How Does Research Evolve? Tracing Cross-Domain Trajectories in NLP, ML, and CV with Claim-Grounded Typed Citations
Pith reviewed 2026-06-26 11:00 UTC · model grok-4.3
The pith
A new corpus ties each citation to the specific claim sentence that motivates it, creating typed edges across NLP, ML, and vision research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
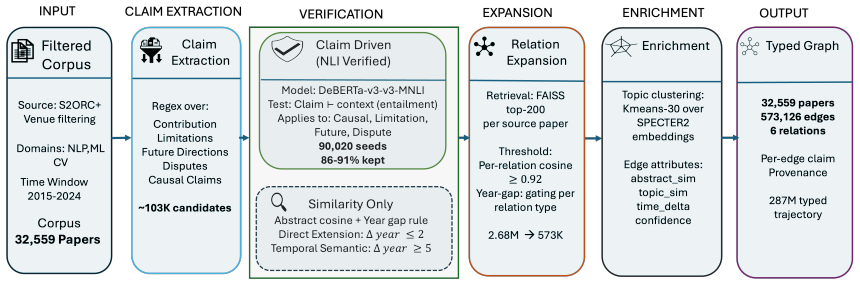
The central claim is that scientific progress can be tracked more precisely by replacing homogeneous citation edges with a claim-grounded typed graph: each of the 573,126 edges is anchored to a verified claim sentence and labeled with one of six relation types, enabling measurement of how ideas extend methods, address limitations, or realize future directions across NLP, ML, and vision.
What carries the argument
SciTraj corpus: a directed graph of 32,559 papers whose 573,126 edges are each linked to a claim sentence extracted from sections and typed by NLI entailment (four relations) or abstract-cosine and year-gap gating (two relations).
If this is right
- Typed citation flows reveal disciplinary siloing across NLP, ML, and vision.
- Topic emergence concentrates in vision and LLM-related work.
- 287 million typed trajectories of length at least three cover 72.8 percent of the papers.
- The corpus supplies a temporally split benchmark for predicting future typed links.
- A year-shuffle test isolates temporal ordering from content-year correlations.
Where Pith is reading between the lines
- The same claim-grounded typing method could be applied to citation graphs in other scientific domains to compare evolution patterns.
- Researchers could query the trajectories to locate papers that address limitations left open by earlier work in a different field.
- The link-prediction benchmark could be extended to test whether models can forecast which relation type will appear next between two topics.
Load-bearing premise
Section-based claim extraction combined with NLI verification and similarity gating produces typed edges that accurately capture the intended scientific relationships without substantial noise.
What would settle it
If a year-shuffle test on the typed link-prediction benchmark shows performance collapsing to random levels, the temporal structure claimed in the trajectories would be an artifact of year-correlated content rather than genuine evolution.
Figures
read the original abstract
How does research evolve, and what substrate would let us forecast where it goes next? Scientific progress is not simply a uniform accumulation of facts: ideas extend prior methods, address known limitations, realize proposed future directions, and sometimes dispute earlier claims. Existing citation graphs usually collapse these roles into a single homogeneous edge type, limiting how we can analyze scientific progress. We address this gap by proposing the SciTraj corpus, the first claim-grounded typed citation graph in which each edge is linked to the specific claim sentence that motivates it. Claim-bearing sentences are extracted from paper sections; four claim-driven relations are verified by NLI entailment against in-paper context, while two similarity-only relations are gated by abstract cosine and year-gap rules. SciTraj contains 32,559 papers from NLP, ML, and Vision (2015--2024), connected by 573,126 directed edges across six relation types, with NLI-verified claim seeds. Using SciTraj, we identify disciplinary siloing in typed citation flow and topic emergence concentrated in Vision and LLM-related work. The corpus also contains 287M typed trajectories of length $\geq 3$, covering 72.8% of papers, and supports a temporally split typed link-prediction benchmark. A year-shuffle falsifiability test separates temporal structure from year-correlated content, and a 3-annotator pilot reports $\kappa = 0.74$ with 79.9% precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
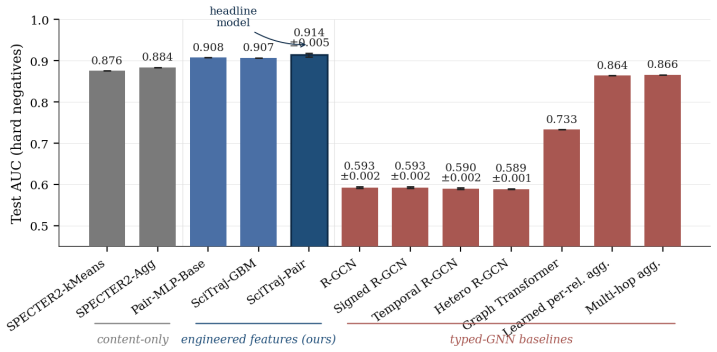
Summary. The manuscript proposes SciTraj, the first claim-grounded typed citation graph, containing 32,559 papers from NLP, ML, and Vision (2015–2024) linked by 573,126 directed edges across six relation types. Four relations are extracted from claim-bearing sentences and verified by NLI entailment; two are gated by abstract cosine similarity and year gap. The corpus supports analyses of disciplinary siloing and topic emergence, contains 287M typed trajectories of length ≥3, and includes a temporally split link-prediction benchmark plus a year-shuffle falsifiability test. A 3-annotator pilot reports κ=0.74 and 79.9% precision.
Significance. If the typed edges faithfully represent claim-driven relationships, SciTraj would constitute a valuable new resource for studying the evolution of scientific ideas beyond homogeneous citation graphs. The scale, inclusion of trajectories, temporally split benchmark, and year-shuffle test are concrete strengths that could enable downstream work on forecasting and cross-domain analysis.
major comments (2)
- [Abstract] Abstract: The claim that SciTraj is a 'claim-grounded typed citation graph' rests on NLI verification for only four of the six relations; the two similarity-gated relations are explicitly not claim-verified, yet are included without separate qualification, weakening the central construction claim.
- [Abstract] Abstract: The only reported quality evidence is a 3-annotator pilot (κ=0.74, 79.9% precision); no full validation metrics, error analysis stratified by relation type on the 573k edges, NLI model choice, threshold, or handling of negation/hedging in scientific text are provided, leaving the fidelity of the typed edges insufficiently supported for a corpus paper.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of SciTraj's potential value. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that SciTraj is a 'claim-grounded typed citation graph' rests on NLI verification for only four of the six relations; the two similarity-gated relations are explicitly not claim-verified, yet are included without separate qualification, weakening the central construction claim.
Authors: The manuscript already distinguishes the four NLI-verified claim-driven relations from the two similarity-gated relations in both the abstract and body text. To avoid any ambiguity in the central claim, we will revise the abstract to explicitly qualify the two similarity-only relations as not claim-verified by NLI. revision: yes
-
Referee: [Abstract] Abstract: The only reported quality evidence is a 3-annotator pilot (κ=0.74, 79.9% precision); no full validation metrics, error analysis stratified by relation type on the 573k edges, NLI model choice, threshold, or handling of negation/hedging in scientific text are provided, leaving the fidelity of the typed edges insufficiently supported for a corpus paper.
Authors: We agree that more detail on validation would improve the paper. In revision we will add the NLI model and threshold used, describe handling of negation/hedging, and provide a pilot-based error analysis stratified by relation type. Full annotation of the 573k edges is not feasible; we will explicitly note this limitation. This is a partial revision. revision: partial
Circularity Check
No significant circularity: dataset construction paper with independent pipeline
full rationale
The paper's central contribution is the construction and release of the SciTraj corpus via section-based claim extraction, NLI entailment for four relations, and cosine/year-gap gating for two others. No quantitative predictions, fitted parameters, or derivations are presented that reduce by construction to the paper's own inputs. The only internal validation is a small 3-annotator pilot (explicitly reported as such), which does not serve as a load-bearing self-citation or self-definition. The work is self-contained as a resource paper; external benchmarks or downstream use are not required for its claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language inference models can accurately determine whether a citation sentence entails or contradicts a specific claim sentence extracted from the cited paper
Reference graph
Works this paper leans on
-
[1]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin and Ming-Wei Chang and Kenton Lee and Kristina Toutanova , title =. Proceedings of NAACL-HLT , pages =. 2019 , publisher =. doi:10.18653/v1/N19-1423 , url =
-
[2]
Arman Cohan and Sergey Feldman and Iz Beltagy and Doug Downey and Daniel S. Weld , title =. Proceedings of ACL , pages =. 2020 , publisher =. doi:10.18653/v1/2020.acl-main.207 , url =
-
[3]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Scirepeval: A multi-format benchmark for scientific document representations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[4]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
S2ORC: The semantic scholar open research corpus , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[5]
Advances in Neural Information Processing Systems (
Weihua Hu and Matthias Fey and Marinka Zitnik and Yuxiao Dong and Hongyu Ren and Bowen Liu and Michele Catasta and Jure Leskovec , title =. Advances in Neural Information Processing Systems (. 2020 , url =
2020
-
[6]
Kipf and Max Welling , title =
Thomas N. Kipf and Max Welling , title =. International Conference on Learning Representations (. 2017 , url =
2017
-
[7]
arXiv preprint arXiv:1710.10903 , year=
Graph attention networks , author=. arXiv preprint arXiv:1710.10903 , year=
-
[8]
European semantic web conference , pages=
Modeling relational data with graph convolutional networks , author=. European semantic web conference , pages=. 2018 , organization=
2018
-
[9]
Yu , title =
Xiao Wang and Houye Ji and Chuan Shi and Bai Wang and Yanfang Ye and Peng Cui and Philip S. Yu , title =. The World Wide Web Conference (WWW) , pages =. 2019 , publisher =
2019
-
[10]
Proceedings of the web conference 2020 , pages=
Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding , author=. Proceedings of the web conference 2020 , pages=
2020
-
[11]
Proceedings of NAACL-HLT , pages =
Chandra Bhagavatula and Sergey Feldman and Russell Power and Waleed Ammar , title =. Proceedings of NAACL-HLT , pages =. 2018 , publisher =. doi:10.18653/v1/N18-1022 , url =
-
[12]
Improved Local Citation Recommendation Based on Context Enhanced with Global Information
Medi \'c , Zoran and Snajder, Jan. Improved Local Citation Recommendation Based on Context Enhanced with Global Information. Proceedings of the First Workshop on Scholarly Document Processing. 2020. doi:10.18653/v1/2020.sdp-1.11
-
[13]
Translating Embeddings for Modeling Multi-relational Data , booktitle =
Antoine Bordes and Nicolas Usunier and Alberto Garc. Translating Embeddings for Modeling Multi-relational Data , booktitle =. 2013 , url =
2013
-
[14]
Complex Embeddings for Simple Link Prediction , booktitle =
Th. Complex Embeddings for Simple Link Prediction , booktitle =. 2016 , url =
2016
-
[15]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Fact or fiction: Verifying scientific claims , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[16]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages=
FEVER: a large-scale dataset for fact extraction and VERification , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages=
2018
-
[17]
Journal of machine Learning research , volume=
Latent dirichlet allocation , author=. Journal of machine Learning research , volume=
-
[18]
Proceedings of the 23rd international conference on Machine learning , pages=
Dynamic topic models , author=. Proceedings of the 23rd international conference on Machine learning , pages=
-
[19]
Social networks , volume=
Friends and neighbors on the web , author=. Social networks , volume=. 2003 , publisher=
2003
-
[20]
Journal of computational and applied mathematics , volume=
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis , author=. Journal of computational and applied mathematics , volume=. 1987 , publisher=
1987
-
[21]
Communications in Statistics-theory and Methods , volume=
A dendrite method for cluster analysis , author=. Communications in Statistics-theory and Methods , volume=. 1974 , publisher=
1974
-
[22]
Advances in neural information processing systems , volume=
Lightgbm: A highly efficient gradient boosting decision tree , author=. Advances in neural information processing systems , volume=
-
[23]
Political Analysis , volume=
Less annotating, more classifying: Addressing the data scarcity issue of supervised machine learning with deep transfer learning and bert-nli , author=. Political Analysis , volume=. 2024 , publisher=
2024
-
[24]
biometrics , pages=
The measurement of observer agreement for categorical data , author=. biometrics , pages=. 1977 , publisher=
1977
-
[25]
Structural Scaffolds for Citation Intent Classification in Scientific Publications
Cohan, Arman and Ammar, Waleed and van Zuylen, Madeleine and Cady, Field. Structural Scaffolds for Citation Intent Classification in Scientific Publications. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[26]
, author=
The ACL Anthology Reference Corpus: A Reference Dataset for Bibliographic Research in Computational Linguistics. , author=. LREC , year=
-
[27]
Transactions of the Association for Computational Linguistics , volume=
Measuring the evolution of a scientific field through citation frames , author=. Transactions of the Association for Computational Linguistics , volume=
-
[28]
S ci F act-Open: Towards open-domain scientific claim verification
Wadden, David and Lo, Kyle and Kuehl, Bailey and Cohan, Arman and Beltagy, Iz and Wang, Lucy Lu and Hajishirzi, Hannaneh. S ci F act-Open: Towards open-domain scientific claim verification. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.347
-
[29]
Transactions of the Association for Computational Linguistics , volume =
Measuring the Evolution of a Scientific Field through Citation Frames , author =. Transactions of the Association for Computational Linguistics , volume =
-
[30]
Structural scaffolds for citation intent classification in scientific publications , author=. Proceedings of the 2019 conference of the North American chapter of the Association for Computational Linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[31]
Quantitative science studies , volume=
A meta-analysis of semantic classification of citations , author=. Quantitative science studies , volume=. 2021 , publisher=
2021
-
[32]
Berrebbi, Dan and Huynh, Nicolas and Balalau, Oana , booktitle =
-
[33]
Companion proceedings of the web conference 2022 , pages=
Graphcite: Citation intent classification in scientific publications via graph embeddings , author=. Companion proceedings of the web conference 2022 , pages=
2022
-
[34]
Paolini, Lorenzo and Vahdati, Sahar and Di Iorio, Angelo and Wardenga, Robert and Heibi, Ivan and Peroni, Silvio , journal =
-
[35]
Scientometrics , pages=
CiteFusion: an ensemble framework for citation intent classification harnessing dual-model binary couples and SHAP analyses , author=. Scientometrics , pages=. 2025 , publisher=
2025
-
[36]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Citation amnesia: on the recency bias of NLP and other academic fields , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[37]
and Ying, Rex and Leskovec, Jure , title =
Hamilton, William L. and Ying, Rex and Leskovec, Jure , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[38]
arXiv preprint arXiv:2111.09543 , year=
Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing , author=. arXiv preprint arXiv:2111.09543 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.