Deep Learning-Based Sign Language Recognition from Videos and Cross-Lingual Translation to Indian Vernaculars
Pith reviewed 2026-06-26 10:52 UTC · model grok-4.3
The pith
A fine-tuned VideoMAE model classifies 13 Indian sign language classes from video clips at 78 percent validation accuracy, then translates the English labels to Hindi, Telugu and Bengali.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a two-stage deep learning pipeline consisting of a fine-tuned VideoMAE video transformer for classifying 16-frame sign language clips into English words, followed by NLLB-200 translation into Hindi, Telugu and Bengali, produces usable output on a 13-class subset of the AI4Bharat Indian Sign Language corpus.
What carries the argument
Fine-tuned VideoMAE video transformer that processes uniformly sampled 16-frame clips at 224 by 224 resolution for English word classification, combined with the NLLB-200 multilingual translation model.
If this is right
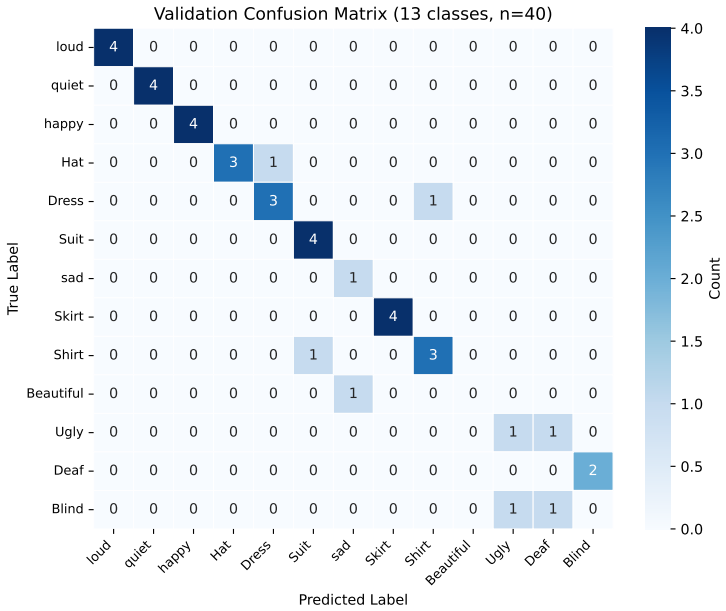
- The per-class confusion matrix identifies dominant failure modes in confusable adjective pairs such as ugly, deaf, blind, hat and dress.
- A Streamlit-based inference demo accepts user-uploaded videos and returns the predicted English label with Hindi, Telugu and Bengali translations.
- Released code supports reproducibility of the 80-20 split training run that reaches the reported accuracies after 15 epochs.
- Expansion to sentence-level generation and a larger vocabulary is identified as the next development step.
Where Pith is reading between the lines
- The pipeline could be tested on continuous signing sequences to determine whether isolated-word classification extends to full-sentence output.
- Performance gaps between training and validation accuracy suggest that adding signer diversity in the training data would be a direct next measurement.
- The single-word translation step may be replaced or augmented with context-aware models to reduce ambiguity in adjective and noun labels.
Load-bearing premise
The 13-class subset of 197 clips drawn from limited signers is assumed to be sufficient for training a model that generalizes beyond this specific dataset and single-signer style.
What would settle it
Running the trained model on a new multi-signer test set containing at least 50 additional classes and measuring whether validation accuracy stays above 70 percent would directly test the generalization premise.
Figures

read the original abstract
Sign language is a primary mode of communication for the global deaf and hard-of-hearing community, yet automated tools that recognize sign gestures from video and translate them into natural language text remain limited, particularly for low-resource Indian languages. We present a two-stage deep learning pipeline that (i) classifies short sign language video clips into English word labels using a fine-tuned VideoMAE video transformer, and (ii) translates the predicted English label into Hindi, Telugu, and Bengali using Meta AI's No Language Left Behind (NLLB-200) multilingual translation model. The classification model is fine-tuned on a 13-class subset of the AI4Bharat Indian Sign Language video corpus from IIT Madras, processing 16-frame clips sampled uniformly from each video at 224 x 224 resolution. Under a small-scale academic setting (13 classes, 197 clips, 80-20 split), the fine-tuned model reaches 99% training accuracy and 78% validation accuracy after 15 epochs. We provide a per-class breakdown via a confusion matrix and classification report, identify the dominant failure modes (confusable adjective pairs such as ugly, deaf, blind, hat, and dress), and describe a Streamlit-based inference demo that takes a user-uploaded video and returns the predicted English label alongside its Hindi, Telugu, and Bengali translations. We discuss the scope, limitations (small label set, isolated-word rather than continuous signing, single-signer style sensitivity, ambiguity of single-word machine translation), and directions for future work, including expanding to sentence-level generation and a larger vocabulary. Code is released to support reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a two-stage pipeline that fine-tunes VideoMAE on 16-frame 224x224 clips from a 13-class, 197-clip subset of the AI4Bharat Indian Sign Language corpus (80-20 split) to reach 99% training and 78% validation accuracy, then applies NLLB-200 to translate the English labels into Hindi, Telugu, and Bengali; it includes a confusion matrix, failure-mode analysis, a Streamlit demo, and explicit discussion of scope and limitations.
Significance. If the reported numbers hold, the work supplies a fully reproducible small-scale demonstration of video-transformer fine-tuning for low-resource sign-language recognition together with multilingual translation, accompanied by released code; its value lies in providing an honest, documented starting point rather than overstated generalization claims.
major comments (2)
- [Experimental evaluation] Experimental evaluation: the 78% validation accuracy is measured on an 80-20 split yielding only ~39 clips; the manuscript provides neither k-fold cross-validation, multiple random splits, nor error bars, which directly limits the reliability that can be attached to the central performance numbers.
- [Experimental evaluation] Experimental evaluation: no baseline classifiers (e.g., 3D-CNN, I3D, or non-transformer video models) are reported, so the contribution of the VideoMAE fine-tuning step to the observed 78% accuracy cannot be isolated from simpler alternatives.
minor comments (2)
- The per-class sample counts underlying the confusion matrix and classification report are not stated; adding them would clarify whether the dominant confusions (ugly/deaf/blind etc.) arise from class imbalance.
- The description of uniform 16-frame sampling at 224x224 resolution would benefit from an explicit statement of the temporal sampling strategy (e.g., start frame selection or stride) to ensure exact reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary and for identifying concrete ways to strengthen the experimental reporting. We respond to each major comment below.
read point-by-point responses
-
Referee: Experimental evaluation: the 78% validation accuracy is measured on an 80-20 split yielding only ~39 clips; the manuscript provides neither k-fold cross-validation, multiple random splits, nor error bars, which directly limits the reliability that can be attached to the central performance numbers.
Authors: We agree that the small validation set (~39 clips) limits statistical reliability. The single 80-20 split was chosen to maximize training data in this low-resource regime. In the revision we will (i) add an explicit paragraph in the Experimental Setup section stating this limitation and recommending k-fold or repeated splits for future larger datasets, and (ii) rerun training with three random seeds and report mean validation accuracy plus standard deviation. revision: yes
-
Referee: Experimental evaluation: no baseline classifiers (e.g., 3D-CNN, I3D, or non-transformer video models) are reported, so the contribution of the VideoMAE fine-tuning step to the observed 78% accuracy cannot be isolated from simpler alternatives.
Authors: We acknowledge the absence of baselines. However, the manuscript is explicitly positioned as a small-scale, fully reproducible starting-point demonstration of the VideoMAE+NLLB pipeline rather than a comparative benchmark. Adding and training additional models (I3D, 3D-CNN, etc.) would materially change the scope and computational requirements. In the revision we will expand the Limitations section to state clearly that no baselines are included and that the 78% figure is specific to fine-tuned VideoMAE on this corpus. revision: no
Circularity Check
No significant circularity in derivation chain
full rationale
The manuscript is an empirical report of fine-tuning VideoMAE on a 13-class, 197-clip subset of the AI4Bharat corpus (80-20 split) and reporting direct training/validation accuracies plus a confusion matrix. No equations, self-referential predictions, fitted parameters renamed as outputs, or load-bearing self-citations appear in the derivation chain. The central results are factual experimental outcomes on held-out clips, framed explicitly as a limited-scope demonstration with stated constraints on generalization.
Axiom & Free-Parameter Ledger
free parameters (1)
- class subset size =
13
axioms (1)
- domain assumption Pre-trained video transformers transfer effectively to sign-language classification when fine-tuned on small domain-specific data
Reference graph
Works this paper leans on
-
[1]
Real-time american sign language recognition using desk and wearable computer based video
Thad Starner, Joshua Weaver, and Alex Pentland. Real-time american sign language recognition using desk and wearable computer based video. InIEEE Transactions on Pattern Analysis and Machine Intelligence, volume 20, pages 1371–1375, 1998
1998
-
[2]
Sign language recognition: Generalising to more complex corpora.Gesture Recognition, pages 523–543, 2011
Helen Cooper, Brian Holt, and Richard Bowden. Sign language recognition: Generalising to more complex corpora.Gesture Recognition, pages 523–543, 2011
2011
-
[3]
Deep sign: Hybrid cnn-hmm for continuous sign language recognition
Oscar Koller, Sepehr Zargaran, Hermann Ney, and Richard Bowden. Deep sign: Hybrid cnn-hmm for continuous sign language recognition. InProceedings of the British Machine Vision Conference (BMVC), 2016. 7
2016
-
[4]
Neural sign language translation
Necati Cihan Camgoz, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden. Neural sign language translation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7784–7793, 2018
2018
-
[5]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2021
2021
-
[7]
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.arXiv preprint arXiv:2203.12602, 2022
-
[8]
NLLB Team, Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Sign language trans- formers: Joint end-to-end sign language recognition and translation
Necati Cihan Camgoz, Oscar Koller, Simon Hadfield, and Richard Bowden. Sign language trans- formers: Joint end-to-end sign language recognition and translation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10023–10033, 2020
2020
-
[10]
Openhands / ai4bharat: Indian sign language datasets
AI4Bharat. Openhands / ai4bharat: Indian sign language datasets. https://openhands. ai4bharat.org/en/latest/instructions/datasets.html, 2023. Dataset curated in collaboration with the Indian Institute of Technology Madras. 8
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.