engineering, 1(FSE):1066–1085, 2024
Vijayaraghavan Murali, Chandra Maddila, Imad Ahmad, Michael Bolin, Daniel Cheng, Negar Ghorbani, Renuka Fernandez, Nachiappan Nagappan, and Peter C Rigby. Ai-assisted code authoring at scale: Fine-tuning, deploying, and mixed methods evaluation.Proceedings of the ACM on Software Engineering, 1(FSE):1066–1085, 2024
2024
-
[7]
Orca: A distributed serving system for {Transformer-Based} generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX symposium on operating systems design and implementation (OSDI 22), pages 521–538, 2022
2022
-
[8]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[9]
Online scheduling for llm inference with kv cache constraints.arXiv preprint arXiv:2502.07115, 2025
Patrick Jaillet, Jiashuo Jiang, Konstantina Mellou, Marco Molinaro, Chara Podimata, and Zijie Zhou. Online scheduling for llm inference with kv cache constraints.arXiv preprint arXiv:2502.07115, 2025
arXiv 2025
-
[10]
Llm serving optimization with variable prefill and decode lengths
Meixuan Wang, Yinyu Ye, and Zijie Zhou. Llm serving optimization with variable prefill and decode lengths. arXiv preprint arXiv:2508.06133, 2025
arXiv 2025
-
[11]
Position: Llm serving needs mathematical optimization and algorithmic foundations, not just heuristics, 2026
Zijie Zhou. Position: Llm serving needs mathematical optimization and algorithmic foundations, not just heuristics, 2026
2026
-
[12]
Yuxing Xiang, Xue Li, Kun Qian, Wenyuan Yu, Ennan Zhai, and Xin Jin. Servegen: Workload characterization and generation of large language model serving in production.arXiv preprint arXiv:2505.09999, 2025
Pith/arXiv arXiv 2025
-
[13]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[14]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
Pith/arXiv arXiv 1909
-
[15]
P Xing, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric. P Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. Lmsys-chat-1m: A large-scale real-world llm conversation dataset, 2023
2023
-
[16]
Longbench: A bilingual, multitask benchmark for long context understanding, 2023
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding, 2023
2023
-
[17]
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbigniew T Kalbarczyk, Tamer Ba¸ sar, and Ravishankar K Iyer. Efficient interactive llm serving with proxy model-based sequence length prediction.arXiv preprint arXiv:2404.08509, 2024
arXiv 2024
-
[18]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019. 11 Geo...
2019
-
[19]
Iulia Turc, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Well-read students learn better: The impact of student initialization on knowledge distillation.CoRR, abs/1908.08962, 2019
arXiv 1908
-
[20]
Prompt-aware scheduling for low-latency llm serving.arXiv preprint arXiv:2510.03243, 2025
Yiheng Tao, Yihe Zhang, Matthew T Dearing, Xin Wang, Yuping Fan, and Zhiling Lan. Prompt-aware scheduling for low-latency llm serving.arXiv preprint arXiv:2510.03243, 2025
arXiv 2025
-
[21]
Efficient llm scheduling by learning to rank.Advances in Neural Information Processing Systems, 37:59006–59029, 2024
Yichao Fu, Siqi Zhu, Runlong Su, Aurick Qiao, Ion Stoica, and Hao Zhang. Efficient llm scheduling by learning to rank.Advances in Neural Information Processing Systems, 37:59006–59029, 2024
2024
-
[22]
Shinjuku: Preemptive scheduling for {µsecond-scale} tail latency
Kostis Kaffes, Timothy Chong, Jack Tigar Humphries, Adam Belay, David Mazières, and Christos Kozyrakis. Shinjuku: Preemptive scheduling for {µsecond-scale} tail latency. In16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), pages 345–360, 2019
2019
-
[23]
Fast distributed inference serving for large language models.arXiv preprint arXiv:2305.05920, 2023
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. Fast distributed inference serving for large language models.arXiv preprint arXiv:2305.05920, 2023
Pith/arXiv arXiv 2023
-
[24]
Yunho Jin, Chun-Feng Wu, David Brooks, and Gu-Yeon Wei.s3: Increasing gpu utilization during generative inference for higher throughput.Advances in Neural Information Processing Systems, 36:18015–18027, 2023
2023
-
[25]
Dynamollm: Designing llm inference clusters for performance and energy efficiency
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. Dynamollm: Designing llm inference clusters for performance and energy efficiency. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1348–1362. IEEE, 2025
2025
-
[26]
Response length perception and sequence scheduling: An llm-empowered llm inference pipeline.Advances in Neural Information Processing Systems, 36:65517–65530, 2023
Zangwei Zheng, Xiaozhe Ren, Fuzhao Xue, Yang Luo, Xin Jiang, and Yang You. Response length perception and sequence scheduling: An llm-empowered llm inference pipeline.Advances in Neural Information Processing Systems, 36:65517–65530, 2023
2023
-
[27]
Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Jiang Xu, Shuang Chen, Hao Feng, Chenxi Wang, Sa Wang, Yungang Bao, et al. Inference without interference: Disaggregate llm inference for mixed downstream workloads.arXiv preprint arXiv:2401.11181, 2024
arXiv 2024
-
[28]
Power-aware deep learning model serving with{µ-Serve}
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbigniew Kalbarczyk, Tamer Ba¸ sar, and Ravishankar K Iyer. Power-aware deep learning model serving with{µ-Serve}. In 2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 75–93, 2024
2024
-
[29]
Don’t stop me now: Embedding based scheduling for llms.arXiv preprint arXiv:2410.01035, 2024
Rana Shahout, Eran Malach, Chunwei Liu, Weifan Jiang, Minlan Yu, and Michael Mitzenmacher. Don’t stop me now: Embedding based scheduling for llms.arXiv preprint arXiv:2410.01035, 2024
arXiv 2024
-
[30]
Enabling efficient batch serving for lmaas via generation length prediction
Ke Cheng, Wen Hu, Zhi Wang, Peng Du, Jianguo Li, and Sheng Zhang. Enabling efficient batch serving for lmaas via generation length prediction. In2024 IEEE International Conference on Web Services (ICWS), pages 853–864. IEEE, 2024
2024
-
[31]
Huanyi Xie, Yubin Chen, Liangyu Wang, Lijie Hu, and Di Wang. Predicting llm output length via entropy-guided representations.arXiv preprint arXiv:2602.11812, 2026
arXiv 2026
-
[32]
Various optimizers for single-stage production
Wayne E Smith. Various optimizers for single-stage production. Technical report, 1955
1955
-
[33]
A proof of the optimality of the shortest remaining processing time discipline.Operations Research, 16(3):687–690, 1968
Linus Schrage. A proof of the optimality of the shortest remaining processing time discipline.Operations Research, 16(3):687–690, 1968
1968
-
[34]
Adaptively robust llm inference optimization under prediction uncertainty
Zixi Chen, Yinyu Ye, and Zijie Zhou. Adaptively robust llm inference optimization under prediction uncertainty. arXiv preprint arXiv:2508.14544, 2025
arXiv 2025
-
[35]
Ruicheng Ao, Gan Luo, David Simchi-Levi, and Xinshang Wang. Optimizing llm inference: Fluid-guided online scheduling with memory constraints.arXiv preprint arXiv:2504.11320, 2025
Pith/arXiv arXiv 2025
-
[36]
Qunyou Liu, Darong Huang, Marina Zapater, and David Atienza. Greenllm: Slo-aware dynamic frequency scaling for energy-efficient llm serving.arXiv preprint arXiv:2508.16449, 2025
arXiv 2025
-
[37]
Bowen Pang, Kai Li, and Feifan Wang. Optimizing llm inference throughput via memory-aware and sla-constrained dynamic batching.arXiv preprint arXiv:2503.05248, 2025. 12 Geometry-Aware Online Scheduling for LLM Serving: From Theoretical Bound to System Practice A Related Works LLM inference scheduling. Efficient serving of LLMs is pivotal for interactive a...
arXiv 2025
-
[38]
From the law of total expectation,p 1O1 +p 2O2 = 1 µ =⇒p 1O1 = 1 µ −p 2O2. Substituting this constraint: p1O2 1 +p 2O2 2 = ( 1 µ −p 2O2)2 p1 +p 2O2 2 = 1 µ2 − 2p2O2 µ +p 2 2O2 2 +p 1p2O2 2 p1 = 1 µ2 −p 2 2O2 µ −O 2 2 p1 (89) Because the long proxy is O2 =θ+ 1 µ, its internal term simplifies beautifully: 2O2 µ −O 2 2 = 1 µ2 −θ 2. Substituting this back: p1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.